100일간의 머신러닝 코드
Siraj Raval이 제안한 100일간의 머신러닝 코딩
여기에서 데이터셋을 받으세요.
데이터 전처리 | 1일차
여기에서 코드를 확인하세요.

단순 선형 회귀 | 2일차
여기에서 코드를 확인하세요.

다중 선형 회귀 | 3일차
여기에서 코드를 확인하세요.

로지스틱 회귀 | 4일차

로지스틱 회귀 | 5일차
#100DaysOfMLCode를 진행하면서 오늘 로지스틱 회귀가 실제로 무엇이며 그 뒤에 숨겨진 수학은 무엇인지 더 깊이 파고들었습니다. 비용 함수가 어떻게 계산되는지, 그리고 예측 오류를 최소화하기 위해 비용 함수에 경사 하강 알고리즘을 적용하는 방법을 배웠습니다. 시간이 부족하여 이제 격일로 인포그래픽을 게시할 예정입니다. 또한 코드 문서화에 도움을 주실 분이 있고 이미 해당 분야에 경험이 있으며 github용 Markdown을 알고 계신다면 LinkedIn으로 저에게 연락해 주세요 :).
로지스틱 회귀 구현 | 6일차
여기에서 코드를 확인하세요.
K 최근접 이웃 | 7일차

로지스틱 회귀의 수학적 원리 | 8일차
#100DaysOfMLCode 로지스틱 회귀에 대한 이해를 명확히 하기 위해 인터넷에서 자료나 기사를 검색하다가 Saishruthi Swaminathan의 이 기사(https://towardsdatascience.com/logistic-regression-detailed-overview-46c4da4303bc)를 발견했습니다.
로지스틱 회귀에 대한 자세한 설명을 제공합니다. 확인해 보세요.
서포트 벡터 머신 | 9일차
SVM이 무엇이며 분류 문제를 해결하는 데 어떻게 사용되는지에 대한 직관을 얻었습니다.
SVM 및 KNN | 10일차
SVM 작동 방식에 대해 더 자세히 배우고 K-NN 알고리즘을 구현했습니다.
K-NN 구현 | 11일차
분류를 위한 K-NN 알고리즘을 구현했습니다. #100DaysOfMLCode 서포트 벡터 머신 인포그래픽이 절반 정도 완료되었습니다. 내일 업데이트하겠습니다.
서포트 벡터 머신 | 12일차
나이브 베이즈 분류기 | 13일차
#100DaysOfMLCode를 계속 진행하면서 오늘 나이브 베이즈 분류기를 살펴보았습니다. 또한 scikit-learn을 사용하여 파이썬으로 SVM을 구현하고 있습니다. 코드는 곧 업데이트하겠습니다.
SVM 구현 | 14일차
오늘 선형적으로 관련된 데이터에 SVM을 구현했습니다. Scikit-Learn 라이브러리를 사용했습니다. Scikit-Learn에는 이 작업을 수행하는 데 사용하는 SVC 분류기가 있습니다. 다음 구현에서는 커널 트릭을 사용할 예정입니다. 여기에서 코드를 확인하세요.
나이브 베이즈 분류기 및 블랙박스 머신러닝 | 15일차
다양한 유형의 나이브 베이즈 분류기에 대해 배웠습니다. 또한 Bloomberg의 강의를 듣기 시작했습니다. 재생 목록의 첫 번째 강의는 블랙박스 머신러닝이었습니다. 예측 함수, 특징 추출, 학습 알고리즘, 성능 평가, 교차 검증, 샘플 편향, 비정상성, 과적합 및 하이퍼파라미터 튜닝에 대한 전체 개요를 제공합니다.
커널 트릭을 사용한 SVM 구현 | 16일차
Scikit-Learn 라이브러리를 사용하여 데이터 포인트를 더 높은 차원으로 매핑하여 최적의 초평면을 찾는 커널 함수와 함께 SVM 알고리즘을 구현했습니다.
Coursera에서 딥러닝 전문 과정 시작 | 17일차
하루 만에 1주차와 2주차 전체를 완료했습니다. 신경망으로서의 로지스틱 회귀를 배웠습니다.
Coursera에서 딥러닝 전문 과정 | 18일차
딥러닝 전문 과정의 첫 번째 과정을 완료했습니다. 파이썬으로 신경망을 구현했습니다.
학습 문제, Yaser Abu-Mostafa 교수 | 19일차
Yaser Abu-Mostafa 교수의 Caltech 머신러닝 과정(CS 156) 18개 강의 중 첫 번째 강의를 시작했습니다. 기본적으로 다음 강의에 대한 소개였습니다. 또한 퍼셉트론 알고리즘에 대해서도 설명했습니다.
딥러닝 전문 과정 2 시작 | 20일차
심층 신경망 개선: 하이퍼파라미터 튜닝, 정규화 및 최적화 1주차를 완료했습니다.
웹 스크래핑 | 21일차
모델 구축을 위한 데이터 수집을 위해 Beautiful Soup을 사용하여 웹 스크래핑을 수행하는 방법에 대한 몇 가지 튜토리얼을 시청했습니다.
학습은 가능한가? | 22일차
Yaser Abu-Mostafa 교수의 Caltech 머신러닝 과정(CS 156) 18개 강의 중 두 번째 강의. 호프딩 부등식에 대해 배웠습니다.
결정 트리 | 23일차

통계 학습 이론 소개 | 24일차
Bloomberg ML 과정의 세 번째 강의에서는 입력 공간, 행동 공간, 결과 공간, 예측 함수, 손실 함수 및 가설 공간과 같은 핵심 개념 중 일부를 소개했습니다.
결정 트리 구현 | 25일차
여기에서 코드를 확인하세요.
선형 대수 복습으로 이동 | 26일차
유튜브에서 3Blue1Brown이라는 놀라운 채널을 발견했습니다. 선형 대수의 본질이라는 재생 목록이 있습니다. 벡터, 선형 조합, 스팬, 기저 벡터, 선형 변환 및 행렬 곱셈에 대한 전체 개요를 제공하는 4개의 비디오를 완료하며 시작했습니다.
재생 목록 링크는 여기입니다.
선형 대수 복습으로 이동 | 27일차
재생 목록을 계속 진행하면서 3D 변환, 행렬식, 역행렬, 열 공간, 영 공간 및 비정방 행렬 주제를 다루는 다음 4개의 비디오를 완료했습니다.
재생 목록 링크는 여기입니다.
선형 대수 복습으로 이동 | 28일차
3Blue1Brown의 재생 목록에서 선형 대수의 본질에서 3개의 비디오를 추가로 완료했습니다. 다룬 주제는 내적과 외적이었습니다.
재생 목록 링크는 여기입니다.
선형 대수 복습으로 이동 | 29일차
오늘 12-14번 비디오를 통해 전체 재생 목록을 완료했습니다. 선형 대수 개념을 복습하기에 정말 놀라운 재생 목록입니다. 다룬 주제는 기저 변경, 고유 벡터 및 고유값, 추상 벡터 공간이었습니다.
재생 목록 링크는 여기입니다.
미적분학의 본질 | 30일차
3blue1brown의 선형 대수의 본질 재생 목록을 완료하자 유튜브에서 같은 채널 3Blue1Brown의 비디오 시리즈에 대한 제안이 나타났습니다. 이미 이전 선형 대수 시리즈에 깊은 인상을 받았기 때문에 바로 뛰어들었습니다. 도함수, 연쇄 법칙, 곱셈 법칙 및 지수 함수의 도함수와 같은 주제에 대한 약 5개의 비디오를 완료했습니다.
재생 목록 링크는 여기입니다.
미적분학의 본질 | 31일차
미적분학의 본질 재생 목록에서 음함수 미분 및 극한 주제에 대한 2개의 비디오를 시청했습니다.
재생 목록 링크는 여기입니다.
미적분학의 본질 | 32일차
적분 및 고계 도함수와 같은 주제를 다루는 나머지 4개의 비디오를 시청했습니다.
재생 목록 링크는 여기입니다.
랜덤 포레스트 | 33일차
랜덤 포레스트 구현 | 34일차
여기에서 코드를 확인하세요.
하지만 신경망이란 무엇일까요? | 딥러닝, 1장 | 35일차
3Blue1Brown 유튜브 채널의 신경망에 대한 놀라운 비디오. 이 비디오는 신경망에 대한 이해를 돕고 손으로 쓴 숫자 데이터셋을 사용하여 개념을 설명합니다. 비디오 링크입니다.
경사 하강, 신경망이 학습하는 방법 | 딥러닝, 2장 | 36일차
3Blue1Brown 유튜브 채널의 신경망 2부. 이 비디오는 흥미로운 방식으로 경사 하강 개념을 설명합니다. 169 꼭 봐야 할 강력 추천 비디오입니다. 비디오 링크입니다.
역전파는 실제로 무엇을 하고 있을까요? | 딥러닝, 3장 | 37일차
3Blue1Brown 유튜브 채널의 신경망 3부. 이 비디오는 주로 편도함수와 역전파에 대해 설명합니다. 비디오 링크입니다.
역전파 미적분학 | 딥러닝, 4장 | 38일차
3Blue1Brown 유튜브 채널의 신경망 4부. 여기서 목표는 역전파가 작동하는 방식에 대한 직관을 다소 공식적인 용어로 표현하는 것이며 비디오는 주로 편도함수와 역전파에 대해 설명합니다. 비디오 링크입니다.
파이썬, 텐서플로우, 케라스를 사용한 딥러닝 튜토리얼 | 39일차
비디오 링크입니다.
자체 데이터 로드 - 파이썬, 텐서플로우, 케라스를 사용한 딥러닝 기초 2부 | 40일차
비디오 링크입니다.
컨볼루션 신경망 - 파이썬, 텐서플로우, 케라스를 사용한 딥러닝 기초 3부 | 41일차
비디오 링크입니다.
텐서보드를 사용한 모델 분석 - 파이썬, 텐서플로우, 케라스를 사용한 딥러닝 4부 | 42일차
비디오 링크입니다.
K 평균 군집화 | 43일차
비지도 학습으로 넘어가 군집화에 대해 공부했습니다. 제 웹사이트 avikjain.me를 확인해 보세요. 또한 K 평균 군집화를 쉽게 이해하는 데 도움이 되는 멋진 애니메이션을 찾았습니다. 링크

K 평균 군집화 구현 | 44일차
K 평균 군집화를 구현했습니다. 여기에서 코드를 확인하세요.
더 깊이 파고들기 | NUMPY | 45일차
JK VanderPlas의 새 책 “Python Data Science HandBook“을 받았습니다. 여기에서 Jupyter 노트북을 확인하세요.
2장 Numpy 소개부터 시작했습니다. 데이터 유형, Numpy 배열 및 Numpy 배열 연산과 같은 주제를 다루었습니다.
코드를 확인하세요 -
NumPy 소개
파이썬의 데이터 유형 이해
NumPy 배열의 기초
NumPy 배열 연산: 유니버설 함수
더 깊이 파고들기 | NUMPY | 46일차
2장: 집계, 비교 및 브로드캐스팅
노트북 링크:
집계: 최소, 최대 및 그 사이의 모든 것
배열 연산: 브로드캐스팅
비교, 마스크 및 부울 논리
더 깊이 파고들기 | NUMPY | 47일차
2장: 팬시 인덱싱, 배열 정렬, 구조화된 데이터
노트북 링크:
팬시 인덱싱
배열 정렬
구조화된 데이터: NumPy의 구조화된 배열
더 깊이 파고들기 | PANDAS | 48일차
3장: Pandas를 사용한 데이터 조작
Pandas 객체, 데이터 인덱싱 및 선택, 데이터 연산, 누락된 데이터 처리, 계층적 인덱싱, ConCat 및 Append와 같은 다양한 주제를 다루었습니다.
노트북 링크:
Pandas를 사용한 데이터 조작
Pandas 객체 소개
데이터 인덱싱 및 선택
Pandas의 데이터 연산
누락된 데이터 처리
계층적 인덱싱
데이터셋 결합: Concat 및 Append
더 깊이 파고들기 | PANDAS | 49일차
3장: 다음 주제 완료 - 병합 및 조인, 집계 및 그룹화, 피벗 테이블.
데이터셋 결합: 병합 및 조인
집계 및 그룹화
피벗 테이블
더 깊이 파고들기 | PANDAS | 50일차
3장: 벡터화된 문자열 연산, 시계열 작업
노트북 링크:
벡터화된 문자열 연산
시계열 작업
고성능 Pandas: eval() 및 query()
더 깊이 파고들기 | MATPLOTLIB | 51일차
4장: Matplotlib을 사용한 시각화
단순 선 플롯, 단순 산점도, 밀도 및 등고선 플롯에 대해 배웠습니다.
노트북 링크:
Matplotlib을 사용한 시각화
단순 선 플롯
단순 산점도
오류 시각화
밀도 및 등고선 플롯
더 깊이 파고들기 | MATPLOTLIB | 52일차
4장: Matplotlib을 사용한 시각화
히스토그램, 플롯 범례 사용자 지정 방법, 색상 막대 및 다중 서브플롯 만들기에 대해 배웠습니다.
노트북 링크:
히스토그램, 구간화 및 밀도
플롯 범례 사용자 지정
색상 막대 사용자 지정
다중 서브플롯
텍스트 및 주석
더 깊이 파고들기 | MATPLOTLIB | 53일차
4장: Mathplotlib의 3차원 플로팅을 다루었습니다.
노트북 링크:
Matplotlib의 3차원 플로팅
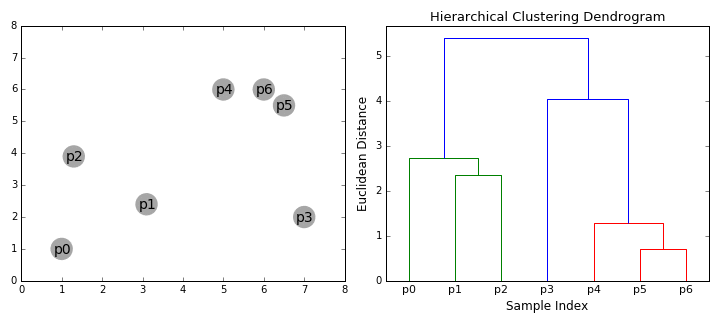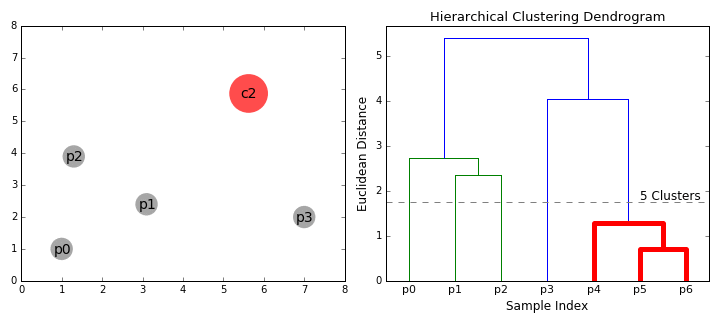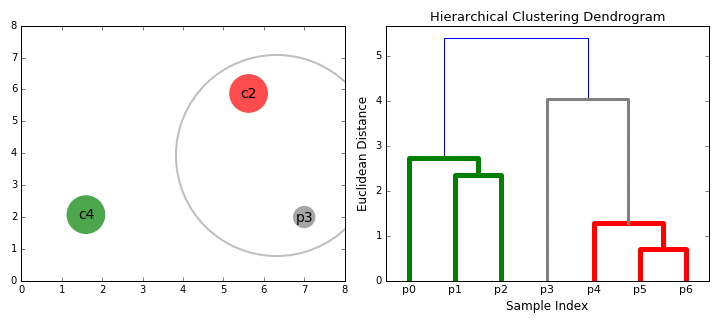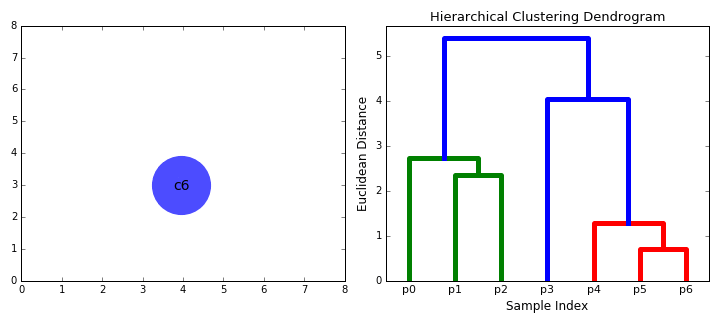
계층적 군집화 | 54일차
계층적 군집화에 대해 공부했습니다. 이 놀라운 시각화를 확인해 보세요.
{kind=link}

강화 학습 소개 | 55일차
강화 학습(RL)의 기본 개념과 용어(에이전트, 환경, 보상, 정책, 가치 함수)를 학습했습니다. 자세히 보기
마르코프 결정 과정 | 56일차
강화 학습의 핵심 프레임워크인 마르코프 결정 과정(MDP)에 대해 학습했습니다. 자세히 보기
Q-러닝 - 이론 및 알고리즘 | 57일차
모델 프리 강화 학습 알고리즘인 Q-러닝의 이론적 배경과 작동 방식에 대해 학습했습니다. 자세히 보기
Q-러닝 - 간단한 구현 | 58일차
간단한 예제(예: 그리드 월드)를 통해 Q-러닝을 구현하는 방법을 학습했습니다. 코드
심층 Q-네트워크 (DQN) | 59일차
Q-러닝과 심층 신경망을 결합한 심층 Q-네트워크(DQN)의 개념과 장점에 대해 학습했습니다. 자세히 보기
자연어 처리 소개 | 60일차
자연어 처리(NLP)의 기본 개념과 용어(코퍼스, 토큰, 임베딩)를 학습했습니다. 자세히 보기
텍스트 전처리 | 61일차
NLP의 중요한 단계인 텍스트 전처리 기법(토큰화, 어간 추출, 표제어 추출)에 대해 학습했습니다. 자세히 보기
Bag-of-Words 및 TF-IDF | 62일차
텍스트 데이터를 수치 벡터로 변환하는 대표적인 방법인 Bag-of-Words와 TF-IDF에 대해 학습하고 구현했습니다. 코드
단어 임베딩 - Word2Vec, GloVe (개념) | 63일차
단어의 의미를 밀집 벡터로 표현하는 단어 임베딩 기법인 Word2Vec과 GloVe의 개념에 대해 학습했습니다. 자세히 보기
Word2Vec 구현 | 64일차
Gensim 라이브러리를 사용하여 Word2Vec을 구현하는 방법을 학습했습니다. 코드
감성 분석 - 기본 기법 | 65일차
텍스트에 나타난 감성을 분석하는 기본 기법들에 대해 학습했습니다. 자세히 보기
간단한 감성 분석기 구축 | 66일차
학습한 내용을 바탕으로 간단한 감성 분석기를 구축했습니다. 코드
순환 신경망 (RNN) 소개 | 67일차
순서가 있는 데이터를 처리하는 데 효과적인 순환 신경망(RNN)의 기본 구조와 원리에 대해 학습했습니다. 자세히 보기
LSTM (Long Short-Term Memory) 네트워크 | 68일차
RNN의 장기 의존성 문제를 해결하기 위해 제안된 LSTM 네트워크에 대해 학습했습니다. 자세히 보기
RNN/LSTM을 이용한 텍스트 분류기 구축 | 69일차
RNN 또는 LSTM을 사용하여 텍스트 분류기를 구축하는 방법을 학습했습니다. 코드
강화 학습 및 NLP 개념 복습 | 70일차
지난 15일간 학습한 강화 학습 및 자연어 처리 관련 주요 개념들을 복습했습니다. 자세히 보기
주성분 분석 (PCA) - 이론 및 구현 | 71일차
차원 축소 기법 중 하나인 주성분 분석(PCA)의 이론을 학습하고 구현했습니다. 코드
선형 판별 분석 (LDA) | 72일차
또 다른 차원 축소 및 분류 기법인 선형 판별 분석(LDA)에 대해 학습했습니다. 코드
모델 평가 지표 | 73일차
머신러닝 모델의 성능을 평가하기 위한 다양한 지표(정밀도, 재현율, F1 점수, ROC AUC)에 대해 학습했습니다. 자세히 보기
교차 검증 기법 | 74일차
모델의 일반화 성능을 평가하기 위한 교차 검증 기법(K-폴드 교차 검증 등)에 대해 학습했습니다. 자세히 보기
하이퍼파라미터 튜닝 | 75일차
모델 성능을 최적화하기 위한 하이퍼파라미터 튜닝 방법(그리드 서치, 랜덤 서치)에 대해 학습했습니다. 자세히 보기
앙상블 방법 - 배깅, 부스팅 | 76일차
여러 모델을 결합하여 성능을 향상시키는 앙상블 기법 중 배깅(랜덤 포레스트 복습)과 부스팅(AdaBoost, Gradient Boosting)에 대해 학습했습니다. 코드
XGBoost - 소개 및 구현 | 77일차
강력한 부스팅 알고리즘인 XGBoost의 개념을 학습하고 구현했습니다. 코드
LightGBM - 소개 및 구현 | 78일차
XGBoost와 유사하지만 더 빠르고 효율적인 LightGBM에 대해 학습하고 구현했습니다. 코드
시계열 분석 소개 | 79일차
시간 순서대로 기록된 데이터인 시계열 데이터 분석의 기초 개념을 학습했습니다. 자세히 보기
시계열을 위한 ARIMA 모델 | 80일차
대표적인 시계열 예측 모델인 ARIMA 모델에 대해 학습하고 간단한 예제에 적용해 보았습니다. 코드
모델 배포 소개 | 81일차
개발한 머신러닝 모델을 실제 환경에서 사용할 수 있도록 배포하는 과정의 중요성과 기본 개념을 학습했습니다. 자세히 보기
ML 모델 배포를 위한 Flask/Django - 기초 | 82일차
웹 프레임워크인 Flask 또는 Django를 사용하여 머신러닝 모델을 배포하는 기초적인 방법을 학습했습니다. 자세히 보기
ML 모델을 위한 간단한 API 만들기 | 83일차
Flask/Django를 사용하여 학습된 머신러닝 모델을 위한 간단한 API를 만드는 실습을 진행했습니다. 코드
ML을 위한 Docker - 기초 | 84일차
컨테이너화 기술인 Docker를 머신러닝 모델 배포에 활용하는 기초적인 방법을 학습했습니다. 자세히 보기
Docker를 사용한 간단한 ML 모델 배포 | 85일차
Docker를 사용하여 간단한 머신러닝 모델을 배포하는 실습을 진행했습니다. 코드
캡스톤 프로젝트 아이디어 브레인스토밍 | 86일차
100일 챌린지를 마무리할 캡스톤 프로젝트에 대한 아이디어를 구상했습니다. 자세히 보기
캡스톤 프로젝트 선정 및 범위 정의 | 87일차
여러 아이디어 중 하나를 캡스톤 프로젝트로 선정하고, 프로젝트의 목표와 범위를 명확히 정의했습니다. 자세히 보기
프로젝트를 위한 데이터 수집 및 전처리 | 88일차
캡스톤 프로젝트에 필요한 데이터를 수집하고, 모델 학습에 적합하도록 전처리하는 작업을 수행했습니다. 자세히 보기
프로젝트를 위한 탐색적 데이터 분석 (EDA) | 89일차
수집된 데이터를 다양한 각도에서 분석하고 시각화하여 데이터의 특징과 패턴을 파악하는 EDA를 수행했습니다. 자세히 보기
프로젝트를 위한 모델 선정 및 초기 학습 | 90일차
프로젝트 목표에 맞는 머신러닝 모델을 선정하고, 전처리된 데이터를 사용하여 초기 모델 학습을 진행했습니다. 자세히 보기
프로젝트를 위한 모델 평가 및 반복 | 91일차
학습된 모델의 성능을 평가하고, 문제점을 분석하여 모델을 개선하는 반복 작업을 수행했습니다. 자세히 보기
프로젝트를 위한 미세 조정 및 최적화 | 92일차
선정된 모델의 하이퍼파라미터를 조정하고 다양한 최적화 기법을 적용하여 모델 성능을 극대화했습니다. 자세히 보기
프로젝트를 위한 간단한 UI 또는 프레젠테이션 구축 | 93일차
캡스톤 프로젝트의 결과를 효과적으로 보여줄 수 있는 간단한 사용자 인터페이스(UI) 또는 프레젠테이션 자료를 제작했습니다. 자세히 보기
캡스톤 프로젝트 문서화 | 94일차
프로젝트의 전 과정(데이터 수집, 전처리, 모델링, 평가, 결과)을 상세히 기록하여 문서화했습니다. 자세히 보기
생성적 적대 신경망 (GAN) 소개 | 95일차
새로운 데이터를 생성하는 모델인 생성적 적대 신경망(GAN)의 기본 개념과 작동 원리에 대해 학습했습니다. 자세히 보기
오토인코더 | 96일차
데이터의 특징을 효율적으로 학습하여 차원 축소나 이상치 탐지 등에 활용되는 오토인코더에 대해 학습했습니다. 자세히 보기
설명 가능한 AI (XAI) - LIME, SHAP | 97일차
머신러닝 모델의 예측 결과를 사람이 이해할 수 있도록 설명하는 XAI 기법(LIME, SHAP 등)에 대해 학습했습니다. 자세히 보기
AI 및 머신러닝 윤리 | 98일차
인공지능 기술 발전과 함께 중요성이 커지고 있는 AI 및 머신러닝 윤리 문제에 대해 고찰했습니다. 자세히 보기
ML 및 AI의 미래 동향 | 99일차
머신러닝과 인공지능 분야의 최신 연구 동향과 미래 발전 가능성에 대해 학습하고 토론했습니다. 자세히 보기
100일 여정 복습 및 다음 단계 | 100일차
지난 100일간의 머신러닝 학습 여정을 되돌아보고, 앞으로의 학습 계획 및 목표를 설정했습니다. 자세히 보기
데이터 전처리
인포그래픽에 표시된 것처럼 데이터 전처리를 6가지 필수 단계로 나눕니다. 이 예제에 사용된 데이터셋은 여기에서 가져오세요.
1단계: 라이브러리 가져오기
import numpy as np
import pandas as pd
2단계: 데이터셋 가져오기
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[ : , :-1].values # 종속 변수를 제외한 모든 열 선택
Y = dataset.iloc[ : , 3].values # 종속 변수 열 선택
3단계: 누락된 데이터 처리
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0) # 누락된 값을 평균으로 대체
imputer = imputer.fit(X[ : , 1:3]) # 숫자형 열에 대해 imputer 학습
X[ : , 1:3] = imputer.transform(X[ : , 1:3]) # 누락된 값 변환
4단계: 범주형 데이터 인코딩
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0]) # 첫 번째 열(국가)을 숫자로 인코딩
더미 변수 만들기
onehotencoder = OneHotEncoder(categorical_features = [0]) # 첫 번째 열을 원-핫 인코딩
X = onehotencoder.fit_transform(X).toarray()
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y) # 종속 변수(구매 여부)를 숫자로 인코딩
5단계: 데이터셋을 훈련 세트와 테스트 세트로 분할
from sklearn.cross_validation import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0) # 80% 훈련, 20% 테스트
6단계: 특징 스케일링
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train) # 훈련 세트에 대해 스케일러 학습 및 변환
X_test = sc_X.transform(X_test) # 테스트 세트에 대해 학습된 스케일러로 변환 (fit_transform 아님)
완료 :smile:
단순 선형 회귀
1단계: 데이터 전처리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
dataset = pd.read_csv('studentscores.csv')
X = dataset.iloc[ : , : 1 ].values # 독립 변수 (학습 시간)
Y = dataset.iloc[ : , 1 ].values # 종속 변수 (점수)
from sklearn.cross_validation import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size = 1/4, random_state = 0) # 75% 훈련, 25% 테스트
2단계: 훈련 세트에 단순 선형 회귀 모델 피팅
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor = regressor.fit(X_train, Y_train) # 훈련 데이터로 모델 학습
3단계: 결과 예측
Y_pred = regressor.predict(X_test) # 테스트 데이터로 예측
4단계: 시각화
훈련 결과 시각화
plt.scatter(X_train , Y_train, color = 'red') # 실제 훈련 데이터 점
plt.plot(X_train , regressor.predict(X_train), color ='blue') # 훈련 데이터에 대한 예측 선
테스트 결과 시각화
plt.scatter(X_test , Y_test, color = 'red') # 실제 테스트 데이터 점
plt.plot(X_test , regressor.predict(X_test), color ='blue') # 테스트 데이터에 대한 예측 선 (X_train에 대한 예측 선과 동일해야 함)
다중 선형 회귀
1단계: 데이터 전처리
라이브러리 가져오기
import pandas as pd
import numpy as np
데이터셋 가져오기
dataset = pd.read_csv('50_Startups.csv')
X = dataset.iloc[ : , :-1].values # 독립 변수 (R&D 지출, 관리비, 마케팅 지출, 주)
Y = dataset.iloc[ : , 4 ].values # 종속 변수 (수익)
범주형 데이터 인코딩
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder = LabelEncoder()
X[: , 3] = labelencoder.fit_transform(X[ : , 3]) # '주' 열을 숫자로 인코딩
onehotencoder = OneHotEncoder(categorical_features = [3]) # '주' 열을 원-핫 인코딩
X = onehotencoder.fit_transform(X).toarray()
더미 변수 함정 피하기
X = X[: , 1:] # 첫 번째 더미 변수 열을 제거하여 다중공선성 방지
데이터셋을 훈련 세트와 테스트 세트로 분할
from sklearn.cross_validation import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0) # 80% 훈련, 20% 테스트
2단계: 훈련 세트에 다중 선형 회귀 피팅
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train, Y_train) # 훈련 데이터로 모델 학습
3단계: 테스트 세트 결과 예측
y_pred = regressor.predict(X_test) # 테스트 데이터로 예측
로지스틱 회귀
데이터셋 | 소셜 네트워크
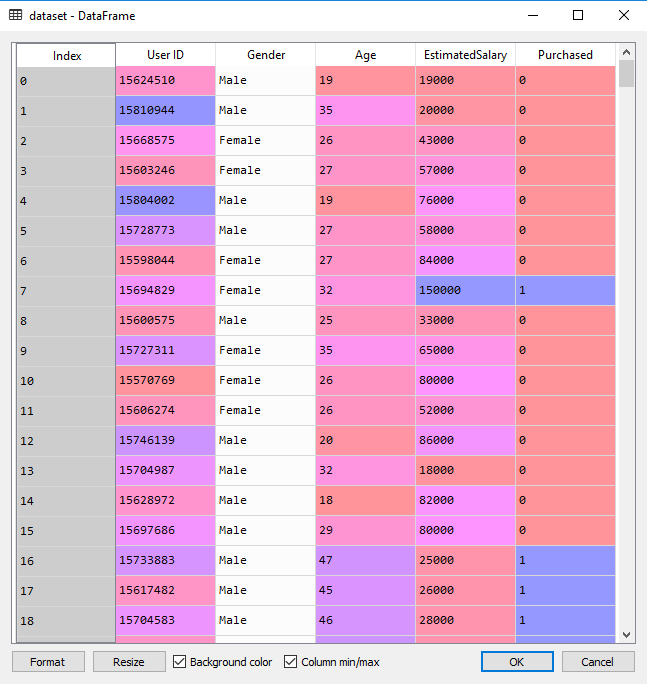
이 데이터셋에는 소셜 네트워크 사용자 정보가 포함되어 있습니다. 이 정보는 사용자 ID, 성별, 나이 및 예상 급여입니다. 한 자동차 회사가 새로운 고급 SUV를 출시했습니다. 그리고 우리는 이 소셜 네트워크 사용자 중 누가 이 새로운 SUV를 구매할 것인지 확인하려고 합니다. 그리고 여기 마지막 열은 사용자가 이 SUV를 구매했는지 여부를 나타냅니다. 우리는 두 가지 변수, 즉 나이와 예상 급여를 기반으로 사용자가 SUV를 구매할지 여부를 예측하는 모델을 구축할 것입니다. 따라서 우리의 특징 행렬은 이 두 열만 해당됩니다. 우리는 사용자의 나이와 예상 급여, 그리고 SUV 구매 결정(예 또는 아니오) 사이의 상관 관계를 찾고 싶습니다.
1단계 | 데이터 전처리
라이브러리 가져오기
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
데이터셋 가져오기
여기에서 데이터셋을 가져오세요.
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values # 독립 변수 (나이, 예상 급여)
y = dataset.iloc[:, 4].values # 종속 변수 (구매 여부)
데이터셋을 훈련 세트와 테스트 세트로 분할
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # 75% 훈련, 25% 테스트
특징 스케일링
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train) # 훈련 세트에 스케일러 학습 및 적용
X_test = sc.transform(X_test) # 테스트 세트에 학습된 스케일러 적용
2단계 | 로지스틱 회귀 모델
이 작업에 사용할 라이브러리는 선형 모델 라이브러리이며 로지스틱 회귀가 선형 분류기이기 때문에 선형이라고 불립니다. 즉, 여기서는 2차원이므로 두 사용자 범주는 직선으로 구분됩니다. 그런 다음 로지스틱 회귀 클래스를 가져옵니다. 다음으로 이 클래스에서 새 객체를 만들 것인데, 이 객체는 훈련 세트에 적합시킬 분류기가 됩니다.
훈련 세트에 로지스틱 회귀 피팅
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression() # random_state는 필요에 따라 추가 가능
classifier.fit(X_train, y_train)
3단계 | 예측
테스트 세트 결과 예측
y_pred = classifier.predict(X_test)
4단계 | 예측 평가
테스트 결과를 예측했으며 이제 로지스틱 회귀 모델이 올바르게 학습하고 이해했는지 평가할 것입니다. 따라서 이 혼동 행렬에는 모델이 세트에서 수행한 올바른 예측과 잘못된 예측이 포함됩니다.
혼동 행렬 만들기
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
시각화
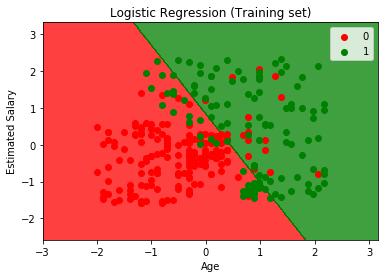
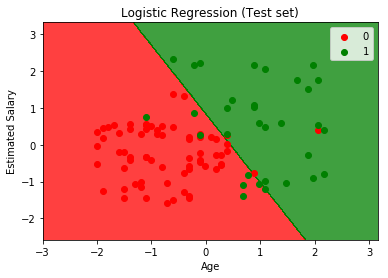
K-최근접 이웃 (K-NN)
데이터셋 | 소셜 네트워크
라이브러리 가져오기
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
데이터셋 가져오기
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
데이터셋을 훈련 세트와 테스트 세트로 분할
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
특징 스케일링
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
훈련 세트에 K-NN 피팅
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski', p = 2) # n_neighbors: 이웃 수, metric: 거리 측정 방식, p: 민코프스키 거리의 파라미터 (2는 유클리드 거리)
classifier.fit(X_train, y_train)
테스트 세트 결과 예측
y_pred = classifier.predict(X_test)
혼동 행렬 만들기
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
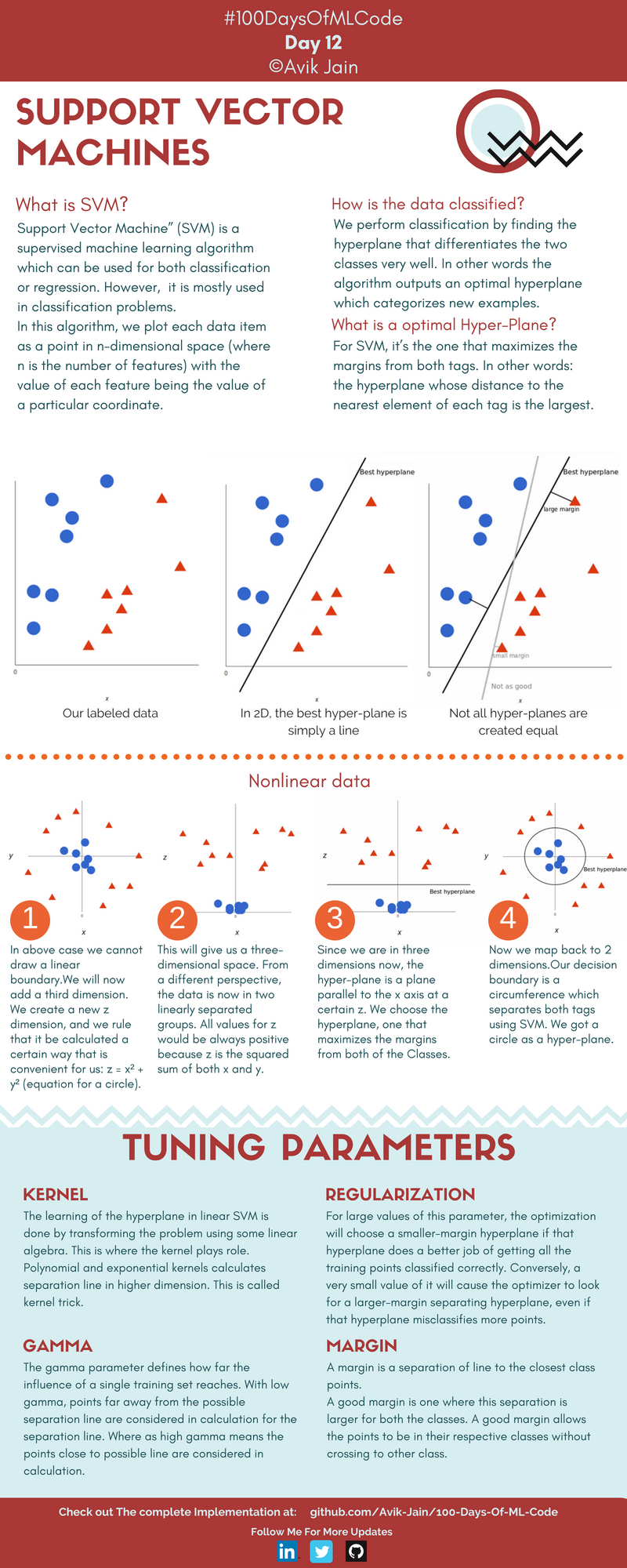
13일차 | 서포트 벡터 머신 (SVM)
라이브러리 가져오기
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
데이터셋 가져오기
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
데이터셋을 훈련 세트와 테스트 세트로 분할
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
특징 스케일링
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.fit_transform(X_test) # 참고: 여기서는 fit_transform 대신 transform을 사용해야 합니다. 테스트 세트에서는 훈련 세트에서 학습한 스케일링을 그대로 적용해야 합니다.
훈련 세트에 SVM 피팅
from sklearn.svm import SVC
classifier = SVC(kernel = 'linear', random_state = 0) # kernel: 사용할 커널 함수 ('linear'는 선형 커널), random_state: 난수 시드
classifier.fit(X_train, y_train)
테스트 세트 결과 예측
y_pred = classifier.predict(X_test)
혼동 행렬 만들기
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
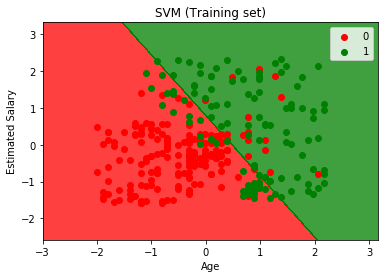
훈련 세트 결과 시각화
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('SVM (훈련 세트)')
plt.xlabel('나이')
plt.ylabel('예상 급여')
plt.legend()
plt.show()
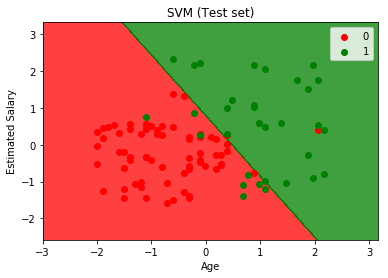
테스트 세트 결과 시각화
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('SVM (테스트 세트)')
plt.xlabel('나이')
plt.ylabel('예상 급여')
plt.legend()
plt.show()
결정 트리 분류
라이브러리 가져오기
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
데이터셋 가져오기
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values # 독립 변수 (나이, 예상 급여)
y = dataset.iloc[:, 4].values # 종속 변수 (구매 여부)
데이터셋을 훈련 세트와 테스트 세트로 분할
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # 75% 훈련, 25% 테스트
특징 스케일링
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train) # 훈련 세트에 스케일러 학습 및 적용
X_test = sc.transform(X_test) # 테스트 세트에 학습된 스케일러 적용
훈련 세트에 결정 트리 분류 피팅
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier(criterion = 'entropy', random_state = 0) # criterion: 분할 품질 측정 기준 ('entropy'는 정보 이득), random_state: 난수 시드
classifier.fit(X_train, y_train)
테스트 세트 결과 예측
y_pred = classifier.predict(X_test)
혼동 행렬 만들기
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
훈련 세트 결과 시각화
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('결정 트리 분류 (훈련 세트)')
plt.xlabel('나이')
plt.ylabel('예상 급여')
plt.legend()
plt.show()
테스트 세트 결과 시각화
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('결정 트리 분류 (테스트 세트)')
plt.xlabel('나이')
plt.ylabel('예상 급여')
plt.legend()
plt.show()
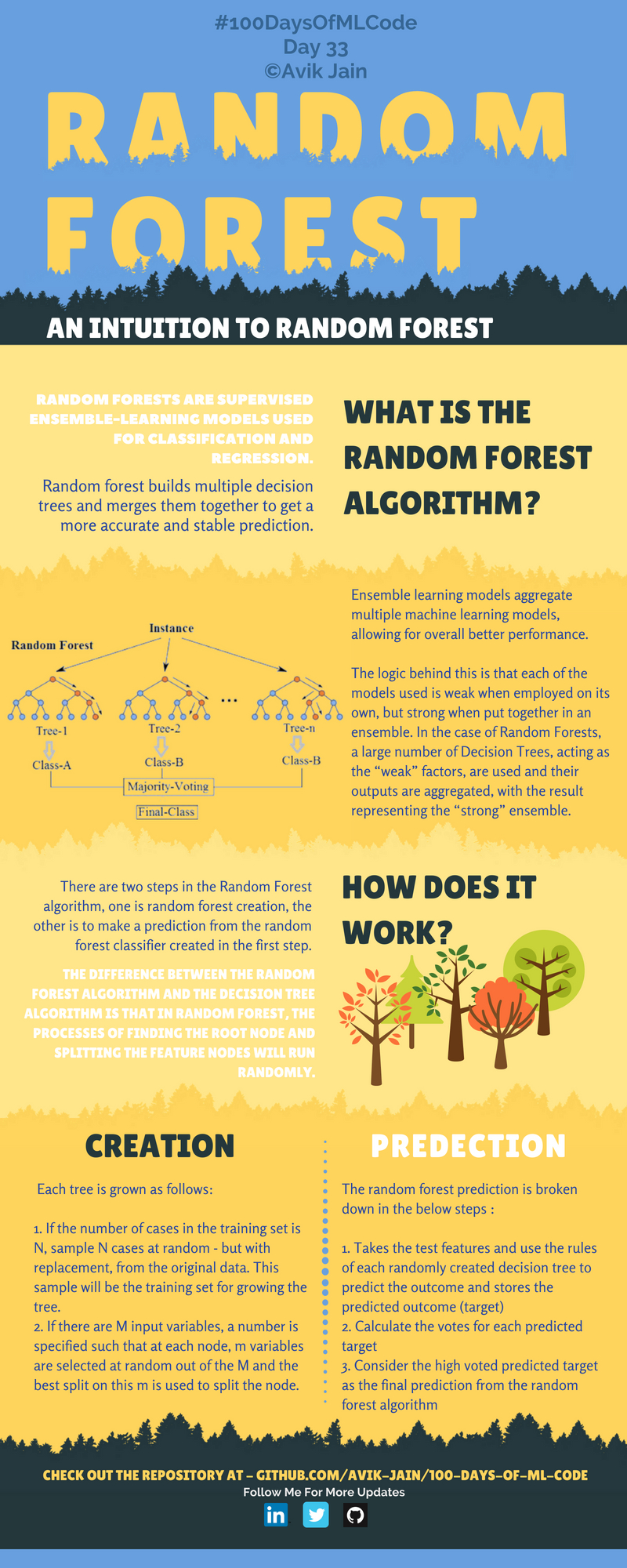
랜덤 포레스트
라이브러리 가져오기
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
데이터셋 가져오기
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values # 독립 변수 (나이, 예상 급여)
y = dataset.iloc[:, 4].values # 종속 변수 (구매 여부)
데이터셋을 훈련 세트와 테스트 세트로 분할
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # 75% 훈련, 25% 테스트
특징 스케일링
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train) # 훈련 세트에 스케일러 학습 및 적용
X_test = sc.transform(X_test) # 테스트 세트에 학습된 스케일러 적용
훈련 세트에 랜덤 포레스트 피팅
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators = 10, criterion = 'entropy', random_state = 0) # n_estimators: 트리의 개수, criterion: 분할 품질 측정 기준 ('entropy'는 정보 이득), random_state: 난수 시드
classifier.fit(X_train, y_train)
테스트 세트 결과 예측
y_pred = classifier.predict(X_test)
혼동 행렬 만들기
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
훈련 세트 결과 시각화
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('랜덤 포레스트 분류 (훈련 세트)')
plt.xlabel('나이')
plt.ylabel('예상 급여')
plt.legend()
plt.show()
테스트 세트 결과 시각화
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('랜덤 포레스트 분류 (테스트 세트)')
plt.xlabel('나이')
plt.ylabel('예상 급여')
plt.legend()
plt.show()
Day 55: 강화 학습 소개 (Introduction to Reinforcement Learning)
학습 목표
- 강화 학습(RL)의 기본 개념 이해
- RL의 주요 용어(에이전트, 환경, 상태, 행동, 보상, 정책, 가치 함수, 모델) 숙지
핵심 개념
1. 강화 학습 (Reinforcement Learning)
- 에이전트(Agent)가 환경(Environment)과 상호작용하며 학습하는 머신러닝의 한 분야입니다.
- 에이전트는 현재 상태(State)를 관찰하고 행동(Action)을 선택합니다.
- 환경은 에이전트의 행동에 따라 다음 상태로 전이되고 보상(Reward)을 에이전트에게 제공합니다.
- 에이전트의 목표는 누적 보상을 최대화하는 정책(Policy)을 학습하는 것입니다.
2. 주요 구성 요소
- **에이전트 (Agent)**: 학습의 주체. 환경을 관찰하고, 행동을 결정하며, 보상을 통해 학습합니다.
- **환경 (Environment)**: 에이전트가 상호작용하는 외부 세계. 에이전트의 행동에 따라 상태가 변하고 보상을 제공합니다.
- **상태 (State, S)**: 특정 시점에서 환경에 대한 관찰 가능한 정보. 에이전트가 행동을 결정하는 데 사용됩니다. (예: 게임 화면, 로봇 센서 값)
- **행동 (Action, A)**: 에이전트가 특정 상태에서 취할 수 있는 움직임이나 결정. (예: 게임 캐릭터의 이동, 로봇 팔의 움직임)
- **보상 (Reward, R)**: 에이전트가 특정 행동을 취했을 때 환경으로부터 받는 피드백. 즉각적인 좋고 나쁨을 나타내는 스칼라 값입니다. (예: 게임 점수 획득(+), 장애물 충돌(-))
- **정책 (Policy, π)**: 특정 상태에서 에이전트가 어떤 행동을 선택할지에 대한 전략 또는 규칙. 상태를 행동으로 매핑하는 함수로 표현될 수 있습니다. (π(a|s) = P[A_t = a | S_t = s])
- **가치 함수 (Value Function, V, Q)**: 특정 상태 또는 특정 상태-행동 쌍의 장기적인 가치를 평가하는 함수. 미래에 받을 누적 보상의 기댓값으로 정의됩니다.
- 상태 가치 함수 V(s): 상태 s에서 시작하여 특정 정책 π를 따랐을 때 받을 수 있는 누적 보상의 기댓값.
- 행동 가치 함수 Q(s, a): 상태 s에서 행동 a를 취하고 이후 특정 정책 π를 따랐을 때 받을 수 있는 누적 보상의 기댓값.
- **모델 (Model)** (선택 사항): 환경이 어떻게 작동하는지에 대한 에이전트의 표현. 상태 전이 확률과 보상 함수를 포함할 수 있습니다.
- 모델 기반 RL: 환경의 모델을 학습하거나 알고 있는 경우.
- 모델 프리 RL: 환경의 모델 없이 학습하는 경우.
3. 강화 학습의 목표
- 에이전트가 장기적으로 받는 누적 보상(Cumulative Reward)을 최대화하는 최적의 정책(Optimal Policy, π*)을 찾는 것입니다.
추가 학습 자료
다음 학습 내용
- Day 56: 마르코프 결정 과정 (Markov Decision Processes)
Day 56: 마르코프 결정 과정 (Markov Decision Processes, MDPs)
학습 목표
- 마르코프 결정 과정(MDP)의 정의와 구성 요소 이해
- MDP가 강화 학습 문제를 형식화하는 데 어떻게 사용되는지 이해
- 벨만 방정식(Bellman Equation)의 기본 개념 학습
핵심 개념
1. 마르코프 결정 과정 (MDP)
- 강화 학습 문제를 수학적으로 모델링하기 위한 프레임워크입니다.
- 순차적 의사 결정 문제를 다루며, 현재 상태가 주어지면 과거의 상태와 무관하게 미래의 상태 전이가 결정되는 마르코프 속성(Markov Property)을 가정합니다.
- MDP는 다음의 튜플로 정의됩니다: (S, A, P, R, γ)
- S (States): 가능한 모든 상태의 유한 집합. (어제 학습한 내용)
- A (Actions): 가능한 모든 행동의 유한 집합. (어제 학습한 내용)
- P (Transition Probability Function, P(s’|s, a)): 상태 s에서 행동 a를 취했을 때 다음 상태 s’로 전이될 확률. P(s’|s, a) = P[S_{t+1} = s’ | S_t = s, A_t = a]
- R (Reward Function, R(s, a, s’)): 상태 s에서 행동 a를 취하여 상태 s’로 전이했을 때 받는 즉각적인 보상. 때로는 R(s, a) 또는 R(s)로 단순화하여 표현하기도 합니다.
- γ (Discount Factor, 감가율): 0과 1 사이의 값으로, 미래 보상의 현재 가치를 나타냅니다. γ가 0에 가까우면 단기적인 보상에 집중하고, 1에 가까우면 장기적인 보상까지 고려합니다.
2. 마르코프 속성 (Markov Property)
- “미래는 과거와 독립적으로 현재에만 의존한다.”
- 특정 시점 t+1에서의 상태 S_{t+1}과 보상 R_{t+1}은, 바로 이전 시점 t에서의 상태 S_t와 행동 A_t에만 의존하고, 그 이전의 모든 상태와 행동 이력과는 무관하다는 성질입니다.
- P[S_{t+1} | S_t, A_t, S_{t-1}, A_{t-1}, …, S_0, A_0] = P[S_{t+1} | S_t, A_t]
3. 정책 (Policy, π)
- MDP에서 에이전트가 각 상태에서 어떤 행동을 선택할지를 결정하는 규칙입니다.
- 결정론적 정책(Deterministic Policy): π(s) = a (상태 s에서 항상 행동 a를 선택)
- 확률론적 정책(Stochastic Policy): π(a|s) = P[A_t = a | S_t = s] (상태 s에서 행동 a를 선택할 확률)
4. 가치 함수 (Value Function)
- 정책 π를 따랐을 때 각 상태 또는 상태-행동 쌍이 얼마나 좋은지를 나타내는 함수입니다.
- 상태 가치 함수 (State-Value Function, Vπ(s)): 상태 s에서 시작하여 정책 π를 따랐을 때 얻을 수 있는 총 감가된 보상의 기댓값. Vπ(s) = Eπ[Gt | St = s] = Eπ[∑k=0∞ γkRt+k+1 | St = s]
- 행동 가치 함수 (Action-Value Function, Qπ(s, a)): 상태 s에서 행동 a를 취하고 이후 정책 π를 따랐을 때 얻을 수 있는 총 감가된 보상의 기댓값. Qπ(s, a) = Eπ[Gt | St = s, At = a] = Eπ[∑k=0∞ γkRt+k+1 | St = s, At = a]
5. 벨만 방정식 (Bellman Equation)
- 가치 함수들 사이의 관계를 나타내는 방정식으로, 현재 상태의 가치와 다음 상태의 가치 사이의 관계를 재귀적으로 표현합니다.
- 강화 학습 알고리즘의 핵심적인 기반이 됩니다.
- 벨만 기대 방정식 (Bellman Expectation Equation) for Vπ: Vπ(s) = ∑a π(a|s) ∑s’ P(s’|s, a) [R(s, a, s’) + γVπ(s’)]
- 벨만 기대 방정식 (Bellman Expectation Equation) for Qπ: Qπ(s, a) = ∑s’ P(s’|s, a) [R(s, a, s’) + γ∑a’ π(a’|s’)Qπ(s’, a’)]
- 벨만 최적 방정식 (Bellman Optimality Equation): 최적 가치 함수 V*(s)와 Q*(s,a)에 대한 방정식.
- V*(s) = maxa ∑s’ P(s’|s, a) [R(s, a, s’) + γV*(s’)]
- Q*(s, a) = ∑s’ P(s’|s, a) [R(s, a, s’) + γmaxa’Q*(s’, a’)]
추가 학습 자료
다음 학습 내용
- Day 57: Q-러닝 - 이론 및 알고리즘 (Q-Learning - Theory and Algorithm)
Day 57: Q-러닝 - 이론 및 알고리즘 (Q-Learning - Theory and Algorithm)
학습 목표
- Q-러닝의 개념과 중요성 이해
- Q-러닝이 모델 프리(Model-Free) 및 오프 폴리시(Off-Policy) 알고리즘인 이유 이해
- Q-러닝 업데이트 규칙 학습
핵심 개념
1. Q-러닝 (Q-Learning)
- 대표적인 모델 프리(Model-Free), 오프 폴리시(Off-Policy) 강화 학습 알고리즘입니다.
- 환경의 모델(상태 전이 확률, 보상 함수)을 알지 못해도 최적의 행동 가치 함수(Optimal Action-Value Function, Q*)를 학습할 수 있습니다.
- Q*를 학습함으로써 에이전트는 각 상태에서 어떤 행동을 취해야 누적 보상을 최대로 얻을 수 있는지 알게 됩니다.
2. 모델 프리 (Model-Free)
- 환경의 모델 P(s’|s, a) 및 R(s, a, s’)을 직접적으로 사용하거나 추정하지 않습니다.
- 대신, 에이전트가 환경과 직접 상호작용하며 얻는 경험(샘플)로부터 가치 함수를 학습합니다. (예: (s, a, r, s’) 튜플)
3. 오프 폴리시 (Off-Policy)
- 에이전트가 행동을 선택하는 데 사용하는 정책(행동 정책, Behavior Policy)과 평가하고 개선하려는 정책(타겟 정책, Target Policy)이 다를 수 있습니다.
- Q-러닝에서는 타겟 정책은 항상 탐욕적 정책(Greedy Policy)으로, 현재 학습된 Q 값에 대해 가장 높은 Q 값을 주는 행동을 선택합니다.
- 반면, 행동 정책은 탐험(Exploration)을 위해 ε-탐욕적 정책(ε-Greedy Policy) 등을 사용할 수 있습니다. 이를 통해 다양한 상태-행동 쌍을 경험하고 더 나은 Q 값을 학습할 기회를 얻습니다.
4. Q-러닝 업데이트 규칙 (Q-Learning Update Rule)
- Q-러닝은 시간차 학습(Temporal Difference Learning, TD Learning)의 한 형태입니다.
- 현재의 Q 값 추정치와 실제 관찰된 보상 및 다음 상태의 Q 값(TD 타겟) 간의 차이(TD 오차)를 이용하여 Q 값을 업데이트합니다.
- Q(St, At) ← Q(St, At) + α [Rt+1 + γ maxaQ(St+1, a) - Q(St, At)]
- St: 현재 상태
- At: 현재 상태에서 취한 행동
- Rt+1: 행동 At에 대한 보상
- St+1: 행동 At 이후의 다음 상태
- α (Learning Rate, 학습률): 0과 1 사이의 값으로, 새로운 정보를 얼마나 반영할지 결정합니다.
- γ (Discount Factor, 감가율): 미래 보상의 현재 가치를 나타냅니다.
- maxaQ(St+1, a): 다음 상태 St+1에서 가능한 모든 행동 a에 대한 Q 값 중 최댓값. 이것이 오프 폴리시 특성을 나타내는 부분으로, 다음 행동을 실제로 어떤 정책으로 선택했든 상관없이 최적 정책(탐욕 정책)을 가정하고 업데이트합니다.
- [Rt+1 + γ maxaQ(St+1, a)]: TD 타겟. 현재 추정하는 Q(St, At)의 목표값입니다.
- [Rt+1 + γ maxaQ(St+1, a) - Q(St, At)]: TD 오차(TD Error).
5. Q-러닝 알고리즘 (Q-Learning Algorithm)
- 모든 상태-행동 쌍 (s, a)에 대해 Q(s, a)를 임의의 값으로 초기화 (보통 0 또는 작은 무작위 값). 터미널 상태의 Q 값은 0으로 초기화.
- 각 에피소드에 대해 다음을 반복: a. 초기 상태 S를 관찰. b. 에피소드가 끝날 때까지 다음을 반복 (S가 터미널 상태가 아닐 동안): i. 현재 상태 S에서 행동 정책(예: ε-탐욕 정책)에 따라 행동 A를 선택. ii. 행동 A를 수행하고, 보상 R과 다음 상태 S’를 관찰. iii. Q(S, A) ← Q(S, A) + α [R + γ maxa’Q(S’, a’) - Q(S, A)] 를 사용하여 Q 값을 업데이트. iv. S ← S’ (상태를 다음 상태로 업데이트).
6. 수렴 조건
- 학습률 α가 적절히 감소하고, 모든 상태-행동 쌍을 무한히 많이 방문하면 Q(s, a)는 최적 행동 가치 함수 Q*(s, a)로 수렴하는 것이 보장됩니다.
추가 학습 자료
다음 학습 내용
- Day 58: Q-러닝 - 간단한 구현 (Q-Learning - Simple Implementation)
Day 58: Q-러닝 - 간단한 구현 (Q-Learning - Simple Implementation)
학습 목표
- 간단한 환경(예: 그리드 월드)에서 Q-러닝 알고리즘을 파이썬으로 구현
- Q-테이블의 개념과 활용 이해
- ε-탐욕 정책(Epsilon-Greedy Policy) 구현
예제 환경: 간단한 그리드 월드 (Simple Grid World)
- 1xN 또는 MxN 형태의 격자 세계.
- 에이전트는 각 셀(상태)에서 상, 하, 좌, 우 등으로 이동(행동)할 수 있습니다.
- 특정 셀에는 장애물이나 목표 지점이 있을 수 있으며, 이에 따라 보상이 주어집니다.
- 예: 1x5 그리드 월드
[S, F, F, F, G]- S: 시작 지점
- F: 일반 필드 (이동 시 작은 음수 보상 또는 0 보상)
- G: 목표 지점 (도달 시 큰 양수 보상, 에피소드 종료)
- 벽을 벗어나려는 행동은 제자리걸음으로 처리하고 음수 보상을 줄 수 있습니다.
Q-테이블 (Q-Table)
- Q-러닝에서 Q(s, a) 값을 저장하는 테이블 (보통 2차원 배열 또는 딕셔너리).
- 행은 상태(States), 열은 행동(Actions)을 나타냅니다.
Q_table[state][action]은 해당 상태에서 해당 행동을 취했을 때의 Q 값을 의미합니다.- 환경이 단순하고 상태와 행동 공간이 작을 때 유용합니다.
ε-탐욕 정책 (Epsilon-Greedy Policy)
- 탐험(Exploration)과 활용(Exploitation) 사이의 균형을 맞추기 위한 정책.
- 활용: 현재까지 학습된 Q 값 중 가장 높은 값을 주는 행동을 선택 (Greedy action).
- 탐험: 무작위로 행동을 선택하여 새로운 경험을 쌓고, 더 나은 정책을 발견할 가능성을 높임.
- 알고리즘:
- 0과 1 사이의 무작위 수
rand를 생성합니다. rand < ε이면 (확률 ε로):- 가능한 행동 중 하나를 무작위로 선택 (탐험).
- 그렇지 않으면 (
rand ≥ ε이면, 확률 1-ε로):- 현재 상태에서 Q 값이 가장 높은 행동을 선택 (활용).
- 0과 1 사이의 무작위 수
- ε 값은 보통 학습 초반에는 높게 설정하여 탐험을 장려하고, 학습이 진행됨에 따라 점차 낮추어 활용에 집중하도록 합니다 (ε-decay).
파이썬 구현 개요 (슈도코드 스타일)
import numpy as np
# 환경 설정
# 예: 1x5 그리드 월드
# 상태: 0, 1, 2, 3, 4 (S, F, F, F, G)
# 행동: 0 (왼쪽), 1 (오른쪽)
# 보상: 목표 도달 +1, 그 외 0 (간단화)
num_states = 5
num_actions = 2
# Q-테이블 초기화
q_table = np.zeros((num_states, num_actions))
# 하이퍼파라미터
learning_rate = 0.1 # 학습률 (α)
discount_factor = 0.9 # 감가율 (γ)
epsilon = 1.0 # 초기 epsilon 값
max_epsilon = 1.0 # 최대 epsilon 값
min_epsilon = 0.01 # 최소 epsilon 값
epsilon_decay_rate = 0.001 # epsilon 감쇠율
num_episodes = 1000
# 보상 정의 (간단화)
# rewards = { (state, action, next_state): reward_value }
# 또는 함수로 정의: get_reward(state, action, next_state)
# 여기서는 간단하게 목표 상태 도달 시 +1
goal_state = 4
# Q-러닝 알고리즘
for episode in range(num_episodes):
state = 0 # 시작 상태 (S)
done = False
while not done:
# Epsilon-greedy 행동 선택
exploration_exploitation_tradeoff = np.random.uniform(0, 1)
if exploration_exploitation_tradeoff < epsilon:
action = np.random.choice(num_actions) # 탐험: 무작위 행동 선택
else:
action = np.argmax(q_table[state, :]) # 활용: Q값이 가장 높은 행동 선택
# 행동 수행 및 다음 상태, 보상 관찰 (환경과의 상호작용)
# 이 부분은 환경 모델에 따라 달라짐
if action == 0: # 왼쪽
next_state = max(0, state - 1)
else: # 오른쪽
next_state = min(num_states - 1, state + 1)
reward = 0
if next_state == goal_state:
reward = 1
done = True
# Q-테이블 업데이트
q_table[state, action] = q_table[state, action] + learning_rate * \
(reward + discount_factor * np.max(q_table[next_state, :]) - q_table[state, action])
state = next_state
# Epsilon 감쇠
epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-epsilon_decay_rate * episode)
print("학습된 Q-테이블:")
print(q_table)
# 학습된 정책 테스트
state = 0
path = [state]
while state != goal_state:
action = np.argmax(q_table[state, :])
if action == 0:
state = max(0, state - 1)
else:
state = min(num_states - 1, state + 1)
path.append(state)
if len(path) > 10: # 무한 루프 방지
print("경로를 찾지 못함 또는 너무 김")
break
print("최적 경로 (추정):", path)
고려 사항
- 환경 표현: 실제 구현에서는 환경을 클래스 등으로 더 잘 구조화할 수 있습니다 (예:
step(action)함수를 통해next_state, reward, done, info반환). OpenAI Gym과 유사한 인터페이스를 고려할 수 있습니다. - 보상 설계: 보상을 어떻게 설계하느냐에 따라 에이전트의 학습 결과가 크게 달라집니다.
- 하이퍼파라미터 튜닝:
learning_rate,discount_factor,epsilon관련 값들은 문제와 환경에 따라 적절히 조절해야 합니다. - 수렴: 간단한 문제에서는 Q-테이블이 최적 값으로 빠르게 수렴할 수 있지만, 복잡한 문제에서는 많은 에피소드가 필요할 수 있습니다.
추가 학습 자료
- Q-Learning Example with Python (Towards Data Science)
- OpenAI Gym FrozenLake Q-Learning (YouTube) (Gym 환경에서의 예시)
다음 학습 내용
- Day 59: 심층 Q-네트워크 (DQN) - 개념 및 장점 (Deep Q-Networks (DQN) - Concept and Advantages)
Day 59: 심층 Q-네트워크 (DQN) - 개념 및 장점 (Deep Q-Networks (DQN) - Concept and Advantages)
학습 목표
- 전통적인 Q-러닝의 한계점 이해
- 심층 Q-네트워크(DQN)의 기본 아이디어와 구성 요소 학습
- DQN이 Q-테이블 대신 신경망을 사용하는 이유와 장점 이해
- DQN의 주요 기법(경험 재현, 타겟 네트워크) 소개
전통적인 Q-러닝의 한계점
-
상태 공간의 저주 (Curse of Dimensionality):
- Q-테이블은 상태와 행동의 모든 가능한 조합에 대한 Q 값을 저장해야 합니다.
- 상태 공간이나 행동 공간이 매우 커지면 (예: 연속적인 상태 공간, 고차원 이미지 입력), Q-테이블을 유지하고 업데이트하는 데 필요한 메모리와 계산량이 기하급수적으로 증가하여 현실적으로 불가능해집니다.
- 예: 아타리 게임의 경우, 화면 픽셀 하나하나를 상태로 간주하면 상태 공간이 엄청나게 커집니다.
-
일반화 능력 부족:
- Q-테이블은 각 상태-행동 쌍에 대한 Q 값을 개별적으로 학습합니다.
- 따라서, 비슷한 상태들에 대한 정보를 일반화하여 활용하기 어렵습니다. 방문해보지 않은 상태에 대해서는 Q 값을 추정할 수 없습니다.
심층 Q-네트워크 (Deep Q-Network, DQN)
- 2013년 DeepMind에서 제안하고, 2015년 Nature에 발표된 알고리즘으로, 심층 신경망(Deep Neural Network)을 사용하여 Q-함수를 근사(approximate)합니다.
- Q-테이블 대신 신경망
Q(s, a; θ)를 사용하여, 상태s를 입력으로 받아 각 행동a에 대한 Q 값을 출력하거나, 상태s와 행동a를 입력으로 받아 해당 Q 값을 출력합니다. (일반적으로 전자를 많이 사용)θ는 신경망의 가중치(weights)를 나타냅니다.
- 이를 통해 Q-러닝을 고차원의 상태 공간(예: 이미지 입력)을 가진 문제에 적용할 수 있게 되었습니다.
DQN의 기본 아이디어
- 신경망을 사용하여 Q-함수를 근사:
Q(s, a; θ) ≈ Q*(s, a) - 손실 함수(Loss Function)를 정의하고, 경사 하강법(Gradient Descent)을 사용하여 신경망의 가중치
θ를 업데이트합니다. - 손실 함수는 Q-러닝의 업데이트 규칙에서 TD 오차와 유사하게 정의됩니다:
L(θ) = E(s,a,r,s’)~D [ ( r + γ maxa’Q(s’, a’; θ-) - Q(s, a; θ) )2 ]
θ: 현재 Q-네트워크의 가중치θ<sup>-</sup>: 타겟 Q-네트워크의 가중치 (아래 설명 참조)D: 경험 재현 메모리 (아래 설명 참조)r + γ max<sub>a'</sub>Q(s', a'; θ<sup>-</sup>): TD 타겟 (목표값)Q(s, a; θ): 현재 Q-네트워크의 예측값
DQN의 장점
- 고차원 입력 처리: 이미지를 직접 입력으로 받아 처리하는 등 복잡하고 큰 상태 공간을 다룰 수 있습니다. (예: Convolutional Neural Networks, CNN 사용)
- 일반화 성능: 신경망은 학습된 데이터로부터 패턴을 학습하여, 이전에 방문하지 않은 유사한 상태에 대해서도 Q 값을 추정할 수 있는 일반화 능력을 가집니다.
- 메모리 효율성: 거대한 Q-테이블을 저장하는 대신, 상대적으로 작은 크기의 신경망 가중치만 저장하면 됩니다.
DQN의 주요 기법
1. 경험 재현 (Experience Replay)
- 에이전트가 환경과 상호작용하며 얻는 경험 샘플
(s_t, a_t, r_{t+1}, s_{t+1})을 리플레이 메모리(Replay Memory)D에 저장합니다. - 신경망 학습 시, 리플레이 메모리에서 미니배치(mini-batch)를 무작위로 샘플링하여 사용합니다.
- 장점:
- 데이터 효율성 향상: 하나의 경험 샘플이 여러 번의 학습에 사용될 수 있습니다.
- 샘플 간의 상관관계 감소: 순차적으로 들어오는 데이터는 시간적 상관관계가 높아 학습을 불안정하게 만들 수 있습니다. 무작위 샘플링은 이러한 상관관계를 줄여 학습 안정성을 높입니다.
- 학습 안정성: 특정 패턴의 데이터가 연속적으로 들어오는 것을 방지하여 학습이 특정 방향으로 치우치는 것을 막아줍니다.
2. 타겟 네트워크 분리 (Separate Target Network)
- Q-러닝 업데이트 시 TD 타겟
y_i = r + γ max<sub>a'</sub>Q(s', a'; θ)을 계산할 때, 현재 Q-값을 예측하는 네트워크와 동일한 네트워크를 사용하면 학습이 불안정해질 수 있습니다.- Q-값을 업데이트하면 TD 타겟도 함께 변하게 되어, 학습 목표가 계속 흔들리는 문제가 발생합니다 (Moving Target Problem).
- 해결책: 두 개의 신경망을 사용합니다.
- 메인 네트워크 (Main Network, Q-Network):
Q(s, a; θ). 주로 학습(가중치 업데이트)이 이루어지는 네트워크. - 타겟 네트워크 (Target Network):
Q(s', a'; θ<sup>-</sup>). TD 타겟을 계산하는 데 사용되는 네트워크.- 타겟 네트워크의 가중치
θ<sup>-</sup>는 주기적으로 메인 네트워크의 가중치θ로 복사되어 업데이트됩니다 (예: 매 C 스텝마다). - 타겟 네트워크는 학습 과정에서 고정되어 있어 TD 타겟값을 안정적으로 유지시켜 학습 안정성을 높입니다.
- 타겟 네트워크의 가중치
- 메인 네트워크 (Main Network, Q-Network):
DQN 알고리즘 개요
- 리플레이 메모리 D를 특정 크기로 초기화.
- 행동-가치 함수 Q를 무작위 가중치 θ로 초기화 (메인 네트워크).
- 타겟 행동-가치 함수 Q̂를 가중치 θ- = θ로 초기화 (타겟 네트워크).
- 각 에피소드에 대해: a. 초기 상태 s1을 관찰. b. 에피소드가 끝날 때까지 (t=1 부터 T까지): i. ε-탐욕 정책에 따라 행동 at를 선택 (Q(st, · ; θ) 사용). ii. 행동 at를 수행하고, 보상 rt+1과 다음 상태 st+1을 관찰. iii. 경험 (st, at, rt+1, st+1)을 D에 저장. iv. D에서 미니배치 (sj, aj, rj+1, sj+1)를 무작위로 샘플링. v. 타겟 yj 설정: - 만약 sj+1이 터미널 상태이면, yj = rj+1. - 그렇지 않으면, yj = rj+1 + γ maxa’Q̂(sj+1, a’; θ-). vi. 손실 (yj - Q(sj, aj; θ))2 에 대해 경사 하강법을 수행하여 메인 네트워크 가중치 θ 업데이트. vii. 매 C 스텝마다 타겟 네트워크 가중치 업데이트: θ- ← θ.
추가 학습 자료
- DeepMind Nature Paper (2015) - Human-level control through deep reinforcement learning
- Playing Atari with Deep Reinforcement Learning (NIPS 2013 Workshop Paper)
- [DQN Explained - Let’s Code DQN (YouTube by SimpleAI)](https://www.youtube.com/watch?v= নারদ7377&list=PLZbbT5o_s2xobby-M9D9sRehVjjYmS3ob&index=2)
다음 학습 내용
- Day 60: 자연어 처리 소개 (Introduction to Natural Language Processing)
Day 60: 자연어 처리 소개 (Introduction to Natural Language Processing, NLP)
학습 목표
- 자연어 처리(NLP)의 정의와 중요성 이해
- NLP의 주요 응용 분야 파악
- NLP의 주요 과제 및 어려움 인식
- NLP의 기본 용어(코퍼스, 토큰, 형태소, 어휘, 문법 등) 학습
핵심 개념
1. 자연어 처리 (Natural Language Processing, NLP)
- 인간이 사용하는 언어(자연어)를 컴퓨터가 이해하고, 해석하고, 생성할 수 있도록 하는 인공지능(AI) 및 언어학의 한 분야입니다.
- 목표는 컴퓨터와 인간 사이의 자연스러운 의사소통을 가능하게 하고, 대량의 텍스트 데이터로부터 의미 있는 정보를 추출하는 것입니다.
2. NLP의 중요성
- 정보 과잉 시대: 웹, 소셜 미디어, 문서 등 방대한 양의 텍스트 데이터가 생성되고 있으며, NLP는 이로부터 가치 있는 정보를 추출하고 활용하는 데 필수적입니다.
- 인간-컴퓨터 상호작용 개선: 음성 비서, 챗봇 등과 같이 보다 자연스럽고 직관적인 방식으로 컴퓨터와 상호작용할 수 있게 합니다.
- 다양한 산업 응용: 검색 엔진, 번역, 고객 서비스, 의료, 금융, 법률 등 다양한 분야에서 활용됩니다.
3. NLP의 주요 응용 분야
- 기계 번역 (Machine Translation): 한 언어로 된 텍스트를 다른 언어로 자동 번역 (예: Google Translate, Papago).
- 정보 검색 (Information Retrieval): 대규모 문서 집합에서 사용자가 원하는 정보를 포함하는 문서를 찾는 기술 (예: 검색 엔진).
- 텍스트 분류 (Text Classification): 텍스트를 미리 정의된 카테고리로 분류 (예: 스팸 메일 필터링, 뉴스 기사 주제 분류, 감성 분석).
- 감성 분석 (Sentiment Analysis): 텍스트에 나타난 주관적인 의견, 감정, 태도 등을 분석 (예: 영화 리뷰 긍/부정 판단).
- 질의응답 시스템 (Question Answering, QA): 사용자의 질문에 대해 자연어로 답변하는 시스템 (예: 챗봇, AI 스피커).
- 텍스트 요약 (Text Summarization): 긴 문서의 핵심 내용을 간결하게 요약.
- 개체명 인식 (Named Entity Recognition, NER): 텍스트에서 인명, 지명, 기관명 등 고유한 의미를 갖는 개체명을 인식하고 분류.
- 음성 인식 (Speech Recognition): 사람의 음성을 텍스트로 변환.
- 텍스트 생성 (Text Generation): 특정 주제나 스타일에 맞춰 새로운 텍스트를 생성 (예: 기사 작성, 소설 창작).
4. NLP의 주요 과제 및 어려움
- 모호성 (Ambiguity):
- 어휘적 모호성: 하나의 단어가 여러 의미를 가짐 (예: “배” - 과일, 선박, 신체 부위).
- 구문적 모호성: 문장의 구조가 여러 가지로 해석될 수 있음 (예: “나는 예쁜 그녀의 친구를 보았다” - ’예쁜’이 ’그녀’를 수식하는지 ’친구’를 수식하는지).
- 의미적 모호성: 문맥에 따라 의미가 달라짐.
- 동의어 및 다의어 처리: 의미가 같거나 유사한 단어들, 여러 의미를 가진 단어들을 처리하는 문제.
- 신조어 및 비표준어: 끊임없이 생성되는 신조어나 오타, 비문법적인 표현 등을 처리하는 어려움.
- 문맥 의존성: 단어나 문장의 의미가 주변 문맥에 크게 의존.
- 세계 지식 및 상식의 부족: 컴퓨터는 인간처럼 세상에 대한 배경지식이나 상식을 가지고 있지 않음.
- 언어별 특성: 언어마다 문법 구조, 어순, 표현 방식 등이 매우 다름.
5. NLP 기본 용어
- 말뭉치 (Corpus, 복수형 Corpora): 특정 목적을 위해 수집된 대량의 텍스트 또는 음성 데이터 집합. NLP 모델 학습 및 평가에 사용됩니다.
- 토큰 (Token): 분석을 위해 텍스트를 더 작은 단위로 나눈 것. 일반적으로 단어, 문장 부호 등이 토큰이 될 수 있습니다.
- 토큰화 (Tokenization): 텍스트를 토큰 단위로 분리하는 과정.
- 형태소 (Morpheme): 의미를 가지는 가장 작은 언어 단위. (예: ‘읽다’ -> ‘읽-’ (어간), ‘-다’ (어미))
- 형태소 분석 (Morphological Analysis): 단어를 형태소 단위로 분해하고 각 형태소의 품사 정보를 부착하는 과정. 한국어 NLP에서 특히 중요합니다.
- 어휘 (Vocabulary / Lexicon): 특정 언어 또는 말뭉치에서 사용되는 모든 단어(또는 토큰)의 집합.
- 문법 (Grammar): 단어들이 결합하여 문장을 이루는 규칙.
- 구문 분석 (Parsing / Syntactic Analysis): 문장의 구조를 분석하여 문법적인 관계를 파악하는 과정. (예: 주어, 동사, 목적어 등)
- 의미 분석 (Semantic Analysis): 단어, 구, 문장의 의미를 이해하고 해석하는 과정.
추가 학습 자료
다음 학습 내용
- Day 61: 텍스트 전처리 - 토큰화, 어간 추출, 표제어 추출 (Text Preprocessing - Tokenization, Stemming, Lemmatization)
Day 61: 텍스트 전처리 (Text Preprocessing)
학습 목표
- 텍스트 전처리의 중요성과 목적 이해
- 주요 텍스트 전처리 기법 학습:
- 문장 분리 (Sentence Segmentation)
- 토큰화 (Tokenization)
- 정제 (Cleaning) 및 정규화 (Normalization)
- 불용어 제거 (Stopword Removal)
- 어간 추출 (Stemming)
- 표제어 추출 (Lemmatization)
1. 텍스트 전처리란?
- 자연어 텍스트를 분석 가능한 형태로 가공하고 정제하는 일련의 과정입니다.
- 목적:
- 분석의 정확도 향상
- 계산 효율성 증대
- 데이터의 일관성 유지
- 노이즈 제거
2. 주요 텍스트 전처리 기법
가. 문장 분리 (Sentence Segmentation / Sentence Tokenization)
- 텍스트를 개별 문장 단위로 분리하는 작업입니다.
- 문장 부호(마침표(.), 물음표(?), 느낌표(!)) 등을 기준으로 분리하지만, 예외 케이스(Dr., Mr., Ph.D. 등)를 고려해야 합니다.
- 파이썬 라이브러리:
NLTK의sent_tokenize
나. 토큰화 (Tokenization / Word Tokenization)
- 문장을 의미 있는 최소 단위인 토큰(주로 단어)으로 분리하는 작업입니다.
- 공백, 문장 부호 등을 기준으로 분리할 수 있습니다.
- 어절 단위 토큰화, 단어 단위 토큰화, 형태소 단위 토큰화 등 다양한 수준이 있습니다.
- 파이썬 라이브러리:
NLTK의word_tokenize,spaCy, 한국어의 경우KoNLPy(Okt, Mecab 등)
다. 정제 (Cleaning) 및 정규화 (Normalization)
- 텍스트에서 불필요하거나 분석에 방해가 되는 요소를 제거하고, 표현을 통일하는 과정입니다.
- 정제 (Cleaning):
- HTML 태그 제거 (예: 웹 크롤링 데이터)
- 특수 문자, 숫자, 이모티콘 등 제거 또는 대체
- 오타 수정
- 정규화 (Normalization):
- 대소문자 통일 (주로 소문자로 변환)
- 축약형 풀기 (예: “don’t” -> “do not”)
- 철자 변이 통일 (예: “color”, “colour” -> “color”)
- 숫자 표현 통일 (예: “1,000”, “one thousand” -> “1000”)
라. 불용어 제거 (Stopword Removal)
- 분석에 큰 의미가 없으면서 자주 등장하는 단어(불용어)를 제거하는 작업입니다.
- 예: “a”, “an”, “the”, “is”, “are”, “of”, “on”, “in” (영어) / “은”, “는”, “이”, “가”, “을”, “를” (한국어)
- 불용어 목록은 직접 정의하거나 라이브러리에서 제공하는 것을 사용할 수 있습니다.
- 파이썬 라이브러리:
NLTK의stopwords
마. 어간 추출 (Stemming)
- 단어의 어미(접미사)를 제거하여 어간(stem)만을 추출하는 과정입니다.
- 목적: 단어의 다양한 활용형을 동일한 형태로 통일하여 단어의 수를 줄이고 분석의 일관성을 높입니다.
- 규칙 기반으로 작동하며, 때로는 문법적으로 정확하지 않은 어간을 추출할 수 있습니다 (예: “running” -> “runn”, “flies” -> “fli”).
- 속도가 빠르다는 장점이 있습니다.
- 대표적인 알고리즘: 포터 스테머(Porter Stemmer), 랭커스터 스테머(Lancaster Stemmer)
- 파이썬 라이브러리:
NLTK의PorterStemmer,LancasterStemmer
바. 표제어 추출 (Lemmatization)
- 단어의 기본형, 즉 표제어(lemma)를 추출하는 과정입니다.
- 품사 정보와 문맥을 고려하여 단어의 사전적 기본형을 찾습니다. (예: “running” -> “run”, “flies” -> “fly”, “better” -> “good”)
- 어간 추출보다 문법적으로 정확한 결과를 제공하지만, 더 복잡하고 시간이 오래 걸릴 수 있습니다.
- 일반적으로 어간 추출보다 선호되나, 분석 목적과 성능 요구사항에 따라 선택합니다.
- 파이썬 라이브러리:
NLTK의WordNetLemmatizer,spaCy
3. 한국어 텍스트 전처리 특수성
- 형태소 분석의 중요성: 한국어는 교착어로, 어근에 접사가 붙어 단어의 의미와 문법적 기능이 결정됩니다. 따라서 단순 공백 토큰화보다는 형태소 분석기를 사용하여 명사, 동사, 형용사 등을 추출하는 것이 효과적입니다. (KoNLPy 라이브러리 활용)
- 띄어쓰기 오류: 한국어는 띄어쓰기가 틀려도 의미 전달이 되는 경우가 많아, 띄어쓰기 교정 작업이 필요할 수 있습니다.
- 다양한 어미 활용: 동사나 형용사의 활용형이 매우 다양하여 어간 추출이나 표제어 추출의 중요성이 큽니다.
4. 전처리 파이프라인 예시
- 텍스트 로드
- (선택적) 소문자화
- 문장 분리
- 각 문장에 대해: a. 토큰화 (단어 또는 형태소) b. (선택적) 정제 (특수문자 제거 등) c. (선택적) 불용어 제거 d. 어간 추출 또는 표제어 추출
- 전처리된 토큰 리스트 생성
추가 학습 자료
다음 학습 내용
- Day 62: Bag-of-Words 및 TF-IDF (Bag-of-Words and TF-IDF)
Day 62: Bag-of-Words 및 TF-IDF
학습 목표
- 텍스트 데이터를 수치 벡터로 변환하는 기법 학습
- Bag-of-Words (BoW) 모델의 개념과 구현 방법 이해
- TF-IDF (Term Frequency-Inverse Document Frequency)의 개념과 계산 방법, 중요성 이해
1. 텍스트 표현 (Text Representation)의 필요성
- 머신러닝 알고리즘은 대부분 숫자 입력을 가정합니다.
- 따라서, 텍스트 데이터를 분석하고 모델링하기 위해서는 텍스트를 수치적인 형태로 변환하는 과정이 필요합니다. 이를 텍스트 표현 또는 특징 벡터화(Feature Vectorization)라고 합니다.
2. Bag-of-Words (BoW)
가. 개념
- 가장 간단하면서도 널리 사용되는 텍스트 표현 방법 중 하나입니다.
- 문서를 단어들의 “가방“으로 간주합니다. 즉, 단어의 순서나 문맥은 무시하고, 문서 내 각 단어의 출현 빈도수(Term Frequency)에만 집중합니다.
- 각 문서는 고유한 단어들의 집합(어휘, Vocabulary)을 기준으로, 해당 단어가 문서에 몇 번 등장했는지를 나타내는 벡터로 표현됩니다.
나. BoW 구축 과정
- 토큰화 (Tokenization): 각 문서를 단어(토큰) 단위로 분리합니다.
- 어휘 구축 (Vocabulary Building): 전체 문서 집합(Corpus)에 등장하는 모든 고유한 단어들의 집합을 만듭니다. 이 어휘집이 벡터의 차원이 됩니다.
- 벡터화 (Vectorization): 각 문서를 어휘집의 단어 순서대로 정렬된 벡터로 표현합니다. 벡터의 각 요소는 해당 단어가 해당 문서에 등장한 횟수(빈도수)를 나타냅니다.
다. 예시
- 문서 1: “John likes to watch movies. Mary likes movies too.”
- 문서 2: “John also likes to watch football games.”
-
토큰화 및 정제 (소문자화, 구두점 제거 등 가정)
- 문서 1 토큰:
["john", "likes", "to", "watch", "movies", "mary", "likes", "movies", "too"] - 문서 2 토큰:
["john", "also", "likes", "to", "watch", "football", "games"]
- 문서 1 토큰:
-
어휘 구축
- 전체 어휘:
{"john", "likes", "to", "watch", "movies", "mary", "too", "also", "football", "games"} - (정렬된 어휘) ->
["also", "football", "games", "john", "likes", "mary", "movies", "to", "too", "watch"](10차원 벡터)
- 전체 어휘:
-
벡터화 (단어 빈도수 기준)
- 문서 1 벡터:
[0, 0, 0, 1, 2, 1, 2, 1, 1, 1]- (also:0, football:0, games:0, john:1, likes:2, mary:1, movies:2, to:1, too:1, watch:1)
- 문서 2 벡터:
[1, 1, 1, 1, 1, 0, 0, 1, 0, 1]- (also:1, football:1, games:1, john:1, likes:1, mary:0, movies:0, to:1, too:0, watch:1)
- 문서 1 벡터:
라. 장점
- 구현이 간단하고 이해하기 쉽습니다.
- 텍스트 분류, 정보 검색 등 다양한 NLP 작업에서 기본적으로 사용될 수 있습니다.
마. 단점
- 단어 순서 무시: 문맥 정보를 잃어버려 의미 파악에 한계가 있습니다. (예: “I hate you” vs “You hate I“는 동일한 BoW 벡터를 가질 수 있음)
- 희소성 문제 (Sparsity): 어휘집의 크기가 매우 커지면 대부분의 값이 0인 희소 벡터(Sparse Vector)가 생성되어 계산 비효율성 및 성능 저하를 유발할 수 있습니다.
- 불용어 문제: “the”, “a“와 같이 자주 등장하지만 의미는 적은 단어들이 높은 빈도수를 가질 수 있습니다. (TF-IDF로 일부 보완 가능)
- 단어의 의미적 유사성 반영 불가: “car“와 “automobile“은 다른 단어로 취급됩니다.
바. 파이썬 구현
scikit-learn의CountVectorizer사용
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'John likes to watch movies. Mary likes movies too.',
'John also likes to watch football games.'
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names_out())
# ['also', 'football', 'games', 'john', 'likes', 'mary', 'movies', 'to', 'too', 'watch']
print(X.toarray())
# [[0 1 1 1 2 1 2 1 1] <- 오타 수정: 실제 출력은 위 예시와 같아야 함
# [1 1 1 1 1 0 0 1 0 1]]
3. TF-IDF (Term Frequency - Inverse Document Frequency)
가. 개념
- BoW의 단점을 보완하기 위해 등장한 가중치 부여 방식입니다.
- 단순히 단어의 빈도수만 고려하는 것이 아니라, 특정 단어가 한 문서에 얼마나 자주 등장하는지(TF)와 함께, 그 단어가 전체 문서 집합에서 얼마나 희귀한지(IDF)를 고려하여 단어의 중요도를 계산합니다.
- 즉, 한 문서 내에서는 자주 등장하지만 다른 여러 문서에서는 잘 등장하지 않는 단어일수록 중요도가 높다고 판단합니다.
나. TF (Term Frequency, 단어 빈도)
- 특정 단어가 특정 문서 내에 얼마나 자주 등장하는지를 나타내는 값입니다.
- 계산 방법은 다양하지만, 가장 기본적인 방법은 해당 단어의 등장 횟수입니다.
TF(t, d)= (문서 d에서 단어 t의 등장 횟수) / (문서 d의 전체 단어 수) (정규화된 TF)- 또는 단순히
TF(t, d)= (문서 d에서 단어 t의 등장 횟수)
다. IDF (Inverse Document Frequency, 역문서 빈도)
- 특정 단어가 전체 문서 집합에서 얼마나 드물게 등장하는지를 나타내는 값입니다.
- 이 값이 클수록 해당 단어는 특정 문서의 주제를 잘 나타내는 희귀한 단어일 가능성이 높습니다.
IDF(t, D)= log ( (전체 문서 수) / (단어 t를 포함하는 문서 수 + 1) )- 분모에 1을 더하는 것은 특정 단어가 모든 문서에 등장하지 않아 0으로 나누어지는 것을 방지하기 위함입니다 (Smoothing).
- 로그를 취하는 이유는 문서 수의 차이가 극심할 때 값의 스케일을 줄여주기 위함입니다.
라. TF-IDF 계산
TF-IDF(t, d, D) = TF(t, d) * IDF(t, D)- TF-IDF 값은 특정 문서 d 내에서 특정 단어 t의 중요도를 나타냅니다.
- 이 값을 사용하여 BoW 벡터를 구성하면, 단순히 빈도수만 사용했을 때보다 단어의 중요도를 더 잘 반영하는 텍스트 표현을 얻을 수 있습니다.
마. 장점
- BoW에 비해 단어의 중요도를 더 잘 반영할 수 있습니다.
- 모든 문서에 자주 등장하는 불용어의 영향력을 줄일 수 있습니다 (IDF 값이 낮아짐).
바. 단점
- 여전히 단어의 순서나 문맥 정보를 반영하지 못합니다.
- 단어의 의미적 유사성은 고려하지 못합니다.
사. 파이썬 구현
scikit-learn의TfidfVectorizer사용
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'John likes to watch movies. Mary likes movies too.',
'John also likes to watch football games.'
]
tfidf_vectorizer = TfidfVectorizer()
X_tfidf = tfidf_vectorizer.fit_transform(corpus)
print(tfidf_vectorizer.get_feature_names_out())
print(X_tfidf.toarray())
추가 학습 자료
다음 학습 내용
- Day 63: 단어 임베딩 - Word2Vec, GloVe (개념) (Word Embeddings - Word2Vec, GloVe (Conceptual))
Day 63: 단어 임베딩 - Word2Vec, GloVe (개념) (Word Embeddings - Word2Vec, GloVe (Conceptual))
학습 목표
- 기존 텍스트 표현 방식(BoW, TF-IDF)의 한계점 재확인
- 단어 임베딩(Word Embedding)의 개념과 필요성 이해
- 분산 표현(Distributed Representation)의 의미 학습
- 대표적인 단어 임베딩 모델인 Word2Vec과 GloVe의 기본 아이디어 및 특징 비교
1. 기존 텍스트 표현 방식의 한계
- BoW, TF-IDF:
- 희소 표현 (Sparse Representation): 어휘집 크기가 커지면 벡터가 매우 희소해지고 차원이 커집니다.
- 단어 의미 반영 부족: 단어 간의 의미적 유사성이나 관계를 파악하기 어렵습니다. (예: “강아지“와 “개“는 서로 다른 단어로 취급)
- 문맥 정보 손실: 단어의 순서나 주변 단어와의 관계를 고려하지 않습니다.
2. 단어 임베딩 (Word Embedding)이란?
- 단어를 고정된 크기의 **저차원 실수 벡터(Dense Vector)**로 표현하는 기법입니다.
- 각 단어는 벡터 공간의 한 점으로 매핑되며, 이 벡터를 **임베딩 벡터(Embedding Vector)**라고 합니다.
- 핵심 아이디어: “비슷한 의미를 가진 단어는 벡터 공간에서 서로 가까이 위치한다.”
- 단어의 의미를 벡터에 함축적으로 담아내려고 시도합니다.
분산 표현 (Distributed Representation)
- 단어 임베딩은 단어의 의미를 여러 차원에 분산하여 표현합니다.
- 벡터의 각 차원이 특정 의미적 또는 문법적 특징을 나타내는 것은 아니지만, 전체적으로 단어의 의미를 포착합니다.
- 예: “king” - “man” + “woman” ≈ “queen” 과 같은 단어 간의 의미론적 관계를 벡터 연산으로 표현 가능.
단어 임베딩의 장점
- 차원 축소: 고차원의 희소 벡터 대신 저차원의 밀집 벡터를 사용하므로 계산 효율성이 높습니다.
- 의미적 유사도 반영: 의미가 유사한 단어들은 벡터 공간에서 가까운 거리에 위치하게 되어 단어 간 관계를 파악할 수 있습니다.
- 일반화 성능 향상: 모델이 학습 데이터에 없는 단어와 유사한 의미의 단어를 처리하는 데 도움을 줄 수 있습니다.
- 다양한 NLP 작업 성능 향상: 텍스트 분류, 기계 번역, 감성 분석 등에서 성능 향상을 가져옵니다.
3. Word2Vec (Word to Vector)
가. 기본 아이디어
- 2013년 Google의 Mikolov 등이 제안한 신경망 기반의 단어 임베딩 모델입니다.
- “주변 단어가 비슷하면 해당 단어의 의미도 비슷할 것이다” 라는 분포 가설(Distributional Hypothesis)에 기반합니다.
- 특정 단어 주변에 나타나는 단어들을 예측하거나, 주변 단어들로부터 특정 단어를 예측하는 과정에서 단어의 임베딩 벡터를 학습합니다.
나. 주요 모델 구조
-
CBOW (Continuous Bag-of-Words):
- 주변 단어들(Context Words)이 주어졌을 때, 중심 단어(Center Word)를 예측하는 모델입니다.
- 여러 주변 단어의 임베딩 벡터를 사용하여 중심 단어의 임베딩 벡터를 예측합니다.
- 작은 데이터셋에서 성능이 좋고 학습 속도가 빠릅니다.
 (이미지 출처: Wikidocs)
(이미지 출처: Wikidocs) -
Skip-gram:
- 중심 단어(Center Word)가 주어졌을 때, 주변 단어들(Context Words)을 예측하는 모델입니다.
- 하나의 중심 단어 임베딩 벡터를 사용하여 여러 주변 단어의 임베딩 벡터를 예측합니다.
- 일반적으로 CBOW보다 성능이 우수하며, 특히 등장 빈도가 낮은 단어에 대해 더 잘 학습합니다.
- 학습 시간이 CBOW보다 오래 걸립니다.
 (이미지 출처: Wikidocs)
(이미지 출처: Wikidocs)
다. 학습 방식 (간략히)
- 입력층, 은닉층(투사층, Projection Layer), 출력층으로 구성된 얕은 신경망(Shallow Neural Network)을 사용합니다.
- 은닉층의 가중치가 바로 단어의 임베딩 벡터가 됩니다.
- 실제로는 계산 효율성을 위해 Negative Sampling이나 Hierarchical Softmax와 같은 최적화 기법을 사용합니다.
4. GloVe (Global Vectors for Word Representation)
가. 기본 아이디어
- 2014년 Stanford 대학에서 제안한 단어 임베딩 모델입니다.
- Word2Vec과 달리, 전체 말뭉치(Corpus)의 단어 동시 등장 빈도 행렬(Word Co-occurrence Matrix) 정보를 직접 사용하여 단어 임베딩을 학습합니다.
- “단어 간의 동시 등장 빈도 비율이 의미적 관계를 나타낸다“는 직관에 기반합니다.
- 예: “ice“는 “solid“와 자주 함께 등장하지만 “gas“와는 덜 등장하고, “steam“은 “gas“와 자주 함께 등장하지만 “solid“와는 덜 등장합니다. 이러한 비율 관계를 학습합니다.
나. 학습 방식 (간략히)
-
단어 동시 등장 빈도 행렬 구축:
- 전체 말뭉치에서 특정 윈도우 크기 내에 두 단어가 함께 등장한 횟수를 계산하여 행렬을 만듭니다.
- Xij: 단어 i의 문맥에 단어 j가 등장한 횟수.
-
손실 함수 설계:
- 임베딩된 단어 벡터 간의 내적(Dot Product)이 두 단어의 동시 등장 빈도 로그값과 유사해지도록 학습합니다.
- wiTw̃j + bi + b̃j ≈ log(Xij)
- wi: 중심 단어 i의 임베딩 벡터
- w̃j: 주변 단어 j의 임베딩 벡터 (별도의 임베딩 행렬 사용)
- bi, b̃j: 각 단어의 편향(bias) 항
- 가중치 함수 f(Xij)를 사용하여 등장 빈도가 낮은 단어에 과도하게 가중치가 부여되거나, 매우 높은 단어에 과도하게 가중치가 부여되는 것을 방지합니다.
다. 특징
- 전역적 통계 정보 활용: 말뭉치 전체의 통계 정보를 직접적으로 활용하여 학습합니다.
- 학습 속도: Word2Vec보다 학습 속도가 빠를 수 있습니다.
- 성능: 종종 Word2Vec과 유사하거나 더 나은 성능을 보이며, 특히 작은 데이터셋에서 강점을 가질 수 있습니다.
5. Word2Vec vs GloVe
| 특징 | Word2Vec (Skip-gram) | GloVe |
|---|---|---|
| 기본 아이디어 | 지역적 문맥 정보 (Local context window) | 전역적 동시 등장 통계 (Global co-occurrence counts) |
| 학습 방식 | 주변 단어 예측 (Predictive) | 동시 등장 행렬 분해 (Count-based / Matrix Factorization) |
| 장점 | 다양한 크기의 데이터셋에서 잘 작동, 의미론적 관계 포착 우수 | 학습 속도가 빠를 수 있음, 전역적 통계 정보 명시적 활용 |
| 단점 | 말뭉치 전체 통계 정보를 간접적으로만 활용, 학습 시간 소요 | 큰 메모리 필요 (동시 등장 행렬), 하이퍼파라미터 튜닝 민감 가능 |
- 실제로는 두 모델 모두 좋은 성능을 보이며, 문제나 데이터셋의 특성에 따라 선택적으로 사용되거나, 사전 훈련된 임베딩(Pre-trained Embeddings)을 활용하는 경우가 많습니다.
추가 학습 자료
- Word2Vec Tutorial - The Skip-Gram Model (Chris McCormick)
- GloVe: Global Vectors for Word Representation (Project Page)
- 딥 러닝을 이용한 자연어 처리 입문 - Word2Vec, GloVe
다음 학습 내용
- Day 64: Word2Vec 구현 (Implementing Word2Vec (e.g., using Gensim))
Day 64: Word2Vec 구현 (Implementing Word2Vec (e.g., using Gensim))
학습 목표
- 파이썬 라이브러리
Gensim을 사용하여 Word2Vec 모델을 학습시키는 방법 이해 - Word2Vec 모델의 주요 하이퍼파라미터 설정 및 의미 파악
- 학습된 임베딩 벡터를 확인하고 단어 간 유사도를 측정하는 방법 학습
1. Gensim 라이브러리 소개
Gensim은 토픽 모델링(Topic Modeling)과 자연어 처리(NLP)를 위한 강력하고 효율적인 파이썬 라이브러리입니다.- Word2Vec, FastText, Doc2Vec 등 다양한 단어 및 문서 임베딩 알고리즘을 쉽게 구현하고 사용할 수 있도록 지원합니다.
- 대용량 텍스트 데이터 처리에 최적화되어 있습니다.
Gensim 설치
pip install gensim
필요에 따라 nltk (토큰화 등 전처리)도 함께 설치합니다.
pip install nltk
2. Word2Vec 학습 과정 (Gensim 사용)
가. 데이터 준비 및 전처리
- Word2Vec 모델을 학습시키기 위해서는 토큰화된 문장들의 리스트가 필요합니다.
- 각 문장은 단어(토큰)들의 리스트 형태여야 합니다.
- 예:
sentences = [['this', 'is', 'the', 'first', 'sentence'], ['this', 'is', 'the', 'second', 'sentence']]
import nltk
from nltk.tokenize import sent_tokenize, word_tokenize
# nltk.download('punkt') # 처음 실행 시 필요할 수 있음
# 예제 텍스트 데이터 (실제로는 더 큰 코퍼스를 사용)
corpus_text = """
Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence.
It is concerned with the interactions between computers and human language.
In particular, how to program computers to process and analyze large amounts of natural language data.
Challenges in natural language processing frequently involve speech recognition, natural language understanding, and natural language generation.
"""
# 1. 문장 분리
raw_sentences = sent_tokenize(corpus_text)
# print(raw_sentences)
# 2. 각 문장을 단어 리스트로 토큰화 및 소문자화 (간단한 전처리)
sentences = []
for raw_sentence in raw_sentences:
tokens = [word.lower() for word in word_tokenize(raw_sentence) if word.isalpha()] # 알파벳만 남기고 소문자화
if tokens: # 빈 리스트가 아닐 경우에만 추가
sentences.append(tokens)
print("전처리된 문장 리스트:")
for s in sentences:
print(s)
# 출력 예시:
# ['natural', 'language', 'processing', 'nlp', 'is', 'a', 'subfield', 'of', 'linguistics', 'computer', 'science', 'and', 'artificial', 'intelligence']
# ['it', 'is', 'concerned', 'with', 'the', 'interactions', 'between', 'computers', 'and', 'human', 'language']
# ...
나. Word2Vec 모델 학습
gensim.models.Word2Vec클래스를 사용합니다.
from gensim.models import Word2Vec
# Word2Vec 모델 학습
# 주요 하이퍼파라미터:
# - sentences: 학습에 사용할 토큰화된 문장 리스트
# - vector_size: 임베딩 벡터의 차원 (예: 100, 200, 300)
# - window: 컨텍스트 윈도우 크기 (중심 단어 기준 앞뒤로 고려할 단어 수)
# - min_count: 모델 학습에 포함할 단어의 최소 등장 빈도 (이 값보다 적게 등장한 단어는 무시)
# - workers: 학습에 사용할 CPU 코어 수 (병렬 처리)
# - sg: 학습 알고리즘 선택 (0: CBOW, 1: Skip-gram)
# - hs: (0: Negative Sampling, 1: Hierarchical Softmax) - Negative Sampling이 주로 사용됨
# - negative: Negative Sampling 시 사용할 '노이즈 단어' 수 (보통 5-20)
# - epochs: 전체 데이터셋에 대한 학습 반복 횟수
model = Word2Vec(sentences=sentences,
vector_size=100, # 임베딩 벡터 차원
window=5, # 컨텍스트 윈도우 크기
min_count=1, # 최소 단어 빈도
workers=4, # CPU 코어 수
sg=0, # 0: CBOW, 1: Skip-gram (여기서는 CBOW 사용)
epochs=10) # 학습 반복 횟수
print("Word2Vec 모델 학습 완료!")
다. 학습된 모델 활용
- 어휘 확인:
model.wv.key_to_index(단어와 인덱스 매핑),model.wv.index_to_key(인덱스와 단어 매핑) - 특정 단어의 임베딩 벡터 확인:
model.wv['단어'] - 단어 간 유사도 계산:
model.wv.similarity('단어1', '단어2') - 가장 유사한 단어 찾기:
model.wv.most_similar('단어', topn=5) - 긍정/부정 단어를 사용한 유추:
model.wv.most_similar(positive=['woman', 'king'], negative=['man'], topn=1)(결과: queen)
# 어휘 확인 (일부)
# print("어휘:", list(model.wv.key_to_index.keys())[:10])
# print("첫 번째 단어:", model.wv.index_to_key[0])
# 특정 단어의 임베딩 벡터 확인
try:
vector_nlp = model.wv['nlp']
print("\n'nlp'의 임베딩 벡터 (일부):", vector_nlp[:5])
print("'nlp'의 임베딩 벡터 차원:", len(vector_nlp))
except KeyError:
print("\n'nlp' 단어가 어휘에 없습니다.")
# 단어 간 유사도 계산
try:
similarity_score = model.wv.similarity('language', 'natural')
print(f"\n'language'와 'natural'의 유사도: {similarity_score:.4f}")
except KeyError as e:
print(f"\n유사도 계산 오류: 단어 '{e.args[0]}'가 어휘에 없습니다.")
try:
similarity_score_diff = model.wv.similarity('computer', 'human')
print(f"'computer'와 'human'의 유사도: {similarity_score_diff:.4f}")
except KeyError as e:
print(f"유사도 계산 오류: 단어 '{e.args[0]}'가 어휘에 없습니다.")
# 가장 유사한 단어 찾기
try:
similar_words = model.wv.most_similar('processing', topn=3)
print("\n'processing'과 가장 유사한 단어들:", similar_words)
except KeyError:
print("\n'processing' 단어가 어휘에 없습니다.")
# 유추 (데이터가 작아 의미있는 결과가 안 나올 수 있음)
try:
# 예시: 'nlp' + 'language' - 'computer' 와 유사한 단어? (의미는 없을 수 있음)
analogy = model.wv.most_similar(positive=['nlp', 'language'], negative=['computer'], topn=1)
print("\n유추 ('nlp' + 'language' - 'computer'):", analogy)
except KeyError as e:
print(f"\n유추 오류: 단어 '{e.args[0]}'가 어휘에 없습니다.")
라. 모델 저장 및 로드
- 학습된 모델은 저장해두고 나중에 다시 불러와 사용할 수 있습니다.
# 모델 저장
model.save("word2vec_gensim.model")
print("\n모델 저장 완료: word2vec_gensim.model")
# 모델 로드
# loaded_model = Word2Vec.load("word2vec_gensim.model")
# print("\n모델 로드 완료!")
# vector_nlp_loaded = loaded_model.wv['nlp']
# print("'nlp'의 로드된 임베딩 벡터 (일부):", vector_nlp_loaded[:5])
3. 주요 하이퍼파라미터 설명
vector_size: 임베딩 벡터의 차원 수. 일반적으로 50~300 사이의 값을 사용. 차원이 클수록 더 많은 정보를 담을 수 있지만, 학습 데이터가 충분하지 않으면 과적합될 수 있고 계산량이 증가.window: 중심 단어를 기준으로 앞뒤로 몇 개의 단어까지를 문맥(context)으로 간주할지 결정. Skip-gram에서는 중심 단어로부터 예측할 주변 단어의 최대 거리. CBOW에서는 중심 단어를 예측하기 위해 사용될 주변 단어들의 범위. 보통 2~10 사이의 값을 사용.min_count: 학습에 사용할 단어의 최소 등장 빈도. 이 값보다 적게 등장한 단어는 어휘에서 제외. 희귀 단어를 무시하여 노이즈를 줄이고 학습 속도를 높일 수 있음. 기본값은 5.sg:0이면 CBOW 모델을 사용하고,1이면 Skip-gram 모델을 사용. Skip-gram이 일반적으로 더 좋은 성능을 보이지만 학습 시간이 오래 걸림.workers: 학습 시 사용할 CPU 스레드 수. 멀티코어 환경에서 학습 속도를 높일 수 있음.epochs: 전체 학습 데이터셋에 대한 반복 학습 횟수. 너무 작으면 충분히 학습되지 않고, 너무 크면 과적합되거나 학습 시간이 오래 걸림. Gensim 4.0.0부터iter대신epochs사용.hs(Hierarchical Softmax):1이면 계층적 소프트맥스를 사용하고,0이면 사용하지 않음.negative파라미터와 함께 사용되며, 둘 중 하나만 선택해야 함.negative(Negative Sampling):hs=0일 때 사용. 0보다 큰 값을 설정하면 네거티브 샘플링을 사용. 얼마나 많은 “노이즈 단어“를 네거티브 샘플로 사용할지 지정. Skip-gram의 경우 5-20, CBOW의 경우 2-5 정도의 값이 권장됨.alpha: 초기 학습률(learning rate).min_alpha: 학습률이 선형적으로 감소하여 도달하는 최소 학습률.
4. 사전 훈련된 Word2Vec 모델 (Pre-trained Word2Vec Models)
- 대규모 말뭉치(예: Google News, Wikipedia)로 미리 학습된 Word2Vec 모델을 다운로드하여 사용할 수도 있습니다.
- 이러한 모델은 이미 풍부한 의미 정보를 담고 있어, 특정 작업에 대한 전이 학습(Transfer Learning)에 유용합니다.
- Gensim의
gensim.downloader모듈을 통해 다양한 사전 훈련된 모델을 쉽게 로드할 수 있습니다.
# import gensim.downloader as api
# 사전 훈련된 모델 목록 보기
# print(list(api.info()['models'].keys()))
# 예: 'word2vec-google-news-300' 모델 로드 (시간이 오래 걸리고 용량이 큼)
# word2vec_google_model = api.load('word2vec-google-news-300')
# print("Google News Word2Vec 모델 로드 완료!")
# similarity_king_queen = word2vec_google_model.similarity('king', 'queen')
# print(f"'king'과 'queen'의 유사도 (Google News): {similarity_king_queen:.4f}")
추가 학습 자료
다음 학습 내용
- Day 65: 감성 분석 - 기본 기법 (Sentiment Analysis - Basic Techniques)
Day 65: 감성 분석 - 기본 기법 (Sentiment Analysis - Basic Techniques)
학습 목표
- 감성 분석(Sentiment Analysis) 또는 오피니언 마이닝(Opinion Mining)의 정의와 중요성 이해
- 감성 분석의 다양한 수준(문서, 문장, 속성 수준) 학습
- 감성 분석의 주요 접근 방식 소개:
- 감성 사전을 이용한 방법 (Lexicon-based Approach)
- 머신러닝 기반 방법 (Machine Learning-based Approach)
- 딥러닝 기반 방법 (Deep Learning-based Approach) - 간략 소개
- 감성 사전 기반 감성 분석의 기본 원리 및 장단점 파악
1. 감성 분석 (Sentiment Analysis)이란?
- 텍스트에 나타난 주관적인 의견, 감정, 태도, 평가 등을 식별하고 추출하여 정량화하는 자연어 처리 기술입니다.
- **오피니언 마이닝(Opinion Mining)**이라고도 불립니다.
- 주로 텍스트가 **긍정적(Positive), 부정적(Negative), 또는 중립적(Neutral)**인지 분류합니다. 때로는 더 세분화된 감정(예: 행복, 슬픔, 분노)을 분석하기도 합니다.
감성 분석의 중요성
- 비즈니스 인텔리전스: 고객 리뷰, 소셜 미디어 반응 등을 분석하여 제품/서비스 개선, 마케팅 전략 수립에 활용.
- 여론 분석: 정치, 사회적 이슈에 대한 대중의 의견 파악.
- 평판 관리: 특정 브랜드나 인물에 대한 온라인 평판 모니터링.
- 고객 지원: 고객 문의의 긴급성이나 불만 정도 파악.
2. 감성 분석의 수준
가. 문서 수준 (Document-level)
- 전체 문서(예: 영화 리뷰, 제품 설명)가 전반적으로 긍정적인지 부정적인지, 중립적인지를 판단합니다.
- 문서가 단일 주제에 대한 의견을 담고 있다고 가정합니다.
나. 문장 수준 (Sentence-level / Aspect-level의 한 형태)
- 각 문장이 표현하는 감성을 분석합니다.
- 하나의 문서 내에서도 여러 감성이 혼재할 수 있기 때문에 더 세밀한 분석이 가능합니다.
- 예: “이 영화의 스토리는 훌륭했지만, 연기는 실망스러웠다.” -> 첫 번째 절은 긍정, 두 번째 절은 부정.
다. 속성 수준 (Aspect-level / Feature-based)
- 텍스트에서 언급된 특정 대상(개체, 속성)에 대한 감성을 분석합니다.
- 가장 세분화된 분석 수준으로, 무엇에 대해 어떤 감정을 느끼는지 구체적으로 파악할 수 있습니다.
- 예: “아이폰의 카메라는 훌륭하지만 배터리는 아쉽다.”
- 카메라 (속성) -> 긍정적
- 배터리 (속성) -> 부정적
3. 감성 분석 접근 방식
가. 감성 사전 기반 접근법 (Lexicon-based Approach)
- 단어와 그 단어가 가지는 감성 점수(긍정/부정/중립 및 강도)를 담고 있는 **감성 사전(Sentiment Lexicon)**을 사용합니다.
- 텍스트 내 단어들의 감성 점수를 합산하거나 평균내어 전체 텍스트의 감성을 판단합니다.
- 장점:
- 구현이 비교적 간단합니다.
- 별도의 학습 데이터가 필요하지 않을 수 있습니다 (사전만 있다면).
- 특정 도메인에 맞는 사전을 구축하면 해당 도메인에서 좋은 성능을 보일 수 있습니다.
- 단점:
- 문맥 처리의 한계: 단어의 의미는 문맥에 따라 달라지지만, 사전 기반 방식은 이를 고려하기 어렵습니다. (예: “not good“에서 “good“은 긍정이지만 “not“과 함께 부정으로 해석되어야 함)
- 신조어 및 비유적 표현 처리 어려움: 사전에 없는 단어나 새로운 표현에 취약합니다.
- 도메인 의존성: 일반적인 감성 사전은 특정 도메인의 전문 용어나 감성 표현을 반영하지 못할 수 있습니다.
- 감성 강도 조절의 어려움: 미묘한 감정의 차이나 강도를 정교하게 반영하기 어렵습니다.
- 주요 감성 사전:
- SentiWordNet: WordNet의 각 synset에 긍정, 부정, 객관성 점수를 할당.
- VADER (Valence Aware Dictionary and sEntiment Reasoner): 소셜 미디어 텍스트 분석에 특화된 사전 및 규칙 기반 시스템.
- AFINN: 각 단어에 -5(부정)에서 +5(긍정) 사이의 점수를 할당.
- 한국어 감성 사전: KNU 한국어 감성사전 등.
기본 알고리즘 (감성 사전 기반)
- 텍스트를 토큰화합니다.
- 각 토큰에 대해 감성 사전을 참조하여 감성 점수를 가져옵니다.
- (선택) 부정어(예: “not”, “안”) 처리: 부정어 뒤에 오는 긍정 단어는 부정으로, 부정 단어는 긍정으로 반전시킵니다.
- (선택) 강조어(예: “very”, “너무”) 처리: 감성 점수의 강도를 조절합니다.
- 문서 전체 또는 문장 전체의 감성 점수를 합산하거나 평균냅니다.
- 최종 점수를 기준으로 긍정, 부정, 중립으로 분류합니다.
나. 머신러닝 기반 접근법 (Machine Learning-based Approach)
- 감성 레이블(긍정/부정/중립)이 태깅된 학습 데이터를 사용하여 분류 모델을 학습시킵니다.
- 텍스트로부터 특징(Features)을 추출하고 (예: BoW, TF-IDF, Word Embeddings), 이를 입력으로 사용하여 지도 학습 알고리즘(예: Naive Bayes, Logistic Regression, SVM, Random Forest)을 훈련시킵니다.
- 장점:
- 데이터로부터 패턴을 학습하므로 문맥 정보를 어느 정도 반영할 수 있습니다.
- 특정 도메인의 데이터로 학습하면 해당 도메인에 특화된 모델을 만들 수 있습니다.
- 단점:
- 대량의 레이블링된 학습 데이터가 필요합니다.
- 특징 공학(Feature Engineering)이 모델 성능에 큰 영향을 미칩니다.
다. 딥러닝 기반 접근법 (Deep Learning-based Approach)
- 최근 가장 활발히 연구되고 좋은 성능을 보이는 접근 방식입니다.
- 순환 신경망(RNN, LSTM, GRU)이나 컨볼루션 신경망(CNN), 트랜스포머(Transformer) 기반 모델(예: BERT, GPT)을 사용하여 텍스트의 의미와 문맥을 학습합니다.
- 단어 임베딩을 입력으로 사용하여 텍스트의 연속적인 표현을 학습합니다.
- 장점:
- 특징 공학의 필요성을 줄여줍니다 (End-to-end learning).
- 복잡한 문맥 정보와 미묘한 감정 표현을 더 잘 포착할 수 있습니다.
- 최신 모델들은 매우 높은 정확도를 보입니다.
- 단점:
- 대량의 학습 데이터와 많은 계산 자원(GPU 등)이 필요합니다.
- 모델이 복잡하여 해석하기 어려울 수 있습니다 (Black box).
4. 감성 분석의 도전 과제
- 미묘한 표현 및 풍자/비꼬는 말투: “이 영화 정말 ’최고’다.” (실제로는 부정적)
- 중의적 표현: 문맥에 따라 긍/부정이 달라지는 표현.
- 주관성 탐지: 객관적인 사실과 주관적인 의견을 구분하는 것.
- 비교급 표현: “A는 B보다 좋다.”
- 도메인 특화성: 한 도메인에서 긍정인 단어가 다른 도메인에서는 부정일 수 있음.
추가 학습 자료
- NLTK Book - Chapter 6: Learning to Classify Text (Sentiment Analysis 예제 포함)
- VADER Sentiment Analysis (GitHub)
- 딥 러닝을 이용한 자연어 처리 입문 - 감성 분석
다음 학습 내용
- Day 66: 간단한 감성 분석기 구축 (Building a simple Sentiment Analyzer)
Day 66: 간단한 감성 분석기 구축 (Building a simple Sentiment Analyzer)
학습 목표
- 감성 사전을 이용하여 간단한 규칙 기반 감성 분석기 구현
- 머신러닝 기반 감성 분석기 (TF-IDF + Logistic Regression) 구현
scikit-learn을 활용한 텍스트 분류 모델 학습 및 평가
1. 감성 사전 기반 감성 분석기 구현
가. 사용할 감성 사전
- 여기서는 간단하게 직접 작은 규모의 긍정/부정 단어 사전을 정의하여 사용합니다.
- 실제로는 AFINN, SentiWordNet, KNU 한국어 감성사전 등을 활용할 수 있습니다.
나. 구현 단계
- 간단한 감성 사전 정의: 긍정 단어와 부정 단어 리스트를 만듭니다.
- 텍스트 입력 및 전처리: 분석할 텍스트를 입력받고, 기본적인 전처리(토큰화, 소문자화 등)를 수행합니다.
- 감성 점수 계산:
- 텍스트 내 각 토큰이 긍정 사전에 있으면 +1, 부정 사전에 있으면 -1을 부여합니다.
- (선택적) 부정어 처리: “not“과 같은 부정어가 긍정 단어 앞에 오면 점수를 반전시킵니다.
- 최종 감성 판단: 계산된 총 점수를 기준으로 긍정, 부정, 중립을 판단합니다.
다. 파이썬 코드 예시 (간단한 사전 기반)
# 1. 간단한 감성 사전 정의
positive_words = ['good', 'great', 'awesome', 'happy', 'love', 'excellent', 'nice', 'wonderful', 'best']
negative_words = ['bad', 'terrible', 'awful', 'sad', 'hate', 'poor', 'worst', 'horrible']
# 간단한 부정어 리스트
negation_words = ['not', 'no', 'never']
def simple_lexicon_sentiment(text):
text = text.lower()
words = text.split() # 간단한 공백 기준 토큰화
score = 0
negation_active = False
for i, word in enumerate(words):
# 부정어 처리 (다음 단어에 영향)
if word in negation_words:
negation_active = True
continue
current_word_score = 0
if word in positive_words:
current_word_score = 1
elif word in negative_words:
current_word_score = -1
if negation_active:
current_word_score *= -1
negation_active = False # 부정어 효과는 한 단어에만 적용 (간단화)
score += current_word_score
if score > 0:
return "Positive"
elif score < 0:
return "Negative"
else:
return "Neutral"
# 테스트
review1 = "This movie is very good and I love it"
review2 = "The food was terrible and the service was poor"
review3 = "It's not bad, actually quite nice" # 부정어 처리 테스트
review4 = "This is a book." # 중립 테스트
print(f"'{review1}' -> Sentiment: {simple_lexicon_sentiment(review1)}")
print(f"'{review2}' -> Sentiment: {simple_lexicon_sentiment(review2)}")
print(f"'{review3}' -> Sentiment: {simple_lexicon_sentiment(review3)}")
print(f"'{review4}' -> Sentiment: {simple_lexicon_sentiment(review4)}")
라. 한계점
- 위 예시는 매우 단순하며, 실제 감성 분석에는 부족한 점이 많습니다.
- 문맥, 비유, 신조어 처리 불가
- 감성 강도 표현 미흡
- 제한된 어휘
2. 머신러닝 기반 감성 분석기 구현
가. 데이터 준비
- 레이블링된 데이터셋이 필요합니다 (예: 영화 리뷰와 해당 리뷰의 긍정/부정 레이블).
- 여기서는 간단한 예제 데이터를 직접 만듭니다. 실제로는 IMDB 영화 리뷰 데이터셋, 네이버 영화 리뷰 데이터셋 등을 사용할 수 있습니다.
# 예제 데이터 (텍스트, 레이블) - 레이블: 1 (긍정), 0 (부정)
train_data = [
("This is a great movie, I loved it!", 1),
("The plot was amazing and the actors were brilliant.", 1),
("What a fantastic film, truly inspiring.", 1),
("I enjoyed every moment of this masterpiece.", 1),
("Absolutely wonderful, a must-see for everyone.", 1),
("This movie was terrible, a complete waste of time.", 0),
("I hated it, the acting was awful.", 0),
("A boring and predictable storyline.", 0),
("The worst film I have ever seen.", 0),
("I do not recommend this movie to anyone.", 0),
("It was okay, not great but not bad either.", 1), # 중립적인 것을 긍정으로 가정 (간단화)
("The movie is neither good nor bad.", 0) # 중립적인 것을 부정으로 가정 (간단화)
]
train_texts = [data[0] for data in train_data]
train_labels = [data[1] for data in train_data]
나. 특징 추출 (TF-IDF)
scikit-learn의TfidfVectorizer를 사용합니다.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(stop_words='english', # 불용어 제거 (영어)
max_features=1000) # 최대 특징 수 제한 (어휘 크기)
# 학습 데이터에 대해 TF-IDF 행렬 생성
X_train_tfidf = vectorizer.fit_transform(train_texts)
print("TF-IDF 행렬 크기:", X_train_tfidf.shape)
# print("어휘 일부:", vectorizer.get_feature_names_out()[:20])
다. 모델 학습 (로지스틱 회귀)
scikit-learn의LogisticRegression을 사용합니다.
from sklearn.linear_model import LogisticRegression
# 로지스틱 회귀 모델 초기화 및 학습
model_lr = LogisticRegression()
model_lr.fit(X_train_tfidf, train_labels)
print("로지스틱 회귀 모델 학습 완료!")
라. 모델 평가 및 예측
- 간단한 테스트 데이터를 사용하여 예측을 수행합니다.
- 실제로는 별도의 테스트 데이터셋을 사용하고, 정확도, 정밀도, 재현율, F1 점수 등으로 평가해야 합니다.
# 테스트 데이터
test_data = [
"I really liked this film, it was fantastic!", # 예상: 긍정 (1)
"A truly awful experience, I would not watch it again.", # 예상: 부정 (0)
"The movie was not good at all.", # 예상: 부정 (0)
"It was an average movie." # 예상: ? (데이터 및 모델에 따라 다름)
]
# 테스트 데이터에 대해 TF-IDF 변환 (학습 시 사용한 vectorizer 사용)
X_test_tfidf = vectorizer.transform(test_data)
# 예측
predictions = model_lr.predict(X_test_tfidf)
predicted_labels = ["Positive" if p == 1 else "Negative" for p in predictions]
for text, label in zip(test_data, predicted_labels):
print(f"'{text}' -> Predicted Sentiment: {label}")
# (선택) 예측 확률 확인
# probabilities = model_lr.predict_proba(X_test_tfidf)
# for text, prob in zip(test_data, probabilities):
# print(f"'{text}' -> Probabilities (Neg, Pos): {prob}")
마. 전체 코드 흐름 (머신러닝 기반)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split # 데이터 분할용
from sklearn.metrics import accuracy_score # 평가용
# 1. 데이터 준비 (더 많은 데이터가 필요함)
texts = [
"This is a great movie, I loved it!", "The plot was amazing and the actors were brilliant.",
"What a fantastic film, truly inspiring.", "I enjoyed every moment of this masterpiece.",
"Absolutely wonderful, a must-see for everyone.", "This movie was terrible, a complete waste of time.",
"I hated it, the acting was awful.", "A boring and predictable storyline.",
"The worst film I have ever seen.", "I do not recommend this movie to anyone.",
"It was okay, not great but not bad either.", "The movie is neither good nor bad.",
"An excellent story with powerful performances.", "Just a so-so movie, nothing special.",
"I was deeply disappointed by this film.", "Two thumbs up for this amazing flick!"
]
labels = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1] # 1: Positive, 0: Negative
# 2. 데이터 분할 (학습용, 테스트용)
X_train, X_test, y_train, y_test = train_test_split(texts, labels, test_size=0.25, random_state=42)
# 3. 특징 추출 (TF-IDF)
vectorizer = TfidfVectorizer(stop_words='english', max_features=1000)
X_train_tfidf = vectorizer.fit_transform(X_train)
X_test_tfidf = vectorizer.transform(X_test) # 테스트 데이터는 학습된 vectorizer로 transform만 수행
# 4. 모델 학습 (로지스틱 회귀)
model_lr = LogisticRegression()
model_lr.fit(X_train_tfidf, y_train)
# 5. 모델 평가
y_pred = model_lr.predict(X_test_tfidf)
accuracy = accuracy_score(y_test, y_pred)
print(f"\n모델 정확도 (Accuracy on Test Set): {accuracy:.4f}")
# 6. 새로운 텍스트 예측
new_reviews = [
"This is the best movie I have seen in years!",
"What a waste of money and time."
]
new_reviews_tfidf = vectorizer.transform(new_reviews)
new_predictions = model_lr.predict(new_reviews_tfidf)
new_predicted_labels = ["Positive" if p == 1 else "Negative" for p in new_predictions]
for review, label in zip(new_reviews, new_predicted_labels):
print(f"New Review: '{review}' -> Predicted Sentiment: {label}")
3. 고려 사항 및 개선 방향
- 데이터: 더 많고 다양한 학습 데이터가 필요합니다.
- 전처리: 더 정교한 전처리(표제어 추출, 특수문자 처리 등)를 적용할 수 있습니다.
- 특징 공학: N-gram, 단어 임베딩(Word2Vec, FastText) 등을 특징으로 사용할 수 있습니다.
- 모델 선택: Naive Bayes, SVM, RandomForest 등 다른 분류 모델을 시도해볼 수 있습니다.
- 하이퍼파라미터 튜닝:
GridSearchCV등을 사용하여 모델의 하이퍼파라미터를 최적화할 수 있습니다. - 딥러닝 모델: LSTM, CNN, BERT와 같은 딥러닝 모델을 사용하면 더 높은 성능을 기대할 수 있습니다 (더 많은 데이터와 계산 자원 필요).
- 한국어: 한국어의 경우 KoNLPy를 사용한 형태소 분석 및 적절한 토큰화가 필수적입니다.
추가 학습 자료
- Scikit-learn Tutorial: Working With Text Data
- IMDB 영화 리뷰 감성 분석 (캐글 노트북 예시 다수) (Word2Vec 사용 예시도 포함)
다음 학습 내용
- Day 67: 순환 신경망 (RNN) 소개 (Introduction to Recurrent Neural Networks (RNNs))
Day 67: 순환 신경망 (RNN) 소개 (Introduction to Recurrent Neural Networks (RNNs))
학습 목표
- 순차 데이터(Sequential Data)의 특징과 기존 신경망의 한계점 이해
- 순환 신경망(RNN)의 기본 구조와 작동 원리 학습
- RNN의 “메모리” 역할과 순환적 연결의 의미 파악
- RNN의 다양한 유형(one-to-many, many-to-one, many-to-many) 소개
- RNN의 주요 응용 분야 및 한계점(장기 의존성 문제) 인식
1. 순차 데이터 (Sequential Data)
- 정의: 시간의 흐름이나 순서에 따라 나타나는 데이터. 각 데이터 포인트는 이전 데이터 포인트와 독립적이지 않고 연관성을 가집니다.
- 예시:
- 자연어: 문장 내 단어들의 순서, 문서 내 문장들의 순서.
- 음성: 시간에 따른 음파 신호.
- 시계열 데이터: 주가, 날씨 변화, 센서 데이터 등.
- DNA 염기서열.
- 동영상: 프레임들의 연속.
기존 신경망(DNN, CNN)의 한계
- DNN (Deep Neural Network) / Feedforward Neural Network:
- 입력 데이터의 순서를 고려하지 않습니다. 각 입력은 독립적으로 처리됩니다.
- 고정된 크기의 입력을 가정합니다. (예: BoW 벡터, 고정 크기 이미지)
- 순차 데이터의 시간적 의존성을 모델링하기 어렵습니다.
- CNN (Convolutional Neural Network):
- 주로 이미지와 같이 공간적 구조를 가진 데이터 처리에 강점을 보입니다.
- 필터를 통해 지역적 특징을 추출하지만, 전체 시퀀스의 장기적인 의존성을 파악하는 데는 한계가 있을 수 있습니다. (1D CNN으로 시퀀스 처리가 가능하지만, RNN과는 다른 방식)
2. 순환 신경망 (Recurrent Neural Network, RNN)
- 정의: 순차 데이터 처리에 특화된 인공 신경망의 한 종류입니다.
- 핵심 아이디어: 네트워크 내부에 **순환적인 연결(Recurrent Connection)**을 포함하여, 이전 타임스텝(time step)의 정보를 현재 타임스텝의 계산에 활용합니다. 이를 통해 “메모리“와 유사한 역할을 수행하여 시퀀스 내의 정보를 기억하고 전달할 수 있습니다.
RNN의 기본 구조
- 각 타임스텝
t에서 RNN 셀은 두 가지 입력을 받습니다:- 현재 타임스텝의 입력 (xt)
- 이전 타임스텝의 은닉 상태 (hidden state, ht-1)
- 이 두 입력을 사용하여 현재 타임스텝의 **은닉 상태 (ht)**를 계산하고, 필요에 따라 **출력 (yt)**을 생성합니다.
- 은닉 상태
h_t는 다음 타임스텝으로 전달되어 과거의 정보를 요약하고 전달하는 역할을 합니다.
 (이미지 출처: Christopher Olah’s blog)
(이미지 출처: Christopher Olah’s blog)
- 수식 표현:
- 은닉 상태 계산: ht = tanh(Whh * ht-1 + Wxh * xt + bh)
- Whh: 이전 은닉 상태에서 현재 은닉 상태로의 가중치 행렬
- Wxh: 현재 입력에서 현재 은닉 상태로의 가중치 행렬
- bh: 은닉 상태의 편향 벡터
- tanh: 활성화 함수 (주로 하이퍼볼릭 탄젠트 사용)
- 출력 계산 (선택 사항): yt = Why * ht + by
- Why: 현재 은닉 상태에서 출력으로의 가중치 행렬
- by: 출력의 편향 벡터
- 은닉 상태 계산: ht = tanh(Whh * ht-1 + Wxh * xt + bh)
- 가중치 공유 (Weight Sharing): RNN은 모든 타임스텝에서 동일한 가중치 행렬(Whh, Wxh, Why)과 편향(bh, by)을 사용합니다. 이는 모델의 파라미터 수를 줄이고, 다양한 길이의 시퀀스에 대해 일반화할 수 있게 합니다.
RNN의 “메모리”
- 은닉 상태
h_t는 과거 타임스텝들의 정보를 요약하여 저장하고 있는 것으로 해석될 수 있습니다. - 이 “메모리“를 통해 RNN은 시퀀스 내의 의존성을 학습할 수 있습니다.
3. RNN의 다양한 구조 (유형)
입력 시퀀스와 출력 시퀀스의 길이에 따라 다양한 형태의 RNN 구조가 가능합니다.
 (이미지 출처: Stack Overflow, Andrej Karpathy)
(이미지 출처: Stack Overflow, Andrej Karpathy)
- One-to-One (바닐라 신경망): 하나의 입력, 하나의 출력. (엄밀히는 RNN이 아님)
- 예: 이미지 분류 (고정 크기 입력)
- One-to-Many: 하나의 입력을 받아 여러 개의 출력을 순차적으로 생성.
- 예: 이미지 캡셔닝 (이미지 입력 -> 단어 시퀀스 출력)
- Many-to-One: 여러 개의 입력을 순차적으로 받아 하나의 출력을 생성.
- 예: 감성 분석 (단어 시퀀스 입력 -> 긍정/부정 레이블 출력), 텍스트 분류.
- Many-to-Many (동일 길이): 입력 시퀀스와 동일한 길이의 출력 시퀀스를 생성. 각 타임스텝마다 출력이 나옴.
- 예: 품사 태깅 (단어 시퀀스 입력 -> 품사 태그 시퀀스 출력), 개체명 인식.
- Many-to-Many (다른 길이, Sequence-to-Sequence): 입력 시퀀스와 다른 길이의 출력 시퀀스를 생성. 인코더-디코더 구조에서 주로 사용.
- 예: 기계 번역 (소스 언어 문장 입력 -> 타겟 언어 문장 출력), 챗봇.
4. RNN의 주요 응용 분야
- 자연어 처리 (NLP):
- 언어 모델링 (Language Modeling)
- 기계 번역 (Machine Translation)
- 텍스트 생성 (Text Generation)
- 감성 분석 (Sentiment Analysis)
- 질의응답 (Question Answering)
- 품사 태깅 (Part-of-Speech Tagging)
- 음성 인식 (Speech Recognition)
- 시계열 예측 (Time Series Prediction)
- 이미지 캡셔닝 (Image Captioning)
- 비디오 분석 (Video Analysis)
5. RNN의 한계점: 장기 의존성 문제 (Long-Term Dependency Problem)
- RNN은 이론적으로는 과거의 정보를 모두 기억할 수 있지만, 실제로는 시퀀스가 길어질수록 앞쪽의 정보가 뒤쪽으로 제대로 전달되지 못하는 문제가 발생합니다.
- 이는 역전파 과정에서 기울기가 너무 작아지거나(Vanishing Gradient) 너무 커지는(Exploding Gradient) 현상 때문에 발생합니다.
- 기울기 소실 (Vanishing Gradient): 시퀀스가 길어질수록 앞쪽 타임스텝으로 전달되는 기울기가 점차 작아져서, 앞쪽 가중치들이 거의 업데이트되지 않아 장기적인 의존성을 학습하기 어려워집니다.
- 기울기 폭주 (Exploding Gradient): 기울기가 매우 커져서 학습이 불안정해지고 발산할 수 있습니다. (기울기 클리핑으로 어느 정도 완화 가능)
- 이 문제로 인해 기본적인 RNN(Vanilla RNN)은 비교적 짧은 시퀀스에서만 효과적입니다.
추가 학습 자료
- Understanding LSTMs (Christopher Olah’s Blog) - (LSTM 설명이지만 RNN 기본도 잘 다룸)
- The Unreasonable Effectiveness of Recurrent Neural Networks (Andrej Karpathy’s Blog)
- 딥 러닝을 이용한 자연어 처리 입문 - 순환 신경망 (RNN)
다음 학습 내용
- Day 68: LSTM (Long Short-Term Memory) 네트워크 (Long Short-Term Memory (LSTM) Networks) - RNN의 장기 의존성 문제를 해결하기 위한 주요 대안.
Day 68: LSTM (Long Short-Term Memory) 네트워크 (Long Short-Term Memory (LSTM) Networks)
학습 목표
- RNN의 장기 의존성 문제(Vanishing/Exploding Gradient) 복습
- LSTM의 등장 배경과 핵심 아이디어 이해
- LSTM 셀(Cell)의 내부 구조와 주요 구성 요소(셀 상태, 게이트) 학습:
- 망각 게이트 (Forget Gate)
- 입력 게이트 (Input Gate)
- 출력 게이트 (Output Gate)
- LSTM이 장기 의존성 문제를 어떻게 완화하는지 이해
1. RNN의 장기 의존성 문제 복습
- 바닐라 RNN은 시퀀스가 길어질수록 앞쪽의 정보가 뒤쪽으로 잘 전달되지 못하는 장기 의존성 문제를 가집니다.
- 이는 역전파 시 기울기가 점차 사라지거나(Vanishing Gradient) 폭주하여(Exploding Gradient) 발생하며, 이로 인해 먼 과거의 정보를 효과적으로 학습하기 어렵습니다.
2. LSTM (Long Short-Term Memory) 소개
- Hochreiter & Schmidhuber (1997)에 의해 제안된 RNN의 특별한 종류로, 장기 의존성 문제를 해결하기 위해 설계되었습니다.
- 핵심 아이디어: **셀 상태(Cell State)**라는 별도의 정보 흐름 경로를 두고, **게이트(Gate)**라는 메커니즘을 통해 이 셀 상태에 정보를 추가하거나 제거하는 것을 제어합니다.
- 이를 통해 중요한 정보는 오래 유지하고, 불필요한 정보는 잊어버릴 수 있도록 하여 장기적인 의존성을 효과적으로 학습할 수 있습니다.
3. LSTM 셀의 구조
- LSTM 셀은 바닐라 RNN 셀보다 복잡한 구조를 가집니다.
- 주요 구성 요소:
- 셀 상태 (Cell State, Ct): LSTM의 핵심. 정보가 큰 변화 없이 셀 전체를 관통하여 흐르는 컨베이어 벨트와 유사. 게이트를 통해 정보가 추가되거나 제거될 수 있음. 장기 기억을 담당.
- 은닉 상태 (Hidden State, ht): 이전 타임스텝의 출력 및 현재 타임스텝의 단기 기억. 다음 셀로 전달됨.
- 게이트 (Gates): 시그모이드(Sigmoid) 함수와 요소별 곱셈(Pointwise Multiplication) 연산으로 구성. 정보의 흐름을 제어.
- 시그모이드 함수는 0과 1 사이의 값을 출력하여, 각 정보 조각을 얼마나 통과시킬지 결정 (0: 통과시키지 않음, 1: 모두 통과시킴).
 (이미지 출처: Christopher Olah’s blog)
(이미지 출처: Christopher Olah’s blog)
가. 망각 게이트 (Forget Gate, ft)
- 역할: 이전 셀 상태(Ct-1)에서 어떤 정보를 버릴지(잊어버릴지) 결정합니다.
- 입력: 이전 은닉 상태(ht-1)와 현재 입력(xt).
- 계산: ft = σ(Wf * [ht-1, xt] + bf)
- σ: 시그모이드 함수
- Wf: 망각 게이트의 가중치 행렬
- bf: 망각 게이트의 편향 벡터
- [ht-1, xt]: ht-1과 xt를 연결(concatenate)한 벡터.
- 출력: 0과 1 사이의 값을 가지는 벡터. 각 요소는 이전 셀 상태의 해당 정보를 얼마나 유지할지(1에 가까울수록 유지, 0에 가까울수록 삭제)를 나타냅니다.
나. 입력 게이트 (Input Gate, it) 및 새로운 후보값 (Candidate Values, C̃t)
- 역할: 현재 입력에서 어떤 새로운 정보를 셀 상태에 저장할지 결정합니다.
- 두 부분으로 나뉩니다:
- 입력 게이트 (it): 어떤 값을 업데이트할지 결정.
- 계산: it = σ(Wi * [ht-1, xt] + bi)
- 새로운 후보값 (C̃t): 셀 상태에 추가될 수 있는 새로운 후보 값들의 벡터를 생성. (tanh 함수 사용)
- 계산: C̃t = tanh(WC * [ht-1, xt] + bC)
- 입력 게이트 (it): 어떤 값을 업데이트할지 결정.
다. 셀 상태 업데이트 (Updating the Cell State)
- 역할: 이전 셀 상태를 업데이트하여 새로운 셀 상태(Ct)를 만듭니다.
- 계산: Ct = ft * Ct-1 + it * C̃t
- ft * Ct-1: 이전 셀 상태에서 망각 게이트를 통해 선택적으로 정보를 버립니다.
- it * C̃t: 입력 게이트를 통해 선택된 새로운 후보값을 스케일링합니다.
- 이 두 부분을 더하여 새로운 셀 상태를 만듭니다.
라. 출력 게이트 (Output Gate, ot) 및 은닉 상태 업데이트
- 역할: 업데이트된 셀 상태(Ct)를 기반으로 어떤 정보를 현재 타임스텝의 은닉 상태(ht, 즉 출력)로 내보낼지 결정합니다.
- 계산:
- 출력 게이트 (ot): 셀 상태의 어느 부분을 출력할지 결정.
- ot = σ(Wo * [ht-1, xt] + bo)
- 은닉 상태 (ht):
- ht = ot * tanh(Ct)
- 셀 상태 Ct를 tanh 함수에 통과시켜 -1과 1 사이의 값으로 만들고, 출력 게이트 ot와 곱하여 최종 은닉 상태(출력)를 결정합니다.
- 출력 게이트 (ot): 셀 상태의 어느 부분을 출력할지 결정.
4. LSTM이 장기 의존성 문제를 완화하는 방식
- 셀 상태의 분리: 셀 상태는 상대적으로 간단한 선형 연산(곱셈과 덧셈)을 통해 정보가 흐르므로, 기울기가 여러 층을 거치면서 소실되거나 폭주하는 문제가 줄어듭니다. 정보가 비교적 잘 보존되어 전달될 수 있습니다.
- 게이트 메커니즘:
- 망각 게이트: 불필요한 정보를 명시적으로 제거하여 셀 상태가 과도하게 복잡해지는 것을 방지합니다.
- 입력 게이트: 중요한 새로운 정보만 선택적으로 셀 상태에 추가합니다.
- 이를 통해 LSTM은 시퀀스에서 중요한 정보는 장기간 기억하고, 덜 중요한 정보는 잊어버리는 학습을 할 수 있습니다.
- 결과적으로, LSTM은 바닐라 RNN보다 훨씬 긴 시퀀스에 대해서도 효과적으로 학습할 수 있으며, 장기 의존성 문제를 크게 완화합니다.
5. GRU (Gated Recurrent Unit)
- LSTM과 유사한 성능을 내면서 구조가 더 간단한 모델로, Cho 등이 2014년에 제안했습니다.
- 망각 게이트와 입력 게이트를 **업데이트 게이트(Update Gate)**로 통합하고, 셀 상태와 은닉 상태를 하나로 합쳤습니다.
- **리셋 게이트(Reset Gate)**를 사용하여 과거 정보를 얼마나 무시할지 결정합니다.
- LSTM보다 파라미터 수가 적어 계산 효율성이 높고, 데이터가 적을 때 과적합 방지에 유리할 수 있습니다.
- 성능은 문제에 따라 LSTM과 비슷하거나 약간 낮을 수 있습니다.
추가 학습 자료
- Understanding LSTMs (Christopher Olah’s Blog) - (LSTM 이해를 위한 최고의 자료 중 하나)
- Illustrated Guide to LSTMs and GRUs: A step by step explanation (Michael Phi)
- 딥 러닝을 이용한 자연어 처리 입문 - LSTM
다음 학습 내용
- Day 69: RNN/LSTM을 이용한 텍스트 분류기 구축 (Building a text classifier using RNN/LSTM)
Day 69: RNN/LSTM을 이용한 텍스트 분류기 구축 (Building a text classifier using RNN/LSTM)
학습 목표
TensorFlow/Keras를 사용하여 RNN 또는 LSTM 기반의 텍스트 분류 모델을 구축하는 과정 이해- 텍스트 데이터 전처리: 토큰화, 정수 인코딩, 패딩
- 임베딩 레이어(Embedding Layer)의 역할과 사용법 학습
- RNN/LSTM 레이어를 포함한 모델 구성 및 학습, 평가 방법 숙지
1. 텍스트 분류 문제 정의
- 예: 영화 리뷰가 긍정인지 부정인지 분류 (이진 분류)
- 예: 뉴스 기사가 어떤 카테고리(스포츠, 정치, 경제 등)에 속하는지 분류 (다중 클래스 분류)
2. 개발 환경 및 라이브러리
- TensorFlow & Keras: 딥러닝 모델 구축 및 학습을 위한 주요 프레임워크.
- NumPy: 수치 연산.
- Scikit-learn: 데이터 분할, 평가 지표 등 (선택 사항).
- NLTK / KoNLPy: 텍스트 전처리 (토큰화 등, 선택 사항). Keras의
Tokenizer도 사용 가능.
pip install tensorflow numpy scikit-learn nltk # 또는 konlpy
3. 구현 단계
가. 데이터 준비 및 로드
- 레이블링된 텍스트 데이터셋이 필요합니다. (예: IMDB 영화 리뷰 데이터셋)
- Keras는 IMDB 데이터셋과 같은 일부 텍스트 데이터셋을 내장하고 있어 쉽게 로드할 수 있습니다.
import numpy as np
from tensorflow.keras.datasets import imdb # IMDB 영화 리뷰 데이터셋
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, LSTM, Dense, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer # 직접 텍스트를 로드할 경우
# from sklearn.model_selection import train_test_split # 직접 텍스트를 로드할 경우
# --- IMDB 데이터셋 로드 예시 ---
num_words = 10000 # 사용할 단어의 최대 개수 (등장 빈도 기준)
(X_train_imdb, y_train_imdb), (X_test_imdb, y_test_imdb) = imdb.load_data(num_words=num_words)
print("훈련용 리뷰 개수: {}".format(len(X_train_imdb)))
print("테스트용 리뷰 개수: {}".format(len(X_test_imdb)))
print("첫 번째 훈련용 리뷰 (정수 시퀀스):", X_train_imdb[0][:10]) # 앞 10개 단어
print("첫 번째 훈련용 리뷰 레이블:", y_train_imdb[0]) # 0: 부정, 1: 긍정
# --- 직접 텍스트 데이터를 로드하고 전처리하는 경우 (예시) ---
# texts = ["This is a great movie.", "I hated this film.", ...] # 실제 텍스트 데이터
# labels = [1, 0, ...] # 긍정/부정 레이블
# # 1. Tokenizer 생성
# tokenizer = Tokenizer(num_words=num_words, oov_token="<unk>") # Out-of-vocabulary 토큰
# tokenizer.fit_on_texts(texts)
# # 2. 텍스트를 정수 시퀀스로 변환
# sequences = tokenizer.texts_to_sequences(texts)
# word_index = tokenizer.word_index
# print("Found %s unique tokens." % len(word_index))
나. 데이터 전처리
-
패딩 (Padding):
- RNN/LSTM 모델은 고정된 길이의 시퀀스를 입력으로 받습니다.
- 문장(리뷰)의 길이가 각기 다르므로, 최대 길이(maxlen)를 정하고 이보다 짧은 시퀀스는 특정 값(보통 0)으로 채워 길이를 맞춥니다 (패딩). 긴 시퀀스는 잘라냅니다.
pad_sequences함수 사용.
maxlen = 200 # 최대 시퀀스 길이 (리뷰 단어 수 제한) X_train_padded = pad_sequences(X_train_imdb, maxlen=maxlen, padding='post', truncating='post') X_test_padded = pad_sequences(X_test_imdb, maxlen=maxlen, padding='post', truncating='post') print("패딩된 첫 번째 훈련용 리뷰 (앞 10개):", X_train_padded[0][:10]) print("패딩된 훈련 데이터 크기:", X_train_padded.shape) # (샘플 수, maxlen)
다. 모델 구축 (RNN 또는 LSTM 사용)
-
임베딩 레이어 (Embedding Layer):
- 정수 인코딩된 단어들을 밀집 벡터(Dense Vector)로 변환합니다.
input_dim: 어휘의 크기 (num_words).output_dim: 임베딩 벡터의 차원 수.input_length: 입력 시퀀스의 길이 (maxlen).- (선택) 사전 훈련된 단어 임베딩(Word2Vec, GloVe)을 로드하여 사용할 수도 있습니다.
-
RNN/LSTM 레이어:
SimpleRNN또는LSTM레이어를 추가합니다.units: RNN/LSTM 셀의 뉴런(유닛) 수. 출력 공간의 차원이기도 합니다.return_sequences:True이면 각 타임스텝의 은닉 상태를 모두 출력 (다음 RNN/LSTM 레이어가 있을 때),False이면 마지막 타임스텝의 은닉 상태만 출력 (주로 분류 레이어 직전에).
-
출력 레이어 (Dense Layer):
- 분류를 위한 완전 연결 레이어.
- 이진 분류:
units=1, 활성화 함수sigmoid. - 다중 클래스 분류:
units=클래스 수, 활성화 함수softmax.
embedding_dim = 128 # 임베딩 벡터 차원
# --- LSTM 모델 구축 예시 ---
model_lstm = Sequential([
Embedding(input_dim=num_words, output_dim=embedding_dim, input_length=maxlen),
LSTM(units=64, dropout=0.2, recurrent_dropout=0.2), # dropout은 과적합 방지에 도움
Dense(units=1, activation='sigmoid') # 이진 분류
])
model_lstm.compile(optimizer='adam',
loss='binary_crossentropy', # 이진 분류 손실 함수
metrics=['accuracy'])
model_lstm.summary()
# --- (선택) SimpleRNN 모델 구축 예시 ---
# model_rnn = Sequential([
# Embedding(input_dim=num_words, output_dim=embedding_dim, input_length=maxlen),
# SimpleRNN(units=64),
# Dense(units=1, activation='sigmoid')
# ])
# model_rnn.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# model_rnn.summary()
# --- (선택) 양방향 LSTM (Bidirectional LSTM) 모델 구축 예시 ---
# Bidirectional LSTM은 시퀀스를 정방향과 역방향으로 모두 처리하여 문맥 정보를 더 잘 포착할 수 있습니다.
# model_bilstm = Sequential([
# Embedding(input_dim=num_words, output_dim=embedding_dim, input_length=maxlen),
# Bidirectional(LSTM(units=64, dropout=0.2, recurrent_dropout=0.2)),
# Dense(units=1, activation='sigmoid')
# ])
# model_bilstm.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# model_bilstm.summary()
라. 모델 학습
fit메소드를 사용하여 모델을 학습시킵니다.epochs: 전체 데이터셋에 대한 학습 반복 횟수.batch_size: 한 번의 가중치 업데이트에 사용될 샘플 수.validation_split또는validation_data: 검증 데이터셋을 설정하여 학습 중 모델 성능 모니터링.
epochs = 5 # 실제로는 더 많은 epoch 필요할 수 있음
batch_size = 64
print("\nLSTM 모델 학습 시작...")
history_lstm = model_lstm.fit(X_train_padded, y_train_imdb,
epochs=epochs,
batch_size=batch_size,
validation_split=0.2) # 훈련 데이터의 20%를 검증용으로 사용
print("LSTM 모델 학습 완료!")
# (선택) 학습 과정 시각화
import matplotlib.pyplot as plt
def plot_history(history):
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(1, len(acc) + 1)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, 'bo-', label='Training acc')
plt.plot(epochs_range, val_acc, 'ro-', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, 'bo-', label='Training loss')
plt.plot(epochs_range, val_loss, 'ro-', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plot_history(history_lstm)
마. 모델 평가
evaluate메소드를 사용하여 테스트 데이터셋에서 모델의 성능(손실, 정확도 등)을 평가합니다.
print("\nLSTM 모델 평가...")
loss_lstm, accuracy_lstm = model_lstm.evaluate(X_test_padded, y_test_imdb, batch_size=batch_size)
print(f"LSTM 모델 테스트 손실: {loss_lstm:.4f}")
print(f"LSTM 모델 테스트 정확도: {accuracy_lstm:.4f}")
바. 예측
- 학습된 모델을 사용하여 새로운 텍스트에 대한 예측을 수행할 수 있습니다.
- 예측을 위해서는 새로운 텍스트도 학습 데이터와 동일한 전처리(토큰화, 정수 인코딩, 패딩) 과정을 거쳐야 합니다.
# 예시: 새로운 리뷰 예측 (IMDB 데이터셋의 단어 인덱스를 알아야 함)
# 실제로는 tokenizer.texts_to_sequences 와 pad_sequences를 사용해야 함
# word_index = imdb.get_word_index()
# reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# def decode_review(text_sequence):
# return ' '.join([reverse_word_index.get(i - 3, '?') for i in text_sequence]) # 0,1,2는 패딩,시작,미등장 토큰
# sample_review_text = "This movie was fantastic! I really loved it and would recommend it to everyone."
# # 1. 토큰화 (실제로는 학습 시 사용한 tokenizer.texts_to_sequences 사용)
# # 아래는 IMDB 데이터셋이 이미 정수 인코딩 되어있다는 가정하에 임의의 시퀀스를 만드는 예시
# sample_sequence = [word_index.get(word.lower(), 2) + 3 for word in sample_review_text.split() if word_index.get(word.lower(), 2) < num_words-3][:maxlen]
# sample_padded = pad_sequences([sample_sequence], maxlen=maxlen, padding='post', truncating='post')
# prediction = model_lstm.predict(sample_padded)
# print(f"\n샘플 리뷰: '{sample_review_text}'")
# print(f"예측된 감성 (0: 부정, 1: 긍정): {'Positive' if prediction[0][0] > 0.5 else 'Negative'} (Raw: {prediction[0][0]:.4f})")
4. 추가 고려 사항
- 하이퍼파라미터 튜닝: 임베딩 차원, LSTM 유닛 수, 드롭아웃 비율, 학습률, 배치 크기, 에포크 수 등을 조절하여 성능을 최적화할 수 있습니다.
- 과적합 방지: 드롭아웃(Dropout), 규제(Regularization), 조기 종료(Early Stopping) 등을 사용할 수 있습니다.
- 모델 복잡도: 모델이 너무 복잡하면 과적합되기 쉽고, 너무 단순하면 충분한 성능을 내지 못할 수 있습니다.
- 사전 훈련된 임베딩 사용:
GloVe,FastText,Word2Vec등 사전 훈련된 단어 임베딩을 사용하면 적은 데이터로도 좋은 성능을 얻는 데 도움이 될 수 있습니다. (Embedding 레이어의weights파라미터 사용) - 어텐션 메커니즘 (Attention Mechanism): 긴 시퀀스에서 중요한 부분에 더 집중하여 성능을 향상시킬 수 있는 기법. (더 고급 주제)
- 트랜스포머 모델 (Transformer Models): BERT, GPT와 같은 트랜스포머 기반 모델들은 현재 많은 NLP 작업에서 SOTA(State-of-the-art) 성능을 보입니다.
추가 학습 자료
- TensorFlow Text classification tutorial
- Keras IMDB LSTM 예제
- 딥 러닝을 이용한 자연어 처리 입문 - IMDB 리뷰 감성 분류하기(LSTM)
다음 학습 내용
- Day 70: 강화 학습 및 NLP 개념 복습 (Review of RL and NLP concepts)
Day 70: 강화 학습 및 NLP 개념 복습 (Review of RL and NLP concepts)
학습 목표
- 지난 15일간 학습한 강화 학습(RL) 및 자연어 처리(NLP)의 핵심 개념들을 되짚어보고 정리합니다.
- 각 기술의 주요 용어, 알고리즘, 응용 분야를 상기합니다.
- 향후 더 심도 있는 학습을 위한 기반을 다집니다.
1. 강화 학습 (Reinforcement Learning, RL) 복습 (Days 55-59)
가. 핵심 개념
- 에이전트(Agent): 환경과 상호작용하며 학습하는 주체.
- 환경(Environment): 에이전트가 행동하는 외부 세계.
- 상태(State, S): 특정 시점에서 환경에 대한 관찰.
- 행동(Action, A): 에이전트가 상태에서 취할 수 있는 결정.
- 보상(Reward, R): 행동에 대한 환경의 피드백. 에이전트는 누적 보상을 최대화하려 함.
- 정책(Policy, π): 상태에 따른 행동 선택 전략. π(a|s).
- 가치 함수(Value Function):
- 상태 가치 함수 (Vπ(s)): 상태 s의 장기적인 가치.
- 행동 가치 함수 (Qπ(s, a)): 상태 s에서 행동 a를 했을 때의 장기적인 가치.
- 모델(Model): 환경의 작동 방식 (상태 전이 확률, 보상 함수).
- 모델 기반 RL: 모델을 알거나 학습하는 경우.
- 모델 프리 RL: 모델 없이 경험으로부터 직접 학습하는 경우.
- 마르코프 결정 과정 (MDP, Markov Decision Process): RL 문제를 수학적으로 정의하는 프레임워크 (S, A, P, R, γ).
- 마르코프 속성: 미래는 현재에만 의존.
- 감가율 (Discount Factor, γ): 미래 보상의 현재 가치 반영.
- 벨만 방정식 (Bellman Equation): 가치 함수 간의 재귀적 관계 정의.
나. 주요 알고리즘 및 기법
- Q-러닝 (Q-Learning):
- 대표적인 모델 프리, 오프 폴리시 알고리즘.
- Q-테이블을 사용하여 최적 행동 가치 함수 Q*를 학습.
- 업데이트 규칙: Q(S,A) ← Q(S,A) + α[R + γ maxa’Q(S’,a’) - Q(S,A)]
- ε-탐욕 정책: 탐험(Exploration)과 활용(Exploitation)의 균형.
- 심층 Q-네트워크 (Deep Q-Network, DQN):
- Q-테이블 대신 심층 신경망을 사용하여 Q-함수를 근사 (Q(s, a; θ)).
- 고차원 상태 공간(예: 이미지) 처리 가능, 일반화 성능 향상.
- 경험 재현 (Experience Replay): 샘플 간 상관관계 감소, 데이터 효율성 증대.
- 타겟 네트워크 분리 (Separate Target Network): 학습 안정성 향상.
다. 응용 분야
- 게임 AI (아타리 게임, 바둑 등)
- 로봇 제어
- 자율 주행
- 추천 시스템
- 자원 관리 최적화
2. 자연어 처리 (Natural Language Processing, NLP) 복습 (Days 60-69)
가. 핵심 개념
- 자연어 처리(NLP): 컴퓨터가 인간의 언어를 이해, 해석, 생성하도록 하는 기술.
- 말뭉치(Corpus): 분석을 위한 대량의 텍스트 데이터 집합.
- 토큰화(Tokenization): 텍스트를 의미 있는 단위(토큰)로 분리 (단어, 형태소 등).
- 정제(Cleaning) 및 정규화(Normalization): 불필요한 문자 제거, 대소문자 통일 등.
- 불용어(Stopword): 분석에 큰 의미 없는 단어 (예: a, the, 은, 는).
- 어간 추출(Stemming): 단어의 어미를 제거하여 어간을 추출.
- 표제어 추출(Lemmatization): 단어의 기본형(사전형)을 추출.
- Bag-of-Words (BoW): 단어 순서 무시, 단어 빈도 기반 텍스트 표현.
- TF-IDF (Term Frequency-Inverse Document Frequency): 단어 빈도와 역문서 빈도를 사용하여 단어 중요도 가중치 부여.
- 단어 임베딩(Word Embedding): 단어를 저차원 밀집 벡터로 표현. 단어 간 의미 유사성 포착.
- 분산 표현(Distributed Representation).
- Word2Vec (CBOW, Skip-gram): 신경망 기반, 주변 단어와의 관계를 통해 학습.
- GloVe (Global Vectors): 단어 동시 등장 빈도 행렬 기반 학습.
- 감성 분석(Sentiment Analysis): 텍스트의 주관적 의견(긍정/부정/중립) 분석.
- 감성 사전(Sentiment Lexicon) 기반 접근.
- 머신러닝/딥러닝 기반 접근.
- 순환 신경망 (RNN, Recurrent Neural Network): 순차 데이터 처리에 특화된 신경망. 이전 타임스텝의 정보를 현재에 활용.
- 장기 의존성 문제(Long-Term Dependency Problem): 기울기 소실/폭주로 긴 시퀀스 학습 어려움.
- LSTM (Long Short-Term Memory): RNN의 장기 의존성 문제 해결. 셀 상태와 게이트(망각, 입력, 출력) 사용.
- GRU (Gated Recurrent Unit): LSTM보다 단순화된 구조, 유사한 성능.
나. 주요 기법 및 라이브러리
- 텍스트 전처리: NLTK, KoNLPy (한국어), spaCy.
- BoW/TF-IDF: Scikit-learn (
CountVectorizer,TfidfVectorizer). - Word2Vec/GloVe: Gensim, TensorFlow/Keras
Embeddinglayer. - 감성 분석: VADER, Scikit-learn (분류 모델), TensorFlow/Keras (딥러닝 모델).
- RNN/LSTM 구현: TensorFlow/Keras (
SimpleRNN,LSTM,GRU,Bidirectionallayers).- 임베딩 레이어: 정수 인코딩된 단어를 임베딩 벡터로 변환.
- 패딩(Padding): 시퀀스 길이를 동일하게 맞춤.
다. 응용 분야
- 기계 번역
- 정보 검색, 검색 엔진
- 텍스트 분류 (스팸 필터, 주제 분류)
- 챗봇, 질의응답 시스템
- 텍스트 요약
- 음성 인식 및 합성
- 개체명 인식
3. 향후 학습 방향 제안
- 강화 학습 심화:
- 정책 경사(Policy Gradient) 방법 (REINFORCE, A2C, A3C)
- Actor-Critic 방법
- 심층 결정론적 정책 경사 (DDPG)
- 실제 환경 적용 및 프로젝트 (OpenAI Gym, PyBullet 등)
- 자연어 처리 심화:
- 어텐션 메커니즘(Attention Mechanism): Seq2Seq 모델 성능 향상.
- 트랜스포머(Transformer): BERT, GPT 등 SOTA 모델의 기반.
- 사전 훈련된 언어 모델 (Pre-trained Language Models) 활용: 전이 학습.
- 다양한 NLP Task 심층 학습: 기계 번역, 질의응답, 텍스트 생성 등.
- 한국어 NLP 특화 처리.
- 두 분야의 결합:
- 대화형 AI (RL을 이용한 대화 정책 학습)
- 자연어 설명을 이해하는 로봇 (NLP + RL)
자기 점검 질문
- MDP의 5가지 구성 요소는 무엇이며, 각 요소는 무엇을 의미하는가?
- Q-러닝 업데이트 규칙을 설명하고, 각 항의 의미를 설명할 수 있는가?
- DQN이 전통적인 Q-러닝에 비해 가지는 장점과 이를 가능하게 하는 핵심 기법은 무엇인가?
- 텍스트 전처리 과정에서 토큰화, 어간 추출, 표제어 추출의 차이점은 무엇인가?
- TF-IDF는 어떻게 계산되며, 어떤 단어에 높은 가중치를 부여하는가?
- 단어 임베딩이란 무엇이며, BoW와 비교했을 때 어떤 장점이 있는가? Word2Vec과 GloVe의 기본 아이디어 차이는?
- RNN의 기본 구조와 장기 의존성 문제란 무엇인가?
- LSTM은 장기 의존성 문제를 해결하기 위해 어떤 메커니즘을 사용하는가? (셀 상태, 3가지 게이트)
- 텍스트 분류를 위해 RNN/LSTM 모델을 구축할 때 필요한 주요 레이어들은 무엇인가? (Embedding, RNN/LSTM, Dense)
이러한 질문들에 스스로 답해보면서 지난 학습 내용을 점검하고, 부족한 부분은 다시 한번 해당 날짜의 학습 내용을 참고하여 복습하는 것이 좋습니다.
다음 학습 내용 예고 (Advanced Topics and Model Deployment)
- Day 71: 주성분 분석 (PCA) - 이론 및 구현 (Principal Component Analysis (PCA) - Theory and implementation)
- Day 72: 선형 판별 분석 (LDA) (Linear Discriminant Analysis (LDA))
- … 그리고 모델 평가, 앙상블, 시계열 분석, 모델 배포 등으로 이어집니다.
Day 71: 주성분 분석 (PCA) - 이론 및 구현 (Principal Component Analysis (PCA) - Theory and implementation)
학습 목표
- 차원 축소(Dimensionality Reduction)의 필요성과 목적 이해
- 주성분 분석(PCA)의 기본 개념과 원리 학습
- 분산(Variance)을 최대로 보존하는 축 찾기
- 주성분(Principal Components)의 의미
- 공분산 행렬(Covariance Matrix)과 고유값/고유벡터(Eigenvalue/Eigenvector)의 역할
- PCA 수행 단계 이해
scikit-learn을 사용한 PCA 구현 방법 숙지
1. 차원 축소 (Dimensionality Reduction)
-
정의: 고차원 데이터의 차원(특성의 수)을 줄이면서 데이터의 중요한 정보는 최대한 유지하는 과정.
-
필요성 및 목적:
- 차원의 저주(Curse of Dimensionality) 완화: 차원이 증가할수록 데이터 간의 거리 계산이 어려워지고, 모델 학습에 필요한 데이터 양이 기하급수적으로 증가하며, 과적합 위험이 커지는 문제.
- 계산 효율성 증대: 모델 학습 시간 및 메모리 사용량 감소.
- 과적합(Overfitting) 방지: 불필요한 노이즈나 중복된 특성을 제거하여 모델의 일반화 성능 향상.
- 데이터 시각화: 고차원 데이터를 2차원 또는 3차원으로 축소하여 시각적으로 탐색 가능.
- 특징 추출(Feature Extraction): 기존 특성들의 조합으로 새로운, 더 의미 있는 특성을 생성.
-
주요 차원 축소 기법:
- 주성분 분석 (PCA): 대표적인 선형 차원 축소 기법.
- 선형 판별 분석 (LDA, Linear Discriminant Analysis): 지도 학습 기반의 차원 축소 (분류 목적).
- t-SNE (t-Distributed Stochastic Neighbor Embedding): 비선형 차원 축소, 주로 시각화에 사용.
- UMAP (Uniform Manifold Approximation and Projection): 비선형 차원 축소, t-SNE보다 빠르고 전역 구조 보존에 유리.
2. 주성분 분석 (Principal Component Analysis, PCA)
가. 기본 개념
- 데이터의 **분산(Variance)**을 가장 잘 나타내는 새로운 좌표축(주성분)을 찾는 방식으로 차원을 축소하는 통계적 기법입니다.
- 즉, 데이터가 가장 넓게 퍼져 있는 방향을 첫 번째 주성분(PC1)으로 삼고, PC1에 직교하면서 다음으로 분산이 큰 방향을 두 번째 주성분(PC2)으로 삼는 방식으로 진행됩니다.
- 원래 특성 공간에서 주성분 공간으로 데이터를 변환(사영, Projection)합니다.
- 비지도 학습 기법으로, 타겟 변수(레이블)를 사용하지 않습니다.
나. 핵심 원리
- 분산 최대화: 각 주성분은 해당 축으로 데이터를 사영했을 때 분산이 최대가 되는 방향으로 결정됩니다.
- 직교성: 각 주성분은 서로 직교(Orthogonal)합니다. 이는 주성분들이 서로 독립적임을 의미하며, 정보의 중복을 최소화합니다.
- 고유값과 고유벡터: 데이터의 공분산 행렬(Covariance Matrix)을 사용하여 주성분을 찾습니다.
- 공분산 행렬: 특성들 간의 선형 관계(공분산)를 나타내는 정방 행렬.
- 고유벡터(Eigenvector): 공분산 행렬의 고유벡터는 주성분의 방향을 나타냅니다.
- 고유값(Eigenvalue): 해당 고유벡터 방향으로 데이터가 얼마나 큰 분산을 가지는지(주성분의 중요도)를 나타냅니다. 고유값이 클수록 더 많은 분산을 설명하는 중요한 주성분입니다.
다. PCA 수행 단계
-
(선택) 데이터 스케일링 (Data Scaling):
- PCA는 분산에 기반하므로, 특성들의 스케일(단위)이 다르면 분산이 큰 특성이 주성분에 과도한 영향을 미칠 수 있습니다.
- 따라서, 각 특성을 평균 0, 분산 1로 만드는 표준화(Standardization)를 수행하는 것이 일반적입니다. (
StandardScaler사용)
-
공분산 행렬 계산:
- 스케일링된 데이터의 공분산 행렬을 계산합니다. (데이터가 n개의 특성을 가지면 n x n 크기의 행렬)
-
고유값 분해 (Eigen Decomposition):
- 공분산 행렬에 대해 고유값 분해를 수행하여 고유값과 해당 고유벡터를 구합니다.
-
주성분 결정:
- 고유값이 큰 순서대로 고유벡터를 정렬합니다. 이 고유벡터들이 주성분이 됩니다.
- 첫 번째 고유벡터가 PC1, 두 번째 고유벡터가 PC2, …
-
차원 축소:
- 원래 데이터에서 유지하고자 하는 주성분의 개수
k를 선택합니다 (k < 원래 차원 수). - 선택된
k개의 주성분(고유벡터)으로 이루어진 행렬을 만듭니다. - 원래 데이터를 이
k개의 주성분으로 이루어진 새로운 공간으로 사영(Projection)시켜k차원의 데이터로 변환합니다. - 변환된 데이터 = 원본 데이터 (스케일링된) × 선택된 고유벡터 행렬
- 원래 데이터에서 유지하고자 하는 주성분의 개수
-
(선택) 설명된 분산 (Explained Variance) 확인:
- 각 주성분이 전체 분산 중 얼마나 많은 부분을 설명하는지 확인합니다. (
explained_variance_ratio_) - 누적 설명된 분산 비율을 보고 몇 개의 주성분을 선택할지 결정하는 데 도움을 받을 수 있습니다. (예: 95% 이상의 분산을 설명하는 최소한의 주성분 선택)
- 각 주성분이 전체 분산 중 얼마나 많은 부분을 설명하는지 확인합니다. (
3. scikit-learn을 사용한 PCA 구현
가. 예제 데이터 생성
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# 예제 데이터 생성 (2차원)
np.random.seed(42)
X = np.dot(np.random.rand(2, 2), np.random.randn(2, 200)).T # 200개의 샘플, 2개의 특성
# 데이터가 원점에 모여있지 않도록 약간 이동
X[:, 0] += 5
X[:, 1] -= 2
plt.figure(figsize=(6, 6))
plt.scatter(X[:, 0], X[:, 1], alpha=0.7)
plt.title("Original Data (2D)")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.axis('equal') # 축 스케일을 동일하게
plt.grid(True)
plt.show()
나. 데이터 스케일링
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
plt.figure(figsize=(6, 6))
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], alpha=0.7)
plt.title("Scaled Data (Mean 0, Var 1)")
plt.xlabel("Feature 1 (scaled)")
plt.ylabel("Feature 2 (scaled)")
plt.axis('equal')
plt.grid(True)
plt.show()
다. PCA 적용
n_components: 축소할 차원(주성분)의 수.- 정수: 선택할 주성분의 개수.
- 0과 1 사이의 실수 (예: 0.95): 설명된 분산의 비율이 해당 값 이상이 되도록 주성분 개수를 자동으로 선택.
None: 모든 주성분을 선택 (차원 축소 안 함, 분산 분석 목적).
# PCA 객체 생성 및 학습
# 예: 2차원에서 1차원으로 축소
pca_1d = PCA(n_components=1)
X_pca_1d = pca_1d.fit_transform(X_scaled)
print("Original data shape:", X_scaled.shape)
print("PCA transformed data shape (1D):", X_pca_1d.shape)
# 주성분 확인
print("\nPrincipal components (Eigenvectors):\n", pca_1d.components_) # 각 행이 주성분 벡터
# 설명된 분산 비율 확인
print("Explained variance ratio (1D):", pca_1d.explained_variance_ratio_) # 각 주성분이 설명하는 분산의 비율
print("Explained variance (1D):", pca_1d.explained_variance_) # 각 주성분의 고유값 (분산 크기)
# 1차원으로 축소된 데이터를 다시 2차원으로 복원 (정보 손실 발생)
X_restored_1d_to_2d = pca_1d.inverse_transform(X_pca_1d)
# 시각화
plt.figure(figsize=(8, 6))
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], alpha=0.3, label='Original Scaled Data')
plt.scatter(X_restored_1d_to_2d[:, 0], X_restored_1d_to_2d[:, 1], alpha=0.7, label='Restored from 1D PCA', marker='x', color='red')
# 주성분 벡터 시각화 (첫 번째 주성분)
# components_는 (n_components, n_features) 형태
# 각 주성분 벡터는 원점에서 시작한다고 가정
origin = [0, 0] # 원점
pc1_vector = pca_1d.components_[0] * np.sqrt(pca_1d.explained_variance_[0]) * 2 # 스케일링하여 잘 보이도록
plt.quiver(*origin, *pc1_vector, color=['green'], scale=5, label=f'PC1 (Expl. Var: {pca_1d.explained_variance_ratio_[0]:.2f})')
plt.title("PCA: Original vs Restored from 1D")
plt.xlabel("Feature 1 (scaled)")
plt.ylabel("Feature 2 (scaled)")
plt.axis('equal')
plt.legend()
plt.grid(True)
plt.show()
# 예: 모든 주성분 확인 (n_components=None 또는 생략)
pca_all = PCA() # 또는 PCA(n_components=None) 또는 PCA(n_components=2) for 2D data
X_pca_all = pca_all.fit_transform(X_scaled) # 이 경우 X_pca_all은 X_scaled를 회전시킨 형태
print("\nPrincipal components (All):\n", pca_all.components_)
print("Explained variance ratio (All):", pca_all.explained_variance_ratio_)
print("Cumulative explained variance ratio (All):", np.cumsum(pca_all.explained_variance_ratio_))
# 주성분 시각화 (PC1, PC2)
plt.figure(figsize=(8, 6))
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], alpha=0.3, label='Original Scaled Data')
for i, (comp, var) in enumerate(zip(pca_all.components_, pca_all.explained_variance_ratio_)):
# 주성분 벡터를 분산 크기만큼 스케일링하여 화살표로 표시
v = comp * np.sqrt(pca_all.explained_variance_[i]) * 2 # 스케일링하여 잘 보이도록
plt.quiver(0, 0, v[0], v[1], color=f'C{i+2}', scale=5, label=f'PC{i+1} (Expl. Var: {var:.2f})')
plt.title("Principal Components of Scaled Data")
plt.xlabel("Feature 1 (scaled)")
plt.ylabel("Feature 2 (scaled)")
plt.axis('equal')
plt.legend()
plt.grid(True)
plt.show()
# Scree Plot (설명된 분산 시각화)
plt.figure(figsize=(6, 4))
plt.bar(range(1, len(pca_all.explained_variance_ratio_) + 1), pca_all.explained_variance_ratio_, alpha=0.7, align='center',
label='Individual explained variance')
plt.step(range(1, len(pca_all.explained_variance_ratio_) + 1), np.cumsum(pca_all.explained_variance_ratio_), where='mid',
label='Cumulative explained variance', color='red')
plt.ylabel('Explained variance ratio')
plt.xlabel('Principal component index')
plt.xticks(range(1, len(pca_all.explained_variance_ratio_) + 1))
plt.title('Scree Plot')
plt.legend(loc='best')
plt.grid(True)
plt.show()
라. 실제 데이터셋에 적용 (예: Iris 데이터셋)
from sklearn.datasets import load_iris
iris = load_iris()
X_iris = iris.data # (150, 4) - 4개의 특성
y_iris = iris.target
# 1. 데이터 스케일링
scaler_iris = StandardScaler()
X_iris_scaled = scaler_iris.fit_transform(X_iris)
# 2. PCA 적용 (예: 4차원 -> 2차원으로 축소)
pca_iris = PCA(n_components=2)
X_iris_pca = pca_iris.fit_transform(X_iris_scaled)
print("\nIris data original shape:", X_iris_scaled.shape)
print("Iris data PCA transformed shape:", X_iris_pca.shape)
print("Explained variance ratio by 2 components:", pca_iris.explained_variance_ratio_)
print("Cumulative explained variance ratio:", np.sum(pca_iris.explained_variance_ratio_))
# 3. 시각화
plt.figure(figsize=(8, 6))
for i, target_name in enumerate(iris.target_names):
plt.scatter(X_iris_pca[y_iris == i, 0], X_iris_pca[y_iris == i, 1],
label=target_name, alpha=0.8)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of Iris Dataset (2 Components)')
plt.legend()
plt.grid(True)
plt.show()
4. PCA의 장단점
- 장점:
- 구현이 간단하고 계산 효율성이 높습니다.
- 데이터의 노이즈를 줄이고 과적합을 방지하는 데 도움이 됩니다.
- 데이터 시각화에 유용합니다.
- 단점:
- 선형 변환이므로 비선형 구조를 가진 데이터의 차원 축소에는 한계가 있습니다.
- 스케일링에 민감하므로 사전에 데이터 스케일링이 필요합니다.
- 주성분의 해석이 어려울 수 있습니다 (원래 특성들의 선형 결합이므로).
- 분류 문제에서 클래스 간의 분리 정보를 활용하지 못합니다 (LDA와 비교).
추가 학습 자료
- A Step-by-Step Explanation of Principal Component Analysis (PCA) - Built In
- StatQuest: PCA main ideas in only 5 minutes!!! (YouTube)
- Scikit-learn PCA Documentation
다음 학습 내용
- Day 72: 선형 판별 분석 (LDA) (Linear Discriminant Analysis (LDA)) - PCA와 비교되는 또 다른 차원 축소 기법.
Day 72: 선형 판별 분석 (LDA) (Linear Discriminant Analysis)
학습 목표
- 선형 판별 분석(LDA)의 기본 개념과 목적 이해
- LDA가 지도 학습 기반의 차원 축소 기법임을 인지
- LDA의 주요 아이디어: 클래스 간 분산은 최대화, 클래스 내 분산은 최소화
- PCA와 LDA의 차이점 비교
scikit-learn을 사용한 LDA 구현 방법 숙지
1. 선형 판별 분석 (Linear Discriminant Analysis, LDA) 소개
- 정의: 지도 학습(Supervised Learning) 기반의 차원 축소 및 분류 기법입니다.
- 주요 목적:
- 차원 축소: 데이터를 저차원 공간으로 투영하여 클래스 간의 분별력을 최대한 유지하면서 차원을 축소합니다.
- 분류: 저차원으로 축소된 공간에서 클래스를 분류하는 모델로도 사용될 수 있습니다. (LDA 분류기)
- LDA는 특히 분류 문제에서 클래스를 가장 잘 구분할 수 있는 새로운 특징 공간을 찾는 데 중점을 둡니다.
2. LDA의 핵심 아이디어
-
LDA는 데이터를 새로운 축(판별 벡터, Discriminant Vector)으로 투영(Projection)할 때, 다음 두 가지 목표를 동시에 달성하려고 합니다:
- 클래스 간 분산(Between-class scatter) 최대화: 서로 다른 클래스의 중심(평균)들이 최대한 멀리 떨어지도록 합니다.
- 클래스 내 분산(Within-class scatter) 최소화: 같은 클래스에 속하는 데이터들이 최대한 가깝게 모이도록 합니다.
-
즉, 투영된 데이터들이 클래스별로 잘 구분되도록 하는 축을 찾는 것이 목표입니다.
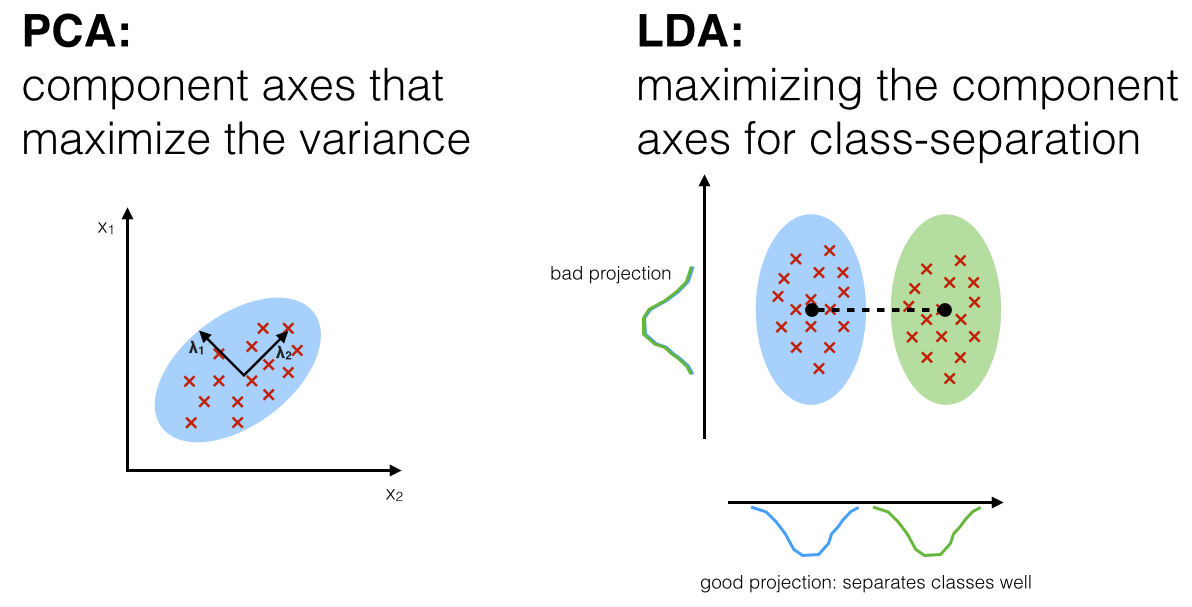 (이미지 출처: Sebastian Raschka’s blog)
(위 그림에서 좋은 부분 공간(Good Subspace)은 클래스 간 분리가 잘 되도록 데이터를 투영합니다.)
(이미지 출처: Sebastian Raschka’s blog)
(위 그림에서 좋은 부분 공간(Good Subspace)은 클래스 간 분리가 잘 되도록 데이터를 투영합니다.)
3. LDA 수행 단계 (개념적)
- (선택) 데이터 스케일링: PCA와 마찬가지로 특성 스케일에 민감할 수 있으나, LDA는 분산 비율을 다루므로 PCA만큼 필수적이지는 않을 수 있습니다. 하지만 일반적으로 적용하는 것이 좋습니다.
- 클래스 내 산포 행렬 (Within-class Scatter Matrix, SW) 계산:
- 각 클래스별로 데이터들이 얼마나 흩어져 있는지를 나타냅니다.
- 각 클래스의 공분산 행렬들을 합하여 계산합니다.
- SW = Σi=1C Si, 여기서 Si는 i번째 클래스의 공분산 행렬, C는 클래스 수.
- 클래스 간 산포 행렬 (Between-class Scatter Matrix, SB) 계산:
- 각 클래스의 중심(평균)이 전체 데이터의 중심(평균)으로부터 얼마나 떨어져 있는지를 나타냅니다.
- SB = Σi=1C Ni (mi - m)(mi - m)T, 여기서 Ni는 i번째 클래스의 샘플 수, mi는 i번째 클래스의 평균 벡터, m은 전체 데이터의 평균 벡터.
- 고유값 문제 해결:
- 다음 일반화된 고유값 문제를 풀어 고유벡터(판별 벡터)와 고유값을 찾습니다:
SW-1SB v = λ v
- v: 고유벡터 (판별 벡터, LDA 축의 방향)
- λ: 고유값 (판별 벡터의 중요도, 클래스 분리 능력)
- 고유값이 큰 순서대로 고유벡터를 정렬합니다. 이 고유벡터들이 LDA의 축이 됩니다.
- 다음 일반화된 고유값 문제를 풀어 고유벡터(판별 벡터)와 고유값을 찾습니다:
SW-1SB v = λ v
- 차원 축소:
- LDA로 축소할 수 있는 최대 차원의 수는
min(클래스 수 - 1, 원래 특성 수)입니다.- 예를 들어, 클래스가 3개이고 특성이 10개라면, 최대 2개의 판별 벡터(축)를 선택할 수 있습니다.
- 선택된
k개의 판별 벡터(고유벡터)로 이루어진 변환 행렬 W를 만듭니다. - 원래 데이터를 이 변환 행렬 W를 사용하여 새로운
k차원 공간으로 투영합니다: Xlda = X W
- LDA로 축소할 수 있는 최대 차원의 수는
4. PCA vs LDA
| 특징 | PCA (주성분 분석) | LDA (선형 판별 분석) |
|---|---|---|
| 학습 유형 | 비지도 학습 (Unsupervised) | 지도 학습 (Supervised) |
| 목표 | 데이터의 분산을 최대한 보존하는 축 탐색 (정보량 최대화) | 클래스 간 분리를 최대화하는 축 탐색 (분류 성능 최적화) |
| 클래스 레이블 사용 | 사용 안 함 | 사용 함 |
| 축소 가능 차원 수 | 최대 min(샘플 수 - 1, 특성 수) | 최대 min(클래스 수 - 1, 특성 수) |
| 데이터 분포 가정 | 가우시안 분포를 암묵적으로 가정할 수 있으나 필수는 아님 | 각 클래스의 데이터가 가우시안 분포를 따르고, 공분산이 동일하다고 가정 |
| 주요 용도 | 차원 축소, 노이즈 제거, 시각화, 특징 추출 | 차원 축소 (분류 목적), 분류 |
| 데이터 스케일링 | 민감 (필수적) | 덜 민감할 수 있으나, 일반적으로 권장 |
- 언제 무엇을 사용할까?
- 단순히 데이터의 차원을 줄이고 싶거나, 데이터의 주요 변동성을 파악하고 싶을 때: PCA
- 분류 모델의 성능을 높이기 위해 클래스 분별력이 좋은 특징을 추출하고 싶을 때: LDA
- 클래스 수가 적을 경우 LDA로 축소할 수 있는 차원이 매우 제한적일 수 있습니다. 이 경우 PCA가 더 유용할 수 있습니다.
5. scikit-learn을 사용한 LDA 구현
가. 예제 데이터 (Iris 데이터셋)
- LDA는 클래스 레이블을 사용하므로, 분류용 데이터셋이 필요합니다. Iris 데이터셋은 3개의 클래스를 가집니다.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA # LDA 임포트
from sklearn.datasets import load_iris
# Iris 데이터셋 로드
iris = load_iris()
X = iris.data
y = iris.target # 클래스 레이블
target_names = iris.target_names
print("Original data shape:", X.shape) # (150, 4) - 4개의 특성
print("Class labels shape:", y.shape) # (150,)
print("Number of classes:", len(np.unique(y))) # 3개의 클래스
나. 데이터 스케일링 (선택적이지만 권장)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
다. LDA 적용
n_components: 축소할 차원(판별 벡터)의 수. LDA의 경우min(클래스 수 - 1, 원래 특성 수)를 넘을 수 없습니다.- Iris 데이터셋의 경우 클래스가 3개이므로,
n_components는 최대 2가 됩니다.
- Iris 데이터셋의 경우 클래스가 3개이므로,
# LDA 객체 생성 및 학습
# n_components는 min(n_classes - 1, n_features) 이하로 설정
# Iris: n_classes=3, n_features=4 -> max n_components = 2
lda = LDA(n_components=2) # 2차원으로 축소
X_lda = lda.fit_transform(X_scaled, y) # LDA는 y (클래스 레이블) 정보가 필요!
print("\nLDA transformed data shape:", X_lda.shape) # (150, 2)
# 설명된 분산 비율 확인 (LDA에서는 'explained_variance_ratio_'로 제공)
# 각 판별 벡터가 클래스 분리를 얼마나 잘 설명하는지를 나타냄
print("Explained variance ratio by LDA components:", lda.explained_variance_ratio_)
print("Cumulative explained variance ratio:", np.sum(lda.explained_variance_ratio_))
라. 시각화
plt.figure(figsize=(8, 6))
colors = ['navy', 'turquoise', 'darkorange']
lw = 2
for color, i, target_name in zip(colors, [0, 1, 2], target_names):
plt.scatter(X_lda[y == i, 0], X_lda[y == i, 1], color=color, alpha=.8, lw=lw,
label=target_name)
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.title('LDA of Iris dataset (2 Components)')
plt.xlabel('LD1 (Linear Discriminant 1)')
plt.ylabel('LD2 (Linear Discriminant 2)')
plt.grid(True)
plt.show()
# PCA와 비교 (Iris 데이터셋에 PCA 적용)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled) # PCA는 y 정보 불필요
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
for color, i, target_name in zip(colors, [0, 1, 2], target_names):
plt.scatter(X_pca[y == i, 0], X_pca[y == i, 1], color=color, alpha=.8, lw=lw,
label=target_name)
plt.title('PCA of Iris dataset (2 Components)')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.grid(True)
plt.subplot(1, 2, 2)
for color, i, target_name in zip(colors, [0, 1, 2], target_names):
plt.scatter(X_lda[y == i, 0], X_lda[y == i, 1], color=color, alpha=.8, lw=lw,
label=target_name)
plt.title('LDA of Iris dataset (2 Components)')
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.grid(True)
plt.tight_layout()
plt.show()
- 위 시각화 결과를 보면, Iris 데이터셋의 경우 LDA가 PCA보다 클래스를 더 잘 분리하는 경향을 보일 수 있습니다. 이는 LDA가 클래스 정보를 활용하여 분별력을 높이는 방향으로 축을 찾기 때문입니다.
6. LDA의 가정 및 한계점
- 가정:
- 각 클래스의 데이터가 정규 분포(Gaussian distribution)를 따른다고 가정합니다.
- 모든 클래스가 동일한 공분산 행렬을 가진다고 가정합니다. (실제로는 이 가정이 맞지 않아도 어느 정도 잘 작동할 수 있습니다.)
- 특성들이 통계적으로 독립적이라고 가정합니다.
- 한계점:
- 위 가정이 실제 데이터와 많이 다를 경우 성능이 저하될 수 있습니다.
- 선형 변환이므로 비선형적으로 분리되는 데이터에는 적합하지 않을 수 있습니다. (커널 LDA 등으로 확장 가능)
- 축소할 수 있는 차원의 수가
클래스 수 - 1로 제한됩니다. 클래스 수가 적으면 차원 축소 효과가 미미할 수 있습니다. - 샘플 크기가 특성 수보다 훨씬 작을 때 불안정할 수 있습니다 (Small Sample Size Problem).
추가 학습 자료
- Linear Discriminant Analysis (LDA) for Dimensionality Reduction - Sebastian Raschka
- StatQuest: Linear Discriminant Analysis (LDA) clearly explained. (YouTube)
- Scikit-learn LDA Documentation
다음 학습 내용
- Day 73: 모델 평가 지표 - 정밀도, 재현율, F1-score, ROC AUC (Model Evaluation Metrics - Precision, Recall, F1-score, ROC AUC)
Day 73: 모델 평가 지표 - 정밀도, 재현율, F1-score, ROC AUC (Model Evaluation Metrics - Precision, Recall, F1-score, ROC AUC)
학습 목표
- 분류 모델의 성능을 정확하게 평가하기 위한 다양한 지표의 필요성 이해
- 오차 행렬(Confusion Matrix)의 구성 요소(TP, FP, FN, TN) 학습
- 주요 분류 평가지표 학습 및 의미 파악:
- 정확도 (Accuracy)
- 정밀도 (Precision)
- 재현율 (Recall) / 민감도 (Sensitivity)
- F1 점수 (F1-Score)
- 특이도 (Specificity)
- ROC 곡선 (Receiver Operating Characteristic Curve)과 AUC (Area Under the Curve)
1. 정확도 (Accuracy)의 한계
- 정확도: (예측이 올바른 샘플 수) / (전체 샘플 수)
- 가장 직관적인 평가지표이지만, 데이터가 불균형(Imbalanced)할 때 모델 성능을 왜곡할 수 있습니다.
- 예: 100개의 이메일 중 95개가 정상 메일, 5개가 스팸 메일인 데이터셋. 모든 메일을 정상으로 예측하는 모델도 정확도는 95%가 됩니다. 하지만 이 모델은 스팸 메일을 전혀 탐지하지 못하므로 유용하지 않습니다.
- 따라서, 특히 불균형 데이터셋에서는 정확도 외에 다른 평가지표들을 함께 고려해야 합니다.
2. 오차 행렬 (Confusion Matrix)
- 분류 모델의 예측 결과를 실제 클래스와 비교하여 시각적으로 표현한 표입니다.
- 이진 분류(Positive/Negative)의 경우 다음과 같이 구성됩니다:
| 예측: Positive (1) | 예측: Negative (0) | |
|---|---|---|
| 실제: Positive (1) | TP | FN |
| 실제: Negative (0) | FP | TN |
-
TP (True Positive, 진짜 양성): 실제 Positive인 것을 Positive로 올바르게 예측. (예: 실제 스팸 메일을 스팸으로 예측)
-
FN (False Negative, 가짜 음성): 실제 Positive인 것을 Negative로 잘못 예측. (예: 실제 스팸 메일을 정상으로 예측) - Type II Error
-
FP (False Positive, 가짜 양성): 실제 Negative인 것을 Positive로 잘못 예측. (예: 실제 정상 메일을 스팸으로 예측) - Type I Error
-
TN (True Negative, 진짜 음성): 실제 Negative인 것을 Negative로 올바르게 예측. (예: 실제 정상 메일을 정상으로 예측)
-
다중 클래스 분류의 경우, 각 클래스에 대해 오차 행렬을 확장하여 생각할 수 있습니다.
3. 주요 분류 평가지표
가. 정확도 (Accuracy)
- 정의: 전체 예측 중 올바르게 예측한 비율.
- 계산:
(TP + TN) / (TP + TN + FP + FN) - 데이터 분포가 균일할 때 유용하지만, 불균형 데이터에서는 신뢰도가 낮습니다.
나. 정밀도 (Precision)
- 정의: 모델이 Positive로 예측한 것들 중 실제로 Positive인 것의 비율.
- 계산:
TP / (TP + FP) - 의미: “모델이 Positive라고 예측했을 때, 얼마나 믿을 수 있는가?”
- FP를 낮추는 것이 중요할 때 사용됩니다. (예: 스팸 메일 필터 - 정상 메일을 스팸으로 잘못 분류(FP)하면 안 됨)
다. 재현율 (Recall) / 민감도 (Sensitivity) / 적중률 (Hit Rate)
- 정의: 실제 Positive인 것들 중 모델이 Positive로 올바르게 예측한 것의 비율.
- 계산:
TP / (TP + FN) - 의미: “실제 Positive 샘플들을 모델이 얼마나 잘 찾아내는가?”
- FN을 낮추는 것이 중요할 때 사용됩니다. (예: 암 진단 모델 - 실제 암 환자를 정상으로 잘못 진단(FN)하면 안 됨)
라. F1 점수 (F1-Score)
- 정의: 정밀도와 재현율의 조화 평균(Harmonic Mean).
- 계산:
2 * (Precision * Recall) / (Precision + Recall) - 의미: 정밀도와 재현율이 모두 중요할 때 사용. 두 지표가 한쪽으로 치우치지 않고 모두 높은 값을 가질 때 F1 점수도 높아집니다.
- 불균형 데이터셋에서 정확도보다 더 신뢰할 수 있는 성능 지표로 간주됩니다.
마. 특이도 (Specificity) / TNR (True Negative Rate)
- 정의: 실제 Negative인 것들 중 모델이 Negative로 올바르게 예측한 것의 비율.
- 계산:
TN / (TN + FP) - 의미: “실제 Negative 샘플들을 모델이 얼마나 잘 식별하는가?”
- 재현율(민감도)과 함께 사용되어 모델의 전반적인 성능을 평가합니다. (예: 질병 진단에서 건강한 사람을 건강하다고 판단하는 능력)
정밀도-재현율 트레이드오프 (Precision-Recall Trade-off)
- 일반적으로 정밀도와 재현율은 서로 반비례 관계(Trade-off)를 가집니다.
- 분류 모델의 결정 임계값(Threshold)을 조정함에 따라 한쪽이 올라가면 다른 한쪽이 내려가는 경향이 있습니다.
- 임계값을 높이면: Positive로 예측하는 기준이 엄격해져 FP가 줄고 정밀도는 높아지지만, TP도 줄어 FN이 늘고 재현율은 낮아질 수 있습니다.
- 임계값을 낮추면: Positive로 예측하는 기준이 완화되어 TP가 늘고 재현율은 높아지지만, FP도 늘어 정밀도는 낮아질 수 있습니다.
- 따라서, 문제의 특성에 따라 정밀도와 재현율 중 어떤 것을 더 중요하게 생각할지 결정하고 임계값을 조절해야 합니다. F1 점수는 이 둘의 균형을 나타냅니다.
4. ROC 곡선 (Receiver Operating Characteristic Curve)과 AUC (Area Under the Curve)
가. ROC 곡선
- 정의: 이진 분류 모델의 성능을 시각적으로 평가하는 그래프. 다양한 임계값(Threshold) 설정에 따라 분류기의 **재현율(TPR, True Positive Rate)**과 **위양성률(FPR, False Positive Rate)**의 변화를 나타냅니다.
- TPR (True Positive Rate) = Recall = Sensitivity =
TP / (TP + FN)(Y축) - FPR (False Positive Rate) =
FP / (FP + TN)= 1 - Specificity (X축)
- TPR (True Positive Rate) = Recall = Sensitivity =
- 해석:
- 곡선이 왼쪽 위 모서리(좌표 (0,1))에 가까울수록 모델 성능이 우수함을 의미합니다. (FPR은 낮고 TPR은 높은 이상적인 상태)
- 대각선(y=x)은 무작위 분류기(Random Classifier)의 성능을 나타냅니다. ROC 곡선이 이 대각선보다 위에 있어야 의미 있는 모델입니다.
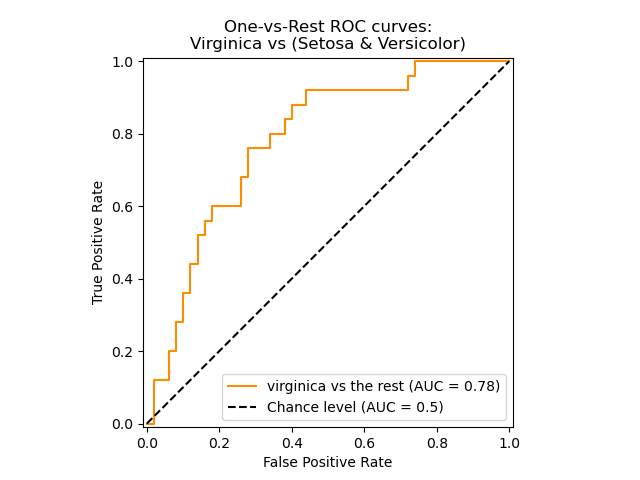 (이미지 출처: Scikit-learn documentation)
(이미지 출처: Scikit-learn documentation)
나. AUC (Area Under the ROC Curve)
- 정의: ROC 곡선 아래의 면적. 0과 1 사이의 값을 가집니다.
- 의미:
- AUC 값이 1에 가까울수록 모델의 성능이 우수함을 나타냅니다. (완벽한 분류기는 AUC=1)
- AUC 값이 0.5이면 무작위 분류기와 동일한 성능을 의미합니다.
- AUC는 임계값에 관계없이 모델이 얼마나 양성 클래스와 음성 클래스를 잘 구분하는지를 나타내는 전반적인 성능 지표입니다.
- 불균형 데이터셋에서도 비교적 안정적인 성능 평가를 제공합니다.
5. scikit-learn을 사용한 평가지표 계산
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification # 예제 데이터 생성용
import matplotlib.pyplot as plt
# 예제 데이터 생성 (불균형 데이터 가정 가능)
X, y = make_classification(n_samples=1000, n_features=20, weights=[0.9, 0.1], random_state=42) # 10%가 Positive 클래스
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y) # stratify=y 중요!
# 모델 학습 (예: 로지스틱 회귀)
model = LogisticRegression(solver='liblinear')
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1] # Positive 클래스에 대한 예측 확률
# 1. 오차 행렬
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:\n", cm)
# TN, FP
# FN, TP
# 2. 정확도
accuracy = accuracy_score(y_test, y_pred)
print(f"\nAccuracy: {accuracy:.4f}")
# 3. 정밀도
precision = precision_score(y_test, y_pred) # pos_label=1 기본값
print(f"Precision: {precision:.4f}")
# 4. 재현율
recall = recall_score(y_test, y_pred)
print(f"Recall (Sensitivity): {recall:.4f}")
# 5. F1 점수
f1 = f1_score(y_test, y_pred)
print(f"F1 Score: {f1:.4f}")
# (선택) 특이도 계산
tn, fp, fn, tp = cm.ravel() # 오차 행렬 값들을 1차원으로 풀기
specificity = tn / (tn + fp)
print(f"Specificity: {specificity:.4f}")
# 6. ROC 곡선 및 AUC
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba) # 예측 확률 사용!
auc = roc_auc_score(y_test, y_pred_proba)
print(f"\nAUC: {auc:.4f}")
# ROC 곡선 시각화
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='blue', lw=2, label=f'ROC curve (area = {auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', lw=2, linestyle='--', label='Random classifier')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate (1 - Specificity)')
plt.ylabel('True Positive Rate (Sensitivity/Recall)')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.grid(True)
plt.show()
6. 어떤 지표를 사용해야 할까?
- 문제의 종류와 중요도에 따라 다릅니다.
- 스팸 메일 필터: 정밀도가 중요 (정상 메일을 스팸으로 오판(FP)하면 안 됨).
- 암 진단: 재현율이 중요 (실제 환자를 놓치면(FN) 안 됨).
- 불균형 데이터: F1 점수, ROC AUC를 주로 사용. 정확도는 부적절.
- 모델 간 비교: ROC AUC는 임계값에 관계없이 모델의 전반적인 분류 능력을 보여주므로 유용.
- 일반적으로 여러 지표를 함께 고려하여 모델의 성능을 다각도로 평가하는 것이 좋습니다.
추가 학습 자료
- Scikit-learn: Model evaluation
- Precision and recall (Wikipedia)
- Receiver operating characteristic (Wikipedia)
- Google Developers - Classification: True vs. False and Positive vs. Negative
다음 학습 내용
- Day 74: 교차 검증 기법 (Cross-Validation techniques) - 모델의 일반화 성능을 더 신뢰성 있게 평가하는 방법.
Day 74: 교차 검증 기법 (Cross-Validation techniques)
학습 목표
- 모델 일반화 성능 평가의 중요성 이해
- 기존의 단일 학습/테스트 데이터 분할 방식의 한계점 인식
- 교차 검증(Cross-Validation)의 개념과 필요성 학습
- 주요 교차 검증 기법 학습:
- K-폴드 교차 검증 (K-Fold Cross-Validation)
- 계층별 K-폴드 교차 검증 (Stratified K-Fold Cross-Validation)
- LOOCV (Leave-One-Out Cross-Validation)
scikit-learn을 사용한 교차 검증 구현 방법 숙지
1. 모델 일반화 성능 평가의 중요성
- 머신러닝 모델의 최종 목표는 학습 데이터에만 잘 맞는 모델이 아니라, 새로운, 보지 못한 데이터(Unseen Data)에 대해서도 좋은 성능을 내는 것입니다. 이를 일반화(Generalization) 성능이라고 합니다.
- 모델이 학습 데이터에 과도하게 최적화되어 일반화 성능이 떨어지는 현상을 **과적합(Overfitting)**이라고 합니다.
- 따라서, 모델의 일반화 성능을 신뢰성 있게 평가하는 것은 매우 중요합니다.
2. 단일 학습/테스트 데이터 분할 방식의 한계점
- 가장 기본적인 모델 평가 방법은 전체 데이터를 학습 데이터(Training Data)와 테스트 데이터(Test Data)로 한 번 분할하고, 학습 데이터로 모델을 학습시킨 후 테스트 데이터로 성능을 평가하는 것입니다 (
train_test_split). - 한계점:
- 데이터 분할에 따른 성능 변동성: 데이터를 어떻게 분할하느냐에 따라 테스트 성능이 우연히 좋게 나오거나 나쁘게 나올 수 있습니다. 즉, 평가 결과가 불안정하고 신뢰하기 어려울 수 있습니다.
- 데이터의 효율적 사용 부족: 특히 데이터 양이 적을 경우, 테스트 데이터로 분리된 만큼 학습에 사용할 데이터가 줄어들어 모델 성능에 영향을 줄 수 있습니다.
- 과적합 평가의 한계: 테스트 데이터에 대한 성능이 좋더라도, 그것이 특정 데이터 분할에 대한 우연한 결과일 수 있으며, 모델이 실제로 일반화 성능이 좋은지 확신하기 어렵습니다.
3. 교차 검증 (Cross-Validation)
- 정의: 모델의 일반화 성능을 보다 신뢰성 있게 평가하기 위해, 데이터를 여러 번에 걸쳐 다양한 방식으로 학습 세트와 검증 세트(Validation Set)로 나누어 모델을 학습하고 평가하는 기법입니다.
- 목적:
- 모델 성능 평가의 안정성 및 신뢰성 향상.
- 제한된 데이터를 최대한 효율적으로 활용.
- 모델의 과적합 여부 판단 및 일반화 능력 측정.
- 하이퍼파라미터 튜닝 시 최적의 파라미터 조합을 찾는 데 활용.
4. 주요 교차 검증 기법
가. K-폴드 교차 검증 (K-Fold Cross-Validation)
- 가장 널리 사용되는 교차 검증 방법입니다.
- 수행 단계:
- 전체 데이터를 동일한 크기의 K개의 부분집합(폴드, Fold)으로 나눕니다.
- 첫 번째 폴드를 검증 세트(Validation Set)로 사용하고, 나머지 K-1개 폴드를 학습 세트(Training Set)로 사용하여 모델을 학습하고 평가합니다.
- 두 번째 폴드를 검증 세트로 사용하고, 나머지 K-1개 폴드를 학습 세트로 사용하여 모델을 학습하고 평가합니다.
- 이 과정을 K번 반복하여 각 폴드가 한 번씩 검증 세트가 되도록 합니다.
- K번의 평가 결과를 평균 내어 최종적인 모델 성능 지표로 사용합니다.
 (이미지 출처: Scikit-learn documentation)
(이미지 출처: Scikit-learn documentation)
- K 값 선택:
- 일반적으로 K=5 또는 K=10이 많이 사용됩니다.
- K가 너무 작으면 (예: K=2) 검증 세트가 너무 커서 학습 데이터가 부족해지고, 평가 결과의 분산이 커질 수 있습니다.
- K가 너무 크면 (예: K=데이터 샘플 수, 아래 LOOCV 참조) 학습 및 평가 시간이 오래 걸리고, 각 폴드의 평가 결과 간 상관관계가 높아질 수 있습니다.
- 장점:
- 모든 데이터가 최소 한 번은 검증에, 여러 번 학습에 사용되므로 데이터를 효율적으로 활용합니다.
- 단일 분할 방식보다 안정적이고 신뢰할 수 있는 성능 추정치를 제공합니다.
- 단점:
- 학습/평가 과정을 K번 반복하므로 시간이 더 오래 걸립니다.
나. 계층별 K-폴드 교차 검증 (Stratified K-Fold Cross-Validation)
- K-폴드 교차 검증의 변형으로, 특히 분류 문제에서 데이터가 불균형(Imbalanced)할 때 유용합니다.
- 핵심 아이디어: 각 폴드를 생성할 때, 원래 데이터셋의 클래스 비율을 각 폴드에서도 동일하게 유지하도록 샘플을 추출합니다.
- 이를 통해 각 폴드가 전체 데이터셋의 클래스 분포를 잘 대표하도록 하여, 보다 안정적이고 편향되지 않은 성능 평가를 가능하게 합니다.
- 분류 문제에서는 일반적인 K-폴드보다 계층별 K-폴드를 사용하는 것이 권장됩니다.
 (이미지 출처: Scikit-learn documentation)
(이미지 출처: Scikit-learn documentation)
다. LOOCV (Leave-One-Out Cross-Validation)
- K-폴드 교차 검증에서 K 값을 전체 데이터 샘플 수(N)와 동일하게 설정한 특수한 경우입니다.
- 수행 단계:
- N개의 샘플 중 단 하나의 샘플만을 검증 세트로 사용하고, 나머지 N-1개 샘플을 학습 세트로 사용합니다.
- 이 과정을 N번 반복하여 각 샘플이 한 번씩 검증 세트가 되도록 합니다.
- N번의 평가 결과를 평균하여 최종 성능을 추정합니다.
- 장점:
- 거의 모든 데이터를 학습에 사용하므로 모델 성능을 최대한 활용할 수 있습니다.
- 데이터 분할 방식에 따른 무작위성이 없어 결과가 항상 동일하게 나옵니다.
- 단점:
- N번의 학습과 평가를 수행해야 하므로 계산 비용이 매우 큽니다. (데이터가 클 경우 현실적으로 사용하기 어려움)
- 각 학습 세트가 매우 유사하여 평가 결과의 분산이 클 수 있습니다.
5. scikit-learn을 사용한 교차 검증 구현
가. K-폴드 교차 검증 예시
from sklearn.model_selection import KFold, cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
import numpy as np
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 모델 정의
model = LogisticRegression(solver='liblinear', max_iter=200) # max_iter는 수렴 경고 방지용
# K-Fold 교차 검증 설정
k = 5
kfold = KFold(n_splits=k, shuffle=True, random_state=42) # shuffle=True로 데이터 섞기 권장
# cross_val_score를 사용하여 교차 검증 수행
# cv 파라미터에 KFold 객체 또는 정수(폴드 수)를 전달할 수 있음
# scoring 파라미터로 평가 지표 지정 (예: 'accuracy', 'f1', 'roc_auc')
scores = cross_val_score(model, X, y, cv=kfold, scoring='accuracy')
print(f"K-Fold ({k} folds) 교차 검증 정확도 점수: {scores}")
print(f"평균 정확도: {scores.mean():.4f}")
print(f"정확도 표준편차: {scores.std():.4f}")
# 직접 KFold 객체를 사용하여 반복문으로 구현할 수도 있음
# accuracies = []
# for train_index, val_index in kfold.split(X):
# X_train_fold, X_val_fold = X[train_index], X[val_index]
# y_train_fold, y_val_fold = y[train_index], y[val_index]
# model.fit(X_train_fold, y_train_fold)
# accuracy = model.score(X_val_fold, y_val_fold)
# accuracies.append(accuracy)
# print(f"수동 K-Fold 정확도 점수: {np.array(accuracies)}")
# print(f"수동 K-Fold 평균 정확도: {np.mean(accuracies):.4f}")
나. 계층별 K-폴드 교차 검증 예시
from sklearn.model_selection import StratifiedKFold
# Stratified K-Fold 교차 검증 설정 (분류 문제에 권장)
# 계층화는 y (클래스 레이블)를 기준으로 수행
skfold = StratifiedKFold(n_splits=k, shuffle=True, random_state=42)
stratified_scores = cross_val_score(model, X, y, cv=skfold, scoring='accuracy')
print(f"\nStratified K-Fold ({k} folds) 교차 검증 정확도 점수: {stratified_scores}")
print(f"평균 정확도 (Stratified): {stratified_scores.mean():.4f}")
print(f"정확도 표준편차 (Stratified): {stratified_scores.std():.4f}")
다. LOOCV 예시
from sklearn.model_selection import LeaveOneOut
# LOOCV 설정
loo = LeaveOneOut()
# 데이터가 작을 때만 실행 권장 (시간이 매우 오래 걸림)
# n_samples = X.shape[0]
# if n_samples <= 30: # 예시로 작은 데이터에만 실행
# loo_scores = cross_val_score(model, X, y, cv=loo, scoring='accuracy')
# print(f"\nLOOCV 교차 검증 정확도 점수 (처음 10개): {loo_scores[:10]}") # 너무 많으므로 일부만 출력
# print(f"평균 정확도 (LOOCV): {loo_scores.mean():.4f}")
# else:
# print(f"\nLOOCV는 샘플 수({n_samples})가 많아 실행하지 않습니다.")
# Iris 데이터 (150개 샘플)에 LOOCV를 cross_val_score로 실행하면 150번 학습/평가.
# 여기서는 직접적인 실행보다 개념 이해에 중점.
# cross_val_score(model, X, y, cv=X.shape[0]) 와 유사하게 동작.
참고: cross_val_score는 내부적으로 모델을 복제하여 각 폴드마다 독립적으로 학습시킵니다.
6. 교차 검증 활용 시 주의사항
- 데이터 전처리: 교차 검증 시 데이터 전처리(스케일링, 특징 선택 등)는 각 폴드별로 학습 데이터에 대해서만
fit하고, 검증 데이터에는transform만 적용해야 합니다. 전체 데이터에 대해fit을 수행하고 교차 검증을 하면 검증 데이터의 정보가 학습에 누수(Data Leakage)되어 성능이 과대평가될 수 있습니다.scikit-learn의Pipeline을 사용하면 이러한 과정을 더 쉽게 관리할 수 있습니다.
- 시간적 순서가 있는 데이터: 시계열 데이터와 같이 시간적 순서가 중요한 경우에는 일반적인 K-폴드 방식이 적합하지 않을 수 있습니다. 과거 데이터로 미래를 예측해야 하므로, 검증 세트는 항상 학습 세트보다 시간적으로 뒤에 와야 합니다. (
TimeSeriesSplit사용)
추가 학습 자료
- Scikit-learn: Cross-validation: evaluating estimator performance
- A Gentle Introduction to k-fold Cross-Validation (Machine Learning Mastery)
- StatQuest: Cross Validation (YouTube)
다음 학습 내용
- Day 75: 하이퍼파라미터 튜닝 - 그리드 서치, 랜덤 서치 (Hyperparameter Tuning - Grid Search, Random Search) - 교차 검증을 활용하여 모델의 최적 하이퍼파라미터를 찾는 방법.
Day 75: 하이퍼파라미터 튜닝 - 그리드 서치, 랜덤 서치 (Hyperparameter Tuning - Grid Search, Random Search)
학습 목표
- 모델 파라미터(Model Parameters)와 하이퍼파라미터(Hyperparameters)의 차이 이해
- 하이퍼파라미터 튜닝의 중요성과 목적 학습
- 주요 하이퍼파라미터 튜닝 기법 학습:
- 수동 탐색 (Manual Search)
- 그리드 서치 (Grid Search)
- 랜덤 서치 (Random Search)
scikit-learn을 사용한 그리드 서치 및 랜덤 서치 구현 방법 숙지- 교차 검증을 하이퍼파라미터 튜닝에 어떻게 활용하는지 이해
1. 모델 파라미터 vs 하이퍼파라미터
가. 모델 파라미터 (Model Parameters)
- 모델이 학습 과정에서 데이터로부터 스스로 학습하는 변수들입니다.
- 사용자가 직접 설정하지 않고, 모델이 학습 데이터를 통해 최적의 값을 찾아냅니다.
- 예:
- 선형 회귀 모델의 계수(coefficients) 및 절편(intercept).
- 로지스틱 회귀 모델의 계수.
- 신경망의 가중치(weights) 및 편향(biases).
- 결정 트리의 각 노드에서의 분기 조건.
나. 하이퍼파라미터 (Hyperparameters)
- 모델의 학습 과정을 제어하거나 모델의 구조를 결정하는 변수들로, 사용자가 직접 설정해야 합니다.
- 모델이 학습을 시작하기 전에 미리 정의되어야 하며, 학습 과정에서 업데이트되지 않습니다.
- 하이퍼파라미터의 선택에 따라 모델의 성능이 크게 달라질 수 있습니다.
- 예:
- 로지스틱 회귀, SVM의 규제 강도
C. - K-최근접 이웃(KNN)의 이웃 수
k. - 결정 트리, 랜덤 포레스트의 최대 깊이
max_depth, 최소 샘플 분할 수min_samples_split. - 신경망의 학습률(learning rate), 은닉층의 수, 각 층의 뉴런 수, 활성화 함수, 옵티마이저 종류, 배치 크기, 에포크 수.
- PCA의 주성분 개수
n_components.
- 로지스틱 회귀, SVM의 규제 강도
2. 하이퍼파라미터 튜닝 (Hyperparameter Tuning / Optimization)
- 정의: 모델의 성능을 최적화하기 위해 가장 좋은 하이퍼파라미터 조합을 찾는 과정입니다.
- 중요성: 적절한 하이퍼파라미터 설정은 모델의 일반화 성능을 크게 향상시킬 수 있습니다. 잘못된 하이퍼파라미터는 과소적합(Underfitting)이나 과적합(Overfitting)을 유발할 수 있습니다.
- 목표: 검증 세트(Validation Set) 또는 교차 검증(Cross-Validation)을 통해 가장 좋은 성능을 내는 하이퍼파라미터 조합을 찾습니다.
3. 주요 하이퍼파라미터 튜닝 기법
가. 수동 탐색 (Manual Search)
- 사용자가 경험이나 직관에 의존하여 하이퍼파라미터 값을 직접 변경해가며 모델 성능을 확인하는 방식입니다.
- 간단한 모델이나 하이퍼파라미터 수가 적을 때는 시도해볼 수 있지만, 비효율적이고 최적의 조합을 찾기 어렵습니다.
나. 그리드 서치 (Grid Search)
- 개념: 사용자가 지정한 하이퍼파라미터 값들의 모든 가능한 조합에 대해 모델 성능을 평가하여 가장 좋은 조합을 찾는 방법입니다.
- 수행 단계:
- 튜닝할 하이퍼파라미터와 탐색할 값들의 목록을 정의합니다. (격자, Grid 생성)
- 정의된 모든 하이퍼파라미터 조합에 대해 모델을 학습하고 교차 검증을 통해 성능을 평가합니다.
- 가장 높은 교차 검증 성능을 보인 하이퍼파라미터 조합을 최적의 조합으로 선택합니다.
- 장점:
- 지정된 범위 내에서 모든 조합을 탐색하므로, 최적의 조합을 찾을 가능성이 비교적 높습니다.
- 구현이 간단합니다.
- 단점:
- 하이퍼파라미터의 종류가 많거나 탐색할 값의 범위가 넓으면 계산 비용이 기하급수적으로 증가합니다 (차원의 저주와 유사).
- 연속적인 하이퍼파라미터의 경우 이산적인 값들만 탐색합니다.
다. 랜덤 서치 (Random Search)
- 개념: 그리드 서치와 유사하지만, 모든 조합을 시도하는 대신 지정된 횟수만큼 하이퍼파라미터 조합을 무작위로 샘플링하여 평가합니다.
- 수행 단계:
- 튜닝할 하이퍼파라미터와 각 하이퍼파라미터의 탐색 범위(또는 확률 분포)를 정의합니다.
- 지정된 횟수(
n_iter)만큼 하이퍼파라미터 조합을 무작위로 선택하여 모델을 학습하고 교차 검증을 통해 성능을 평가합니다. - 가장 높은 교차 검증 성능을 보인 하이퍼파라미터 조합을 최적의 조합으로 선택합니다.
- 장점:
- 그리드 서치보다 계산 효율성이 높습니다. (특히 하이퍼파라미터 공간이 클 때)
- 모든 하이퍼파라미터가 동일하게 중요하지 않다는 가정 하에, 중요한 하이퍼파라미터에 대해 더 다양한 값을 탐색할 가능성이 있습니다.
- 제한된 시간 내에 좋은 성능의 조합을 찾을 확률이 높습니다.
- 단점:
- 무작위 탐색이므로 최적의 조합을 반드시 찾는다는 보장은 없습니다. (하지만 충분한 반복 횟수를 설정하면 좋은 결과를 얻을 수 있음)
라. 베이지안 최적화 (Bayesian Optimization) - 고급 기법
- 이전 탐색 결과를 바탕으로 다음 탐색할 하이퍼파라미터 조합을 더 효율적으로 결정하는 방식입니다. (예: Hyperopt, Optuna 라이브러리)
- 랜덤 서치보다 더 적은 반복으로 좋은 성능을 찾을 수 있는 경우가 많습니다.
4. scikit-learn을 사용한 그리드 서치 및 랜덤 서치 구현
GridSearchCV와RandomizedSearchCV클래스를 사용합니다.- 내부적으로 교차 검증을 수행하여 각 하이퍼파라미터 조합의 성능을 평가합니다.
가. 예제 데이터 및 모델 준비
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV, RandomizedSearchCV
from sklearn.svm import SVC # 예제 모델로 SVM 사용
from sklearn.preprocessing import StandardScaler
import numpy as np
# 데이터 로드 및 분할
iris = load_iris()
X, y = iris.data, iris.target
# 데이터 스케일링 (SVM은 스케일링에 민감)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42, stratify=y)
# 기본 모델 (튜닝 전)
base_model = SVC(random_state=42)
base_model.fit(X_train, y_train)
print(f"기본 모델 정확도: {base_model.score(X_test, y_test):.4f}")
나. 그리드 서치 (GridSearchCV)
# 1. 하이퍼파라미터 그리드 정의
# SVM의 주요 하이퍼파라미터: C (규제 강도), kernel, gamma (커널 계수)
param_grid = {
'C': [0.1, 1, 10, 100],
'kernel': ['linear', 'rbf', 'poly'],
'gamma': ['scale', 'auto', 0.1, 1] # 'rbf', 'poly', 'sigmoid' 커널에만 해당
}
# 2. GridSearchCV 객체 생성
# estimator: 사용할 모델
# param_grid: 탐색할 하이퍼파라미터 그리드
# cv: 교차 검증 폴드 수 (또는 교차 검증기 객체)
# scoring: 성능 평가 지표 (예: 'accuracy', 'f1')
# n_jobs: 병렬 처리할 CPU 코어 수 (-1이면 모든 코어 사용)
# verbose: 로그 출력 레벨
grid_search = GridSearchCV(estimator=SVC(random_state=42),
param_grid=param_grid,
cv=5, # 5-fold cross-validation
scoring='accuracy',
n_jobs=-1,
verbose=1)
# 3. 그리드 서치 수행 (학습 데이터에 대해)
print("\nGridSearchCV 시작...")
grid_search.fit(X_train, y_train)
print("GridSearchCV 완료!")
# 4. 최적 하이퍼파라미터 및 성능 확인
print("\n최적 하이퍼파라미터:", grid_search.best_params_)
print("최적 교차 검증 점수 (Accuracy):", grid_search.best_score_)
# 5. 최적 모델로 테스트 데이터 평가
best_model_grid = grid_search.best_estimator_ # 최적 하이퍼파라미터로 학습된 모델
test_accuracy_grid = best_model_grid.score(X_test, y_test)
print("테스트 세트 정확도 (GridSearch):", test_accuracy_grid)
# (선택) 모든 결과 확인
# results_df = pd.DataFrame(grid_search.cv_results_)
# print("\nGridSearchCV 결과 상세:\n", results_df[['param_C', 'param_kernel', 'param_gamma', 'mean_test_score']].sort_values(by='mean_test_score', ascending=False).head())
다. 랜덤 서치 (RandomizedSearchCV)
from scipy.stats import expon, uniform # 확률 분포 정의용
# 1. 하이퍼파라미터 탐색 범위 (분포) 정의
param_dist = {
'C': expon(scale=100), # 지수 분포 (큰 값에 더 많은 확률 부여, 예시) / 또는 [0.1, 1, 10, 100, 1000] 같은 리스트
'kernel': ['linear', 'rbf', 'poly'],
'gamma': expon(scale=.1), # 또는 ['scale', 'auto', 0.01, 0.1, 1]
'degree': [2, 3, 4] # 'poly' 커널에만 해당
}
# 2. RandomizedSearchCV 객체 생성
# n_iter: 시도할 하이퍼파라미터 조합의 수
random_search = RandomizedSearchCV(estimator=SVC(random_state=42),
param_distributions=param_dist,
n_iter=50, # 50개의 조합을 무작위로 시도
cv=5,
scoring='accuracy',
n_jobs=-1,
random_state=42, # 재현성을 위해 설정
verbose=1)
# 3. 랜덤 서치 수행
print("\nRandomizedSearchCV 시작...")
random_search.fit(X_train, y_train)
print("RandomizedSearchCV 완료!")
# 4. 최적 하이퍼파라미터 및 성능 확인
print("\n최적 하이퍼파라미터 (RandomSearch):", random_search.best_params_)
print("최적 교차 검증 점수 (Accuracy, RandomSearch):", random_search.best_score_)
# 5. 최적 모델로 테스트 데이터 평가
best_model_random = random_search.best_estimator_
test_accuracy_random = best_model_random.score(X_test, y_test)
print("테스트 세트 정확도 (RandomSearch):", test_accuracy_random)
5. 하이퍼파라미터 튜닝 시 고려사항
- 탐색 공간 정의: 하이퍼파라미터의 탐색 범위나 분포를 적절히 설정하는 것이 중요합니다. 너무 넓으면 비효율적이고, 너무 좁으면 최적값을 놓칠 수 있습니다. 도메인 지식이나 이전 경험을 활용할 수 있습니다.
- 계산 비용: 그리드 서치는 조합 수가 많아지면 매우 오래 걸립니다. 랜덤 서치나 베이지안 최적화는 제한된 예산 내에서 더 효율적일 수 있습니다.
- 교차 검증 폴드 수:
cv값을 적절히 설정해야 합니다. 일반적으로 5 또는 10이 사용됩니다. - 평가 지표:
scoring파라미터를 문제에 맞는 적절한 평가지표로 설정해야 합니다 (예: 불균형 데이터에서는 ‘f1’ 또는 ‘roc_auc’). - 데이터 누수 방지: 하이퍼파라미터 튜닝은 학습 데이터(또는 학습 데이터 내의 검증 폴드)에 대해서만 수행되어야 하며, 최종 평가는 별도의 테스트 세트에서 이루어져야 합니다.
GridSearchCV와RandomizedSearchCV는 내부적으로 이를 잘 처리합니다.
추가 학습 자료
- Scikit-learn: Tuning the hyper-parameters of an estimator
- Hyperparameter Tuning the Random Forest in Python (Towards Data Science)
- A Gentle Introduction to Algorithm Tuning (Machine Learning Mastery)
다음 학습 내용
- Day 76: 앙상블 방법 - 배깅 (랜덤 포레스트 복습), 부스팅 (AdaBoost, Gradient Boosting) (Ensemble Methods - Bagging (revisit Random Forests), Boosting (AdaBoost, Gradient Boosting))
Day 76: 앙상블 방법 - 배깅 (랜덤 포레스트 복습), 부스팅 (AdaBoost, Gradient Boosting) (Ensemble Methods - Bagging, Boosting)
학습 목표
- 앙상블 학습(Ensemble Learning)의 개념과 장점 이해
- 주요 앙상블 기법 학습:
- 배깅 (Bagging) 및 랜덤 포레스트 (Random Forest) 복습
- 부스팅 (Boosting)의 기본 아이디어
- 대표적인 부스팅 알고리즘: AdaBoost, Gradient Boosting Machine (GBM)
- 각 앙상블 기법의 작동 원리와 특징 비교
1. 앙상블 학습 (Ensemble Learning)
- 정의: 여러 개의 개별 모델(기본 학습기, Base Learner 또는 약한 학습기, Weak Learner)을 학습시키고, 그 예측들을 결합하여 단일 모델보다 더 강력하고 안정적인 최종 예측을 만들어내는 기법입니다.
- “다수결의 지혜” 또는 “집단 지성” 원리에 기반합니다.
- 장점:
- 성능 향상: 단일 모델보다 더 높은 정확도와 일반화 성능을 기대할 수 있습니다.
- 과적합 감소: 여러 모델의 예측을 평균내거나 결합함으로써 분산(Variance)을 줄여 과적합을 방지하는 데 도움이 됩니다.
- 모델 안정성 증가: 데이터의 작은 변화에 덜 민감한 모델을 만들 수 있습니다.
2. 배깅 (Bagging - Bootstrap Aggregating)
가. 기본 아이디어 (복습)
- 부트스트랩 샘플링 (Bootstrap Sampling): 원본 학습 데이터셋에서 중복을 허용하여 여러 개의 부분 데이터셋(부트스트랩 샘플)을 생성합니다. 각 부트스트랩 샘플은 원본 데이터와 크기가 동일합니다.
- 병렬 학습: 각 부트스트랩 샘플에 대해 독립적으로 동일한 유형의 기본 학습기를 학습시킵니다.
- 결합 (Aggregating):
- 회귀 문제: 각 기본 학습기의 예측값을 평균냅니다.
- 분류 문제: 각 기본 학습기의 예측 클래스 중 다수결 투표(Majority Voting) 또는 확률 평균을 통해 최종 클래스를 결정합니다.
나. 랜덤 포레스트 (Random Forest) (복습)
- 배깅의 대표적인 알고리즘으로, 기본 학습기로 **결정 트리(Decision Tree)**를 사용합니다.
- 일반적인 배깅과의 차이점:
- 각 트리를 학습할 때, 전체 특성 중 무작위로 일부 특성만 선택하여 최적의 분할을 찾습니다. (특성 샘플링)
- 이를 통해 각 트리들이 서로 다른 특성에 집중하게 되어 트리 간의 상관관계를 줄이고, 모델의 다양성을 높여 일반화 성능을 더욱 향상시킵니다.
- 장점:
- 높은 정확도와 좋은 일반화 성능.
- 과적합에 강한 편.
- 대용량 데이터에도 잘 작동.
- 특성 중요도(Feature Importance)를 제공.
scikit-learn의RandomForestClassifier,RandomForestRegressor사용.
3. 부스팅 (Boosting)
가. 기본 아이디어
- 배깅과 달리, 부스팅은 순차적으로 약한 학습기들을 학습시킵니다.
- 각 단계에서 이전 학습기가 잘못 예측한 샘플에 더 큰 가중치를 부여하거나, 이전 학습기의 잔차(Residual)를 다음 학습기가 학습하도록 하여 모델을 점진적으로 개선해 나갑니다.
- 즉, 약한 학습기들을 여러 개 결합하여 강력한 학습기를 만드는 데 초점을 맞춥니다.
- 주로 편향(Bias)을 줄이는 데 효과적입니다.
나. 에이다부스트 (AdaBoost - Adaptive Boosting)
- 1995년 Freund와 Schapire에 의해 제안된 초기 부스팅 알고리즘 중 하나입니다.
- 작동 원리:
- 모든 학습 데이터 샘플에 동일한 가중치를 부여하여 시작합니다.
- 첫 번째 약한 학습기(예: 간단한 결정 트리 - 스텀프(Stump): 깊이가 1인 트리)를 학습시키고, 예측 오류를 계산합니다.
- 잘못 분류된 샘플에는 가중치를 높이고, 올바르게 분류된 샘플에는 가중치를 낮춥니다.
- 업데이트된 가중치를 사용하여 다음 약한 학습기를 학습시킵니다. 이 학습기는 이전 단계에서 잘못 분류된 샘플에 더 집중하게 됩니다.
- 이 과정을 지정된 횟수만큼 반복합니다.
- 최종 예측은 각 약한 학습기의 예측을 **가중 합산(Weighted Sum)**하여 결정합니다. 이때, 성능이 좋은(오류율이 낮은) 학습기일수록 더 높은 가중치를 받습니다.
- 특징:
- 구현이 비교적 간단합니다.
- 잘못 분류된 샘플에 집중하여 모델을 개선합니다.
- 이상치(Outlier)에 민감할 수 있습니다 (잘못 분류된 이상치에 높은 가중치가 부여될 수 있음).
scikit-learn의AdaBoostClassifier,AdaBoostRegressor사용.
다. 그래디언트 부스팅 머신 (Gradient Boosting Machine, GBM)
- AdaBoost와 유사하게 이전 학습기의 오류를 보완하는 방식으로 순차적으로 학습기를 추가하지만, **손실 함수(Loss Function)의 그래디언트(Gradient, 기울기)**를 사용하여 오류를 최적화합니다.
- 작동 원리 (회귀 문제 예시):
- 첫 번째 모델(보통 간단한 모델, 예: 데이터의 평균값)로 초기 예측을 합니다.
- 실제값과 예측값 사이의 **잔차(Residual = 실제값 - 예측값)**를 계산합니다. 이 잔차가 현재 모델이 설명하지 못하는 오류를 나타냅니다.
- 다음 약한 학습기는 이 잔차를 예측하도록 학습합니다. (즉, 이전 모델의 오류를 보정하려고 노력)
- 이전 모델의 예측값에 학습된 잔차 예측값(일정 학습률(learning rate)을 곱하여)을 더하여 전체 모델의 예측을 업데이트합니다.
- 이 과정을 반복하여 모델을 점진적으로 개선합니다. 각 단계에서 손실 함수를 최소화하는 방향으로 학습이 진행됩니다.
- 주요 하이퍼파라미터:
n_estimators: 부스팅 단계의 수 (약한 학습기의 수).learning_rate: 각 약한 학습기의 기여도를 조절하는 값 (0과 1 사이). 너무 크면 과적합, 너무 작으면 학습이 느려짐.max_depth: 각 약한 학습기(주로 결정 트리)의 최대 깊이.subsample: 각 트리를 학습할 때 사용할 학습 데이터의 비율 (Stochastic Gradient Boosting). 과적합 방지에 도움.
- 특징:
- 강력한 예측 성능을 보이며, 다양한 문제에 널리 사용됩니다.
- AdaBoost보다 이상치에 덜 민감할 수 있습니다.
- 다양한 손실 함수를 사용할 수 있어 유연성이 높습니다.
- 하이퍼파라미터 튜닝이 중요하며, 과적합에 주의해야 합니다.
scikit-learn의GradientBoostingClassifier,GradientBoostingRegressor사용.
4. 배깅 vs 부스팅
| 특징 | 배깅 (Bagging) - 예: 랜덤 포레스트 | 부스팅 (Boosting) - 예: AdaBoost, GBM |
|---|---|---|
| 학습 방식 | 병렬적 (독립적으로 학습) | 순차적 (이전 모델의 결과에 기반하여 학습) |
| 주요 목표 | 분산 감소 (Variance Reduction), 과적합 방지 | 편향 감소 (Bias Reduction), 모델 성능 점진적 개선 |
| 샘플 가중치 | 모든 샘플에 동일한 가중치 (부트스트랩 샘플링으로 다양성 확보) | 이전 모델이 잘못 예측한 샘플에 더 높은 가중치 부여 (AdaBoost) |
| 오류 처리 | - | 이전 모델의 오류(잔차)를 다음 모델이 학습 (GBM) |
| 기본 학습기 | 주로 분산이 큰 모델 (예: 완전히 성장한 결정 트리) | 주로 편향이 큰 약한 학습기 (예: 얕은 결정 트리 - 스텀프) |
| 과적합 민감도 | 상대적으로 덜 민감 | 과적합에 민감할 수 있음 (특히 n_estimators가 클 때) |
| 계산 효율성 | 병렬 처리가 가능하여 학습 속도가 빠를 수 있음 | 순차적 학습으로 인해 병렬 처리가 어려움 |
5. scikit-learn을 사용한 부스팅 모델 구현 예시
가. AdaBoost 예시
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier # 약한 학습기로 사용
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 데이터 로드 (유방암 데이터셋 - 이진 분류)
cancer = load_breast_cancer()
X, y = cancer.data, cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# AdaBoost 모델 생성 및 학습
# base_estimator: 사용할 약한 학습기 (기본값: DecisionTreeClassifier(max_depth=1))
# n_estimators: 약한 학습기의 수
# learning_rate: 학습률 (기본값: 1.0)
ada_model = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=50,
learning_rate=1.0,
random_state=42)
ada_model.fit(X_train, y_train)
# 예측 및 평가
y_pred_ada = ada_model.predict(X_test)
accuracy_ada = accuracy_score(y_test, y_pred_ada)
print(f"AdaBoost 정확도: {accuracy_ada:.4f}")
나. Gradient Boosting Machine (GBM) 예시
from sklearn.ensemble import GradientBoostingClassifier
# Gradient Boosting 모델 생성 및 학습
# n_estimators: 트리의 수
# learning_rate: 학습률
# max_depth: 각 트리의 최대 깊이
# subsample: 각 트리를 학습할 때 사용할 샘플의 비율 (Stochastic Gradient Boosting)
gbm_model = GradientBoostingClassifier(n_estimators=100,
learning_rate=0.1,
max_depth=3,
subsample=0.8, # 80%의 샘플 사용
random_state=42)
gbm_model.fit(X_train, y_train)
# 예측 및 평가
y_pred_gbm = gbm_model.predict(X_test)
accuracy_gbm = accuracy_score(y_test, y_pred_gbm)
print(f"Gradient Boosting 정확도: {accuracy_gbm:.4f}")
# 특성 중요도 확인 (GBM은 특성 중요도 제공)
# import pandas as pd
# feature_importances = pd.Series(gbm_model.feature_importances_, index=cancer.feature_names)
# print("\nGBM 특성 중요도 (상위 5개):\n", feature_importances.sort_values(ascending=False).head())
추가 학습 자료
- Ensemble methods (Scikit-learn Documentation)
- A Gentle Introduction to Ensemble Learning (Machine Learning Mastery)
- StatQuest: AdaBoost, Clearly Explained (YouTube)
- StatQuest: Gradient Boost Part 1 (of 4): Regression Main Ideas (YouTube)
다음 학습 내용
- Day 77: XGBoost - 소개 및 구현 (XGBoost - Introduction and implementation) - 그래디언트 부스팅의 강력한 확장판.
Day 77: XGBoost - 소개 및 구현 (XGBoost - Introduction and implementation)
학습 목표
- XGBoost (Extreme Gradient Boosting)의 개념과 등장 배경 이해
- XGBoost가 기존 그래디언트 부스팅 머신(GBM)에 비해 가지는 주요 장점 학습
- 규제(Regularization)를 통한 과적합 방지
- 병렬 처리 및 최적화를 통한 빠른 학습 속도
- 결측치(Missing Values) 자체 처리 기능
- 교차 검증 내장 기능 등
- XGBoost의 주요 하이퍼파라미터 이해
- 파이썬 XGBoost 라이브러리를 사용한 모델 구현 방법 숙지
1. XGBoost (Extreme Gradient Boosting) 소개
- 정의: 그래디언트 부스팅 알고리즘을 기반으로 성능과 속도를 극대화한 트리 기반의 앙상블 학습 프레임워크입니다.
- Tianqi Chen에 의해 개발되었으며, 캐글(Kaggle)과 같은 데이터 과학 경진대회에서 압도적인 성능을 보여주며 널리 사용되기 시작했습니다.
- 분류(Classification)와 회귀(Regression) 문제 모두에 사용할 수 있습니다.
2. XGBoost의 주요 장점 및 특징
가. 규제 (Regularization)
- 표준 GBM에는 없는 **L1 규제(Lasso Regression)**와 L2 규제(Ridge Regression) 항을 손실 함수에 추가하여 모델의 복잡도를 제어하고 과적합을 방지합니다.
- L1 규제 (
reg_alpha): 가중치의 절대값 합에 페널티를 부여하여 일부 가중치를 0으로 만들어 특징 선택 효과를 가집니다. - L2 규제 (
reg_lambda): 가중치의 제곱 합에 페널티를 부여하여 가중치 크기를 줄여 모델을 부드럽게 만듭니다.
- L1 규제 (
- 이는 모델이 너무 복잡해지는 것을 막아 일반화 성능을 향상시킵니다.
나. 병렬 처리 및 최적화 (Parallel Processing and Optimization)
- 트리 생성 시 병렬 처리: 각 노드에서 최적의 분할 지점을 찾는 과정을 병렬로 처리하여 학습 속도를 크게 향상시킵니다. (주의: 트리가 순차적으로 생성되는 부스팅의 특성상 전체 트리를 병렬로 학습하는 것은 아님)
- 캐시 인식 접근 (Cache-aware Access): 메모리 접근 패턴을 최적화하여 하드웨어 성능을 최대한 활용합니다.
- 블록 압축 및 샤딩 (Block Compression and Sharding): 대용량 데이터를 효율적으로 처리하기 위한 기술.
다. 결측치 자체 처리 (Inbuilt Missing Value Treatment)
- 데이터 전처리 단계에서 결측치를 특별히 처리하지 않아도 XGBoost는 학습 과정에서 결측치를 자동으로 처리하는 방법을 학습합니다.
- 각 노드에서 분기할 때 결측치를 가진 샘플을 어느 쪽으로 보낼지(왼쪽 또는 오른쪽 자식 노드)를 학습하여 최적의 방향을 결정합니다.
라. 트리 가지치기 (Tree Pruning)
- 일반적인 GBM은 탐욕적(Greedy) 방식으로 트리를 성장시킨 후 가지치기를 하지만, XGBoost는
max_depth에 도달할 때까지 트리를 성장시킨 후, 손실 감소 기여도가 음수인 분기(즉, 모델 성능에 도움이 안 되는 분기)를 역방향으로 가지치기합니다 (Post-pruning). gamma(또는min_split_loss) 파라미터를 사용하여 리프 노드를 추가적으로 분할할 최소 손실 감소 값을 지정하여, 이 값보다 작은 손실 감소를 보이는 분기는 수행하지 않습니다.
마. 교차 검증 내장 기능 (Built-in Cross-Validation)
- XGBoost API 내에 교차 검증 기능(
xgb.cv)이 포함되어 있어, 최적의 부스팅 라운드 수(n_estimators또는num_boost_round)를 찾는 데 유용합니다. - 학습 과정에서 검증 세트의 성능을 모니터링하고, 성능이 더 이상 향상되지 않으면 조기 종료(Early Stopping)할 수 있습니다.
바. 높은 유연성 및 확장성
- 사용자 정의 손실 함수(Custom Objective Function) 및 평가 지표(Evaluation Metric)를 사용할 수 있습니다.
- 다양한 프로그래밍 언어(Python, R, Java, Scala, C++ 등)와 분산 환경(Hadoop, Spark)을 지원합니다.
3. XGBoost의 주요 하이퍼파라미터
- XGBoost는 많은 하이퍼파라미터를 가지고 있으며, 적절한 튜닝이 중요합니다.
가. 일반 파라미터 (General Parameters)
booster[기본값=gbtree]: 사용할 부스터 모델 유형.gbtree(트리 기반 모델),gblinear(선형 모델),dart(Dropout을 추가한 트리 모델) 중 선택.nthread[기본값=시스템 최대 스레드 수]: 병렬 처리에 사용할 스레드 수.verbosity[기본값=1]: 메시지 출력 레벨. 0(Silent), 1(Warning), 2(Info), 3(Debug).
나. 부스터 파라미터 (Booster Parameters) - gbtree 기준
eta(또는learning_rate) [기본값=0.3]: 학습률. 각 부스팅 단계에서 가중치를 얼마나 줄일지 결정. 낮은 값은 모델을 더 견고하게 만들지만,num_boost_round를 늘려야 함. (0.01 ~ 0.2 권장)gamma(또는min_split_loss) [기본값=0]: 리프 노드를 추가적으로 분할하기 위한 최소 손실 감소 값. 클수록 모델이 보수적(덜 복잡)이 됨.max_depth[기본값=6]: 각 트리의 최대 깊이. 클수록 모델이 복잡해지고 과적합 가능성이 높아짐. (3 ~ 10 권장)min_child_weight[기본값=1]: 자식 노드에 필요한 최소한의 관측치 가중치 합. 과적합 방지에 사용.subsample[기본값=1]: 각 트리를 학습할 때 사용할 학습 데이터 샘플의 비율. (0.5 ~ 1 권장)colsample_bytree[기본값=1]: 각 트리를 구성할 때 사용할 특성(피처)의 비율. (0.5 ~ 1 권장)colsample_bylevel,colsample_bynode: 더 세부적인 특성 샘플링 비율.lambda(또는reg_lambda) [기본값=1]: L2 규제 가중치.alpha(또는reg_alpha) [기본값=0]: L1 규제 가중치.tree_method[기본값=auto]: 트리 생성 알고리즘.auto,exact,approx,hist,gpu_hist등.hist가 대용량 데이터에 효율적.
다. 학습 과정 파라미터 (Learning Task Parameters)
objective[기본값=reg:squarederror]: 학습 목표 함수.reg:squarederror: 회귀 문제 (제곱 오차).binary:logistic: 이진 분류 (로지스틱 손실). 예측값은 확률.multi:softmax: 다중 클래스 분류 (소프트맥스 손실). 예측값은 클래스.num_class파라미터 필요.multi:softprob: 다중 클래스 분류. 예측값은 각 클래스에 대한 확률.num_class파라미터 필요.
eval_metric: 검증 세트에 사용할 평가 지표.- 회귀:
rmse,mae등. - 분류:
error(분류 오류율),logloss(로그 손실),auc(ROC AUC),aucpr(PR AUC),merror(다중 클래스 오류율) 등.
- 회귀:
seed[기본값=0]: 재현성을 위한 랜덤 시드.
4. 파이썬 XGBoost 라이브러리 사용법
xgboost라이브러리를 설치해야 합니다:pip install xgboost
가. Scikit-Learn 래퍼 (Wrapper) 사용
- XGBoost는 Scikit-Learn과 호환되는 래퍼 클래스(
XGBClassifier,XGBRegressor)를 제공하여 기존 Scikit-Learn 워크플로우에 쉽게 통합할 수 있습니다.
import xgboost as xgb
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 데이터 로드 (유방암 데이터셋 - 이진 분류)
cancer = load_breast_cancer()
X, y = cancer.data, cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# XGBClassifier 모델 생성 및 학습 (Scikit-Learn 래퍼)
# 주요 하이퍼파라미터 설정 예시
xgb_clf = xgb.XGBClassifier(
objective='binary:logistic', # 이진 분류
n_estimators=100, # 부스팅 라운드 수 (트리 개수)
learning_rate=0.1, # 학습률
max_depth=3, # 트리의 최대 깊이
subsample=0.8, # 각 트리에 사용할 샘플 비율
colsample_bytree=0.8, # 각 트리에 사용할 특성 비율
gamma=0, # 최소 손실 감소
reg_alpha=0, # L1 규제
reg_lambda=1, # L2 규제
use_label_encoder=False, # LabelEncoder 사용 경고 방지 (XGBoost 1.3.0 이상)
eval_metric='logloss', # 평가 지표 (학습 중 출력)
random_state=42
)
# 조기 종료(Early Stopping) 설정하여 학습
# eval_set: 검증 데이터셋. 조기 종료 및 학습 과정 모니터링에 사용
# early_stopping_rounds: 지정된 라운드 동안 성능 향상이 없으면 학습 중단
eval_set = [(X_test, y_test)] # 테스트셋을 검증셋으로 사용 (실제로는 별도 검증셋 권장)
xgb_clf.fit(X_train, y_train,
early_stopping_rounds=10,
eval_set=eval_set,
verbose=True) # verbose=True로 학습 과정 출력
# 예측
y_pred = xgb_clf.predict(X_test)
y_pred_proba = xgb_clf.predict_proba(X_test)[:, 1]
# 평가
accuracy = accuracy_score(y_test, y_pred)
print(f"\nXGBoost 정확도: {accuracy:.4f}")
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
# 특성 중요도 시각화
# xgb.plot_importance(xgb_clf)
# plt.show()
나. XGBoost 고유 API 사용
- XGBoost는 자체적인 데이터 구조(
DMatrix)와 학습 API를 가지고 있습니다. 대용량 데이터 처리나 세밀한 제어에 더 유리할 수 있습니다.
# 1. DMatrix 생성 (XGBoost 전용 데이터 구조)
dtrain = xgb.DMatrix(data=X_train, label=y_train)
dtest = xgb.DMatrix(data=X_test, label=y_test) # 레이블은 평가에만 사용
# 2. 파라미터 설정 (딕셔너리 형태)
params = {
'objective': 'binary:logistic',
'eval_metric': 'logloss',
'eta': 0.1, # learning_rate
'max_depth': 3,
'subsample': 0.8,
'colsample_bytree': 0.8,
'gamma': 0,
'lambda': 1, # L2 규제
'alpha': 0, # L1 규제
'seed': 42
}
num_boost_round = 200 # 부스팅 라운드 수
# 3. 모델 학습 (xgb.train)
# watchlist: 학습 과정에서 성능을 모니터링할 데이터셋 리스트
watchlist = [(dtrain, 'train'), (dtest, 'eval')]
bst_model = xgb.train(
params=params,
dtrain=dtrain,
num_boost_round=num_boost_round,
evals=watchlist,
early_stopping_rounds=10, # 조기 종료
verbose_eval=10 # 10 라운드마다 평가 결과 출력
)
# 4. 예측 (확률값 반환)
pred_probs_bst = bst_model.predict(dtest)
# 확률을 이진 클래스로 변환 (임계값 0.5 기준)
preds_bst = [1 if prob > 0.5 else 0 for prob in pred_probs_bst]
# 5. 평가
accuracy_bst = accuracy_score(y_test, preds_bst)
print(f"\nXGBoost (Native API) 정확도: {accuracy_bst:.4f}")
# 최적의 부스팅 라운드 수 확인 (조기 종료 시)
print(f"최적 부스팅 라운드: {bst_model.best_iteration}")
다. 교차 검증 (xgb.cv)
# xgb.cv를 사용한 교차 검증
# 파라미터는 xgb.train과 유사
# nfold: 폴드 수
# metrics: 평가 지표 리스트
# early_stopping_rounds: 조기 종료
# as_pandas: 결과를 Pandas DataFrame으로 반환
cv_results = xgb.cv(
params=params,
dtrain=dtrain,
num_boost_round=num_boost_round,
nfold=5, # 5-fold cross-validation
metrics={'logloss', 'auc'}, # 여러 지표 사용 가능
early_stopping_rounds=10,
seed=42,
verbose_eval=50,
as_pandas=True
)
print("\nXGBoost CV 결과 (마지막 5개 라운드):\n", cv_results.tail())
print(f"\n최적 CV LogLoss: {cv_results['test-logloss-mean'].min()} at round {cv_results['test-logloss-mean'].idxmin()}")
print(f"최적 CV AUC: {cv_results['test-auc-mean'].max()} at round {cv_results['test-auc-mean'].idxmax()}")
5. XGBoost 하이퍼파라미터 튜닝
GridSearchCV또는RandomizedSearchCV(Scikit-Learn 래퍼 사용 시) 또는Hyperopt,Optuna와 같은 베이지안 최적화 도구를 사용하여 튜닝할 수 있습니다.- 주요 튜닝 대상:
n_estimators,learning_rate,max_depth,min_child_weight,gamma,subsample,colsample_bytree,reg_alpha,reg_lambda. - 일반적으로
learning_rate를 낮추고(eta< 0.1),n_estimators(또는num_boost_round)를 조기 종료와 함께 크게 설정하는 전략이 많이 사용됩니다.
추가 학습 자료
- XGBoost 공식 문서
- A Gentle Introduction to XGBoost for Applied Machine Learning (Machine Learning Mastery)
- XGBoost Algorithm: Long May It Reign! (Towards Data Science)
다음 학습 내용
- Day 78: LightGBM - 소개 및 구현 (LightGBM - Introduction and implementation) - XGBoost와 유사하지만 더 빠르고 효율적인 또 다른 그래디언트 부스팅 프레임워크.
Day 78: LightGBM - 소개 및 구현 (LightGBM - Introduction and implementation)
학습 목표
- LightGBM (Light Gradient Boosting Machine)의 개념과 등장 배경 이해
- LightGBM이 XGBoost 및 기존 GBM에 비해 가지는 주요 장점 학습
- 리프 중심 트리 분할(Leaf-wise Tree Growth) 방식
- GOSS (Gradient-based One-Side Sampling)
- EFB (Exclusive Feature Bundling)
- 빠른 학습 속도와 낮은 메모리 사용량
- LightGBM의 주요 하이퍼파라미터 이해
- 파이썬 LightGBM 라이브러리를 사용한 모델 구현 방법 숙지
1. LightGBM (Light Gradient Boosting Machine) 소개
- 정의: Microsoft에서 개발한 그래디언트 부스팅 프레임워크로, XGBoost와 마찬가지로 트리 기반 학습 알고리즘입니다.
- 주요 특징: 대용량 데이터셋에서 매우 빠르고 효율적인 학습 성능을 제공하는 것을 목표로 합니다. “Light“라는 이름에서 알 수 있듯이 가볍고 빠릅니다.
- XGBoost와 함께 데이터 과학 경진대회 및 실제 산업 현장에서 널리 사용됩니다.
2. LightGBM의 주요 장점 및 핵심 기술
가. 리프 중심 트리 분할 (Leaf-wise Tree Growth)
- 기존 대부분의 트리 기반 알고리즘(예: XGBoost의
depthwise방식)은 트리를 레벨 중심(Level-wise) 또는 깊이 우선(Depth-wise) 방식으로 균형 있게 성장시킵니다. 즉, 같은 레벨의 모든 노드를 분할한 후 다음 레벨로 넘어갑니다. - LightGBM은 리프 중심(Leaf-wise) 방식을 사용합니다.
- 트리를 확장할 때, 현재까지 생성된 리프 노드 중 가장 큰 손실 감소(Max Delta Loss)가 예상되는 리프 노드를 선택하여 분할합니다.
- 이를 통해 더 깊고 비대칭적인 트리가 생성될 수 있지만, 같은 수의 분할을 수행했을 때 레벨 중심 방식보다 더 큰 손실 감소를 얻을 수 있어 학습 효율이 높습니다.
- 단, 데이터셋이 작을 경우 과적합될 가능성이 있으므로
max_depth와 같은 파라미터로 트리의 깊이를 제한하는 것이 중요합니다.
 (이미지 출처: LightGBM Documentation)
(이미지 출처: LightGBM Documentation)
나. GOSS (Gradient-based One-Side Sampling)
- 아이디어: 정보 이득(Information Gain)을 계산할 때, 그래디언트가 큰(즉, 학습이 덜 된, 오류가 큰) 데이터 샘플이 더 중요한 역할을 한다는 점에 착안합니다.
- 작동 방식:
- 데이터 샘플들을 그래디언트 크기 순으로 정렬합니다.
- 그래디언트가 큰 상위 a%의 샘플들(중요한 샘플)은 모두 선택합니다.
- 그래디언트가 작은 나머지 샘플들 중에서는 무작위로 b%의 샘플들(덜 중요한 샘플)만 선택합니다.
- 정보 이득 계산 시, 선택된 작은 그래디언트 샘플들의 가중치를 (1-a)/b 만큼 증폭시켜 원래 데이터 분포를 근사합니다.
- 효과: 학습 데이터의 양을 줄이면서도 정보 손실을 최소화하여 학습 속도를 높이고, 과적합을 방지하는 데 도움을 줍니다.
다. EFB (Exclusive Feature Bundling)
- 아이디어: 고차원의 희소(Sparse) 데이터셋에서 많은 특성들은 상호 배타적(Mutually Exclusive)인 경우가 많습니다. 즉, 여러 특성 중 동시에 0이 아닌 값을 가지는 경우가 드뭅니다. (예: 원-핫 인코딩된 범주형 변수들)
- 작동 방식: 이러한 상호 배타적인 특성들을 하나의 “번들(Bundle)“로 묶어 특성의 수를 효과적으로 줄입니다.
- 특성 번들링 알고리즘을 통해 어떤 특성들을 함께 묶을지 결정합니다.
- 번들 내의 특성들은 원래 값을 유지하면서 오프셋(Offset)을 추가하여 구분합니다.
- 효과: 특성 수를 줄여 학습 속도를 향상시키고 메모리 사용량을 줄입니다. 특히 희소한 고차원 데이터에서 효과적입니다.
라. 기타 장점
- 빠른 학습 속도와 낮은 메모리 사용량: 위 기술들(리프 중심 분할, GOSS, EFB) 덕분에 특히 대용량 데이터에서 XGBoost보다 더 빠른 학습 속도와 적은 메모리 사용량을 보이는 경우가 많습니다.
- 범주형 특성 자동 처리: 명시적으로 원-핫 인코딩 등을 하지 않아도 범주형 특성을 효과적으로 처리할 수 있습니다 (
categorical_feature파라미터 사용). - GPU 학습 지원.
- 병렬 학습 지원.
3. LightGBM의 주요 하이퍼파라미터
- XGBoost와 유사한 파라미터들이 많지만, 일부 고유한 파라미터도 있습니다.
가. 핵심 파라미터 (Core Parameters)
objective[기본값=regression]: 학습 목표 함수.regression,binary(이진 분류),multiclass(다중 분류),lambdarank(랭킹) 등.boosting또는boosting_type[기본값=gbdt]: 부스팅 타입.gbdt: 전통적인 Gradient Boosting Decision Tree.dart: Dropout을 적용한 트리 부스팅 (과적합 방지에 더 효과적일 수 있으나 느림).goss: Gradient-based One-Side Sampling (GOSS 사용).rf: Random Forest (배깅 방식).
num_iterations또는n_estimators[기본값=100]: 부스팅 라운드 수 (생성할 트리의 수).learning_rate[기본값=0.1]: 학습률.num_iterations와 반비례 관계.num_leaves[기본값=31]: 하나의 트리가 가질 수 있는 최대 리프 노드의 수. 리프 중심 분할을 사용하므로max_depth보다 중요한 파라미터. 너무 크면 과적합. (일반적으로 2max_depth보다 작거나 같게 설정)max_depth[기본값=-1]: 트리의 최대 깊이. -1은 제한 없음을 의미. 리프 중심 분할에서는num_leaves로 복잡도를 주로 제어하지만, 과적합 방지를 위해 적절히 설정하는 것이 좋음.
나. 학습 제어 파라미터 (Learning Control Parameters)
min_data_in_leaf또는min_child_samples[기본값=20]: 리프 노드가 되기 위한 최소한의 레코드(데이터 샘플) 수. 과적합 방지.min_sum_hessian_in_leaf또는min_child_weight[기본값=1e-3]: 리프 노드가 되기 위한 최소 헤시안(Hessian) 합. 과적합 방지.feature_fraction또는colsample_bytree[기본값=1.0]: 각 트리를 학습할 때 무작위로 선택하는 특성의 비율. (0.0 ~ 1.0)bagging_fraction또는subsample[기본값=1.0]: 각 트리를 학습할 때 사용할 데이터의 비율 (GOSS를 사용하지 않을 경우). (0.0 ~ 1.0)bagging_freq또는subsample_freq[기본값=0]: 배깅 수행 빈도. 0이면 비활성화. k > 0 이면 k번 반복마다 배깅 수행.lambda_l1또는reg_alpha[기본값=0.0]: L1 규제 가중치.lambda_l2또는reg_lambda[기본값=0.0]: L2 규제 가중치.cat_smooth[기본값=10.0]: 범주형 특성 처리 시 스무딩 값. 과적합 방지.categorical_feature[기본값=None]: 범주형 특성의 인덱스 또는 이름 리스트. (예:categorical_feature='0,1,2'또는categorical_feature=[0,1,2])
다. IO 파라미터 (IO Parameters)
verbosity[기본값=1]: 메시지 출력 레벨. <0 (Fatal), 0 (Error), 1 (Warning), >1 (Info).max_bin[기본값=255]: 특성 값을 구간화(binning)할 때 사용할 최대 구간 수. 값이 클수록 정확도는 높아지나 학습 시간이 오래 걸리고 과적합 가능성 증가.
4. 파이썬 LightGBM 라이브러리 사용법
lightgbm라이브러리를 설치해야 합니다:pip install lightgbm
가. Scikit-Learn 래퍼 (Wrapper) 사용
- LightGBM도 Scikit-Learn과 호환되는 래퍼 클래스(
LGBMClassifier,LGBMRegressor)를 제공합니다.
import lightgbm as lgb
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 데이터 로드 (유방암 데이터셋 - 이진 분류)
cancer = load_breast_cancer()
X, y = cancer.data, cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# LGBMClassifier 모델 생성 및 학습 (Scikit-Learn 래퍼)
# 주요 하이퍼파라미터 설정 예시
lgbm_clf = lgb.LGBMClassifier(
objective='binary', # 이진 분류
metric='binary_logloss', # 평가 지표 (학습 중 출력용)
n_estimators=100, # 부스팅 라운드 수
learning_rate=0.1, # 학습률
num_leaves=31, # 리프 노드 수
max_depth=-1, # 최대 깊이 (-1은 제한 없음)
min_child_samples=20, # 리프 노드의 최소 샘플 수
subsample=0.8, # 데이터 샘플링 비율
colsample_bytree=0.8, # 특성 샘플링 비율
reg_alpha=0.0, # L1 규제
reg_lambda=0.0, # L2 규제
random_state=42,
n_jobs=-1 # 사용할 CPU 코어 수 (-1은 전체)
)
# 조기 종료(Early Stopping) 설정하여 학습
# eval_set: 검증 데이터셋
# early_stopping_rounds: 조기 종료 라운드 수
# LGBMClassifier의 fit 메소드에서는 callbacks 파라미터를 통해 조기 종료 설정
eval_set = [(X_test, y_test)]
callbacks = [lgb.early_stopping(stopping_rounds=10, verbose=1)] # verbose=1로 조기 종료 메시지 출력
lgbm_clf.fit(X_train, y_train,
eval_set=eval_set,
callbacks=callbacks)
# 예측
y_pred_lgbm = lgbm_clf.predict(X_test)
y_pred_proba_lgbm = lgbm_clf.predict_proba(X_test)[:, 1]
# 평가
accuracy_lgbm = accuracy_score(y_test, y_pred_lgbm)
print(f"\nLightGBM 정확도: {accuracy_lgbm:.4f}")
print("\nConfusion Matrix (LightGBM):\n", confusion_matrix(y_test, y_pred_lgbm))
print("\nClassification Report (LightGBM):\n", classification_report(y_test, y_pred_lgbm))
# 특성 중요도 확인
# lgb.plot_importance(lgbm_clf, max_num_features=10)
# plt.show()
나. LightGBM 고유 API 사용
- XGBoost와 유사하게 자체 데이터 구조(
Dataset)와 학습 API를 가집니다.
# 1. Dataset 생성 (LightGBM 전용 데이터 구조)
lgb_train = lgb.Dataset(data=X_train, label=y_train)
lgb_eval = lgb.Dataset(data=X_test, label=y_test, reference=lgb_train) # reference는 학습 데이터셋과 동일한 특성 사용 명시
# 2. 파라미터 설정 (딕셔너리 형태)
params_lgb = {
'objective': 'binary',
'metric': 'binary_logloss',
'boosting_type': 'gbdt',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9, # colsample_bytree와 유사
'bagging_fraction': 0.8, # subsample과 유사
'bagging_freq': 5,
'verbose': -1, # 메시지 출력 안 함 (0 이상으로 설정 시 출력)
'seed': 42
}
num_boost_round_lgb = 200
# 3. 모델 학습 (lgb.train)
# callbacks 파라미터를 통해 조기 종료 설정
callbacks_native = [lgb.early_stopping(stopping_rounds=10, verbose=1)]
bst_model_lgb = lgb.train(
params=params_lgb,
train_set=lgb_train,
num_boost_round=num_boost_round_lgb,
valid_sets=[lgb_train, lgb_eval], # 학습셋과 검증셋 모두 전달 가능
callbacks=callbacks_native
)
# 4. 예측 (확률값 반환)
pred_probs_bst_lgb = bst_model_lgb.predict(X_test, num_iteration=bst_model_lgb.best_iteration)
# 확률을 이진 클래스로 변환 (임계값 0.5 기준)
preds_bst_lgb = [1 if prob > 0.5 else 0 for prob in pred_probs_bst_lgb]
# 5. 평가
accuracy_bst_lgb = accuracy_score(y_test, preds_bst_lgb)
print(f"\nLightGBM (Native API) 정확도: {accuracy_bst_lgb:.4f}")
print(f"최적 부스팅 라운드 (Native API): {bst_model_lgb.best_iteration}")
다. 교차 검증 (lgb.cv)
# lgb.cv를 사용한 교차 검증
cv_results_lgb = lgb.cv(
params=params_lgb,
train_set=lgb_train, # 전체 학습 데이터를 전달 (내부적으로 분할)
num_boost_round=num_boost_round_lgb,
nfold=5, # 5-fold cross-validation
# metrics 파라미터는 params_lgb에 이미 'metric'으로 지정됨
callbacks=callbacks_native, # 조기 종료 콜백 사용
seed=42,
# verbose_eval=50 # cv에서는 직접 지원 안 함, callbacks의 verbose 사용
)
print(f"\nLightGBM CV 결과 (마지막 라운드의 binary_logloss 평균): {cv_results_lgb['valid binary_logloss-mean'][-1]:.4f}")
# cv_results_lgb는 딕셔너리로, 각 지표의 평균과 표준편차를 라운드별로 담고 있음
# 예: cv_results_lgb['valid binary_logloss-mean']
# 최적 라운드는 조기 종료에 의해 결정되므로, 마지막 라운드의 값이 최적값 근처일 것임.
# (또는 len(cv_results_lgb['valid binary_logloss-mean']) 으로 실제 수행된 라운드 수 확인 가능)
print(f"실제 수행된 CV 라운드 수: {len(cv_results_lgb['valid binary_logloss-mean'])}")
5. LightGBM vs XGBoost
- 속도 및 메모리: 일반적으로 LightGBM이 대용량 데이터에서 더 빠르고 메모리를 적게 사용합니다.
- 정확도: 데이터셋이나 문제 특성에 따라 다르지만, 많은 경우 유사한 수준의 높은 정확도를 보입니다. 때로는 LightGBM이 약간 더 좋거나, 때로는 XGBoost가 더 좋을 수 있습니다.
- 하이퍼파라미터 튜닝: 두 라이브러리 모두 하이퍼파라미터 튜닝이 중요합니다. LightGBM은
num_leaves가 핵심적인 역할을 합니다. - 범주형 특성 처리: LightGBM이 범주형 특성을 더 직접적이고 효율적으로 처리하는 기능을 제공합니다.
- 작은 데이터셋: LightGBM의 리프 중심 분할 방식은 작은 데이터셋에서는 과적합되기 쉬우므로,
max_depth를 적절히 제한하고num_leaves를 너무 크게 설정하지 않는 것이 중요합니다.
추가 학습 자료
- LightGBM 공식 문서
- Why LightGBM is a great choice for Machine Learning tasks (Neptune.ai Blog)
- LightGBM vs XGBoost (Towards Data Science)
다음 학습 내용
- Day 79: 시계열 분석 소개 (Introduction to Time Series Analysis) - 시간 순서대로 기록된 데이터 분석의 기초.
Day 79: 시계열 분석 소개 (Introduction to Time Series Analysis)
학습 목표
- 시계열 데이터(Time Series Data)의 정의와 특징 이해
- 시계열 분석의 주요 목적(예측, 패턴 파악 등) 학습
- 시계열 데이터의 주요 구성 요소 파악:
- 추세 (Trend)
- 계절성 (Seasonality)
- 주기성 (Cyclicality)
- 불규칙 요소 (Irregular/Random Component)
- 시계열 데이터 분석의 기본 단계 소개
- 정상성(Stationarity)의 개념과 중요성 학습
1. 시계열 데이터 (Time Series Data)란?
- 정의: 시간의 흐름에 따라 일정한 간격으로 관찰되거나 기록된 데이터들의 수열(Sequence).
- 특징:
- 시간적 순서 의존성: 데이터 포인트들이 시간 순서대로 정렬되어 있으며, 과거의 값이 미래의 값에 영향을 미칩니다. (자기상관성, Autocorrelation)
- 일정한 시간 간격: 보통 초, 분, 시간, 일, 주, 월, 분기, 연 단위 등 일정한 시간 간격으로 수집됩니다.
- 예시:
- 일별 주가 (Stock prices)
- 월별 강수량 (Monthly rainfall)
- 연도별 GDP 성장률 (Annual GDP growth rate)
- 시간별 웹사이트 방문자 수 (Hourly website traffic)
- 일별 코로나19 확진자 수
- 센서에서 주기적으로 수집되는 데이터
2. 시계열 분석 (Time Series Analysis)의 목적
- 과거 패턴 이해: 데이터에 내재된 추세, 계절성, 주기성 등의 패턴을 파악합니다.
- 미래 예측 (Forecasting): 과거의 패턴을 기반으로 미래의 값을 예측합니다. (가장 일반적인 목적)
- 이상 탐지 (Anomaly Detection): 일반적인 패턴에서 벗어나는 특이한 관측치를 찾아냅니다.
- 제어 (Control): 시계열 데이터를 모니터링하고 특정 목표를 달성하기 위해 시스템을 제어합니다. (예: 공정 관리)
- 가설 검정: 시간의 흐름에 따른 특정 현상의 변화나 관계를 통계적으로 검증합니다.
3. 시계열 데이터의 주요 구성 요소
시계열 데이터는 일반적으로 다음과 같은 요소들의 결합으로 구성될 수 있다고 가정합니다. (분해, Decomposition)
가. 추세 (Trend, Tt)
- 데이터가 장기적으로 증가하거나 감소하거나 또는 일정한 수준을 유지하는 경향.
- 예: 기술 발전으로 인한 생산성 증가, 인구 증가에 따른 수요 증가.
나. 계절성 (Seasonality, St)
- 특정 기간(보통 1년 이내)을 주기로 반복적으로 나타나는 패턴.
- 달력상의 요인(월, 분기, 요일, 휴일 등)과 관련이 깊습니다.
- 예: 여름철 아이스크림 판매량 증가, 연말연시 쇼핑객 증가, 주말 교통량 변화.
다. 주기성 (Cyclicality / Cycle, Ct)
- 계절성보다 긴 기간(보통 1년 이상)을 가지며, 고정된 주기가 아닌 불규칙적인 변동 패턴.
- 주로 경제 순환(경기 변동), 비즈니스 사이클 등과 관련됩니다.
- 계절성만큼 예측하기 어렵고, 주기가 일정하지 않을 수 있습니다.
라. 불규칙 요소 (Irregular / Random Component, εt / It)
- 추세, 계절성, 주기성으로 설명되지 않는 예측 불가능한 무작위 변동.
- 노이즈(Noise) 또는 잔차(Residual)라고도 불립니다.
- 이상치(Outlier)나 갑작스러운 사건의 영향을 포함할 수 있습니다.
시계열 분해 모델
- 덧셈 모델 (Additive Model): Yt = Tt + St + Ct + εt
- 각 구성 요소의 크기가 시계열의 수준과 관계없이 일정하다고 가정.
- 곱셈 모델 (Multiplicative Model): Yt = Tt * St * Ct * εt
- 각 구성 요소의 크기가 시계열의 수준에 비례하여 변한다고 가정. (예: 추세가 증가하면 계절적 변동폭도 커짐)
- 로그 변환을 통해 덧셈 모델로 변환하여 분석하기도 합니다: log(Yt) = log(Tt) + log(St) + log(Ct) + log(εt)
 (이미지 출처: Forecasting: Principles and Practice by Hyndman & Athanasopoulos)
(이미지 출처: Forecasting: Principles and Practice by Hyndman & Athanasopoulos)
4. 시계열 데이터 분석의 기본 단계
- 데이터 수집 및 시각화:
- 시간의 흐름에 따른 데이터를 수집하고, 라인 플롯(Line Plot) 등을 통해 시각화하여 전반적인 패턴을 파악합니다.
- 데이터 전처리:
- 결측치 처리, 이상치 탐지 및 처리.
- 필요시 로그 변환, 차분(Differencing) 등을 수행하여 데이터 안정화.
- 시계열 분해 (Decomposition):
- 추세, 계절성, 불규칙 요소 등을 분리하여 각 구성 요소의 특징을 분석합니다. (예: 이동 평균법, STL 분해)
- 정상성 확인 (Stationarity Check):
- 시계열 데이터가 정상성을 만족하는지 확인합니다. 많은 시계열 모델은 정상성을 가정합니다.
- 비정상 시계열의 경우 차분 등을 통해 정상 시계열로 변환합니다.
- 모델 선택 및 학습:
- 데이터의 특징과 분석 목적에 맞는 시계열 모델을 선택합니다. (예: ARIMA, 지수평활법, Prophet, LSTM 등)
- 학습 데이터를 사용하여 모델 파라미터를 추정합니다.
- 모델 진단 및 평가:
- 학습된 모델이 데이터를 잘 설명하는지, 잔차가 백색 잡음(White Noise)의 특성을 보이는지 등을 진단합니다.
- 예측 성능 평가지표(MAE, MSE, RMSE, MAPE 등)를 사용하여 모델을 평가합니다.
- 예측 (Forecasting):
- 최종 선택된 모델을 사용하여 미래 값을 예측합니다.
5. 정상성 (Stationarity)
- 정의: 시계열의 통계적 특성(평균, 분산, 자기공분산 등)이 시간의 흐름에 따라 변하지 않고 일정하게 유지되는 성질.
- 중요성: 많은 전통적인 시계열 모델(예: ARIMA)은 데이터가 정상성을 만족한다고 가정합니다. 비정상 시계열은 예측의 불확실성을 높이고 모델링을 어렵게 만듭니다.
- 종류:
- 강한 정상성 (Strict Stationarity): 시계열의 모든 분포가 시간에 따라 변하지 않음. (매우 엄격한 조건)
- 약한 정상성 (Weak Stationarity / Covariance Stationarity):
- 평균이 시간에 관계없이 일정 (No Trend).
- 분산이 시간에 관계없이 일정 (Homoscedasticity).
- 두 시점 간의 공분산(자기공분산)은 시차(Lag)에만 의존하고, 특정 시점에는 의존하지 않음.
- 정상성 확인 방법:
- 시각적 확인: 시계열 그림에서 추세나 계절성, 변동하는 분산 등이 관찰되는지 확인.
- 자기상관 함수 (ACF, Autocorrelation Function) 플롯: ACF가 천천히 감소하면 비정상성을 의심.
- 단위근 검정 (Unit Root Test): 통계적 가설 검정 방법. (예: ADF 테스트 - Augmented Dickey-Fuller Test, KPSS 테스트)
- ADF 검정: 귀무가설(H0)은 “단위근이 존재한다 (비정상 시계열이다)”. p-value가 유의수준(예: 0.05)보다 작으면 귀무가설을 기각하고 정상 시계열로 판단.
- 비정상 시계열을 정상 시계열로 변환하는 방법:
- 차분 (Differencing): 현재 시점의 값에서 이전 시점의 값을 빼는 것. (dt = Yt - Yt-1). 추세를 제거하는 데 효과적.
- 로그 변환 (Log Transformation): 분산이 시간에 따라 증가하는 경우 분산을 안정화시키는 데 도움.
- 계절 차분 (Seasonal Differencing): 계절성을 제거하기 위해 특정 계절 주기만큼 떨어진 값을 빼는 것.
추가 학습 자료
- Forecasting: Principles and Practice (3rd ed) by Rob J Hyndman and George Athanasopoulos (온라인 책) - (시계열 분석 및 예측 분야의 교과서적인 자료)
- Stationarity in time series analysis (Towards Data Science)
- Introduction to Time Series Analysis in Python (DataCamp)
다음 학습 내용
- Day 80: 시계열을 위한 ARIMA 모델 (ARIMA models for Time Series) - 대표적인 전통적 시계열 예측 모델.
Day 80: 시계열을 위한 ARIMA 모델 (ARIMA models for Time Series)
학습 목표
- ARIMA (AutoRegressive Integrated Moving Average) 모델의 개념과 구성 요소 이해
- AR (AutoRegressive, 자기회귀) 모델
- MA (Moving Average, 이동평균) 모델
- I (Integrated, 통합/차분)
- ACF (Autocorrelation Function)와 PACF (Partial Autocorrelation Function)를 사용한 ARIMA 모델 식별 (차수 결정) 방법 학습
- ARIMA 모델 구축 및 예측 과정 이해
statsmodels라이브러리를 사용한 ARIMA 모델 구현 방법 숙지
1. ARIMA 모델 소개
- 정의: 과거 자신의 관측값(AR)과 과거 예측 오차(MA)를 사용하여 현재 시점의 값을 설명하고 예측하는, 가장 널리 사용되는 전통적인 시계열 예측 모델 중 하나입니다.
- ARIMA(p, d, q) 형태로 표현됩니다:
- p: AR 모델의 차수 (자기회귀 항의 수, 과거 몇 개의 관측값을 사용할지).
- d: 차분(Differencing) 횟수 (시계열을 정상성(Stationary)으로 만들기 위해 필요한 차분 횟수).
- q: MA 모델의 차수 (이동평균 항의 수, 과거 몇 개의 예측 오차를 사용할지).
- ARIMA 모델은 **정상 시계열(Stationary Time Series)**을 가정합니다. 만약 시계열이 비정상이면, 차분(d)을 통해 정상 시계열로 변환한 후 ARMA(p,q) 모델을 적용합니다.
2. ARIMA 모델의 구성 요소
가. AR (AutoRegressive, 자기회귀) 모델 - AR(p)
- 개념: 현재 시점의 값(Yt)이 과거 p개의 자신의 관측값(Yt-1, …, Yt-p)들의 선형 결합으로 설명된다고 가정하는 모델.
- 수식: Yt = c + φ1Yt-1 + φ2Yt-2 + … + φpYt-p + εt
- Yt: 현재 시점의 값
- c: 상수항
- φi: i번째 자기회귀 계수 (모델 파라미터)
- Yt-i: i 시점 전의 과거 값
- εt: 현재 시점의 백색 잡음(White Noise) 오차항 (평균 0, 일정한 분산)
- 특징: 과거의 값이 현재 값에 직접적인 영향을 미치는 시계열 패턴을 모델링합니다.
나. MA (Moving Average, 이동평균) 모델 - MA(q)
- 개념: 현재 시점의 값(Yt)이 과거 q개의 예측 오차(εt-1, …, εt-q)들의 선형 결합과 현재 시점의 예측 오차(εt)로 설명된다고 가정하는 모델.
- 주의: 여기서 이동평균은 시계열 데이터의 단순 이동평균(Smoothing 기법)과는 다른 개념입니다. 예측 오차의 이동평균을 의미합니다.
- 수식: Yt = μ + εt + θ1εt-1 + θ2εt-2 + … + θqεt-q
- μ: 시계열의 평균 (또는 상수항)
- εt: 현재 시점의 백색 잡음 오차항
- θi: i번째 이동평균 계수 (모델 파라미터)
- εt-i: i 시점 전의 예측 오차
- 특징: 과거의 예측 불가능했던 충격(Shock)이나 오차가 현재 값에 영향을 미치는 시계열 패턴을 모델링합니다.
다. I (Integrated, 통합/차분) - d
- 개념: 비정상 시계열을 정상 시계열로 변환하기 위해 필요한 차분(Differencing) 횟수를 의미합니다.
- d=0: 시계열이 이미 정상성을 만족하는 경우 (ARMA(p,q) 모델).
- d=1: 1차 차분을 통해 정상성을 만족하는 경우 (Y’t = Yt - Yt-1).
- d=2: 2차 차분을 통해 정상성을 만족하는 경우. (보통 0, 1, 2 정도의 값을 가짐)
ARMA(p,q) 모델
- AR(p) 모델과 MA(q) 모델을 결합한 형태로, 정상 시계열에 적용됩니다.
- 수식: Yt = c + φ1Yt-1 + … + φpYt-p + εt + θ1εt-1 + … + θqεt-q
3. ARIMA 모델 차수 결정 (p, d, q 식별)
- 적절한 p, d, q 값을 결정하는 것은 ARIMA 모델링에서 매우 중요한 단계입니다.
가. 차분 횟수 (d) 결정
- 시계열 시각화: 원본 시계열 그림을 보고 추세나 계절성이 있는지 확인합니다.
- 단위근 검정 (Unit Root Test): ADF(Augmented Dickey-Fuller) Test, KPSS Test 등을 수행하여 정상성을 통계적으로 검정합니다.
- ADF 검정: 귀무가설 “단위근이 존재한다 (비정상)” vs 대립가설 “단위근이 없다 (정상)”. p-value < 0.05 이면 정상으로 판단.
- 비정상으로 판단되면 1차 차분을 수행하고, 다시 정상성 검정을 합니다. 여전히 비정상이면 2차 차분을 시도합니다.
- 일반적으로 d는 0, 1, 또는 2의 값을 가집니다. 과도한 차분은 불필요한 복잡성을 야기할 수 있습니다.
나. AR 차수 (p) 및 MA 차수 (q) 결정
- 차분된 (정상화된) 시계열에 대해 **ACF (Autocorrelation Function, 자기상관 함수)**와 PACF (Partial Autocorrelation Function, 편자기상관 함수) 플롯을 사용하여 p와 q를 추정합니다.
-
ACF (자기상관 함수):
- 시차(Lag) k에 따른 현재 시점과 k 시점 전의 값 사이의 상관관계를 나타냅니다.
- MA(q) 모델의 특징: ACF는 시차 q 이후에 급격히 감소하여 0에 가까워집니다 ( 절단점, Cut-off at lag q).
- AR(p) 모델의 특징: ACF는 지수적으로 또는 사인파 형태로 천천히 감소합니다.
-
PACF (편자기상관 함수):
- 시차 k에 따른 현재 시점과 k 시점 전의 값 사이의 “순수한” 상관관계를 나타냅니다. (즉, 그 사이의 시차들의 영향을 제거한 후의 상관관계)
- AR(p) 모델의 특징: PACF는 시차 p 이후에 급격히 감소하여 0에 가까워집니다 (절단점, Cut-off at lag p).
- MA(q) 모델의 특징: PACF는 지수적으로 또는 사인파 형태로 천천히 감소합니다.
ACF와 PACF를 이용한 (p, q) 선택 가이드라인 (Box-Jenkins 방법론)
| 모델 유형 | ACF 패턴 | PACF 패턴 |
|---|---|---|
| AR(p) | 점진적 감소 (Tails off) | 시차 p 이후 절단 (Cuts off after lag p) |
| MA(q) | 시차 q 이후 절단 (Cuts off after lag q) | 점진적 감소 (Tails off) |
| ARMA(p,q) | 점진적 감소 (Tails off after lag q-p) | 점진적 감소 (Tails off after lag p-q) |
| (일반적) | 점진적 감소 | 점진적 감소 |
- 실제로는 ACF/PACF 플롯이 명확하게 나타나지 않는 경우가 많아, 여러 (p,q) 조합을 시도하고 AIC, BIC와 같은 정보 기준(Information Criteria)을 사용하여 최적의 모델을 선택하기도 합니다.
- AIC (Akaike Information Criterion)
- BIC (Bayesian Information Criterion)
- 이 값들이 낮을수록 더 좋은 모델로 간주합니다. (모델의 적합도와 복잡도 간의 균형 고려)
4. ARIMA 모델 구축 및 예측 과정
- 데이터 준비 및 시각화: 시계열 데이터를 로드하고 시간의 흐름에 따른 패턴을 확인합니다.
- 정상성 확인 및 차분 (d 결정): 단위근 검정 등을 통해 정상성을 확인하고, 필요하면 차분을 수행합니다.
- ACF/PACF 분석 (p, q 결정): 차분된 시계열의 ACF와 PACF 플롯을 그려 AR 및 MA 차수를 잠정적으로 결정합니다.
- 모델 학습: 결정된 (p, d, q) 값으로 ARIMA 모델을 학습시킵니다. (모델 파라미터 추정)
- 모델 진단: 학습된 모델의 잔차(Residuals)가 백색 잡음의 특성을 보이는지 확인합니다. (잔차의 ACF/PACF 플롯, 정규성 검정 등)
- (선택) 모델 비교 및 선택: 여러 (p,d,q) 조합에 대해 AIC, BIC 등을 비교하여 최적 모델을 선택합니다.
- 예측: 최종 선택된 모델을 사용하여 미래 값을 예측합니다.
- 예측 성능 평가: 실제 값과 예측 값을 비교하여 MAE, MSE, RMSE, MAPE 등으로 예측 성능을 평가합니다.
5. statsmodels 라이브러리를 사용한 ARIMA 모델 구현
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA # ARIMA 모델
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf # ACF, PACF 플롯
from statsmodels.tsa.stattools import adfuller # ADF 검정
# import pmdarima as pm # auto_arima 사용 시 (선택 사항)
# 예제 시계열 데이터 생성 (간단한 ARMA(1,1) 과정 + 추세)
np.random.seed(42)
n_samples = 200
ar_params = np.array([0.5]) # AR(1) 계수
ma_params = np.array([0.3]) # MA(1) 계수
# ARMA 과정 생성 함수 (statsmodels에 있음)
from statsmodels.tsa.arima_process import ArmaProcess
arma_process = ArmaProcess(ar_params, ma_params)
data_stationary = arma_process.generate_sample(nsample=n_samples)
# 추세 추가 (비정상 시계열로 만들기)
trend = np.linspace(0, 10, n_samples)
data_nonstationary = data_stationary + trend
time_index = pd.date_range(start='2020-01-01', periods=n_samples, freq='D')
series = pd.Series(data_nonstationary, index=time_index)
# 1. 데이터 시각화
plt.figure(figsize=(10, 4))
plt.plot(series)
plt.title("Original Time Series")
plt.show()
# 2. 정상성 확인 및 차분 (d 결정)
# ADF 검정
result_adf = adfuller(series)
print(f'ADF Statistic: {result_adf[0]}')
print(f'p-value: {result_adf[1]}') # p-value가 크므로 비정상으로 판단 (귀무가설 기각 실패)
# 1차 차분
series_diff1 = series.diff().dropna() # diff()는 차분, dropna()는 결측치 제거
plt.figure(figsize=(10, 4))
plt.plot(series_diff1)
plt.title("1st Differenced Time Series")
plt.show()
result_adf_diff1 = adfuller(series_diff1)
print(f'\nADF Statistic (1st Diff): {result_adf_diff1[0]}')
print(f'p-value (1st Diff): {result_adf_diff1[1]}') # p-value가 작으므로 정상으로 판단 (d=1)
# d = 1 로 결정
# 3. ACF/PACF 분석 (p, q 결정) - 차분된 시계열 사용
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
plot_acf(series_diff1, ax=ax[0], lags=20) # lags는 최대 시차
plot_pacf(series_diff1, ax=ax[1], lags=20, method='ywm') # method='ols' or 'ywm' 등
plt.suptitle("ACF and PACF of 1st Differenced Series")
plt.show()
# ACF: lag 1 이후 절단? -> q=1 가능성
# PACF: lag 1 이후 절단? -> p=1 가능성
# 잠정적으로 ARIMA(1,1,1) 또는 ARIMA(1,1,0), ARIMA(0,1,1) 등을 고려
# 4. 모델 학습 (예: ARIMA(1,1,1))
# order=(p, d, q)
model = ARIMA(series, order=(1, 1, 1)) # 원본 시계열과 차분 횟수 d를 함께 전달
results = model.fit()
print(results.summary())
# 5. 모델 진단 (잔차 분석)
residuals = results.resid
fig, ax = plt.subplots(1, 2, figsize=(12, 3))
residuals.plot(title="Residuals", ax=ax[0])
plot_acf(residuals, ax=ax[1], lags=20)
plt.suptitle("Residuals Analysis")
plt.show() # 잔차가 백색 잡음인지 확인 (ACF가 거의 0에 가까워야 함)
# 6. (선택) auto_arima 사용 (pmdarima 라이브러리 필요: pip install pmdarima)
# from pmdarima.arima import auto_arima
# auto_model = auto_arima(series,
# start_p=0, start_q=0,
# max_p=3, max_q=3,
# d=1, # 또는 D=None으로 두어 자동 결정
# seasonal=False, # 비계절성 ARIMA
# trace=True, # 모델 탐색 과정 출력
# error_action='ignore',
# suppress_warnings=True,
# stepwise=True) # 단계적 탐색
# print("\nAuto ARIMA Best Model Summary:")
# print(auto_model.summary())
# best_order = auto_model.order # (p,d,q)
# 7. 예측
n_forecast = 30
forecast_results = results.get_forecast(steps=n_forecast)
forecast_mean = forecast_results.predicted_mean # 예측값
forecast_ci = forecast_results.conf_int() # 신뢰구간
plt.figure(figsize=(12, 5))
plt.plot(series, label='Observed')
plt.plot(forecast_mean, label='Forecast', color='red')
plt.fill_between(forecast_ci.index,
forecast_ci.iloc[:, 0], # 하한
forecast_ci.iloc[:, 1], # 상한
color='pink', alpha=0.3, label='Confidence Interval')
plt.title("Time Series Forecast with ARIMA(1,1,1)")
plt.legend()
plt.show()
# 8. 예측 성능 평가 (실제로는 테스트 데이터셋으로 평가해야 함)
# 예: 마지막 30개를 테스트 데이터로 사용했다고 가정하고 평가
# train_series = series[:-30]
# test_series = series[-30:]
# model_eval = ARIMA(train_series, order=(1,1,1))
# results_eval = model_eval.fit()
# forecast_eval_mean = results_eval.get_forecast(steps=30).predicted_mean
# from sklearn.metrics import mean_squared_error
# mse = mean_squared_error(test_series, forecast_eval_mean)
# print(f"\nMean Squared Error (Test): {mse:.4f}")
6. SARIMA (Seasonal ARIMA) 모델
- ARIMA 모델은 계절성(Seasonality)을 직접적으로 다루지 못합니다.
- 시계열 데이터에 계절성이 포함된 경우, SARIMA(p, d, q)(P, D, Q)m 모델을 사용합니다.
- (p, d, q): 비계절성 부분의 차수 (ARIMA와 동일).
- (P, D, Q): 계절성 부분의 차수.
- m: 계절 주기의 길이 (예: 월별 데이터면 m=12, 분기별 데이터면 m=4).
statsmodels.tsa.statespace.SARIMAX클래스를 사용하여 구현할 수 있습니다.
추가 학습 자료
- ARIMA Model for Time Series Forecasting (Machine Learning Mastery)
- A Gentle Introduction to SARIMA for Time Series Forecasting in Python (Machine Learning Mastery)
- Statsmodels ARIMA Documentation
- Forecasting: Principles and Practice - Chapter 9: ARIMA models (온라인 책)
다음 학습 내용
- Day 81: 모델 배포 소개 (Introduction to Model Deployment) - 개발한 머신러닝 모델을 실제 환경에서 사용 가능하도록 만드는 과정.
Day 81: 모델 배포 소개 (Introduction to Model Deployment)
학습 목표
- 머신러닝 모델 배포의 정의와 중요성 이해
- 모델 배포가 머신러닝 프로젝트 생명주기에서 차지하는 위치 파악
- 다양한 모델 배포 전략 및 방법론 소개
- 배치 예측 (Batch Prediction) vs 실시간 예측 (Real-time Prediction)
- 온프레미스 (On-premise) vs 클라우드 (Cloud) 배포
- 모델 배포 시 고려해야 할 주요 사항 학습
1. 머신러닝 모델 배포 (Model Deployment)란?
- 정의: 개발 및 학습이 완료된 머신러닝 모델을 실제 운영 환경에서 사용자들이나 다른 시스템이 접근하여 예측 결과를 활용할 수 있도록 통합하는 과정입니다.
- 모델을 단순히 만드는 것을 넘어, 실제 비즈니스 가치를 창출하거나 문제를 해결하는 데 사용되도록 하는 핵심 단계입니다.
- MLOps (Machine Learning Operations)의 중요한 부분입니다.
2. 모델 배포의 중요성
- 가치 실현: 아무리 좋은 모델이라도 배포되어 활용되지 않으면 아무런 가치가 없습니다. 배포를 통해 모델의 예측 능력이 실제 의사 결정이나 서비스에 기여하게 됩니다.
- 자동화 및 효율성: 수동으로 예측을 수행하는 대신, 배포된 모델은 자동화된 방식으로 예측을 제공하여 시간과 노력을 절약합니다.
- 확장성: 사용자 증가나 데이터량 증가에 따라 예측 서비스를 확장할 수 있는 기반을 마련합니다.
- 지속적인 개선: 배포된 모델의 성능을 모니터링하고, 필요에 따라 재학습 및 재배포를 통해 모델을 지속적으로 개선할 수 있습니다.
3. 머신러닝 프로젝트 생명주기에서의 배포 위치
일반적인 머신러닝 프로젝트 생명주기는 다음과 같습니다:
- 문제 정의 (Problem Definition): 해결하고자 하는 문제와 목표를 명확히 합니다.
- 데이터 수집 (Data Collection): 관련된 데이터를 수집합니다.
- 데이터 전처리 및 탐색 (Data Preprocessing & EDA): 데이터를 정제하고 분석 가능한 형태로 만들며, 데이터의 특징을 파악합니다.
- 특징 공학 (Feature Engineering): 모델 성능 향상을 위해 유용한 특징을 생성하거나 선택합니다.
- 모델 선택 및 학습 (Model Selection & Training): 적절한 머신러닝 알고리즘을 선택하고 학습 데이터를 사용하여 모델을 학습시킵니다.
- 모델 평가 (Model Evaluation): 학습된 모델의 성능을 다양한 지표로 평가합니다.
- 하이퍼파라미터 튜닝 (Hyperparameter Tuning): 모델 성능을 최적화하기 위해 하이퍼파라미터를 조정합니다.
- 모델 배포 (Model Deployment): 최종 선택된 모델을 실제 운영 환경에 배포합니다.
- 모델 모니터링 및 유지보수 (Model Monitoring & Maintenance): 배포된 모델의 성능을 지속적으로 모니터링하고, 데이터 변화나 성능 저하 시 모델을 업데이트하거나 재학습합니다.
4. 다양한 모델 배포 전략 및 방법론
가. 예측 방식에 따른 분류
-
배치 예측 (Batch Prediction / Offline Prediction):
- 개념: 일정 기간 동안 수집된 대량의 데이터를 한꺼번에 모델에 입력하여 예측 결과를 일괄적으로 생성하는 방식입니다.
- 특징:
- 실시간성이 중요하지 않은 경우에 사용됩니다.
- 예측 결과를 데이터베이스나 파일에 저장해두고 필요할 때 사용합니다.
- 주기적인 작업(예: 매일 밤, 매주)으로 스케줄링될 수 있습니다.
- 예시:
- 매일 밤 고객 이탈 예측 업데이트.
- 주간 판매량 예측.
- 월간 보고서 생성을 위한 데이터 분석.
- 장점: 구현이 비교적 간단하고, 자원 활용을 효율적으로 관리할 수 있습니다.
- 단점: 실시간 예측이 불가능하며, 예측 결과가 최신 데이터에 즉각적으로 반영되지 않을 수 있습니다.
-
실시간 예측 (Real-time Prediction / Online Prediction / On-demand Prediction):
- 개념: 사용자의 요청이나 새로운 데이터 발생 시 즉각적으로 모델에 입력하여 예측 결과를 반환하는 방식입니다.
- 특징:
- 낮은 지연 시간(Low Latency)이 중요합니다.
- 보통 API(Application Programming Interface) 형태로 모델을 제공합니다.
- 예시:
- 웹사이트나 앱에서 사용자의 행동에 따른 실시간 제품 추천.
- 금융 거래 사기 탐지 시스템.
- 이미지 인식 서비스 (사진 업로드 시 즉시 분석).
- 챗봇 응답 생성.
- 장점: 즉각적인 예측 결과를 통해 사용자 경험을 향상시키거나 빠른 의사 결정을 지원할 수 있습니다.
- 단점: 인프라 구축 및 관리가 더 복잡하며, 높은 가용성과 안정성이 요구됩니다.
나. 배포 환경에 따른 분류
-
온프레미스 (On-premise) 배포:
- 개념: 기업이나 조직이 자체적으로 보유하고 관리하는 서버나 데이터 센터에 모델을 배포하는 방식입니다.
- 장점:
- 데이터 보안 및 통제에 유리합니다 (민감한 데이터를 외부로 보내지 않음).
- 기존 인프라를 활용할 수 있습니다.
- 단점:
- 초기 인프라 구축 비용이 많이 들 수 있습니다.
- 확장성 확보 및 유지보수에 전문 인력과 노력이 필요합니다.
-
클라우드 (Cloud) 배포:
- 개념: AWS (Amazon Web Services), GCP (Google Cloud Platform), Azure (Microsoft Azure) 등 클라우드 서비스 제공업체의 플랫폼을 사용하여 모델을 배포하는 방식입니다.
- 클라우드 플랫폼 제공 서비스 예시:
- IaaS (Infrastructure as a Service): 가상 머신(VM)을 직접 설정하고 모델 배포 (예: AWS EC2, GCP Compute Engine).
- PaaS (Platform as a Service): 모델 배포 및 관리를 위한 플랫폼 제공 (예: AWS Elastic Beanstalk, Google App Engine).
- MLaaS (Machine Learning as a Service): 머신러닝 모델 학습, 배포, 관리를 위한 특화된 서비스 (예: Amazon SageMaker, Google AI Platform/Vertex AI, Azure Machine Learning).
- FaaS (Function as a Service) / Serverless: 특정 이벤트 발생 시 코드를 실행하는 서버리스 환경 (예: AWS Lambda, Google Cloud Functions). 간단한 모델 API 배포에 유용.
- 장점:
- 초기 비용 부담이 적고, 사용한 만큼만 비용을 지불합니다 (Pay-as-you-go).
- 필요에 따라 쉽게 확장(Scalability) 및 축소할 수 있습니다.
- 다양한 관리형 서비스(Managed Services)를 통해 인프라 관리 부담을 줄일 수 있습니다.
- MLOps 도구 및 통합 환경을 제공하는 경우가 많습니다.
- 단점:
- 데이터 보안 및 규정 준수에 대한 고려가 필요합니다.
- 특정 클라우드 플랫폼에 종속될 수 있습니다 (Vendor Lock-in).
- 장기적으로 비용이 증가할 수 있습니다.
다. 기타 배포 방식
- 엣지 배포 (Edge Deployment): 모델을 최종 사용자의 디바이스(스마트폰, IoT 기기, 자율주행차 등)나 엣지 서버에 직접 배포하는 방식입니다.
- 장점: 네트워크 지연 시간 감소, 오프라인 작동 가능, 데이터 프라이버시 향상.
- 단점: 디바이스의 계산 능력 및 메모리 제약, 모델 경량화 필요. (예: TensorFlow Lite, ONNX Runtime)
- 데이터베이스 내 모델 배포 (In-database Deployment): 일부 데이터베이스 시스템은 내부에 머신러닝 모델을 통합하여 SQL 쿼리 등을 통해 예측을 수행할 수 있는 기능을 제공합니다.
5. 모델 배포 시 고려해야 할 주요 사항
- 모델 직렬화 (Model Serialization): 학습된 모델을 파일 형태로 저장(Pickle, Joblib, HDF5, ONNX 등)하고, 배포 환경에서 다시 로드하여 사용할 수 있도록 해야 합니다.
- API 디자인 (for Real-time Prediction):
- 입력 데이터 형식 (JSON, Protocol Buffers 등) 및 출력 데이터 형식 정의.
- REST API, gRPC 등 프로토콜 선택.
- 인증 및 권한 부여.
- 확장성 (Scalability): 증가하는 요청량이나 데이터 처리를 감당할 수 있도록 시스템을 설계해야 합니다 (예: 로드 밸런싱, 오토 스케일링).
- 성능 (Performance):
- 지연 시간 (Latency): 예측 요청에 대한 응답 시간. 실시간 서비스에서 매우 중요.
- 처리량 (Throughput): 단위 시간당 처리할 수 있는 예측 요청 수.
- 모니터링 (Monitoring):
- 시스템 모니터링: CPU, 메모리, 네트워크 등 인프라 상태.
- 모델 성능 모니터링: 예측 정확도, 데이터 드리프트(Data Drift - 입력 데이터 분포 변화), 컨셉 드리프트(Concept Drift - 타겟 변수와 입력 변수 간의 관계 변화) 등.
- 보안 (Security): 모델 및 데이터에 대한 무단 접근 방지, API 엔드포인트 보안.
- 버전 관리 (Versioning): 모델, 코드, 데이터, 배포 환경 등에 대한 버전 관리를 통해 재현성 및 롤백 가능성 확보.
- A/B 테스팅: 새로운 모델을 배포하기 전에 기존 모델과 성능을 비교하거나, 여러 버전의 모델을 동시에 운영하며 사용자 반응을 테스트.
- 비용 (Cost): 인프라, 라이선스, 인력 등 배포 및 운영에 드는 비용.
- 문서화 (Documentation): 배포 과정, API 사용법, 모니터링 방법 등을 문서로 남겨야 합니다.
추가 학습 자료
- Machine Learning Model Deployment (Google Cloud Documentation)
- MLOps: Continuous delivery and automation pipelines in machine learning (Google Cloud Whitepaper)
- An Overview of Model Deployment (Neptune.ai Blog)
- “Designing Machine Learning Systems” by Chip Huyen (책) - (모델 배포를 포함한 MLOps 전반에 대한 심도 있는 내용)
다음 학습 내용
- Day 82: ML 모델 배포를 위한 Flask/Django - 기초 (Flask/Django for deploying ML models - Basics) - 파이썬 웹 프레임워크를 사용하여 간단한 모델 API를 만드는 방법.
Day 82: ML 모델 배포를 위한 Flask/Django - 기초 (Flask/Django for deploying ML models - Basics)
학습 목표
- 파이썬 웹 프레임워크 Flask와 Django의 기본 개념 이해
- 머신러닝 모델을 API 형태로 배포하는 데 웹 프레임워크가 왜 필요한지 학습
- Flask를 사용하여 간단한 머신러닝 모델 예측 API를 만드는 기본 과정 숙지
- Django를 사용한 모델 배포의 간략한 개념 소개 및 Flask와의 비교
1. 웹 프레임워크(Web Framework)란?
- 웹 애플리케이션, 웹 서비스, 웹 API 등을 개발하는 데 필요한 기본적인 구조와 도구들을 제공하는 소프트웨어 프레임워크입니다.
- 반복적인 작업(요청 처리, 라우팅, 데이터베이스 연동, 템플릿 렌더링 등)을 단순화하고 개발 생산성을 높여줍니다.
2. 왜 ML 모델 배포에 웹 프레임워크를 사용하는가?
- 학습된 머신러닝 모델을 다른 애플리케이션이나 사용자가 쉽게 접근하여 사용할 수 있도록 하려면, 모델을 웹 서비스 또는 API 형태로 노출하는 것이 일반적입니다.
- 웹 프레임워크는 다음과 같은 기능을 제공하여 ML 모델 API 개발을 용이하게 합니다:
- HTTP 요청 처리: 클라이언트(사용자, 다른 시스템)로부터 HTTP 요청(GET, POST 등)을 받아 처리합니다.
- 라우팅 (Routing): 특정 URL 경로(엔드포인트)로 들어오는 요청을 적절한 처리 함수(핸들러)로 연결합니다.
- 데이터 직렬화/역직렬화: 요청으로 들어온 데이터(JSON, 폼 데이터 등)를 파이썬 객체로 변환하고, 모델 예측 결과를 다시 클라이언트가 이해할 수 있는 형태(JSON 등)로 변환합니다.
- 요청/응답 관리: HTTP 헤더, 상태 코드 등을 관리합니다.
- 확장성: 필요에 따라 기능을 추가하거나 다른 서비스와 연동하기 용이합니다.
3. Flask 소개
- 정의: 파이썬으로 작성된 마이크로(Micro) 웹 프레임워크입니다. “마이크로“라는 의미는 핵심 기능을 작고 가볍게 유지하며, 필요한 기능은 확장(Extension)을 통해 추가할 수 있다는 뜻입니다.
- 특징:
- 가볍고 단순함: 배우기 쉽고 빠르게 웹 애플리케이션을 개발할 수 있습니다.
- 유연성: 개발자가 원하는 방식으로 구조를 설계하고 필요한 확장을 선택하여 사용할 수 있습니다.
- 최소한의 기능 제공: URL 라우팅, 요청/응답 처리, 템플릿 엔진(Jinja2) 연동 등 핵심 기능에 집중합니다. 데이터베이스 ORM, 폼 처리 등은 기본으로 제공하지 않고 확장으로 지원.
- 작은 프로젝트나 프로토타이핑, 간단한 API 개발에 적합.
Flask 설치
pip install Flask
간단한 Flask 애플리케이션 예제
# app.py
from flask import Flask, request, jsonify
app = Flask(__name__) # Flask 애플리케이션 객체 생성
# 루트 URL ('/')로 GET 요청이 오면 실행될 함수
@app.route('/')
def home():
return "Hello, Flask!"
# '/greet' URL로 GET 요청이 오고, 'name' 파라미터가 있으면 실행
@app.route('/greet', methods=['GET'])
def greet():
name = request.args.get('name', 'Guest') # URL 파라미터에서 'name' 값 가져오기
return f"Hello, {name}!"
# '/predict' URL로 POST 요청이 오면 실행 (JSON 데이터 예상)
@app.route('/predict', methods=['POST'])
def predict_example():
if request.is_json:
data = request.get_json() # POST 요청의 JSON 데이터 가져오기
# 여기서 data를 사용하여 모델 예측 수행 (예시)
number = data.get('number', 0)
prediction = number * 2
return jsonify({'input_number': number, 'prediction': prediction}) # JSON 형태로 응답
else:
return jsonify({'error': 'Request must be JSON'}), 400 # 400 Bad Request
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=5000) # 개발 서버 실행
# debug=True: 코드 변경 시 자동 재시작, 디버깅 정보 제공 (운영 환경에서는 False)
# host='0.0.0.0': 모든 네트워크 인터페이스에서 접속 허용
# port=5000: 사용할 포트 번호
- 위 코드를
app.py로 저장하고 터미널에서python app.py실행. - 웹 브라우저나
curl등으로 테스트:http://localhost:5000/-> “Hello, Flask!”http://localhost:5000/greet?name=World-> “Hello, World!”curl -X POST -H "Content-Type: application/json" -d '{"number": 10}' http://localhost:5000/predict->{"input_number": 10, "prediction": 20}
4. Flask를 사용한 간단한 ML 모델 예측 API 만들기
가. 모델 준비 (학습 및 직렬화)
- 먼저, 학습된 머신러닝 모델이 파일 형태로 저장되어 있어야 합니다. (예:
pickle,joblib사용) - 여기서는 간단한 Scikit-learn 모델을 예시로 사용합니다.
# train_model.py (모델 학습 및 저장 - 별도 파일로 실행)
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
import joblib # 또는 pickle
# 1. 데이터 로드 및 모델 학습 (간단 예시)
iris = load_iris()
X, y = iris.data, iris.target
# 간단화를 위해 두 개의 클래스만 사용 (0, 1)
X_binary = X[y != 2]
y_binary = y[y != 2]
model = LogisticRegression(solver='liblinear')
model.fit(X_binary, y_binary)
print("모델 학습 완료!")
# 2. 모델 저장
joblib.dump(model, 'iris_binary_model.pkl')
print("모델 저장 완료: iris_binary_model.pkl")
# (선택) 스케일러 등 전처리기도 함께 저장해야 할 수 있음
# from sklearn.preprocessing import StandardScaler
# scaler = StandardScaler()
# X_scaled = scaler.fit_transform(X_binary)
# model.fit(X_scaled, y_binary)
# joblib.dump(scaler, 'iris_scaler.pkl')
# joblib.dump(model, 'iris_binary_model_scaled.pkl')
- 위
train_model.py를 먼저 실행하여iris_binary_model.pkl파일을 생성합니다.
나. Flask API 서버 구현
# flask_api.py
from flask import Flask, request, jsonify
import joblib
import numpy as np
app = Flask(__name__)
# 모델 로드 (애플리케이션 시작 시 한 번만 로드)
try:
model = joblib.load('iris_binary_model.pkl')
print("모델 로드 성공!")
# scaler = joblib.load('iris_scaler.pkl') # 스케일러 사용 시 함께 로드
except FileNotFoundError:
model = None
# scaler = None
print("저장된 모델 파일을 찾을 수 없습니다. 'train_model.py'를 먼저 실행하세요.")
except Exception as e:
model = None
# scaler = None
print(f"모델 로드 중 오류 발생: {e}")
@app.route('/')
def home():
return "Iris Binary Classification API"
@app.route('/predict_iris', methods=['POST'])
def predict_iris():
if model is None:
return jsonify({'error': '모델이 로드되지 않았습니다.'}), 500
if request.is_json:
try:
data = request.get_json()
# 입력 데이터 형식 가정: {"features": [sepal_length, sepal_width, petal_length, petal_width]}
features = data.get('features')
if features is None or not isinstance(features, list) or len(features) != 4:
return jsonify({'error': '입력 데이터 형식이 올바르지 않습니다. "features" 키에 4개의 숫자 리스트를 제공해야 합니다.'}), 400
# 입력 데이터를 NumPy 배열로 변환
input_array = np.array(features).reshape(1, -1) # (1, 4) 형태
# (선택) 스케일링 적용 (학습 시 사용한 스케일러와 동일하게)
# if scaler:
# input_array_scaled = scaler.transform(input_array)
# prediction_proba = model.predict_proba(input_array_scaled)[0] # 각 클래스에 대한 확률
# prediction = model.predict(input_array_scaled)[0] # 예측 클래스
# else:
prediction_proba = model.predict_proba(input_array)[0]
prediction = model.predict(input_array)[0]
class_names = ['setosa', 'versicolor'] # 이진 분류 클래스 이름 (0, 1)
return jsonify({
'input_features': features,
'predicted_class_id': int(prediction),
'predicted_class_name': class_names[int(prediction)],
'probabilities': {'setosa': float(prediction_proba[0]), 'versicolor': float(prediction_proba[1])}
})
except Exception as e:
return jsonify({'error': f'예측 중 오류 발생: {str(e)}'}), 500
else:
return jsonify({'error': 'Request must be JSON'}), 400
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=5001) # 다른 포트 사용
다. API 테스트 (curl 사용)
# flask_api.py 실행 후 터미널에서 아래 명령어 실행
curl -X POST \
-H "Content-Type: application/json" \
-d '{"features": [5.1, 3.5, 1.4, 0.2]}' \
http://localhost:5001/predict_iris
# 예상 응답:
# {
# "input_features": [5.1, 3.5, 1.4, 0.2],
# "predicted_class_id": 0,
# "predicted_class_name": "setosa",
# "probabilities": {
# "setosa": 0.9...,
# "versicolor": 0.0...
# }
# }
curl -X POST \
-H "Content-Type: application/json" \
-d '{"features": [6.0, 2.2, 4.0, 1.0]}' \
http://localhost:5001/predict_iris
# 예상 응답 (versicolor에 가까운 값)
5. Django 소개 및 Flask와의 비교
- 정의: 파이썬으로 작성된 고수준(High-level) 웹 프레임워크로, “배터리 포함(Batteries-included)” 철학을 따릅니다. 즉, 웹 개발에 필요한 대부분의 기능(ORM, 관리자 인터페이스, 폼 처리, 인증 등)을 기본적으로 제공합니다.
- 특징:
- 풀 스택 프레임워크: 웹 개발의 모든 측면을 다룰 수 있는 포괄적인 기능 제공.
- ORM (Object-Relational Mapper): 데이터베이스 작업을 파이썬 객체로 쉽게 처리.
- 강력한 관리자 인터페이스: 모델 데이터를 관리할 수 있는 웹 기반 관리자 페이지 자동 생성.
- 보안 기능: CSRF 방지, XSS 방지 등 기본적인 보안 기능 내장.
- 대규모 프로젝트, 복잡한 웹 애플리케이션 개발에 적합.
Django를 사용한 ML 모델 배포
- Django를 사용하여 ML 모델 API를 만드는 것도 가능하며, Flask와 유사한 방식으로 라우팅, 요청 처리, 모델 로드 및 예측 로직을 구현합니다.
- Django REST framework와 같은 확장을 사용하면 강력한 REST API를 더 쉽게 구축할 수 있습니다.
- 더 많은 기능을 기본 제공하므로 초기 설정이나 학습 곡선이 Flask보다 가파를 수 있지만, 복잡한 요구사항이나 대규모 서비스에는 더 적합할 수 있습니다.
Flask vs Django (ML 모델 API 배포 관점)
| 특징 | Flask | Django |
|---|---|---|
| 철학 | 마이크로 프레임워크, 최소 기능, 높은 유연성 | 풀 스택 프레임워크, “배터리 포함” |
| 학습 곡선 | 낮음, 배우기 쉬움 | 상대적으로 높음 |
| 기본 기능 | 핵심 기능만 제공, 나머지는 확장으로 | ORM, 관리자, 폼, 인증 등 대부분 기능 내장 |
| 프로젝트 규모 | 작거나 중간 규모, 간단한 API, 프로토타입 | 중간 규모 이상, 복잡한 웹 애플리케이션, 대규모 서비스 |
| ML API 개발 | 간단한 API 빠르게 구축 가능 | 더 많은 기능과 구조 제공, DRF 등 활용 시 강력 |
| 유연성 | 매우 높음 | 상대적으로 낮으나, 필요한 대부분 기능 제공 |
- 선택 가이드:
- 빠르게 간단한 예측 API를 만들어야 할 때, 또는 다른 마이크로서비스와 통합할 때: Flask가 좋은 선택일 수 있습니다.
- 모델 API 외에 사용자 인터페이스, 데이터 관리, 인증 등 복합적인 웹 애플리케이션 기능이 함께 필요할 때: Django가 더 적합할 수 있습니다.
- 최근에는 FastAPI와 같은 ASGI(Asynchronous Server Gateway Interface) 기반의 현대적인 프레임워크도 ML API 개발에 많이 사용됩니다 (비동기 처리, 자동 API 문서 생성 등 장점).
추가 학습 자료
- Flask Documentation
- Deploy Machine Learning Model using Flask (DataCamp Tutorial)
- Django Documentation
- Building a Machine Learning API with Django REST framework (Real Python)
다음 학습 내용
- Day 83: ML 모델을 위한 간단한 API 만들기 (Creating a simple API for an ML model) - 오늘 배운 내용을 바탕으로 실제 API 엔드포인트 설계 및 추가 기능 고려.
Day 83: ML 모델을 위한 간단한 API 만들기 (Creating a simple API for an ML model)
학습 목표
- 어제 학습한 Flask 기본 지식을 바탕으로, 실제 머신러닝 모델을 위한 API 엔드포인트를 설계하고 구현하는 과정 심화.
- API 요청(Request) 및 응답(Response) 형식 설계.
- 입력 데이터 유효성 검사(Validation)의 중요성과 간단한 구현 방법 학습.
- 오류 처리(Error Handling) 및 로깅(Logging)의 기초 개념 이해.
- API 문서화의 필요성 인지.
1. API 엔드포인트 설계 복습 및 구체화
- 어제 만든
/predict_iris엔드포인트를 기준으로 좀 더 구체적인 설계를 고려합니다.
가. 요청 (Request) 형식
- HTTP 메소드:
POST(예측을 위해 데이터를 서버로 전송하므로) - Content-Type:
application/json(JSON 형식으로 데이터 전송) - 요청 본문 (Request Body) 예시:
또는 좀 더 명시적으로:{ "features": [5.1, 3.5, 1.4, 0.2] // Iris 데이터의 4개 특성 값 }{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }- 후자의 방식이 각 특성이 무엇인지 명확하게 알 수 있어 더 좋습니다. 여기서는 간단함을 위해 전자의 리스트 형태를 유지하되, 실제로는 명시적인 키-값 쌍을 권장합니다.
나. 응답 (Response) 형식
- Content-Type:
application/json - 성공 시 응답 본문 (HTTP Status Code: 200 OK) 예시:
{ "input_features": [5.1, 3.5, 1.4, 0.2], "predicted_class_id": 0, "predicted_class_name": "setosa", "probabilities": { "setosa": 0.98, "versicolor": 0.02 // "virginica": 0.0 (다중 클래스였다면) }, "model_version": "1.0.0" // (선택) 사용된 모델 버전 정보 } - 오류 시 응답 본문 (HTTP Status Code: 4xx, 5xx) 예시:
- 입력 데이터 오류 (400 Bad Request):
{ "error_type": "InvalidInputError", "message": "입력된 'features'는 4개의 숫자 값으로 이루어진 리스트여야 합니다." } - 서버 내부 오류 (500 Internal Server Error):
{ "error_type": "PredictionError", "message": "모델 예측 중 내부 오류가 발생했습니다." }
- 입력 데이터 오류 (400 Bad Request):
2. 입력 데이터 유효성 검사 (Input Validation)
- API는 다양한 경로로 호출될 수 있으므로, 예상치 못한 입력에 대해 방어적으로 코드를 작성해야 합니다.
- 유효성 검사는 잘못된 입력으로 인한 모델 오류나 서버 다운을 방지하고, 사용자에게 명확한 피드백을 제공합니다.
유효성 검사 항목 예시
- 필수 필드 존재 여부 (예:
features키가 있는지) - 데이터 타입 확인 (예:
features가 리스트인지, 각 요소가 숫자인지) - 데이터 범위 확인 (예: 특성 값이 특정 범위 내에 있는지 - 필요하다면)
- 리스트 길이 확인 (예:
features리스트의 길이가 정확히 4인지)
간단한 유효성 검사 구현 (어제 코드에 추가/수정)
# flask_api_v2.py (어제 코드 기반으로 수정)
from flask import Flask, request, jsonify
import joblib
import numpy as np
import logging # 로깅 추가
app = Flask(__name__)
# 로깅 설정 (간단 설정)
logging.basicConfig(level=logging.INFO, format='%(asctime)s %(levelname)s: %(message)s')
# 모델 로드
try:
model = joblib.load('iris_binary_model.pkl')
app.logger.info("모델 로드 성공: iris_binary_model.pkl")
# scaler = joblib.load('iris_scaler.pkl')
except FileNotFoundError:
model = None
# scaler = None
app.logger.error("저장된 모델 파일을 찾을 수 없습니다. 'train_model.py'를 먼저 실행하세요.")
except Exception as e:
model = None
# scaler = None
app.logger.error(f"모델 로드 중 오류 발생: {e}")
MODEL_VERSION = "1.0.0" # 모델 버전 정보
@app.route('/')
def home():
return f"Iris Binary Classification API (v{MODEL_VERSION})"
@app.route('/health', methods=['GET']) # 헬스 체크 엔드포인트 추가
def health_check():
if model:
return jsonify({'status': 'ok', 'message': 'API is healthy and model is loaded.'}), 200
else:
return jsonify({'status': 'error', 'message': 'API is unhealthy, model not loaded.'}), 500
@app.route('/predict_iris', methods=['POST'])
def predict_iris():
if model is None:
app.logger.error("'/predict_iris' 호출 시 모델이 로드되지 않음.")
return jsonify({'error_type': 'ModelNotLoadedError', 'message': '모델이 로드되지 않았습니다. 서버 로그를 확인하세요.'}), 500
if not request.is_json:
app.logger.warning("'/predict_iris' 호출 시 JSON 형식이 아닌 요청 받음.")
return jsonify({'error_type': 'InvalidContentTypeError', 'message': 'Request Content-Type must be application/json'}), 400
try:
data = request.get_json()
app.logger.info(f"요청 데이터: {data}")
# --- 입력 데이터 유효성 검사 시작 ---
if 'features' not in data:
app.logger.warning("요청 데이터에 'features' 키가 없음.")
return jsonify({'error_type': 'MissingFieldError', 'message': "'features' 필드가 요청에 포함되어야 합니다."}), 400
features = data['features']
if not isinstance(features, list):
app.logger.warning("'features' 필드가 리스트 타입이 아님.")
return jsonify({'error_type': 'InvalidInputTypeError', 'message': "'features' 필드는 리스트여야 합니다."}), 400
if len(features) != 4:
app.logger.warning(f"'features' 리스트 길이가 4가 아님: {len(features)}")
return jsonify({'error_type': 'InvalidInputLengthError', 'message': f"'features' 리스트는 4개의 요소를 가져야 합니다. (현재: {len(features)}개)"}), 400
if not all(isinstance(f, (int, float)) for f in features):
app.logger.warning("'features' 리스트에 숫자가 아닌 값이 포함됨.")
return jsonify({'error_type': 'InvalidFeatureTypeError', 'message': "'features' 리스트의 모든 요소는 숫자여야 합니다."}), 400
# --- 입력 데이터 유효성 검사 끝 ---
input_array = np.array(features).reshape(1, -1)
# if scaler:
# input_array_scaled = scaler.transform(input_array)
# prediction_proba = model.predict_proba(input_array_scaled)[0]
# prediction = model.predict(input_array_scaled)[0]
# else:
prediction_proba = model.predict_proba(input_array)[0]
prediction = model.predict(input_array)[0]
class_names = ['setosa', 'versicolor']
response_data = {
'input_features': features,
'predicted_class_id': int(prediction),
'predicted_class_name': class_names[int(prediction)],
'probabilities': {'setosa': round(float(prediction_proba[0]), 4),
'versicolor': round(float(prediction_proba[1]), 4)},
'model_version': MODEL_VERSION
}
app.logger.info(f"예측 결과: {response_data}")
return jsonify(response_data), 200
except Exception as e:
app.logger.error(f"예측 중 예외 발생: {str(e)}", exc_info=True) # exc_info=True로 스택 트레이스 로깅
return jsonify({'error_type': 'InternalPredictionError', 'message': f'예측 중 내부 오류가 발생했습니다: {str(e)}'}), 500
if __name__ == '__main__':
# 운영 환경에서는 Gunicorn, uWSGI 같은 WSGI 서버 사용 권장
app.run(debug=False, host='0.0.0.0', port=5001) # debug=False로 변경
3. 오류 처리 (Error Handling) 및 로깅 (Logging)
가. 오류 처리
try-except블록을 사용하여 예측 과정에서 발생할 수 있는 예외(Exception)를 처리합니다.- 사용자에게는 일반적인 오류 메시지를 반환하고, 서버 로그에는 자세한 오류 정보를 기록하여 디버깅에 활용합니다.
- HTTP 상태 코드를 적절히 사용하여 클라이언트가 오류 상황을 인지하도록 합니다.
200 OK: 성공400 Bad Request: 클라이언트 요청 오류 (예: 잘못된 입력 형식)401 Unauthorized: 인증 실패403 Forbidden: 권한 없음404 Not Found: 요청한 리소스 없음500 Internal Server Error: 서버 내부 오류503 Service Unavailable: 서비스 일시 사용 불가
나. 로깅
- 애플리케이션의 상태, 요청 정보, 오류 발생 등을 기록하는 것은 매우 중요합니다.
- 로깅을 통해 문제 발생 시 원인을 파악하고, 시스템 사용 현황을 분석할 수 있습니다.
- 파이썬의 내장
logging모듈을 사용하거나, Flask 확장(예:Flask-Logging)을 사용할 수 있습니다. - 로그 레벨(DEBUG, INFO, WARNING, ERROR, CRITICAL)을 적절히 사용하여 필요한 정보만 기록합니다.
- 위
flask_api_v2.py코드에 간단한 로깅(app.logger)이 추가되었습니다.app.logger.info(): 정보성 메시지.app.logger.warning(): 경고 메시지.app.logger.error(): 오류 메시지.
- 실제 운영 환경에서는 로그 파일로 저장하고, 로그 로테이션, 중앙 집중식 로그 관리 시스템(ELK Stack, Splunk 등)을 고려해야 합니다.
4. API 문서화 (API Documentation)
- API를 사용하는 다른 개발자나 시스템이 API를 올바르게 호출하고 응답을 이해할 수 있도록 명확한 문서가 필요합니다.
- 문서화 내용:
- 엔드포인트 URL 및 HTTP 메소드
- 요청 파라미터 설명 (필수 여부, 데이터 타입, 예시)
- 요청 본문 형식 및 예시
- 응답 형식 및 예시 (성공 시, 오류 시)
- 인증 방법 (필요한 경우)
- 사용 예제 코드
- 도구:
- Swagger / OpenAPI Specification: API 설계를 위한 표준 명세. 이를 기반으로 자동 문서 생성, 클라이언트 코드 생성 등이 가능.
- Flask-RESTx, FastAPI: Swagger UI를 자동으로 생성해주는 기능을 가진 Flask 확장 또는 프레임워크.
- Postman: API 테스트 도구지만, API 컬렉션을 문서화하고 공유하는 기능도 제공.
- Markdown 파일: 간단한 API의 경우 직접 Markdown으로 작성할 수도 있습니다.
5. 추가 고려 사항 (간략히)
- 인증 및 권한 부여 (Authentication & Authorization): API 키, OAuth, JWT 등을 사용하여 허가된 사용자/시스템만 API에 접근하도록 제어.
- 요청 속도 제한 (Rate Limiting): 특정 시간 동안 특정 클라이언트가 보낼 수 있는 요청 수를 제한하여 API 남용 방지.
- 비동기 처리: 예측 시간이 오래 걸리는 모델의 경우, 비동기 작업 큐(Celery, RabbitMQ 등)를 사용하여 요청을 즉시 반환하고 백그라운드에서 예측을 처리하는 방식 고려.
- 테스팅: 단위 테스트(Unit Test), 통합 테스트(Integration Test)를 작성하여 API의 안정성 확보.
- 배포 환경: 개발 서버(
app.run())는 운영 환경에 적합하지 않음. Gunicorn, uWSGI와 같은 WSGI(Web Server Gateway Interface) 서버와 Nginx 같은 웹 서버를 함께 사용하여 배포. (다음 주제에서 다룰 Docker도 활용)
실습 아이디어
- 어제 만든
flask_api.py를 기반으로flask_api_v2.py와 같이 유효성 검사, 오류 처리, 로깅 기능을 추가해보세요. - 다양한 잘못된 입력을
curl이나 Postman으로 보내면서 오류 응답과 서버 로그를 확인해보세요. - (선택)
/health엔드포인트를 추가하여 API 서버의 상태를 확인할 수 있도록 해보세요.
다음 학습 내용
- Day 84: ML을 위한 Docker - 기초 (Docker for ML - Basics) - 모델과 API 서버를 컨테이너화하여 배포 환경을 일관되게 만드는 방법.
Day 84: ML을 위한 Docker - 기초 (Docker for ML - Basics)
학습 목표
- 컨테이너화(Containerization)의 개념과 Docker의 역할 이해
- Docker 이미지(Image)와 컨테이너(Container)의 차이점 학습
- Dockerfile을 사용하여 머신러닝 애플리케이션(예: Flask API)을 위한 Docker 이미지를 빌드하는 방법 숙지
- 빌드된 이미지를 사용하여 Docker 컨테이너를 실행하고 API를 테스트하는 방법 학습
- Docker가 ML 모델 배포에 제공하는 이점 이해
1. 컨테이너화 (Containerization)와 Docker
가. 컨테이너화란?
- 애플리케이션과 그 실행에 필요한 모든 종속성(라이브러리, 시스템 도구, 코드, 런타임 등)을 패키지화하여 격리된 환경에서 실행할 수 있도록 하는 기술입니다.
- “내 컴퓨터에서는 잘 되는데, 다른 컴퓨터에서는 안 돼요“와 같은 문제를 해결하는 데 도움을 줍니다.
- 가상 머신(VM)과 유사하지만, 컨테이너는 호스트 운영체제(OS)의 커널을 공유하므로 더 가볍고 빠르며 효율적입니다.
나. Docker란?
- 컨테이너화 기술을 사용하는 대표적인 오픈소스 플랫폼입니다.
- Docker를 사용하면 애플리케이션을 쉽게 개발, 배포, 실행할 수 있습니다.
- 주요 구성 요소:
- Docker Engine: Docker 컨테이너를 만들고 실행하는 핵심 구성 요소 (Docker 데몬, REST API, CLI 클라이언트 포함).
- Docker Image: 애플리케이션과 그 종속성을 포함하는 읽기 전용 템플릿. 컨테이너를 만드는 데 사용됩니다.
- Docker Container: Docker 이미지의 실행 가능한 인스턴스. 격리된 환경에서 애플리케이션을 실행합니다.
- Dockerfile: Docker 이미지를 빌드하기 위한 지침(명령어)을 담고 있는 텍스트 파일.
- Docker Hub / Docker Registry: Docker 이미지를 저장하고 공유하는 레지스트리 서비스 (Docker Hub은 공용 레지스트리).
 (이미지 출처: Docker Documentation)
(이미지 출처: Docker Documentation)
2. Docker 이미지 (Image) vs 컨테이너 (Container)
- 이미지 (Image):
- 애플리케이션을 실행하는 데 필요한 모든 것을 담고 있는 “설계도” 또는 “템플릿”.
- 운영체제, 라이브러리, 애플리케이션 코드 등이 계층(Layer) 구조로 쌓여 있습니다.
- 읽기 전용(Read-only)입니다.
- 예: 특정 버전의 파이썬, 필요한 라이브러리, Flask API 코드가 포함된 이미지.
- 컨테이너 (Container):
- 이미지의 “실행 인스턴스”.
- 이미지를 기반으로 생성되며, 격리된 프로세스로 실행됩니다.
- 컨테이너 내에서 파일을 생성하거나 수정하는 등의 변경 사항은 해당 컨테이너에만 적용됩니다 (이미지 자체는 변경되지 않음).
- 하나의 이미지로 여러 개의 동일한 컨테이너를 생성하여 실행할 수 있습니다.
3. Dockerfile 작성하기 (ML API 예제)
Dockerfile은 Docker 이미지를 어떻게 빌드할지를 정의하는 텍스트 파일입니다.- 어제 만든 Flask API (
flask_api_v2.py)와 학습된 모델(iris_binary_model.pkl)을 Docker 이미지로 만들어 보겠습니다.
프로젝트 구조 예시:
my_ml_api/
├── flask_api_v2.py # Flask 애플리케이션 코드
├── iris_binary_model.pkl # 학습된 모델 파일
├── requirements.txt # 필요한 파이썬 라이브러리 목록
└── Dockerfile # Docker 이미지 빌드 지침
requirements.txt 파일 내용 예시:
Flask==2.0.1 # 실제 사용하는 Flask 버전에 맞게
joblib==1.1.0
numpy==1.21.2
scikit-learn==0.24.2 # 모델 학습 시 사용한 scikit-learn 버전과 일치시키는 것이 좋음
# gunicorn # (선택) 운영 환경용 WSGI 서버
(위 버전은 예시이므로, 실제 환경에 맞게 pip freeze > requirements.txt 명령으로 생성하는 것이 좋습니다.)
Dockerfile 내용 예시:
# 1. 베이스 이미지 선택 (Base Image)
# 파이썬 3.8 버전을 기반으로 하는 공식 이미지 사용
FROM python:3.8-slim
# 2. 작업 디렉토리 설정 (Working Directory)
# 컨테이너 내에서 명령이 실행될 기본 경로 설정
WORKDIR /app
# 3. 필요한 파일 복사 (Copy Files)
# 현재 디렉토리(Dockerfile이 있는 위치)의 모든 파일을 컨테이너의 /app 디렉토리로 복사
COPY . /app
# 또는 특정 파일만 복사:
# COPY requirements.txt .
# COPY flask_api_v2.py .
# COPY iris_binary_model.pkl .
# 4. 종속성 설치 (Install Dependencies)
# requirements.txt 파일에 명시된 라이브러리 설치
RUN pip install --no-cache-dir -r requirements.txt
# 5. 포트 노출 (Expose Port)
# 컨테이너가 외부와 통신할 포트 지정 (Flask 앱이 5001번 포트 사용 가정)
EXPOSE 5001
# 6. 애플리케이션 실행 명령어 (CMD or ENTRYPOINT)
# 컨테이너가 시작될 때 실행될 기본 명령어
# 개발용: python flask_api_v2.py
# 운영용: gunicorn -w 4 -b 0.0.0.0:5001 flask_api_v2:app (Gunicorn 사용 시)
# 여기서는 개발용으로 간단히 실행
CMD ["python", "flask_api_v2.py"]
Dockerfile 명령어 설명:
FROM: 베이스 이미지를 지정합니다. (예: 특정 OS, 특정 프로그래밍 언어 런타임)WORKDIR: 컨테이너 내의 작업 디렉토리를 설정합니다. 이후 명령어들은 이 디렉토리를 기준으로 실행됩니다.COPY <src> <dest>: 호스트 머신의 파일이나 디렉토리를 컨테이너 내부로 복사합니다.RUN <command>: 이미지를 빌드하는 과정에서 컨테이너 내에서 실행할 명령입니다. (예: 패키지 설치)EXPOSE <port>: 컨테이너가 특정 포트를 사용함을 알립니다. 실제 포트 매핑은 컨테이너 실행 시 이루어집니다.CMD ["executable","param1","param2"]또는ENTRYPOINT ["executable","param1","param2"]: 컨테이너가 시작될 때 실행될 기본 명령을 지정합니다.CMD: 컨테이너 실행 시 다른 명령어로 쉽게 덮어쓸 수 있습니다.ENTRYPOINT: 컨테이너를 실행 파일처럼 사용하며, 실행 시 전달되는 인자들은ENTRYPOINT명령어의 파라미터로 추가됩니다.
4. Docker 이미지 빌드 및 컨테이너 실행
가. Docker 이미지 빌드
Dockerfile이 있는 디렉토리에서 다음 명령을 실행합니다.docker build -t <이미지_이름>:<태그> .-t: 이미지에 이름과 태그(버전 등)를 지정합니다. (예:my-iris-api:v1).: 현재 디렉토리의Dockerfile을 사용하라는 의미입니다.
# Dockerfile이 있는 my_ml_api 디렉토리로 이동했다고 가정
cd path/to/my_ml_api
# 이미지 빌드 (예: 이미지 이름 my-iris-api, 태그 v1)
docker build -t my-iris-api:v1 .
- 빌드가 성공하면 로컬 Docker 이미지 목록에서 확인할 수 있습니다:
docker images
나. Docker 컨테이너 실행
- 빌드된 이미지를 사용하여 컨테이너를 실행합니다.
docker run [OPTIONS] IMAGE [COMMAND] [ARG...]-d: 백그라운드에서 컨테이너 실행 (Detached mode).-p <호스트_포트>:<컨테이너_포트>: 호스트 머신의 포트와 컨테이너의 포트를 매핑합니다. (예:-p 5001:5001-> 호스트의 5001번 포트를 컨테이너의 5001번 포트로 연결)--name <컨테이너_이름>: 컨테이너에 이름을 지정합니다.<이미지_이름>:<태그>: 실행할 이미지.
# 컨테이너 실행 (예: my-iris-api:v1 이미지 사용, 컨테이너 이름 my-api-container)
# 호스트의 5001번 포트를 컨테이너의 5001번 포트(Dockerfile에서 EXPOSE한 포트)로 매핑
docker run -d -p 5001:5001 --name my-api-container my-iris-api:v1
- 실행 중인 컨테이너 확인:
docker ps - 컨테이너 로그 확인:
docker logs my-api-container
다. API 테스트 (컨테이너 실행 후)
- 이제 호스트 머신의
localhost:5001(또는 Docker가 실행 중인 머신의 IP:5001)로 API 요청을 보낼 수 있습니다.
# 어제 사용한 curl 명령어로 테스트
curl -X POST \
-H "Content-Type: application/json" \
-d '{"features": [5.1, 3.5, 1.4, 0.2]}' \
http://localhost:5001/predict_iris
- Docker 컨테이너 내에서 Flask API가 정상적으로 응답하는지 확인합니다.
라. 컨테이너 중지 및 삭제
- 컨테이너 중지:
docker stop my-api-container - 컨테이너 삭제:
docker rm my-api-container(중지된 컨테이너만 삭제 가능) - 이미지 삭제:
docker rmi my-iris-api:v1(해당 이미지를 사용하는 컨테이너가 없어야 삭제 가능)
5. Docker가 ML 모델 배포에 제공하는 이점
- 환경 일관성: 개발, 테스트, 운영 환경 간의 환경 차이로 인한 문제를 최소화합니다. 모델과 모든 종속성이 이미지에 포함되므로 “내 컴퓨터에서는 되는데…” 문제가 줄어듭니다.
- 재현성: 동일한 Dockerfile과 코드를 사용하면 언제 어디서든 동일한 환경을 재현할 수 있습니다.
- 이식성: Docker 이미지는 Docker가 설치된 어떤 환경(로컬 머신, 테스트 서버, 클라우드 등)에서도 동일하게 실행될 수 있습니다.
- 격리: 각 컨테이너는 독립된 환경에서 실행되므로, 다른 애플리케이션이나 시스템과의 충돌을 방지합니다.
- 쉬운 배포 및 확장: Docker 이미지를 사용하여 새로운 서버에 애플리케이션을 쉽게 배포할 수 있습니다. Kubernetes와 같은 컨테이너 오케스트레이션 도구와 함께 사용하면 서비스 확장 및 관리가 용이해집니다.
- 빠른 배포 사이클: 이미지 빌드 및 배포 과정을 자동화하여 개발 및 배포 속도를 높일 수 있습니다 (CI/CD 파이프라인).
- 자원 효율성: 가상 머신보다 가볍고 빠르게 시작되며, 호스트 시스템의 자원을 더 효율적으로 사용합니다.
Docker 사용 시 추가 팁
.dockerignore파일 사용: 이미지 빌드 시 불필요한 파일(예:.git,__pycache__, 가상환경 폴더 등)이 이미지에 포함되지 않도록 제외합니다.- 이미지 크기 최적화:
- 가벼운 베이스 이미지 사용 (예:
python:3.8-slim-buster). RUN명령어를 최소화하고, 여러 명령어를&&로 연결하여 레이어 수 줄이기.- 불필요한 파일이나 빌드 중간 산출물 삭제.
- 멀티 스테이지 빌드(Multi-stage builds) 사용.
- 가벼운 베이스 이미지 사용 (예:
- 보안: 베이스 이미지의 취약점 점검, 최소 권한 원칙 적용 등.
추가 학습 자료
- Docker 공식 문서 - Get Started
- Docker Tutorial for Beginners (YouTube - Programming with Mosh)
- A Docker Tutorial for Data Scientists (Towards Data Science)
- Dockerizing a Python Flask Application (Real Python)
다음 학습 내용
- Day 85: Docker를 사용한 간단한 ML 모델 배포 (Deploying a simple ML model using Docker) - 오늘 배운 내용을 바탕으로 실제 배포 시나리오 및 클라우드 연동 가능성 탐색.
Day 85: Docker를 사용한 간단한 ML 모델 배포 (Deploying a simple ML model using Docker)
학습 목표
- 어제 학습한 Docker 기본 지식을 바탕으로, 실제 머신러닝 모델 API를 Docker 컨테이너로 실행하고 외부에서 접근하는 전체 과정 복습 및 심화.
- Docker 이미지 레지스트리(예: Docker Hub)에 이미지를 푸시(Push)하고 풀(Pull)하는 방법 이해.
- 간단한 클라우드 환경(예: 가상 머신)에 Docker 컨테이너를 배포하는 개념 학습.
- Docker Compose를 사용한 다중 컨테이너 애플리케이션 관리의 기초 소개 (선택 사항).
1. 전체 배포 시나리오 복습
어제까지의 과정을 통해 다음을 수행했습니다:
- 머신러닝 모델 학습 및 저장:
iris_binary_model.pkl(및 필요시iris_scaler.pkl) - Flask API 서버 작성:
flask_api_v2.py(모델 로드, 예측 엔드포인트/predict_iris구현) - 필요 라이브러리 목록 작성:
requirements.txt - Dockerfile 작성: Flask API 서버를 실행하는 Docker 이미지 빌드 지침 정의
- Docker 이미지 빌드:
docker build -t my-iris-api:v1 . - Docker 컨테이너 로컬 실행:
docker run -d -p 5001:5001 --name my-api-container my-iris-api:v1 - 로컬에서 API 테스트:
curl또는 Postman 사용
오늘은 이 로컬에서 실행한 Docker 컨테이너를 다른 환경에서도 사용할 수 있도록 하는 단계를 추가적으로 고려합니다.
2. Docker 이미지 레지스트리 (Docker Image Registry)
- 정의: Docker 이미지를 저장하고 관리하며 공유하는 중앙 저장소입니다.
- 종류:
- Docker Hub: Docker에서 제공하는 공식 공용 레지스트리. 무료로 공개 이미지를 저장하거나, 유료로 비공개 이미지를 저장할 수 있습니다.
- 프라이빗 레지스트리 (Private Registry): 기업이나 조직 내부에 자체적으로 구축하거나, 클라우드 서비스 제공업체(AWS ECR, GCP Container Registry/Artifact Registry, Azure ACR 등)가 제공하는 비공개 레지스트리를 사용할 수 있습니다.
가. Docker Hub에 이미지 푸시 (Push)
- Docker Hub 계정 생성: Docker Hub 웹사이트에서 계정을 만듭니다.
- 로컬 Docker에 로그인: 터미널에서
docker login명령을 실행하고 Docker Hub 사용자 이름과 비밀번호를 입력합니다.docker login # Username: <your_dockerhub_username> # Password: <your_dockerhub_password> - 이미지 태그 변경 (선택 사항, 권장): Docker Hub에 푸시하려면 이미지 이름을
<DockerHub_사용자이름>/<이미지_이름>:<태그>형식으로 지정해야 합니다. 기존 이미지에 새 태그를 추가하거나, 빌드 시 이 형식으로 이름을 지정합니다.# 기존 이미지에 새 태그 추가 docker tag my-iris-api:v1 <your_dockerhub_username>/my-iris-api:v1 # 또는 빌드 시 바로 지정 # docker build -t <your_dockerhub_username>/my-iris-api:v1 . - 이미지 푸시:
docker push <DockerHub_사용자이름>/<이미지_이름>:<태그>docker push <your_dockerhub_username>/my-iris-api:v1- 푸시가 완료되면 Docker Hub 웹사이트의 내 레포지토리에서 이미지를 확인할 수 있습니다. (기본적으로 공개 이미지로 생성됨)
나. 다른 환경에서 이미지 풀 (Pull) 및 실행
- Docker가 설치된 다른 서버나 컴퓨터에서 Docker Hub (또는 다른 레지스트리)에 있는 이미지를 가져와 실행할 수 있습니다.
- (선택) 해당 환경에서 Docker 로그인: 비공개 이미지의 경우 필요. 공개 이미지는 로그인 없이 풀 가능.
- 이미지 풀:
docker pull <DockerHub_사용자이름>/<이미지_이름>:<태그>docker pull <your_dockerhub_username>/my-iris-api:v1 - 컨테이너 실행: 로컬에서 실행했던 것과 동일한
docker run명령 사용.docker run -d -p 5001:5001 --name my-remote-api-container <your_dockerhub_username>/my-iris-api:v1- 이제 해당 서버의 IP 주소와 5001번 포트를 통해 API에 접근할 수 있습니다. (방화벽 설정 등 필요할 수 있음)
3. 간단한 클라우드 환경에 Docker 컨테이너 배포 (개념)
- 클라우드 서비스 제공업체(AWS, GCP, Azure 등)의 가상 머신(VM) 인스턴스를 사용하여 Docker 컨테이너를 배포할 수 있습니다.
일반적인 단계 (예: AWS EC2, GCP Compute Engine)
- 클라우드 플랫폼에서 VM 인스턴스 생성:
- 운영체제 선택 (예: Ubuntu, Amazon Linux 등 Docker 지원 OS).
- 인스턴스 크기(CPU, 메모리) 선택.
- 네트워크 설정 (보안 그룹/방화벽 규칙에서 API 포트 - 예: 5001 - 허용).
- VM 인스턴스에 접속 (SSH).
- Docker 설치: VM 인스턴스에 Docker Engine을 설치합니다. (각 클라우드 플랫폼 및 OS별 설치 가이드 참조)
# 예시: Ubuntu에 Docker 설치 # sudo apt update # sudo apt install -y docker.io # sudo systemctl start docker # sudo systemctl enable docker # sudo usermod -aG docker $USER # 현재 사용자를 docker 그룹에 추가 (재로그인 필요) - Docker 이미지 풀: Docker Hub 또는 프라이빗 레지스트리에서 배포할 이미지를 풀합니다.
docker pull <your_dockerhub_username>/my-iris-api:v1 - Docker 컨테이너 실행:
docker run명령으로 컨테이너를 실행합니다.docker run -d -p 5001:5001 --name my-cloud-api-container <your_dockerhub_username>/my-iris-api:v1 # --restart always 옵션을 추가하면 VM 재부팅 시 컨테이너 자동 시작 # docker run -d -p 5001:5001 --name my-cloud-api-container --restart always <your_dockerhub_username>/my-iris-api:v1 - API 테스트: VM 인스턴스의 공인 IP 주소와 매핑된 포트(예:
http://<VM_Public_IP>:5001/predict_iris)로 API를 테스트합니다.
클라우드 관리형 컨테이너 서비스
- 위 방법은 VM에 직접 Docker를 설치하고 관리하는 방식입니다.
- 클라우드 제공업체들은 컨테이너 배포 및 관리를 더 쉽게 해주는 관리형 서비스도 제공합니다:
- AWS: ECS (Elastic Container Service), EKS (Elastic Kubernetes Service), Fargate, App Runner
- GCP: Cloud Run, GKE (Google Kubernetes Engine), App Engine
- Azure: ACI (Azure Container Instances), AKS (Azure Kubernetes Service), App Service
- 이러한 서비스들은 컨테이너 오케스트레이션, 자동 확장, 로드 밸런싱, 모니터링 등을 더 쉽게 설정하고 관리할 수 있도록 도와줍니다. (더 고급 주제)
4. Docker Compose 사용 기초 (선택 사항)
- 정의: 여러 개의 Docker 컨테이너로 구성된 애플리케이션을 정의하고 실행하기 위한 도구입니다.
docker-compose.yml이라는 YAML 파일을 사용하여 애플리케이션의 서비스, 네트워크, 볼륨 등을 설정합니다.- ML 배포에서의 활용 예시:
- Flask/Django API 서버 컨테이너.
- 데이터베이스 컨테이너 (예: PostgreSQL, MySQL).
- 메시지 큐 컨테이너 (예: RabbitMQ, Redis - 비동기 작업용).
- 모니터링 도구 컨테이너 (예: Prometheus, Grafana).
- 여러 컨테이너를 한 번의 명령(
docker-compose up,docker-compose down)으로 쉽게 관리할 수 있습니다.
간단한 docker-compose.yml 예시 (Flask API만 있는 경우)
# docker-compose.yml
version: '3.8' # Docker Compose 파일 형식 버전
services:
my-api-service: # 서비스 이름 (임의 지정)
image: <your_dockerhub_username>/my-iris-api:v1 # 사용할 Docker 이미지
# build: . # Dockerfile이 있는 현재 디렉토리에서 이미지를 빌드할 수도 있음
container_name: my-compose-api-container # 실행될 컨테이너 이름
ports:
- "5001:5001" # 호스트 포트:컨테이너 포트
restart: always # 컨테이너 비정상 종료 시 자동 재시작
# environment: # 환경 변수 설정 (필요시)
# - FLASK_ENV=production
- 위 파일을
docker-compose.yml로 저장하고, 해당 디렉토리에서 다음 명령 실행:docker-compose up -d: 백그라운드에서 서비스 시작 (이미지가 없으면 풀 또는 빌드)docker-compose down: 서비스 중지 및 컨테이너, 네트워크 등 제거docker-compose logs my-api-service: 해당 서비스 로그 확인
5. 운영 환경에서의 추가 고려 사항
- WSGI 서버 사용: Flask/Django의 내장 개발 서버는 운영 환경에 적합하지 않습니다. Gunicorn, uWSGI와 같은 WSGI 서버를 Dockerfile의
CMD또는ENTRYPOINT에서 사용하여 애플리케이션을 실행해야 합니다.- 예:
CMD ["gunicorn", "-w", "4", "-b", "0.0.0.0:5001", "flask_api_v2:app"]-w 4: 워커 프로세스 4개 사용-b 0.0.0.0:5001: 모든 인터페이스의 5001번 포트에서 바인딩flask_api_v2:app:flask_api_v2.py파일의appFlask 객체를 의미
- 예:
- HTTPS 설정: 실제 서비스에서는 보안을 위해 HTTPS를 사용해야 합니다. 이는 보통 로드 밸런서나 리버스 프록시(Nginx 등) 수준에서 처리합니다.
- 환경 변수 관리: API 키, 데이터베이스 접속 정보 등 민감한 정보는 Docker 이미지에 직접 하드코딩하지 않고, 컨테이너 실행 시 환경 변수로 주입하거나 Docker Secrets, Vault 등을 사용합니다.
- 로깅 및 모니터링: 컨테이너 로그를 수집하고 분석할 수 있는 시스템(ELK Stack, CloudWatch Logs 등)과 애플리케이션 및 인프라 모니터링 도구(Prometheus, Grafana, Datadog 등)를 설정합니다.
- CI/CD (Continuous Integration / Continuous Deployment): 코드 변경 시 자동으로 이미지를 빌드, 테스트하고 레지스트리에 푸시하며, 배포까지 자동화하는 파이프라인을 구축합니다. (Jenkins, GitLab CI, GitHub Actions 등)
실습 아이디어
- 어제 만든
my-iris-api:v1이미지를 Docker Hub의 본인 계정에 푸시해보세요. - (가능하다면) 다른 컴퓨터나 클라우드 VM에 Docker를 설치하고, 푸시한 이미지를 풀하여 컨테이너를 실행하고 API를 테스트해보세요.
- (선택) 간단한
docker-compose.yml파일을 작성하여 어제 만든 API 컨테이너를 실행해보세요. - (선택) Dockerfile의
CMD를 Gunicorn을 사용하도록 변경하고 이미지를 다시 빌드하여 실행해보세요. (Gunicorn 설치 필요:requirements.txt에 추가)
추가 학습 자료
- Docker Hub Quickstart
- Deploying Docker containers on AWS (AWS Documentation)
- Docker Compose Overview
- Best practices for writing Dockerfiles
다음 학습 내용
- Day 86: 캡스톤 프로젝트 아이디어 브레인스토밍 (Brainstorming Capstone Project ideas) - 지금까지 배운 내용을 종합적으로 활용할 수 있는 프로젝트 아이디어 구상.
Day 86: 캡스톤 프로젝트 아이디어 브레인스토밍 (Brainstorming Capstone Project ideas)
학습 목표
- 지난 85일간 학습한 머신러닝, 딥러닝, 자연어 처리, 시계열 분석, 모델 배포 등의 지식을 종합적으로 활용할 수 있는 캡스톤 프로젝트 아이디어 구상.
- 개인의 관심사, 사용 가능한 데이터, 현실적인 구현 가능성을 고려하여 아이디어 발상.
- 다양한 분야의 문제 해결에 머신러닝을 어떻게 적용할 수 있을지 탐색.
1. 캡스톤 프로젝트의 중요성
- 지식 통합 및 심화: 개별적으로 학습한 개념들을 실제 문제 해결 과정에 적용해보면서 지식을 통합하고 깊이 이해할 수 있습니다.
- 실전 경험: 데이터 수집부터 모델 배포까지 머신러닝 프로젝트의 전체 생명주기를 경험해볼 수 있습니다.
- 문제 해결 능력 향상: 정의되지 않은 문제에 대해 스스로 해결책을 찾아나가는 과정을 통해 실질적인 문제 해결 능력을 기릅니다.
- 포트폴리오 구축: 성공적인 캡스톤 프로젝트는 개인의 역량을 보여주는 훌륭한 포트폴리오가 될 수 있습니다.
- 자신감 향상: 스스로 프로젝트를 완성해나가는 과정에서 성취감과 자신감을 얻을 수 있습니다.
2. 아이디어 발상 시 고려사항
- 개인의 관심사: 자신이 흥미를 느끼는 분야나 주제를 선택해야 프로젝트를 진행하는 동안 동기 부여가 되고 즐겁게 참여할 수 있습니다.
- 데이터 확보 가능성:
- 공개 데이터셋 (Kaggle, UCI Machine Learning Repository, 공공데이터포털 등) 활용 가능 여부.
- 웹 크롤링을 통해 직접 데이터 수집 가능성.
- API를 통해 데이터 수집 가능성.
- 데이터의 양과 질이 프로젝트 수행에 적합한지.
- 기술적 실현 가능성: 현재까지 학습한 내용과 앞으로 학습할 내용을 바탕으로 현실적으로 구현 가능한 범위 내에서 아이디어를 선택합니다. 너무 거창하거나 복잡한 아이디어는 중간에 포기할 수 있습니다.
- 프로젝트 목표의 명확성: 무엇을 만들고 싶은지, 어떤 문제를 해결하고 싶은지, 어떤 결과를 기대하는지 명확하게 정의해야 합니다.
- 예상 소요 시간 및 노력: 남은 100일 챌린지 기간(약 10~14일) 내에 어느 정도 완성도를 갖출 수 있을지 고려합니다.
- 차별성 및 독창성 (선택 사항): 기존에 많이 다뤄진 주제라도 자신만의 새로운 접근 방식이나 아이디어를 추가하면 좋습니다.
3. 다양한 분야별 프로젝트 아이디어 예시
가. 자연어 처리 (NLP)
- 감성 분석기 심화:
- 특정 도메인(영화 리뷰, 제품 리뷰, 뉴스 댓글 등)의 텍스트에 대한 감성 분석.
- 단순 긍/부정을 넘어 다중 감정(기쁨, 슬픔, 분노 등) 분류.
- 속성 기반 감성 분석 (Aspect-based Sentiment Analysis).
- 한국어 데이터 사용 시 KoNLPy 및 한국어 특화 모델 활용.
- 텍스트 분류기:
- 뉴스 기사 카테고리 자동 분류 (스포츠, 정치, 경제, 사회 등).
- 스팸 메일 필터링.
- 기술 문서나 논문 주제 분류.
- 챗봇 (간단한 형태):
- 특정 주제에 대한 질의응답 봇 (FAQ 봇).
- 간단한 규칙 기반 또는 검색 기반 챗봇.
- (고급) Seq2Seq 모델을 사용한 생성 기반 챗봇 기초.
- 텍스트 요약기:
- 긴 뉴스 기사나 문서를 몇 문장으로 요약.
- 추출적 요약(Extractive Summarization) 또는 (고급) 생성적 요약(Abstractive Summarization) 시도.
- 유사 문서 검색 시스템:
- 특정 문서와 내용이 유사한 다른 문서들을 찾아주는 시스템.
- TF-IDF, Word Embeddings, Doc2Vec 등 활용.
- 개체명 인식 (NER):
- 텍스트에서 인명, 지명, 기관명 등 특정 유형의 개체를 인식하고 태깅.
나. 컴퓨터 비전 (Computer Vision) - (학습 범위 외지만, 관심 있다면 도전 가능)
- 이미지 분류:
- 특정 종류의 객체(고양이/개, 자동차 종류 등) 이미지 분류.
- 손글씨 숫자 또는 문자 인식 (MNIST, EMNIST 데이터셋).
- 객체 탐지 (Object Detection) 기초:
- 이미지 내 특정 객체의 위치를 바운딩 박스로 표시. (YOLO, SSD 등 모델 사용은 고급)
- 간단한 객체(예: 얼굴)를 찾는 수준.
다. 시계열 분석 (Time Series Analysis)
- 주가 예측 (간단한 모델):
- 특정 주식의 과거 데이터를 사용하여 미래 주가 등락 예측 (ARIMA, LSTM 등 사용).
- (주의) 실제 투자 목적으로는 매우 신중해야 하며, 많은 변수를 고려해야 함.
- 날씨 예측:
- 과거 기온, 습도 등의 데이터를 사용하여 미래 날씨 예측.
- 수요 예측:
- 특정 상품의 과거 판매 데이터를 기반으로 미래 수요량 예측.
- 이상 탐지:
- 센서 데이터나 시스템 로그에서 비정상적인 패턴 탐지.
라. 추천 시스템 (Recommender Systems)
- 콘텐츠 기반 필터링 (Content-based Filtering):
- 사용자가 과거에 좋아했던 아이템과 유사한 아이템을 추천. (아이템의 특징 정보 활용)
- 협업 필터링 (Collaborative Filtering):
- 사용자와 아이템 간의 상호작용 패턴(평점, 구매 이력 등)을 기반으로 추천.
- 사용자 기반 또는 아이템 기반.
- (고급) 행렬 분해 (Matrix Factorization) 기법.
- 간단한 영화/음악/상품 추천 시스템 구축.
마. 데이터 분석 및 시각화 기반 예측/분류
- 고객 이탈 예측 (Customer Churn Prediction):
- 통신사, 금융기관 등의 고객 데이터를 분석하여 이탈 가능성이 높은 고객 예측.
- 신용카드 사기 탐지 (Credit Card Fraud Detection):
- 거래 내역 데이터를 분석하여 사기 거래 탐지 (불균형 데이터 처리 중요).
- 질병 예측:
- 환자 데이터를 기반으로 특정 질병 발병 가능성 예측.
- 부동산 가격 예측:
- 지역, 크기, 편의시설 등 다양한 요소를 고려하여 부동산 가격 예측.
바. 강화 학습 (Reinforcement Learning) - (고급 주제, 간단한 환경에서 시도)
- 간단한 게임 AI:
- 그리드 월드, 카트폴(CartPole) 등 OpenAI Gym의 간단한 환경에서 Q-러닝, DQN 등 적용.
- 미로 찾기 에이전트.
사. 모델 배포 및 MLOps 관련
- ML 모델 서빙 API 심화:
- 이전에 만든 Flask/Django API를 확장하여 더 많은 기능 추가 (인증, 로깅, 모니터링, 비동기 처리 등).
- FastAPI와 같은 다른 프레임워크 사용 시도.
- Docker를 이용한 모델 배포 파이프라인 구축:
- 모델 학습, API 서버 패키징, Docker 이미지 빌드, 레지스트리 푸시까지의 과정을 스크립트로 자동화.
- 간단한 웹 UI와 ML 모델 연동:
- 사용자가 웹 인터페이스를 통해 데이터를 입력하고 예측 결과를 확인할 수 있는 간단한 웹 애플리케이션 제작. (HTML, CSS, JavaScript 기초 필요)
4. 아이디어 구체화 질문
- 어떤 문제를 해결하고 싶은가? (Problem Statement)
- 이 문제를 해결했을 때 어떤 가치가 있는가? (Value Proposition)
- 어떤 데이터를 사용할 것인가? 어떻게 확보할 것인가? (Data Source)
- 어떤 머신러닝/딥러닝 모델 또는 기법을 적용해볼 수 있을까? (Methodology)
- 프로젝트의 최종 결과물은 어떤 형태일까? (Deliverables: 코드, 보고서, 데모, API, 웹앱 등)
- 성공/실패를 판단할 수 있는 기준은 무엇인가? (Evaluation Metrics)
- 가장 어려운 부분은 무엇일까? 어떻게 해결할 수 있을까? (Challenges & Solutions)
- 프로젝트를 통해 무엇을 배우고 싶은가? (Learning Objectives)
5. 다음 단계: 아이디어 선정 및 계획 수립
- 오늘 브레인스토밍한 아이디어들 중에서 가장 관심 있고 실현 가능성이 높은 아이디어를 1~2개 정도로 추립니다.
- 각 아이디어에 대해 위 “아이디어 구체화 질문“에 답해보면서 더 깊이 고민합니다.
- 내일은 이 중 최종 프로젝트 주제를 선정하고, 구체적인 수행 계획을 세울 예정입니다.
팁: Kaggle 경진대회(과거 포함), GitHub의 머신러닝 프로젝트, 관련 블로그나 논문 등을 참고하여 아이디어를 얻거나 구체화하는 데 도움을 받을 수 있습니다.
다음 학습 내용
- Day 87: 캡스톤 프로젝트 선정 및 범위 정의 (Selecting a Capstone Project and defining scope) - 브레인스토밍한 아이디어 중 하나를 선택하고 프로젝트의 목표와 범위를 명확히 설정.
Day 87: 캡스톤 프로젝트 선정 및 범위 정의 (Selecting a Capstone Project and defining scope)
학습 목표
- 어제 브레인스토밍한 아이디어들을 바탕으로 최종 캡스톤 프로젝트 주제 선정.
- 선택한 프로젝트의 목표(Goals)와 기대 결과물(Deliverables)을 명확히 정의.
- 프로젝트의 범위(Scope)를 현실적으로 설정하여 제한된 시간 내에 달성 가능하도록 계획.
- 프로젝트 성공을 위한 주요 평가 지표(Evaluation Metrics) 설정.
1. 캡스톤 프로젝트 주제 선정 과정
가. 아이디어 검토 및 우선순위화
- 어제 브레인스토밍한 아이디어 리스트를 다시 한번 살펴봅니다.
- 각 아이디어에 대해 다음 기준을 적용하여 평가하고 우선순위를 매깁니다:
- 개인적인 흥미도 및 동기 부여: 얼마나 이 주제에 대해 열정을 가지고 임할 수 있는가?
- 기술적 실현 가능성: 현재 보유한 지식과 남은 기간 동안 학습할 내용을 고려했을 때, 현실적으로 구현 가능한가? 너무 어렵거나 너무 쉽지는 않은가?
- 데이터 확보의 용이성 및 적절성: 프로젝트 수행에 필요한 데이터를 쉽게 구할 수 있는가? 데이터의 양과 질은 충분한가?
- 학습 목표 달성 기여도: 이 프로젝트를 통해 무엇을 배우고 성장할 수 있는가? 지금까지 배운 내용을 잘 활용할 수 있는가?
- 예상 소요 시간 및 노력: 남은 챌린지 기간(약 2주) 내에 의미 있는 결과물을 만들 수 있는가?
- (선택) 독창성 및 차별성: 기존에 많이 다뤄지지 않았거나, 자신만의 새로운 시각을 더할 수 있는가?
나. 최종 주제 선정
- 위 평가 기준을 바탕으로 가장 적합하다고 판단되는 프로젝트 주제를 1개 최종 선택합니다.
- 선택 과정에서 어려움이 있다면, 2~3개의 후보를 두고 각 후보에 대해 아래 “프로젝트 목표 및 범위 정의” 과정을 미리 간략하게 진행해보면서 비교하는 것도 좋은 방법입니다.
예시 프로젝트 주제 선정 (가상 시나리오):
여러 아이디어를 검토한 결과, “영화 리뷰 감성 분석 모델 개선 및 API 배포” 프로젝트를 진행하기로 결정.
- 흥미도: NLP와 모델 배포에 관심이 많음.
- 실현 가능성: 기본적인 감성 분석 모델 구축 경험이 있고, API 배포도 최근 학습함. 심화된 모델이나 새로운 데이터셋 적용은 도전적이지만 가능할 것으로 판단.
- 데이터 확보: 기존 IMDB 데이터셋 외에, 추가적으로 네이버 영화 리뷰 데이터를 수집하여 한국어 처리 능력도 향상시키고 싶음. (웹 크롤링 또는 공개 API 활용)
- 학습 목표: 다양한 감성 분석 기법 비교, 한국어 NLP 처리, 모델 서빙 API의 완성도 향상, Docker를 이용한 배포 경험.
2. 프로젝트 목표 (Goals) 및 기대 결과물 (Deliverables) 정의
가. 프로젝트 목표 설정
- 프로젝트를 통해 궁극적으로 달성하고자 하는 바를 명확하고 구체적으로 기술합니다.
- SMART 원칙(Specific, Measurable, Achievable, Relevant, Time-bound)을 참고하여 목표를 설정하면 좋습니다.
- 예시 (위 가상 시나리오 기반):
- 주 목표: 다양한 머신러닝/딥러닝 모델(예: Logistic Regression, LSTM, BERT 기반 모델)을 사용하여 영화 리뷰 감성 분류 정확도를 85% 이상 달성하고, 최적 모델을 Docker 컨테이너 기반의 REST API로 배포한다.
- 부 목표:
- 영어(IMDB) 및 한국어(네이버 영화 리뷰) 데이터셋 모두에 적용 가능한 감성 분석 파이프라인 구축.
- 한국어 전처리(형태소 분석, 토큰화) 기법 적용 및 효과 분석.
- API에 기본적인 입력 유효성 검사 및 로깅 기능 구현.
- 프로젝트 과정 및 결과를 GitHub 저장소에 문서화.
나. 기대 결과물 정의
- 프로젝트 완료 시 만들어낼 구체적인 산출물을 나열합니다.
- 예시:
- 소스 코드:
- 데이터 수집 및 전처리 스크립트 (Python).
- 모델 학습 및 평가 스크립트 (Python, Jupyter Notebook).
- Flask/FastAPI 기반 예측 API 서버 코드 (Python).
- Dockerfile 및 (선택) docker-compose.yml 파일.
- 학습된 모델 파일: 직렬화된 최종 모델 파일 (예:
.pkl,.h5,pytorch_model.bin). - API 문서: (선택) Swagger/OpenAPI 명세 또는 간단한 Markdown 형식의 API 사용법.
- 프로젝트 보고서/문서:
- 프로젝트 개요, 목표, 사용 데이터, 적용 방법론.
- 실험 과정 및 결과 (모델 성능 비교, 분석 등).
- API 배포 과정 및 테스트 결과.
- 결론 및 향후 개선 방향.
- (형식은 자유롭게: README.md 상세 작성, 별도 문서 등)
- GitHub 저장소: 위 모든 결과물을 포함하는 공개 GitHub 저장소.
- (선택) 데모: 간단한 웹 UI 또는 API 호출 시연 영상/스크린샷.
- 소스 코드:
3. 프로젝트 범위 (Scope) 정의
- 프로젝트의 경계를 명확히 하여 무엇을 하고 무엇을 하지 않을지를 결정합니다.
- 제한된 시간과 자원 내에서 현실적으로 달성 가능한 범위를 설정하는 것이 매우 중요합니다. “범위蔓延(Scope Creep)“을 방지해야 합니다.
가. 포함할 내용 (In-Scope)
- 프로젝트 목표 달성을 위해 반드시 수행해야 할 핵심 작업들을 구체적으로 나열합니다.
- 예시:
- 영어(IMDB) 리뷰 데이터 전처리 및 TF-IDF, Word2Vec 임베딩 생성.
- 한국어(네이버 영화) 리뷰 데이터 수집(크롤링 범위 제한), KoNLPy를 이용한 형태소 분석 및 토큰화.
- 최소 2개 이상의 분류 모델(예: Logistic Regression, LSTM) 학습 및 비교 평가.
- 선택된 최적 모델을 Flask API로 구현 (예측 엔드포인트 1개).
- Dockerfile 작성 및 로컬 환경에서 Docker 컨테이너 실행 및 테스트.
- GitHub 저장소에 코드 및 간략한 README 문서 작성.
나. 제외할 내용 (Out-of-Scope)
- 시간 제약이나 기술적 어려움 등으로 인해 이번 프로젝트에서는 다루지 않을 내용을 명시합니다.
- 이를 통해 프로젝트의 초점을 명확히 하고, 불필요한 작업에 시간을 낭비하는 것을 막습니다.
- 예시:
- 실시간 스트리밍 데이터 처리.
- 복잡한 사용자 인터페이스(UI) 개발 (간단한 테스트용 UI는 가능).
- 클라우드 플랫폼(AWS, GCP 등)으로의 완전 자동화된 배포 파이프라인 구축 (로컬 Docker 배포까지만).
- A/B 테스팅 및 고급 모니터링 시스템 구축.
- 매우 큰 규모의 데이터셋 처리 (개인 PC 환경 고려).
- 모든 가능한 하이퍼파라미터 조합에 대한 완전 탐색 (시간 제약).
다. 최소 기능 제품 (MVP, Minimum Viable Product) 정의 (선택 사항)
- 프로젝트의 가장 핵심적인 기능을 구현한 최소한의 결과물을 정의합니다.
- 만약 시간이 부족할 경우, 최소한 MVP는 달성하는 것을 목표로 할 수 있습니다.
- 예시 MVP: IMDB 데이터셋에 대한 LSTM 기반 감성 분석 모델 학습 및 Flask API (로컬 실행) 구현.
4. 주요 평가 지표 (Evaluation Metrics) 설정
- 프로젝트의 성공 여부를 판단하거나, 모델의 성능을 객관적으로 측정하기 위한 지표를 설정합니다.
- 문제 유형(분류, 회귀, NLP 등)에 맞는 적절한 평가지표를 선택합니다.
- 예시 (감성 분석 분류 문제):
- 정확도 (Accuracy): 전체 예측 중 올바르게 예측한 비율.
- 정밀도 (Precision), 재현율 (Recall), F1 점수 (F1-Score): 특히 클래스 불균형이 있을 경우 중요. 긍정/부정 클래스 각각에 대해 계산하거나 평균(macro/micro) 사용.
- ROC AUC: 모델의 전반적인 분류 성능.
- (API 배포 관련) 응답 시간 (Latency), 처리량 (Throughput) - 간단한 테스트로 측정.
5. 다음 단계: 세부 계획 수립
- 오늘 정의한 프로젝트 목표, 범위, 결과물, 평가지표를 바탕으로, 남은 기간 동안 각 작업을 어떻게 수행할지 세부적인 일정을 계획합니다.
- 각 작업 단계별로 필요한 시간, 자원, 예상되는 어려움 등을 고려합니다.
- 예:
- 1일차: 데이터 수집 및 EDA
- 2-3일차: 데이터 전처리 및 특징 공학
- 4-6일차: 모델 학습 및 평가 (여러 모델 시도)
- 7-8일차: API 개발
- 9-10일차: Docker 패키징 및 테스트
- 11-12일차: 문서화 및 최종 정리
팁: 프로젝트를 진행하면서 계획은 변경될 수 있습니다. 중요한 것은 주기적으로 진행 상황을 점검하고, 필요에 따라 계획을 유연하게 수정하는 것입니다. 혼자 진행하는 프로젝트이므로, 스스로에게 현실적인 기대치를 설정하고 과정을 즐기는 것이 중요합니다.
다음 학습 내용
- Day 88: 프로젝트를 위한 데이터 수집 및 전처리 (Data Collection and Preprocessing for the project) - 선택한 프로젝트에 필요한 데이터를 실제로 수집하고, 모델 학습에 적합한 형태로 가공하는 작업 시작.
Day 88: 프로젝트를 위한 데이터 수집 및 전처리 (Data Collection and Preprocessing for the project)
학습 목표
- 선정된 캡스톤 프로젝트에 필요한 실제 데이터를 수집하는 방법 실행.
- 수집된 데이터의 초기 탐색(EDA 기초)을 통해 데이터의 특성 파악.
- 프로젝트 목표에 맞게 데이터를 정제하고, 결측치 및 이상치를 처리하며, 필요한 경우 특징 스케일링 등의 전처리 작업 수행.
- 머신러닝 모델 학습에 적합한 형태로 데이터를 가공.
1. 데이터 수집 (Data Collection)
- 프로젝트 주제와 범위에 따라 데이터 수집 방법이 달라집니다.
가. 공개 데이터셋 활용
- Kaggle Datasets: 다양한 주제의 방대한 데이터셋 제공. (예: 영화 리뷰, 고객 이탈, 주가 등)
- 예시: IMDB Movie Reviews, Amazon Product Reviews, Twitter US Airline Sentiment.
- UCI Machine Learning Repository: 고전적이고 잘 알려진 머신러닝 데이터셋 다수 보유.
- 공공데이터포털 (data.go.kr): 국내 공공기관에서 제공하는 다양한 분야의 데이터.
- 기타 연구기관 또는 기업에서 공개하는 데이터셋: (예: AI Hub, Dacon 등)
- 데이터셋 선택 시 고려사항:
- 프로젝트 주제와의 관련성.
- 데이터의 크기 (너무 작거나 너무 크지 않은 적절한 규모).
- 데이터의 품질 (결측치, 오류 등).
- 데이터 사용 라이선스 확인.
나. 웹 크롤링 (Web Crawling/Scraping)
- 웹사이트에서 직접 필요한 정보를 수집하는 방법.
- 파이썬 라이브러리:
Requests(HTTP 요청),Beautiful Soup(HTML 파싱),Selenium(동적 웹사이트 크롤링). - 주의사항:
- 웹사이트의
robots.txt파일을 확인하여 크롤링 허용 여부 및 규칙 준수. - 과도한 요청으로 서버에 부담을 주지 않도록 주의 (시간 간격 설정).
- 수집한 데이터의 저작권 및 개인정보보호 관련 법규 확인.
- 웹사이트의
- 예시 (영화 리뷰 감성 분석 프로젝트): 네이버 영화, 다음 영화 등에서 리뷰 데이터 수집.
다. API 활용
- 많은 서비스(트위터, 유튜브, 공공 API 등)에서 데이터를 제공하는 API를 운영.
- API 문서를 참고하여 요청 방식, 인증 방법 등을 숙지하고 데이터 수집.
- 파이썬 라이브러리:
Requests, 각 서비스별 API 클라이언트 라이브러리.
데이터 수집 후 초기 작업
- 수집된 데이터는 보통 CSV, JSON, TXT, 데이터베이스 등의 형태로 저장합니다.
- 데이터 로드: Pandas DataFrame 등으로 데이터를 불러옵니다.
- 기본 정보 확인:
df.head(),df.info(),df.describe(),df.shape등을 통해 데이터의 구조, 타입, 기초 통계량, 크기 등을 파악합니다.
2. 데이터 탐색 및 시각화 (Exploratory Data Analysis, EDA) - 기초
- 데이터의 특성을 이해하고, 패턴을 발견하며, 문제점을 식별하는 과정.
- 주요 활동:
- 데이터 분포 확인: 각 특성(Feature)의 분포를 시각화 (히스토그램, 박스 플롯 등).
- 결측치 확인:
df.isnull().sum()등으로 결측치의 수와 위치 파악. - 이상치 확인: 박스 플롯이나 산점도 등으로 극단적인 값 확인.
- 타겟 변수 분포 확인: 분류 문제의 경우 클래스별 데이터 불균형 확인.
- 특성 간 관계 분석: 산점도 행렬(Scatter Matrix), 상관관계 히트맵(Correlation Heatmap) 등으로 특성 간의 관계 파악.
- 텍스트 데이터의 경우: 단어 빈도 분석, 워드 클라우드, 문장 길이 분포 등.
# EDA 예시 (Pandas, Matplotlib, Seaborn 사용)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# CSV 파일 로드 가정
# df = pd.read_csv('your_data.csv')
# --- 예시 데이터 생성 (실제로는 수집한 데이터 사용) ---
data_dict = {
'text': [
"This movie is great and wonderful!",
"Absolutely terrible film, I hated it.",
"Not bad, but could have been better.",
"An amazing masterpiece of cinema.",
None, # 결측치 예시
"Just okay, nothing special to write home about."
],
'sentiment': [1, 0, 0, 1, 1, 0], # 1: 긍정, 0: 부정
'rating': [5, 1, 3, 5, 4, 3] # 1-5점 척도
}
df = pd.DataFrame(data_dict)
# --- 예시 데이터 생성 끝 ---
print("데이터 샘플:")
print(df.head())
print("\n데이터 정보:")
df.info()
print("\n수치형 데이터 기술 통계:")
print(df.describe())
print("\n결측치 확인:")
print(df.isnull().sum())
# 타겟 변수 분포 (분류 문제의 경우)
if 'sentiment' in df.columns:
plt.figure(figsize=(6, 4))
sns.countplot(x='sentiment', data=df)
plt.title('Sentiment Distribution')
plt.show()
# 텍스트 길이 분포 (텍스트 데이터의 경우)
if 'text' in df.columns:
df['text_length'] = df['text'].astype(str).apply(len) # 결측치 때문에 str로 변환 후 길이 계산
plt.figure(figsize=(8, 5))
sns.histplot(df['text_length'], kde=True)
plt.title('Distribution of Text Length')
plt.show()
# (선택) 워드 클라우드 (텍스트 데이터)
# from wordcloud import WordCloud
# if 'text' in df.columns:
# all_text = " ".join(review for review in df['text'].astype(str) if review) # 결측치 제외
# if all_text:
# wordcloud = WordCloud(width=800, height=400, background_color='white').generate(all_text)
# plt.figure(figsize=(10, 5))
# plt.imshow(wordcloud, interpolation='bilinear')
# plt.axis("off")
# plt.title("Word Cloud of Reviews")
# plt.show()
3. 데이터 전처리 (Data Preprocessing)
- EDA 결과를 바탕으로 모델 학습에 적합하도록 데이터를 가공하고 정제하는 과정.
가. 결측치 처리 (Handling Missing Values)
- 결측치 확인:
df.isnull().sum() - 처리 방법:
- 삭제 (Deletion):
- 결측치가 포함된 행(Row) 또는 열(Column)을 삭제.
- 결측치가 매우 적거나, 해당 데이터가 중요하지 않을 때 사용.
df.dropna(axis=0)(행 삭제),df.dropna(axis=1)(열 삭제).
- 대치 (Imputation):
- 결측치를 특정 값으로 채움.
- 수치형 데이터: 평균(Mean), 중앙값(Median), 최빈값(Mode) 등으로 대치. 또는 예측 모델을 사용하여 대치.
df['column'].fillna(df['column'].mean(), inplace=True) - 범주형 데이터: 최빈값으로 대치. 또는 “Unknown“과 같은 새로운 카테고리 생성.
df['column'].fillna(df['column'].mode()[0], inplace=True) - 텍스트 데이터: 빈 문자열(“”) 또는 특정 토큰(“
<unk>”)으로 대치.df['text_column'].fillna("", inplace=True) scikit-learn의SimpleImputer사용 가능.
- 삭제 (Deletion):
나. 이상치 처리 (Handling Outliers) - (필요시)
- 데이터의 일반적인 분포에서 크게 벗어난 값.
- 탐지 방법: 박스 플롯, Z-score, IQR(Interquartile Range) 등.
- 처리 방법:
- 삭제: 이상치가 오류로 판단되거나 모델에 큰 악영향을 줄 경우.
- 변환 (Transformation): 로그 변환 등으로 데이터 분포를 조정.
- 값 수정 (Capping/Flooring): 특정 임계값(예: IQR 기준 상한/하한)으로 값을 제한.
- 그대로 사용: 이상치가 실제 현상을 반영하는 중요한 정보일 수 있음.
다. 텍스트 데이터 전처리 (NLP 프로젝트의 경우)
- Day 61에서 다룬 내용 복습 및 적용:
- 정제: HTML 태그, 특수 문자, 숫자 제거 또는 대체.
- 정규화: 소문자화, 축약형 처리.
- 토큰화: 단어 또는 형태소 단위로 분리 (영어: NLTK, spaCy / 한국어: KoNLPy).
- 불용어 제거: 의미 없는 단어 제거.
- 어간 추출 (Stemming) 또는 표제어 추출 (Lemmatization): 단어의 기본형으로 통일.
# 텍스트 전처리 예시 (간단화)
import re
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# nltk.download('punkt') # 최초 실행 시
# nltk.download('stopwords') # 최초 실행 시
stop_words = set(stopwords.words('english'))
def preprocess_text(text):
if pd.isnull(text): # 결측치 처리
return ""
text = text.lower() # 소문자화
text = re.sub(r'<[^>]+>', '', text) # HTML 태그 제거
text = re.sub(r'[^a-z\s]', '', text) # 알파벳과 공백 외 문자 제거
tokens = word_tokenize(text) # 토큰화
tokens = [word for word in tokens if word not in stop_words and len(word) > 1] # 불용어 및 한 글자 단어 제거
# (선택) 표제어 추출 등 추가 가능
return " ".join(tokens)
if 'text' in df.columns:
df['processed_text'] = df['text'].apply(preprocess_text)
print("\n전처리된 텍스트 샘플:")
print(df[['text', 'processed_text']].head())
라. 범주형 데이터 인코딩 (Categorical Data Encoding) - (해당되는 경우)
- 머신러닝 모델은 숫자 입력을 가정하므로, 범주형 특성(예: 성별, 지역명)을 숫자로 변환해야 합니다.
- 레이블 인코딩 (Label Encoding): 각 범주를 정수로 매핑 (예: ‘Red’:0, ‘Green’:1, ‘Blue’:2). 순서가 없는 명목형 변수에 부적절할 수 있음 (모델이 순서 관계로 오해 가능).
sklearn.preprocessing.LabelEncoder
- 원-핫 인코딩 (One-Hot Encoding): 각 범주를 새로운 이진 특성(0 또는 1)으로 변환. 범주 수만큼 차원이 증가.
sklearn.preprocessing.OneHotEncoder,pandas.get_dummies()
마. 특징 스케일링 (Feature Scaling) - (수치형 데이터, 거리 기반 모델 등에 중요)
- 서로 다른 범위의 값을 가진 특성들을 일정한 범위로 조정합니다.
- 목적: 특정 특성이 값의 크기 때문에 모델 학습에 과도한 영향을 미치는 것을 방지. 거리 기반 알고리즘(KNN, SVM, K-Means 등)이나 경사 하강법 기반 알고리즘(선형 회귀, 로지스틱 회귀, 신경망 등)에서 중요.
- 종류:
- 표준화 (Standardization): 특성의 평균을 0, 표준편차를 1로 변환. (Z-score 정규화)
sklearn.preprocessing.StandardScaler - 정규화 (Normalization / Min-Max Scaling): 특성의 값을 0과 1 사이의 범위로 변환.
sklearn.preprocessing.MinMaxScaler
- 표준화 (Standardization): 특성의 평균을 0, 표준편차를 1로 변환. (Z-score 정규화)
바. 데이터 분할 (Train-Test Split)
- 전처리된 데이터를 모델 학습용(Train Set)과 평가용(Test Set)으로 분리합니다.
sklearn.model_selection.train_test_split- 주의: 데이터 분할은 모든 전처리(특히 스케일링, 인코딩 등)가 완료된 후, 또는 학습 데이터에 대해서만
fit하고 테스트 데이터에는transform만 적용하는 방식으로 수행되어야 데이터 누수(Data Leakage)를 방지할 수 있습니다. (Pipeline 사용 권장)
4. 다음 단계: 특징 공학 및 모델링
- 오늘 전처리된 데이터를 바탕으로, 내일은 모델 성능을 더욱 향상시키기 위한 특징 공학(Feature Engineering) 단계를 진행하고, 본격적인 모델 학습 및 평가를 시작합니다.
- 특징 공학 예시:
- 텍스트 데이터: TF-IDF, Word Embeddings (Word2Vec, FastText, GloVe) 생성.
- 수치형 데이터: 다항 특성 생성, 상호작용 특성 생성.
- 날짜/시간 데이터: 연, 월, 일, 요일, 시간 등 파생 변수 생성.
실습 아이디어
- 본인이 선정한 캡스톤 프로젝트에 필요한 데이터를 수집하는 과정을 시작해보세요.
- 공개 데이터셋이라면 다운로드하고 로드합니다.
- 웹 크롤링이 필요하다면, 간단한 스크립트를 작성하여 소량의 데이터를 수집해봅니다. (대상 웹사이트의 정책 확인 필수)
- 수집한 데이터를 Pandas DataFrame으로 로드하고, 오늘 배운 EDA 기초 기법을 적용하여 데이터의 특성을 파악해보세요.
- 결측치, 이상치 등을 확인하고, 적절한 전처리 계획을 세워보세요. (실제 적용은 내일 특징 공학과 함께 진행해도 좋습니다.)
- 텍스트 데이터가 주된 프로젝트라면, 기본적인 텍스트 정제 및 토큰화 함수를 만들어 적용해보세요.
다음 학습 내용
- Day 89: 프로젝트를 위한 탐색적 데이터 분석 (EDA) 심화 및 특징 공학 (Exploratory Data Analysis (EDA) for the project and Feature Engineering) - 수집/전처리된 데이터에 대한 심층적인 분석과 모델 성능 향상을 위한 특징 생성.
Day 89: 프로젝트를 위한 탐색적 데이터 분석 (EDA) 심화 및 특징 공학 (Exploratory Data Analysis (EDA) for the project and Feature Engineering)
학습 목표
- 어제 수집 및 기본 전처리된 데이터를 바탕으로 심층적인 탐색적 데이터 분석(EDA) 수행.
- 데이터 시각화 및 통계적 분석을 통해 데이터 내 패턴, 관계, 이상 현상 등을 깊이 있게 파악.
- EDA 결과를 바탕으로 모델 성능 향상에 기여할 수 있는 새로운 특징(Feature)을 생성하거나 기존 특징을 변환하는 특징 공학(Feature Engineering) 기법 적용.
- 최종적으로 모델 학습에 사용할 데이터셋 준비.
1. 탐색적 데이터 분석 (EDA) 심화
- 어제 수행한 기초 EDA를 바탕으로, 더 구체적인 질문을 던지고 데이터로부터 인사이트를 얻는 과정입니다.
가. 분석 질문 정의
- 프로젝트 목표와 관련된 구체적인 질문들을 정의합니다.
- 예시 (영화 리뷰 감성 분석 프로젝트):
- 긍정 리뷰와 부정 리뷰는 어떤 단어 사용에서 차이를 보이는가?
- 리뷰 길이는 감성과 관련이 있는가?
- 특정 단어가 포함된 리뷰는 특정 감성으로 치우치는 경향이 있는가?
- (만약 사용자 정보가 있다면) 특정 사용자 그룹이 특정 감성의 리뷰를 더 많이 작성하는가?
- (만약 영화 장르 정보가 있다면) 특정 장르의 영화에 대한 감성 분포는 어떠한가?
나. 데이터 시각화 심화
- 단변량 분석 (Univariate Analysis): 개별 특성의 분포를 더 자세히 탐색.
- 수치형: 히스토그램(구간 조정), 밀도 플롯(Density Plot), QQ 플롯(정규성 확인).
- 범주형: 막대 그래프(빈도, 비율), 파이 차트.
- 텍스트: N-gram(바이그램, 트라이그램) 빈도 분석, 핵심 단어 추출.
- 이변량 분석 (Bivariate Analysis): 두 특성 간의 관계 탐색.
- 수치형 vs 수치형: 산점도(Scatter Plot), 상관계수 히트맵.
- 범주형 vs 수치형: 그룹별 박스 플롯, 그룹별 바이올린 플롯, 그룹별 평균 막대 그래프.
- 범주형 vs 범주형: 교차표(Contingency Table), 그룹화된 막대 그래프, 모자이크 플롯.
- 타겟 변수와 각 특성 간의 관계 분석이 중요.
- 다변량 분석 (Multivariate Analysis): 세 개 이상의 특성 간 관계 탐색.
- 산점도에 색상이나 크기로 세 번째 변수 표현.
- Pair Plot (Seaborn의
pairplot): 모든 수치형 특성 쌍에 대한 산점도와 대각선에는 각 특성의 분포 표시. - 3D 산점도 (표현의 한계가 있음).
- 차원 축소(PCA 등) 후 시각화.
# EDA 심화 예시 (어제 코드 이어서)
# (데이터프레임 df가 전처리된 상태라고 가정)
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
# from nltk.util import ngrams # N-gram 생성용
# --- 예시 데이터 (어제와 유사하게, 'processed_text' 컬럼이 있다고 가정) ---
data_dict_processed = {
'text': ["movie great wonderful", "terrible film hated", "not bad could better", "amazing masterpiece cinema", "", "okay nothing special write home"],
'sentiment': [1, 0, 0, 1, 1, 0],
'rating': [5, 1, 3, 5, 4, 3],
'text_length': [20, 20, 20, 25, 0, 35] # 임의의 길이
}
df = pd.DataFrame(data_dict_processed)
df.rename(columns={'text':'processed_text'}, inplace=True) # processed_text로 가정
# --- 예시 데이터 끝 ---
# 1. 긍정/부정 리뷰별 단어 빈도 비교 (간단 예시)
if 'processed_text' in df.columns and 'sentiment' in df.columns:
positive_texts = " ".join(df[df['sentiment'] == 1]['processed_text'])
negative_texts = " ".join(df[df['sentiment'] == 0]['processed_text'])
positive_word_counts = Counter(positive_texts.split())
negative_word_counts = Counter(negative_texts.split())
print("\n가장 흔한 긍정 단어 (상위 5개):", positive_word_counts.most_common(5))
print("가장 흔한 부정 단어 (상위 5개):", negative_word_counts.most_common(5))
# (선택) N-gram 분석
# positive_bigrams = list(ngrams(positive_texts.split(), 2))
# positive_bigram_counts = Counter(positive_bigrams)
# print("\n가장 흔한 긍정 바이그램 (상위 3개):", positive_bigram_counts.most_common(3))
# 2. 리뷰 길이와 감성 간의 관계 (박스 플롯)
if 'text_length' in df.columns and 'sentiment' in df.columns:
plt.figure(figsize=(7, 5))
sns.boxplot(x='sentiment', y='text_length', data=df)
plt.title('Text Length Distribution by Sentiment')
plt.xticks([0, 1], ['Negative', 'Positive'])
plt.show()
# 3. 평점(rating)과 감성(sentiment) 간의 관계 (교차표 및 시각화)
if 'rating' in df.columns and 'sentiment' in df.columns:
rating_sentiment_crosstab = pd.crosstab(df['rating'], df['sentiment'])
print("\n평점과 감성 간 교차표:\n", rating_sentiment_crosstab)
rating_sentiment_crosstab.plot(kind='bar', stacked=False, figsize=(8,5))
plt.title('Sentiment Distribution by Rating')
plt.xlabel('Rating')
plt.ylabel('Count')
plt.xticks(rotation=0)
plt.legend(title='Sentiment', labels=['Negative', 'Positive'])
plt.show()
# 4. (만약 수치형 특성이 더 있다면) Pair Plot
# num_features_df = df[['text_length', 'rating']] # 예시 수치형 특성
# if not num_features_df.empty:
# sns.pairplot(num_features_df)
# plt.suptitle('Pair Plot of Numerical Features', y=1.02)
# plt.show()
# 5. (만약 수치형 특성이 더 있다면) 상관관계 히트맵
# if not num_features_df.empty:
# plt.figure(figsize=(6,4))
# sns.heatmap(num_features_df.corr(), annot=True, cmap='coolwarm', fmt=".2f")
# plt.title('Correlation Heatmap of Numerical Features')
# plt.show()
2. 특징 공학 (Feature Engineering)
- 정의: 도메인 지식이나 EDA를 통해 얻은 통찰력을 바탕으로, 기존 특징으로부터 새로운 특징을 만들거나, 특징을 변환하여 모델의 성능을 향상시키는 과정.
- 머신러닝 프로젝트 성공에 매우 중요한 단계 중 하나입니다. “Garbage in, garbage out” - 좋은 특징이 좋은 모델을 만듭니다.
가. 특징 생성 (Feature Creation)
- 기존 특징들을 결합하거나 변형하여 새로운 정보를 담는 특징을 만듭니다.
- 예시:
- 날짜/시간 데이터: 연, 월, 일, 요일, 시간, 분기, 주말 여부, 공휴일 여부 등 파생 변수 생성.
- 텍스트 데이터:
- 텍스트 길이: 문장/문서의 단어 수, 문자 수.
- 특정 단어/구문 포함 여부: 긍정/부정 사전 단어 포함 수, 특정 키워드 존재 여부.
- N-gram 특징: 단어의 순서를 일부 고려 (예: “not good“은 “not“과 “good“을 따로 보는 것보다 의미 파악에 유리).
- 가독성 지수: 텍스트의 복잡도나 가독성을 나타내는 지표.
- 문장 부호 사용 빈도: 물음표, 느낌표 등의 빈도.
- 수치형 데이터:
- 다항 특성 (Polynomial Features): 기존 특성들의 거듭제곱 또는 교호작용 항 (예: x2, x*y).
sklearn.preprocessing.PolynomialFeatures. - 비율 또는 차이: 두 특성 간의 비율(예: 소득 대비 부채 비율)이나 차이.
- 그룹별 통계량: 특정 그룹(예: 카테고리) 내에서의 평균, 합계, 표준편차 등.
- 다항 특성 (Polynomial Features): 기존 특성들의 거듭제곱 또는 교호작용 항 (예: x2, x*y).
- 범주형 데이터:
- 빈도 인코딩 (Frequency Encoding): 범주의 등장 빈도로 인코딩.
- 타겟 인코딩 (Target Encoding): 범주별 타겟 변수의 평균값 등으로 인코딩 (데이터 누수 주의).
나. 특징 변환 (Feature Transformation)
- 기존 특징의 형태나 분포를 변경하여 모델이 더 잘 학습할 수 있도록 합니다.
- 예시:
- 로그 변환 (Log Transform): 왜도(Skewness)가 큰 데이터의 분포를 정규분포에 가깝게 만듦. 분산을 안정화.
- 제곱근 변환 (Square Root Transform).
- 박스-칵스 변환 (Box-Cox Transform): 정규성을 만족하도록 하는 변환. (데이터가 양수여야 함)
- 수치형 데이터를 범주형으로 변환 (Binning/Discretization): 연속형 변수를 특정 구간(Bin)으로 나누어 범주형으로 만듦. (예: 나이를 청년, 중년, 노년으로)
다. 특징 선택 (Feature Selection) - (필요시)
- 모델 성능에 중요하지 않거나 중복되는 특징을 제거하여 모델을 단순화하고 과적합을 방지하며 계산 효율성을 높입니다. (Day 71, 72의 PCA, LDA도 일종의 특징 선택/추출)
- 방법:
- 필터 방법 (Filter Methods): 통계적 측정값(상관계수, 카이제곱 검정, 분산 분석 등)을 사용하여 각 특징과 타겟 변수 간의 관련성을 평가하고 순위를 매겨 선택. 모델과 독립적으로 수행.
- 래퍼 방법 (Wrapper Methods): 특정 모델의 성능을 직접 평가 기준으로 삼아, 다양한 특징 부분집합을 시도하며 최적의 조합을 찾음. (예: 전진 선택, 후진 제거, 재귀적 특징 제거 -
RFE) 계산 비용이 높을 수 있음. - 임베디드 방법 (Embedded Methods): 모델 학습 과정 자체에 특징 선택이 포함된 방식. (예: L1 규제(Lasso)를 사용한 선형 모델, 트리 기반 모델의 특성 중요도)
특징 공학 예시 (Python 코드)
# 특징 공학 예시 (어제 코드 이어서)
# df에 'processed_text', 'sentiment', 'rating', 'text_length'가 있다고 가정
# 1. 텍스트 길이 제곱 특징 추가 (다항 특성 예시)
if 'text_length' in df.columns:
df['text_length_sq'] = df['text_length'] ** 2
# 2. 긍정/부정 단어 포함 수 (간단한 텍스트 특징 예시)
positive_keywords = ['great', 'amazing', 'wonderful', 'love', 'excellent']
negative_keywords = ['terrible', 'hated', 'bad', 'awful', 'poor']
def count_keywords(text, keywords):
count = 0
if pd.notnull(text): # 결측이 아닌 경우에만
for keyword in keywords:
if keyword in text.lower(): # 소문자로 변환 후 키워드 포함 여부 확인
count += 1
return count
if 'processed_text' in df.columns:
df['positive_keyword_count'] = df['processed_text'].apply(lambda x: count_keywords(x, positive_keywords))
df['negative_keyword_count'] = df['processed_text'].apply(lambda x: count_keywords(x, negative_keywords))
# 3. (만약 날짜 데이터가 있다면) 요일, 월 등 파생 변수 생성
# df['date_column'] = pd.to_datetime(df['date_column'])
# df['day_of_week'] = df['date_column'].dt.dayofweek
# df['month'] = df['date_column'].dt.month
# 4. 로그 변환 (예시: text_length가 매우 왜곡된 분포를 가질 경우)
# if 'text_length' in df.columns and df['text_length'].min() > 0: # 로그 변환은 양수 값에만 적용
# df['text_length_log'] = np.log(df['text_length'])
# else:
# df['text_length_log'] = np.log(df['text_length'] + 1) # 0을 피하기 위해 +1 (log1p와 유사)
print("\n특징 공학 후 데이터 샘플:")
print(df.head())
# 최종적으로 모델 학습에 사용할 특징 선택
# 예: features_for_model = df[['text_length', 'text_length_sq', 'positive_keyword_count', 'negative_keyword_count', 'rating']]
# 텍스트 자체를 사용하는 경우: processed_text 컬럼을 TF-IDF 등으로 변환
4. 최종 데이터셋 준비
- EDA와 특징 공학을 거쳐 최종적으로 모델 학습에 사용할 특징들을 선택하고, 이들을 포함하는 데이터셋을 구성합니다.
- 이 데이터셋은 이후 모델 학습, 평가, 하이퍼파라미터 튜닝 단계에서 사용됩니다.
- 주의: 특징 공학 과정에서도 데이터 누수(Data Leakage)가 발생하지 않도록 주의해야 합니다. 예를 들어, 타겟 변수의 정보를 사용하여 새로운 특징을 만들 때, 이 정보가 검증 세트나 테스트 세트에서 온 것이라면 안 됩니다. 일반적으로 학습 데이터에 대해서만
fit하고, 전체 데이터(학습, 검증, 테스트)에transform을 적용하는 파이프라인을 구성합니다.
실습 아이디어
- 본인의 캡스톤 프로젝트 데이터에 대해 오늘 배운 EDA 심화 기법들을 적용해보세요.
- 다양한 시각화를 통해 데이터의 숨겨진 패턴이나 관계를 찾아보세요.
- 프로젝트 목표와 관련된 구체적인 질문을 설정하고, EDA를 통해 답을 찾아보세요.
- EDA 결과를 바탕으로, 모델 성능에 도움이 될 만한 새로운 특징들을 2~3개 이상 생성해보세요.
- 텍스트 데이터라면 길이, 특정 단어 포함 여부, N-gram 등을 고려해보세요.
- 수치형 데이터라면 다항 특성, 비율, 그룹 통계 등을 고려해보세요.
- 생성한 특징들이 실제로 유용한지 간단한 모델(예: 로지스틱 회귀)로 테스트해보거나, 다음 모델링 단계에서 평가할 수 있도록 준비해두세요.
다음 학습 내용
- Day 90: 프로젝트를 위한 모델 선정 및 초기 학습 (Model Selection and initial training for the project) - 준비된 데이터를 사용하여 다양한 머신러닝/딥러닝 모델을 선택하고 초기 학습 및 평가를 진행.
Day 90: 프로젝트를 위한 모델 선정 및 초기 학습 (Model Selection and initial training for the project)
학습 목표
- 전처리 및 특징 공학이 완료된 데이터를 사용하여 캡스톤 프로젝트에 적합한 머신러닝/딥러닝 모델 후보군 선정.
- 선택한 모델들에 대해 초기 하이퍼파라미터로 학습을 진행하고, 교차 검증을 통해 기본적인 성능 평가.
- 다양한 모델들의 성능을 비교하여 향후 집중적으로 튜닝하고 개선할 주요 모델 선택.
- 모델 학습 및 평가 파이프라인 구축의 기초 마련.
1. 모델 후보군 선정
- 프로젝트의 문제 유형(분류, 회귀, NLP, 시계열 등), 데이터의 특성(크기, 차원, 희소성 등), 사용 가능한 자원(시간, 계산 능력) 등을 고려하여 적절한 모델 후보들을 선택합니다.
- 일반적인 가이드라인:
- 분류 문제:
- 기본 모델: 로지스틱 회귀(Logistic Regression), K-최근접 이웃(KNN), 나이브 베이즈(Naive Bayes).
- 트리 기반 모델: 결정 트리(Decision Tree), 랜덤 포레스트(Random Forest), 그래디언트 부스팅 머신(GBM), XGBoost, LightGBM.
- 서포트 벡터 머신 (SVM).
- 신경망/딥러닝: 다층 퍼셉트론(MLP), CNN (텍스트/이미지), RNN/LSTM (순차 데이터).
- 회귀 문제:
- 기본 모델: 선형 회귀(Linear Regression), 릿지(Ridge), 라쏘(Lasso), 엘라스틱넷(ElasticNet).
- 트리 기반 모델: 랜덤 포레스트 회귀, GBM 회귀, XGBoost 회귀, LightGBM 회귀.
- 서포트 벡터 회귀 (SVR).
- 신경망/딥러닝.
- 자연어 처리 (텍스트 분류/회귀):
- 전통적 방법: TF-IDF + (로지스틱 회귀, SVM, 나이브 베이즈, 랜덤 포레스트 등).
- 딥러닝: Word Embeddings + (LSTM, GRU, 1D CNN, BERT 기반 모델 등).
- 시계열 예측:
- 전통적 방법: ARIMA, SARIMA, 지수평활법.
- 머신러닝/딥러닝: 과거 시점을 특징으로 변환 후 회귀 모델 적용, RNN/LSTM.
- 분류 문제:
- 초기에는 너무 복잡한 모델보다는 해석 가능하고 빠르게 학습시킬 수 있는 모델부터 시작하는 것이 좋습니다. (예: 로지스틱 회귀, 간단한 트리 모델)
- 이후 점차 복잡도가 높은 모델(앙상블, 딥러닝)을 추가하여 비교합니다.
예시 (영화 리뷰 감성 분석 프로젝트 - 이진 분류):
- 후보 모델군:
- TF-IDF + 로지스틱 회귀 (베이스라인)
- TF-IDF + 나이브 베이즈
- TF-IDF + 랜덤 포레스트
- Word2Vec (사전 훈련 또는 직접 학습) + LSTM
- (선택) BERT 기반 사전 훈련 모델 미세 조정 (Fine-tuning) - 고급
2. 데이터 준비 및 분할
- Day 88, 89에서 준비한 최종 데이터셋을 사용합니다.
- 학습 데이터(Train Set)와 테스트 데이터(Test Set)로 분할합니다.
sklearn.model_selection.train_test_split- 테스트 세트는 모델의 최종 성능 평가에만 사용하고, 모델 선택 및 하이퍼파라미터 튜닝 과정에서는 사용하지 않습니다.
- 교차 검증을 위한 준비: 모델 선택 및 튜닝 과정에서는 학습 데이터를 다시 여러 폴드로 나누어 교차 검증을 수행합니다.
import pandas as pd
from sklearn.model_selection import train_test_split
# from sklearn.feature_extraction.text import TfidfVectorizer # 예시용
# from tensorflow.keras.preprocessing.text import Tokenizer # 예시용
# from tensorflow.keras.preprocessing.sequence import pad_sequences # 예시용
# --- 예시 데이터 로드 (Day 89에서 생성된 df_final.csv 가정) ---
# 실제 프로젝트에서는 이전 단계에서 생성/저장한 데이터를 로드합니다.
# df_final = pd.read_csv('capstone_data_processed_featured.csv')
# X_text = df_final['processed_text_or_features'] # 텍스트 또는 특징 컬럼
# y = df_final['sentiment'] # 타겟 변수
# --- 간략화된 예시 데이터 (실제 프로젝트 데이터 사용) ---
# (Day 89의 df와 유사한 형태라고 가정, 텍스트 특징과 수치 특징이 섞여있을 수 있음)
# 여기서는 'processed_text'가 주요 입력이고 'sentiment'가 타겟이라고 가정
data_for_modeling = {
'processed_text': [
"movie great wonderful", "terrible film hated", "not bad could better",
"amazing masterpiece cinema", "okay nothing special write home",
"fantastic story engaging characters", "boring plot uninspired acting",
"truly enjoyed this experience", "would not recommend this", "a must see film"
],
'sentiment': [1, 0, 0, 1, 0, 1, 0, 1, 0, 1],
# ... (다른 특징들이 있다면 함께 포함)
}
df_model = pd.DataFrame(data_for_modeling)
X_text_data = df_model['processed_text']
y_target = df_model['sentiment']
# --- 간략화된 예시 데이터 끝 ---
# 1. 학습/테스트 데이터 분할
X_train_text, X_test_text, y_train, y_test = train_test_split(
X_text_data, y_target, test_size=0.2, random_state=42, stratify=y_target
)
print("학습 데이터 크기:", X_train_text.shape, y_train.shape)
print("테스트 데이터 크기:", X_test_text.shape, y_test.shape)
# 2. 텍스트 데이터 벡터화 (예: TF-IDF) - 전통적 모델용
# (실제로는 Day 89에서 생성한 특징을 사용하거나, 여기서 새로 생성)
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer(max_features=100) # 예시로 최대 특징 100개
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train_text)
X_test_tfidf = tfidf_vectorizer.transform(X_test_text)
print("TF-IDF 벡터화된 학습 데이터 크기:", X_train_tfidf.shape)
# 3. (딥러닝 모델용) 텍스트 데이터 정수 인코딩 및 패딩 - LSTM 등 딥러닝 모델용
# from tensorflow.keras.preprocessing.text import Tokenizer
# from tensorflow.keras.preprocessing.sequence import pad_sequences
# vocab_size = 500 # 어휘 크기
# max_length = 20 # 최대 시퀀스 길이
# oov_tok = "<unk>"
# tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
# tokenizer.fit_on_texts(X_train_text)
# X_train_seq = tokenizer.texts_to_sequences(X_train_text)
# X_test_seq = tokenizer.texts_to_sequences(X_test_text)
# X_train_pad = pad_sequences(X_train_seq, maxlen=max_length, padding='post', truncating='post')
# X_test_pad = pad_sequences(X_test_seq, maxlen=max_length, padding='post', truncating='post')
# print("패딩된 학습 시퀀스 데이터 크기:", X_train_pad.shape)
3. 초기 모델 학습 및 평가 (교차 검증 사용)
- 선택한 모델 후보군에 대해 기본 하이퍼파라미터 또는 간단하게 설정한 하이퍼파라미터로 학습을 진행합니다.
sklearn.model_selection.cross_val_score또는cross_validate를 사용하여 교차 검증을 수행하고, 주요 평가지표(정확도, F1 점수, ROC AUC 등)를 기록합니다.- 딥러닝 모델의 경우, 교차 검증이 시간과 자원을 많이 소모할 수 있으므로, 학습 데이터의 일부를 검증 세트(Validation Set)로 분리하여 평가하거나, K-폴드 수를 줄여서(예: 3-폴드) 수행할 수 있습니다.
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, StratifiedKFold
import numpy as np
# 교차 검증 설정
cv_stratified = StratifiedKFold(n_splits=3, shuffle=True, random_state=42) # 예시로 3-폴드
# 모델 후보군 정의
models = {
"Logistic Regression": LogisticRegression(solver='liblinear', random_state=42),
"Multinomial Naive Bayes": MultinomialNB(),
"Random Forest": RandomForestClassifier(n_estimators=50, random_state=42, n_jobs=-1) # 간단한 설정
}
results = {} # 모델별 성능 저장
print("\n--- 초기 모델 학습 및 교차 검증 (TF-IDF 기반) ---")
for model_name, model_instance in models.items():
# cross_val_score는 여러 평가지표를 한 번에 반환하지 않으므로, 필요시 각각 실행
accuracy_scores = cross_val_score(model_instance, X_train_tfidf, y_train, cv=cv_stratified, scoring='accuracy', n_jobs=-1)
f1_scores = cross_val_score(model_instance, X_train_tfidf, y_train, cv=cv_stratified, scoring='f1_macro', n_jobs=-1) # macro f1 사용 예시
results[model_name] = {
'mean_accuracy': np.mean(accuracy_scores),
'std_accuracy': np.std(accuracy_scores),
'mean_f1_macro': np.mean(f1_scores),
'std_f1_macro': np.std(f1_scores)
}
print(f"\n{model_name}:")
print(f" 평균 정확도: {results[model_name]['mean_accuracy']:.4f} (±{results[model_name]['std_accuracy']:.4f})")
print(f" 평균 F1 (Macro): {results[model_name]['mean_f1_macro']:.4f} (±{results[model_name]['std_f1_macro']:.4f})")
# 결과 비교
results_df = pd.DataFrame(results).T.sort_values(by='mean_f1_macro', ascending=False)
print("\n\n--- 모델별 교차 검증 성능 비교 (F1 Macro 기준 정렬) ---")
print(results_df)
# --- (선택) 딥러닝 모델 (LSTM) 초기 학습 예시 (Keras) ---
# from tensorflow.keras.models import Sequential
# from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout
# from tensorflow.keras.callbacks import EarlyStopping
# from sklearn.metrics import f1_score # Keras 모델 평가용
# def create_lstm_model(vocab_size_dl, embedding_dim_dl, max_length_dl, lstm_units=64, dropout_rate=0.2):
# model = Sequential([
# Embedding(input_dim=vocab_size_dl, output_dim=embedding_dim_dl, input_length=max_length_dl),
# LSTM(units=lstm_units, dropout=dropout_rate, recurrent_dropout=dropout_rate),
# Dense(units=1, activation='sigmoid')
# ])
# model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# return model
# # 딥러닝 모델용 데이터 준비 (위에서 주석 처리된 부분 참고하여 X_train_pad, y_train 사용)
# # vocab_size, max_length, embedding_dim 등은 실제 데이터에 맞게 설정 필요
# # embedding_dim = 100
# # K-Fold 교차 검증 (딥러닝 모델은 시간이 오래 걸리므로 주의)
# # 또는 간단히 학습 데이터의 일부를 검증 데이터로 분리하여 평가
# # lstm_f1_scores = []
# # for fold_idx, (train_idx, val_idx) in enumerate(cv_stratified.split(X_train_pad, y_train)):
# # print(f"\n--- LSTM Fold {fold_idx+1}/{cv_stratified.get_n_splits()} ---")
# # X_train_fold, X_val_fold = X_train_pad[train_idx], X_train_pad[val_idx]
# # y_train_fold, y_val_fold = y_train.iloc[train_idx], y_train.iloc[val_idx] # y_train이 Series일 경우 iloc 사용
# # lstm_model = create_lstm_model(vocab_size, embedding_dim, max_length)
# # early_stopping = EarlyStopping(monitor='val_loss', patience=2, restore_best_weights=True)
# # history = lstm_model.fit(X_train_fold, y_train_fold,
# # epochs=5, # 초기에는 적은 에포크로 테스트
# # batch_size=32,
# # validation_data=(X_val_fold, y_val_fold),
# # callbacks=[early_stopping],
# # verbose=1)
# # y_pred_val = (lstm_model.predict(X_val_fold) > 0.5).astype("int32")
# # f1_val = f1_score(y_val_fold, y_pred_val, average='macro')
# # lstm_f1_scores.append(f1_val)
# # print(f"Fold {fold_idx+1} F1 (Macro): {f1_val:.4f}")
# # if lstm_f1_scores:
# # print(f"\nLSTM 평균 F1 (Macro): {np.mean(lstm_f1_scores):.4f} (±{np.std(lstm_f1_scores):.4f})")
# # results['LSTM'] = {
# # 'mean_accuracy': np.nan, # 정확도는 history에서 가져와야 함
# # 'std_accuracy': np.nan,
# # 'mean_f1_macro': np.mean(lstm_f1_scores),
# # 'std_f1_macro': np.std(lstm_f1_scores)
# # }
# # results_df = pd.DataFrame(results).T.sort_values(by='mean_f1_macro', ascending=False)
# # print("\n\n--- 모델별 교차 검증 성능 비교 (LSTM 포함) ---")
# # print(results_df)
4. 초기 결과 분석 및 다음 단계 결정
- 각 모델의 교차 검증 성능(평균 및 표준편차)을 비교합니다.
- 고려 사항:
- 성능: 어떤 모델이 가장 좋은 성능을 보이는가? (예: F1 점수, ROC AUC)
- 안정성: 교차 검증 폴드 간 성능 표준편차가 작은가? (표준편차가 크면 모델이 데이터 분할에 민감하다는 의미)
- 학습 시간: 모델 학습에 소요되는 시간은 현실적인가?
- 해석 가능성: 모델의 예측 결과를 얼마나 쉽게 해석할 수 있는가? (필요하다면)
- 구현 복잡도: 모델 구현 및 관리가 얼마나 복잡한가?
- 이 결과를 바탕으로, 1~3개 정도의 유망한 모델을 선택하여 다음 단계인 하이퍼파라미터 튜닝 및 모델 개선을 진행합니다.
- 성능이 매우 낮은 모델은 제외하거나, 특징 공학 또는 데이터 전처리를 다시 검토하여 개선할 여지가 있는지 확인합니다.
- 특정 모델이 특정 평가지표에서는 좋지만 다른 지표에서는 나쁠 수 있으므로, 프로젝트 목표에 맞는 주요 평가지표를 기준으로 판단합니다.
5. 파이프라인 구축의 중요성
- 데이터 전처리, 특징 공학, 모델 학습, 평가 과정을 연결하는 파이프라인(
sklearn.pipeline.Pipeline)을 구축하면 코드를 간결하게 만들고, 데이터 누수를 방지하며, 전체 워크플로우를 효율적으로 관리할 수 있습니다. - 특히 교차 검증이나 하이퍼파라미터 튜닝 시 파이프라인을 사용하면 각 폴드마다 전처리 과정을 올바르게 적용하는 데 매우 유용합니다.
실습 아이디어
- 본인의 캡스톤 프로젝트 데이터에 대해 오늘 배운 내용을 적용해보세요.
- 프로젝트에 적합한 모델 후보군을 3개 이상 선정합니다.
- 각 모델에 대해 초기 하이퍼파라미터로 설정하고, (계층별) K-폴드 교차 검증을 수행하여 주요 평가지표(정확도, F1 점수 등)를 기록합니다.
- (선택) Scikit-learn의
Pipeline을 사용하여 전처리(예: TF-IDF 벡터화)와 모델 학습을 하나로 묶어 교차 검증을 수행해보세요.
- 교차 검증 결과를 비교하여, 다음 단계에서 집중적으로 개선할 모델 1~2개를 선정하고 그 이유를 정리해보세요.
다음 학습 내용
- Day 91: 프로젝트를 위한 모델 평가 및 반복 (Model Evaluation and Iteration for the project) - 선택된 모델들의 테스트 세트 성능을 상세히 평가하고, 오류 분석 등을 통해 모델 개선 방향을 설정하며 반복적으로 모델을 개선.
Day 91: 프로젝트를 위한 모델 평가 및 반복 (Model Evaluation and Iteration for the project)
학습 목표
- 초기 학습 및 교차 검증을 통해 선택된 주요 모델(들)에 대해 테스트 세트(Test Set)를 사용하여 최종 성능 평가.
- 다양한 평가지표(정밀도, 재현율, F1 점수, ROC AUC, 오차 행렬 등)를 종합적으로 분석하여 모델의 강점과 약점 파악.
- 오류 분석(Error Analysis)을 통해 모델이 어떤 유형의 샘플에서 실수를 하는지 구체적으로 조사.
- 분석 결과를 바탕으로 모델 개선을 위한 반복(Iteration) 전략 수립:
- 특징 공학 추가/수정
- 데이터 추가 수집 또는 증강(Augmentation)
- 하이퍼파라미터 미세 조정
- 다른 모델 아키텍처 시도
1. 테스트 세트를 사용한 최종 성능 평가
- 모델 선택 및 하이퍼파라미터 튜닝 과정에서는 **학습 데이터(Train Data)**와 (교차) **검증 데이터(Validation Data)**만을 사용해야 합니다.
- **테스트 세트(Test Set)**는 모델 개발의 가장 마지막 단계에서, 최종적으로 선택되고 튜닝된 모델의 일반화 성능을 딱 한 번 평가하는 데 사용됩니다.
- 테스트 세트의 성능은 모델이 실제 운영 환경에서 보일 것으로 기대되는 성능의 추정치가 됩니다.
# Day 90에서 준비된 X_test_tfidf, y_test (또는 X_test_pad 등) 사용
# Day 90에서 선택된 최적 모델 (예: best_model_from_grid_search 또는 tuned_lstm_model) 사용
# --- 예시: Day 90의 Logistic Regression 모델을 최종 선택했다고 가정 ---
# (실제로는 하이퍼파라미터 튜닝까지 완료된 모델이어야 함)
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd # 결과 정리를 위해
# (Day 90에서 학습된 최적 모델을 불러오거나, 여기서 간단히 재학습 가정)
# 여기서는 Day 90의 초기 모델 중 하나를 예시로 사용
# 실제로는 하이퍼파라미터 튜닝된 모델이어야 합니다.
# best_model = results_df.index[0] # 가장 성능 좋았던 모델 이름
# print(f"평가를 위해 선택된 모델: {best_model}") # 예시: RandomForestClassifier
# (데이터 준비 - Day 90의 X_train_tfidf, y_train, X_test_tfidf, y_test 사용)
# --- 간략화된 예시 데이터 및 모델 (실제 프로젝트 데이터 및 튜닝된 모델 사용) ---
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
data_for_modeling = {
'processed_text': [
"movie great wonderful", "terrible film hated", "not bad could better",
"amazing masterpiece cinema", "okay nothing special write home",
"fantastic story engaging characters", "boring plot uninspired acting",
"truly enjoyed this experience", "would not recommend this", "a must see film"
],
'sentiment': [1, 0, 0, 1, 0, 1, 0, 1, 0, 1],
}
df_model = pd.DataFrame(data_for_modeling)
X_text_data = df_model['processed_text']
y_target = df_model['sentiment']
X_train_text, X_test_text, y_train, y_test = train_test_split(
X_text_data, y_target, test_size=0.2, random_state=42, stratify=y_target
)
tfidf_vectorizer = TfidfVectorizer(max_features=100)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train_text)
X_test_tfidf = tfidf_vectorizer.transform(X_test_text)
# 최종 평가할 모델 (예: 로지스틱 회귀 - 실제로는 튜닝된 모델)
final_model = LogisticRegression(solver='liblinear', random_state=42)
final_model.fit(X_train_tfidf, y_train) # 학습 데이터 전체로 최종 학습
# --- 간략화된 예시 데이터 및 모델 끝 ---
# 1. 테스트 세트에 대한 예측
y_pred_test = final_model.predict(X_test_tfidf)
try:
y_pred_proba_test = final_model.predict_proba(X_test_tfidf)[:, 1] # Positive 클래스 확률
except AttributeError: # 일부 모델은 predict_proba를 지원 안 할 수 있음 (예: SVM 기본)
y_pred_proba_test = None
print("선택된 모델이 predict_proba를 지원하지 않아 ROC AUC 계산이 불가능할 수 있습니다.")
# 2. 평가지표 계산
accuracy_test = accuracy_score(y_test, y_pred_test)
precision_test = precision_score(y_test, y_pred_test, average='macro', zero_division=0)
recall_test = recall_score(y_test, y_pred_test, average='macro', zero_division=0)
f1_test = f1_score(y_test, y_pred_test, average='macro', zero_division=0)
print("\n--- 최종 모델 테스트 세트 평가 결과 ---")
print(f"정확도 (Accuracy): {accuracy_test:.4f}")
print(f"정밀도 (Precision, Macro): {precision_test:.4f}")
print(f"재현율 (Recall, Macro): {recall_test:.4f}")
print(f"F1 점수 (F1 Score, Macro): {f1_test:.4f}")
if y_pred_proba_test is not None:
try:
roc_auc_test = roc_auc_score(y_test, y_pred_proba_test) # 이진 분류 시
# 다중 클래스인 경우: roc_auc_score(y_test, final_model.predict_proba(X_test_tfidf), multi_class='ovr' or 'ovo')
print(f"ROC AUC: {roc_auc_test:.4f}")
except ValueError as e: # 예: 단일 클래스만 예측된 경우 등
print(f"ROC AUC 계산 중 오류: {e}")
roc_auc_test = None
else:
roc_auc_test = None
# 3. 오차 행렬 (Confusion Matrix) 시각화
cm_test = confusion_matrix(y_test, y_pred_test)
plt.figure(figsize=(6, 5))
sns.heatmap(cm_test, annot=True, fmt='d', cmap='Blues',
xticklabels=final_model.classes_ if hasattr(final_model, 'classes_') else ['Neg', 'Pos'],
yticklabels=final_model.classes_ if hasattr(final_model, 'classes_') else ['Neg', 'Pos'])
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix on Test Set')
plt.show()
# 4. 분류 리포트 (Classification Report)
print("\n분류 리포트 (Classification Report):\n", classification_report(y_test, y_pred_test, zero_division=0))
2. 오류 분석 (Error Analysis)
- 모델이 어떤 부분에서 실수를 하는지 구체적으로 살펴보는 과정입니다. 이는 모델 개선에 매우 중요한 단서를 제공합니다.
- 주요 방법:
- 오차 행렬 상세 분석:
- FN (False Negative): 실제 Positive인데 Negative로 잘못 예측한 경우. (예: 실제 긍정 리뷰를 부정으로) 왜 이런 실수가 발생했을까?
- FP (False Positive): 실제 Negative인데 Positive로 잘못 예측한 경우. (예: 실제 부정 리뷰를 긍정으로) 왜 이런 실수가 발생했을까?
- 잘못 분류된 샘플 직접 확인: 모델이 틀린 예측을 한 실제 데이터 샘플(텍스트, 이미지 등)을 직접 살펴봅니다.
- 어떤 특징을 가진 샘플에서 주로 오류가 발생하는가?
- 데이터 레이블링 자체에 오류는 없는가?
- 모델이 이해하기 어려운 애매모호한 표현, 비꼬는 말투, 문맥 의존적인 내용 등이 포함되어 있는가?
- 특정 클래스에서 유독 오류가 많이 발생하는가? (클래스 불균형 문제와 연관 가능)
- 예측 확률(Confidence Score) 분석:
- 모델이 매우 높은 확률로 틀린 예측을 한 경우.
- 모델이 애매하게(예측 확률이 0.5 근처) 예측하여 틀린 경우.
- 특성 중요도(Feature Importance) 또는 모델 내부 가중치 확인 (해석 가능한 모델의 경우):
- 모델이 어떤 특징에 의존하여 예측하는지, 잘못된 특징에 과도하게 의존하고 있지는 않은지 확인.
- (NLP) 어텐션 가중치 시각화 (트랜스포머, 어텐션 기반 RNN 등).
- 오차 행렬 상세 분석:
# 오류 분석 예시 (잘못 분류된 샘플 확인)
# (X_test_text, y_test, y_pred_test 가 준비되어 있다고 가정)
# 데이터프레임으로 만들어 분석 용이하게
df_test_results = pd.DataFrame({'text': X_test_text, 'actual': y_test, 'predicted': y_pred_test})
# FN (실제:1, 예측:0) 과 FP (실제:0, 예측:1) 샘플 분리
false_negatives = df_test_results[(df_test_results['actual'] == 1) & (df_test_results['predicted'] == 0)]
false_positives = df_test_results[(df_test_results['actual'] == 0) & (df_test_results['predicted'] == 1)]
print(f"\n--- 오류 분석: False Negatives (실제 긍정 -> 예측 부정) ---")
if not false_negatives.empty:
for index, row in false_negatives.head().iterrows(): # 상위 몇 개만 출력
print(f" 실제 텍스트: {row['text']}")
print(f" 실제 레이블: {row['actual']}, 예측 레이블: {row['predicted']}\n")
else:
print(" False Negative 샘플이 없습니다.")
print(f"\n--- 오류 분석: False Positives (실제 부정 -> 예측 긍정) ---")
if not false_positives.empty:
for index, row in false_positives.head().iterrows():
print(f" 실제 텍스트: {row['text']}")
print(f" 실제 레이블: {row['actual']}, 예측 레이블: {row['predicted']}\n")
else:
print(" False Positive 샘플이 없습니다.")
# (선택) 예측 확률과 함께 보기 (y_pred_proba_test 사용)
# if y_pred_proba_test is not None:
# df_test_results['probability_positive'] = y_pred_proba_test
# # 예측 확률이 0.4~0.6 사이인 애매한 예측들 확인 등
3. 모델 개선을 위한 반복 (Iteration) 전략
- 테스트 세트 평가와 오류 분석 결과를 바탕으로 모델을 개선하기 위한 다음 단계를 결정합니다.
- 이 과정은 한 번에 끝나지 않고, 여러 번 반복될 수 있습니다 (Iterative Process).
가. 데이터 관점
- 데이터 추가 수집: 특정 유형의 오류가 많이 발생한다면, 해당 유형의 데이터를 더 많이 수집하여 모델이 학습하도록 합니다. (예: 비꼬는 표현이 포함된 리뷰 데이터 추가)
- 데이터 증강 (Data Augmentation): (특히 딥러닝, 이미지/텍스트) 기존 데이터를 변형하여 학습 데이터의 양과 다양성을 늘립니다.
- 텍스트: 역번역(Back-translation), 동의어 대체, 무작위 삽입/삭제 등.
- 데이터 레이블링 품질 개선: 레이블링 오류가 발견되면 수정합니다. 모호한 샘플에 대한 레이블링 가이드라인을 명확히 합니다.
- 클래스 불균형 해소: 소수 클래스 데이터에 대한 오버샘플링(SMOTE 등), 다수 클래스 데이터에 대한 언더샘플링, 또는 손실 함수 가중치 조절 등을 시도합니다.
나. 특징 공학 관점
- 새로운 특징 생성: 오류 분석을 통해 얻은 인사이트를 바탕으로 모델이 더 잘 일반화할 수 있는 새로운 특징을 만듭니다.
- 예: (감성 분석) 문장 내 부정어의 존재 여부, 감정 단어의 강도, 특정 문장 부호의 빈도 등을 특징으로 추가.
- 기존 특징 수정/제거: 중요도가 낮거나 노이즈로 작용하는 특징을 제거하거나, 다른 방식으로 변환합니다.
- 특징 스케일링 재검토: 사용한 스케일링 방법이 적절했는지 확인합니다.
다. 모델 관점
- 하이퍼파라미터 미세 조정 (Fine-tuning): Day 75에서 배운 그리드 서치, 랜덤 서치, 베이지안 최적화 등을 사용하여 현재 모델의 하이퍼파라미터를 더 정교하게 튜닝합니다. (교차 검증 사용)
- 다른 모델 아키텍처 시도:
- 현재 모델군 외에 다른 유형의 모델을 시도해봅니다. (예: 전통적 ML 모델에서 딥러닝 모델로, 또는 그 반대)
- (딥러닝) 레이어 추가/제거, 유닛 수 변경, 다른 활성화 함수나 옵티마이저 사용, 어텐션 메커니즘 도입 등.
- 앙상블 기법 활용: 여러 모델의 예측을 결합하여 성능을 향상시킵니다. (배깅, 부스팅, 스태킹)
- 전이 학습 (Transfer Learning): (특히 딥러닝, NLP/비전) 대규모 데이터로 사전 훈련된 모델을 가져와 현재 문제에 맞게 미세 조정합니다.
라. 반복 주기
- 가설 수립: 오류 분석 결과를 바탕으로 “어떤 변경이 모델 성능을 향상시킬 것이다“라는 가설을 세웁니다.
- 실험: 가설에 따라 데이터, 특징, 모델 등을 수정하고 다시 학습 및 (검증 세트) 평가를 수행합니다.
- 결과 분석: 변경 사항이 실제로 성능 향상에 기여했는지, 새로운 문제는 없는지 분석합니다.
- 반복 또는 종료: 목표 성능에 도달했거나 더 이상 개선의 여지가 크지 않다고 판단되면 반복을 종료합니다. 그렇지 않으면 다시 1단계로 돌아갑니다.
주의: 모델 개선을 위한 모든 실험과 변경은 학습 데이터와 검증 데이터를 사용하여 이루어져야 합니다. 테스트 세트는 최종 평가에만 사용되어야 그 의미가 있습니다. 만약 테스트 세트를 반복적으로 사용하여 모델을 수정한다면, 테스트 세트에 과적합될 위험이 있습니다.
실습 아이디어
- 본인의 캡스톤 프로젝트에서 Day 90에 선택한 주요 모델(들)에 대해 테스트 세트 성능을 상세히 평가해보세요.
- 다양한 평가지표(정확도, 정밀도, 재현율, F1, ROC AUC 등)를 계산하고 기록합니다.
- 오차 행렬을 시각화하고, 분류 리포트를 출력하여 각 클래스별 성능을 확인합니다.
- 모델이 잘못 예측한 샘플들(FN, FP)을 최소 5~10개 이상 직접 살펴보세요.
- 어떤 특징을 가진 샘플에서 오류가 주로 발생하는지 패턴을 찾아보세요.
- 가능한 오류의 원인(데이터 문제, 특징 부족, 모델 한계 등)을 추측해보세요.
- 오류 분석 결과를 바탕으로, 모델 성능을 개선하기 위한 아이디어를 2~3가지 이상 구체적으로 정리해보세요. (예: “부정어를 포함한 문장에 대한 특징을 추가한다”, “특정 단어들에 대한 임베딩을 개선한다”, “LSTM 모델의 유닛 수를 늘려본다” 등)
다음 학습 내용
- Day 92: 프로젝트를 위한 미세 조정 및 최적화 (Fine-tuning and Optimization for the project) - 오류 분석 및 개선 아이디어를 바탕으로 실제 모델 하이퍼파라미터 튜닝, 특징 공학 수정 등을 통해 모델 성능을 최적화하는 작업.
Day 92: 프로젝트를 위한 미세 조정 및 최적화 (Fine-tuning and Optimization for the project)
학습 목표
- 어제(Day 91)의 오류 분석 및 모델 개선 아이디어를 바탕으로, 선택된 주요 모델의 성능을 극대화하기 위한 미세 조정 및 최적화 작업 수행.
- 하이퍼파라미터 튜닝 기법(그리드 서치, 랜덤 서치, 베이지안 최적화 등)을 실제로 적용하여 최적의 하이퍼파라미터 조합 탐색.
- 특징 공학 아이디어를 실제로 구현하고, 그 효과를 검증.
- (딥러닝 모델의 경우) 학습률 스케줄링, 조기 종료, 배치 정규화, 드롭아웃 등의 기법을 활용하여 학습 안정성 및 일반화 성능 향상.
- 반복적인 실험과 평가를 통해 최적의 모델 구성 도출.
1. 하이퍼파라미터 튜닝 (Hyperparameter Tuning) 심화
- Day 75에서 학습한 내용을 바탕으로, Day 90에서 선택된 유망한 모델(들)에 대해 본격적인 하이퍼파라미터 튜닝을 진행합니다.
가. 튜닝 대상 하이퍼파라미터 및 탐색 범위 설정
- 모델별 주요 하이퍼파라미터 숙지:
- 로지스틱 회귀:
C(규제 강도),penalty(‘l1’, ‘l2’),solver. - 랜덤 포레스트/GBM/XGBoost/LightGBM:
n_estimators,max_depth,learning_rate(부스팅 계열),min_samples_split,min_samples_leaf,subsample,colsample_bytree, 규제 파라미터 (reg_alpha,reg_lambda등). - SVM:
C,kernel(‘linear’, ‘rbf’, ‘poly’),gamma(rbf, poly 커널),degree(poly 커널). - LSTM/RNN (Keras): 임베딩 차원, LSTM/RNN 유닛 수, 드롭아웃 비율, 옵티마이저 종류 및 학습률, 배치 크기.
- 로지스틱 회귀:
- 탐색 범위 설정:
- 너무 넓으면 계산 비용이 커지고, 너무 좁으면 최적값을 놓칠 수 있습니다.
- 일반적으로 로그 스케일(Logarithmic Scale)로 탐색하는 것이 효과적인 경우가 많습니다 (예:
C: [0.01, 0.1, 1, 10, 100]). - 이전 실험 결과나 관련 연구/문서를 참고하여 합리적인 범위를 설정합니다.
나. 튜닝 도구 선택 및 적용
- Scikit-learn 모델:
GridSearchCV: 모든 조합 탐색. 계산량이 많을 수 있음.RandomizedSearchCV: 지정된 횟수만큼 무작위 조합 탐색. 계산 효율적.- 교차 검증(
cv) 폴드 수와 평가지표(scoring)를 적절히 설정.
- Keras (TensorFlow) 딥러닝 모델:
KerasTuner: Keras 모델을 위한 하이퍼파라미터 튜닝 라이브러리 (RandomSearch, Hyperband, BayesianOptimization 지원).- 또는
GridSearchCV/RandomizedSearchCV와 Keras 모델을 래핑하는KerasClassifier/KerasRegressor(fromscikeras.wrappers또는 과거tf.keras.wrappers.scikit_learn)를 함께 사용할 수 있으나, KerasTuner가 더 권장됨.
- XGBoost/LightGBM:
- Scikit-learn 래퍼 사용 시
GridSearchCV/RandomizedSearchCV활용. - 자체 API 사용 시, 반복문을 통해 직접 탐색하거나
Optuna,Hyperopt와 같은 베이지안 최적화 도구 사용.
- Scikit-learn 래퍼 사용 시
- 베이지안 최적화 도구 (고급):
Optuna,Hyperopt,Scikit-Optimize (skopt)등. 이전 탐색 결과를 바탕으로 다음 탐색 지점을 효율적으로 결정.
# 하이퍼파라미터 튜닝 예시 (Random Forest 모델, RandomizedSearchCV 사용)
# (Day 90, 91의 X_train_tfidf, y_train 사용 가정)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint # 정수형 랜덤 값 생성용
# 1. 튜닝할 모델 정의
rf_model = RandomForestClassifier(random_state=42, n_jobs=-1)
# 2. 하이퍼파라미터 탐색 공간 정의
param_dist_rf = {
'n_estimators': randint(50, 300), # 50에서 299 사이의 정수
'max_depth': [None] + list(randint(5, 30).rvs(5)), # None 또는 5~29 사이 랜덤 정수 5개
'min_samples_split': randint(2, 20),
'min_samples_leaf': randint(1, 20),
'max_features': ['sqrt', 'log2', None] + list(np.random.uniform(0.1, 1.0, 3)), # 문자열 또는 0.1~1.0 사이 랜덤 실수 3개
'bootstrap': [True, False],
'criterion': ['gini', 'entropy']
}
# 3. RandomizedSearchCV 객체 생성
# n_iter: 시도할 조합 수
# cv: 교차 검증 폴드 수
# scoring: 평가지표
# random_state: 재현성
# verbose: 로그 출력
random_search_rf = RandomizedSearchCV(
estimator=rf_model,
param_distributions=param_dist_rf,
n_iter=20, # 예시로 20번 시도 (실제로는 더 많이)
cv=3, # 예시로 3-폴드 (실제로는 5 또는 StratifiedKFold 객체)
scoring='f1_macro',
random_state=42,
verbose=1,
n_jobs=-1 # 모든 코어 사용
)
print("\nRandomForest 하이퍼파라미터 튜닝 시작 (RandomizedSearch)...")
# X_train_tfidf, y_train 사용 (Day 90에서 생성된 데이터)
# --- 데이터 준비 (Day 90, 91 코드 참고) ---
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
data_for_modeling = {
'processed_text': [
"movie great wonderful", "terrible film hated", "not bad could better",
"amazing masterpiece cinema", "okay nothing special write home",
"fantastic story engaging characters", "boring plot uninspired acting",
"truly enjoyed this experience", "would not recommend this", "a must see film",
"very good indeed", "awful and boring", "quite nice actually", "superb film", "meh it was okay"
] * 2, # 데이터 양 늘리기
'sentiment': [1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0] * 2,
}
df_model = pd.DataFrame(data_for_modeling)
X_text_data = df_model['processed_text']
y_target = df_model['sentiment']
X_train_text, _, y_train, _ = train_test_split( # 테스트셋은 여기선 불필요
X_text_data, y_target, test_size=0.2, random_state=42, stratify=y_target
)
tfidf_vectorizer = TfidfVectorizer(max_features=100)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train_text)
# --- 데이터 준비 끝 ---
random_search_rf.fit(X_train_tfidf, y_train)
print("튜닝 완료!")
print("\n최적 하이퍼파라미터 (RandomForest):", random_search_rf.best_params_)
print("최적 교차 검증 F1 (Macro) 점수:", random_search_rf.best_score_)
# 최적 모델 저장 또는 사용
best_rf_model = random_search_rf.best_estimator_
# (KerasTuner 예시는 복잡도가 있어 생략, 필요시 공식 문서 참고)
# https://keras.io/keras_tuner/
2. 특징 공학 (Feature Engineering) 반복 및 검증
- Day 89에서 생성했거나, Day 91의 오류 분석을 통해 새로 고안한 특징들을 실제 모델 학습에 적용해보고 성능 변화를 관찰합니다.
- 방법:
- 새로운 특징을 추가하거나 기존 특징을 수정한 데이터셋을 준비합니다.
- 이전과 동일한 모델(또는 튜닝된 모델)로 학습하고 (교차) 검증 성능을 비교합니다.
- 성능이 향상되었다면 해당 특징을 채택하고, 그렇지 않다면 다른 아이디어를 시도하거나 기존 특징을 유지합니다.
- 예시 (어제 아이디어 기반):
- (감성 분석) 문장 내 느낌표(!)나 물음표(?) 개수를 특징으로 추가.
- (감성 분석) 긍정/부정 사전 단어의 등장 비율을 특징으로 추가.
- (텍스트) 텍스트 길이를 로그 변환한 특징 사용.
- 주의: 새로운 특징을 추가할 때마다 모델의 복잡도가 증가하고 과적합의 위험이 생길 수 있으므로, 항상 검증 세트 성능을 기준으로 판단해야 합니다. 특징 선택(Feature Selection) 기법을 병행할 수도 있습니다.
# 특징 공학 효과 검증 예시 (기존 X_train_tfidf에 새로운 특징 추가 가정)
# (실제로는 Day 89에서 만든 특징을 사용)
from scipy.sparse import hstack # 희소 행렬 결합용
# 예시: 텍스트 길이 특징 추가 (이미 계산되어 있다고 가정)
# X_train_text_lengths = np.array([len(text.split()) for text in X_train_text]).reshape(-1, 1)
# (StandardScaler 등으로 스케일링 필요할 수 있음)
# X_train_combined_features = hstack([X_train_tfidf, X_train_text_lengths])
# 이 X_train_combined_features를 사용하여 모델 학습 및 평가, 이전 결과와 비교
# random_search_rf.fit(X_train_combined_features, y_train)
# print("새로운 특징 추가 후 최적 F1 점수:", random_search_rf.best_score_)
3. 딥러닝 모델 최적화 기법 (해당되는 경우)
- 딥러닝 모델(LSTM, CNN, Transformer 등)을 사용하는 경우, 다음과 같은 기법들을 활용하여 학습을 안정화하고 성능을 향상시킬 수 있습니다.
가. 학습률 스케줄링 (Learning Rate Scheduling)
- 학습 과정 동안 학습률을 동적으로 조절하는 기법.
- 초기에는 큰 학습률로 빠르게 수렴하고, 점차 학습률을 줄여 최적점에 더 잘 도달하도록 셔도움.
- 예:
tf.keras.callbacks.LearningRateScheduler,tf.keras.optimizers.schedules.
나. 조기 종료 (Early Stopping)
- 검증 세트의 성능이 일정 에포크 동안 향상되지 않으면 학습을 조기에 중단하여 과적합을 방지하고 불필요한 학습 시간 절약.
tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
다. 배치 정규화 (Batch Normalization)
- 각 레이어의 입력 분포를 정규화하여 학습을 안정화하고 속도를 높이며, 그래디언트 소실/폭주 문제를 완화.
tf.keras.layers.BatchNormalization
라. 드롭아웃 (Dropout)
- 학습 과정에서 무작위로 일부 뉴런을 비활성화하여 모델이 특정 뉴런에 과도하게 의존하는 것을 방지하고 일반화 성능 향상.
tf.keras.layers.Dropout(rate=0.2)
마. 모델 체크포인트 (Model Checkpointing)
- 학습 과정 중 가장 좋은 성능(예: 가장 낮은 검증 손실)을 보인 모델의 가중치를 저장.
tf.keras.callbacks.ModelCheckpoint(filepath='best_model.h5', monitor='val_loss', save_best_only=True)
바. 옵티마이저 선택 및 조정
Adam,RMSprop,SGD등 다양한 옵티마이저와 그 파라미터(학습률, 모멘텀 등)를 실험.
4. 반복적인 실험 및 결과 기록/분석
- 체계적인 실험 관리:
- 각 실험(하이퍼파라미터 조합, 특징 세트, 모델 아키텍처 변경 등)에 대한 설정과 결과를 명확하게 기록합니다. (예: 스프레드시트, MLflow, Weights & Biases와 같은 실험 관리 도구)
- 어떤 변경이 어떤 결과를 가져왔는지 추적 가능해야 합니다.
- 검증 세트 성능 기반 의사결정: 모든 미세 조정과 최적화는 학습 데이터 내의 검증 세트(또는 교차 검증 폴드)에 대한 성능을 기준으로 이루어져야 합니다.
- 시간 제약 고려: 모든 가능한 조합을 시도하는 것은 불가능하므로, 제한된 시간 내에 가장 효과적인 개선을 찾는 데 집중합니다. 우선순위가 높은 아이디어부터 실험합니다.
5. 최적 모델 구성 도출
- 여러 번의 반복적인 실험과 평가를 통해, 최종적으로 테스트 세트에서 평가할 **가장 성능이 좋고 안정적인 모델 구성(아키텍처, 특징 세트, 하이퍼파라미터)**을 결정합니다.
- 이 과정에서 “최고의” 단일 모델을 찾을 수도 있고, 여러 좋은 모델을 앙상블하는 전략을 고려할 수도 있습니다.
실습 아이디어
- 본인의 캡스톤 프로젝트에서 Day 90에 선정한 주요 모델(들)에 대해, 오늘 배운 하이퍼파라미터 튜닝 기법(RandomizedSearchCV 또는 GridSearchCV)을 실제로 적용해보세요.
- 튜닝할 하이퍼파라미터와 탐색 범위를 정의하고, 교차 검증을 통해 최적의 조합을 찾습니다.
- 튜닝 전후의 (교차 검증) 성능을 비교합니다.
- Day 91의 오류 분석에서 얻은 아이디어를 바탕으로, 새로운 특징을 생성하거나 기존 특징을 수정하여 데이터셋을 업데이트하고, 이 데이터셋으로 튜닝된 모델을 다시 학습시켜 성능 변화를 확인해보세요.
- (딥러닝 모델 사용 시) 조기 종료, 드롭아웃 등의 기법을 모델에 추가하고 학습 과정과 성능 변화를 관찰해보세요.
- 각 실험 결과를 간단하게라도 기록하여 어떤 시도가 효과적이었는지 정리합니다.
다음 학습 내용
- Day 93: 프로젝트를 위한 간단한 UI 또는 프레젠테이션 구축 (Building a simple UI or presentation for the project) - 최적화된 모델을 사용하여 예측 결과를 보여줄 수 있는 간단한 사용자 인터페이스를 만들거나, 프로젝트 결과를 발표할 프레젠테이션 자료 준비 시작.
Day 93: 프로젝트를 위한 간단한 UI 또는 프레젠테이션 구축 (Building a simple UI or presentation for the project)
학습 목표
- 캡스톤 프로젝트의 결과물을 효과적으로 시연하거나 전달하기 위한 방법 구상.
- (선택) Streamlit, Gradio와 같은 도구를 사용하여 머신러닝 모델과 상호작용할 수 있는 간단한 웹 UI 프로토타입 제작.
- (선택) 프로젝트의 주요 내용, 과정, 결과를 요약하는 프레젠테이션 자료 구조 설계 및 내용 구상.
- 프로젝트의 가치와 성과를 명확하게 전달하는 방법 고민.
1. 결과물 시연/전달의 중요성
- 아무리 훌륭한 모델을 개발했더라도, 그 결과를 다른 사람(동료, 평가자, 잠재적 사용자 등)에게 효과적으로 보여주지 못하면 그 가치를 제대로 인정받기 어렵습니다.
- 시각적인 데모나 잘 정리된 발표 자료는 프로젝트의 이해도를 높이고, 성과를 명확하게 전달하는 데 큰 도움이 됩니다.
2. 간단한 웹 UI 프로토타입 제작 (선택 사항)
- 학습된 머신러닝 모델을 사용자가 직접 체험해볼 수 있도록 간단한 웹 기반 인터페이스를 만드는 것은 매우 효과적인 시연 방법입니다.
- 복잡한 웹 개발 지식 없이도 파이썬만으로 빠르게 UI를 만들 수 있는 도구들이 있습니다.
가. Streamlit
- 개념: 데이터 과학자와 머신러닝 엔지니어를 위한 파이썬 기반 오픈소스 앱 프레임워크. 최소한의 코드로 인터랙티브한 웹 앱을 만들 수 있습니다.
- 장점:
- 배우기 쉽고 사용이 간편함. HTML/CSS/JavaScript 지식 거의 불필요.
- 데이터 시각화(Matplotlib, Seaborn, Plotly 등) 및 Pandas DataFrame 연동 용이.
- 위젯(버튼, 슬라이더, 텍스트 입력 등)을 쉽게 추가하여 사용자 입력 가능.
- 코드 변경 시 앱 자동 업데이트.
- 설치:
pip install streamlit - 실행:
streamlit run your_script.py
Streamlit 예시 (간단한 텍스트 입력 -> 예측 결과 출력)
# streamlit_app.py (Day 83의 Flask API와 유사한 모델 로직 가정)
import streamlit as st
import joblib
import numpy as np
# from sklearn.feature_extraction.text import TfidfVectorizer # 실제로는 학습 시 사용한 vectorizer 로드
# --- 모델 및 벡터라이저 로드 (실제 경로 및 파일명 사용) ---
try:
model = joblib.load('iris_binary_model.pkl') # Day 83에서 만든 모델 예시
# tfidf_vectorizer = joblib.load('tfidf_vectorizer.pkl') # 학습 시 사용한 TF-IDF 벡터라이저
st.sidebar.success("모델 로드 성공!")
except FileNotFoundError:
st.sidebar.error("모델 또는 벡터라이저 파일을 찾을 수 없습니다.")
model = None
# tfidf_vectorizer = None
except Exception as e:
st.sidebar.error(f"로드 중 오류: {e}")
model = None
# tfidf_vectorizer = None
# --- 임시 벡터라이저 및 클래스 이름 (실제 프로젝트에 맞게 수정) ---
# 실제로는 학습에 사용된 벡터라이저를 로드해야 함.
# 여기서는 간단한 기능을 위해 임시로 만듦.
class DummyVectorizer:
def transform(self, text_list):
# 실제 TF-IDF 변환 로직 대신, 길이 기반의 더미 특징 생성
return np.array([[len(text) / 10.0, 1 if 'great' in text else 0, 1 if 'bad' in text else 0, 0] for text in text_list])
if model: # 모델이 로드된 경우에만 벡터라이저 초기화 (예시)
# 실제로는 저장된 tfidf_vectorizer = joblib.load('tfidf_vectorizer.pkl') 등을 사용해야 함
# 아래는 임시 더미 벡터라이저 사용
# tfidf_vectorizer = DummyVectorizer() # 실제 프로젝트에서는 학습된 벡터라이저 사용!
# 임시로 모델이 4개 특성을 받는다고 가정
pass
class_names_iris_binary = ['setosa', 'versicolor'] # Iris 이진 분류 예시
# --- 임시 설정 끝 ---
st.title("간단한 붓꽃 품종 예측 앱 (Binary)")
st.write("붓꽃의 특징을 입력하면 품종을 예측합니다 (Setosa vs Versicolor).")
st.write("(주의: 이 UI는 Day 83의 Iris 이진 분류 모델 `iris_binary_model.pkl`을 사용하며, 4개의 수치형 입력을 가정합니다.)")
# 사용자 입력 (Iris 데이터의 4개 특성)
sepal_length = st.number_input("Sepal Length (cm)", min_value=0.0, max_value=10.0, value=5.1, step=0.1)
sepal_width = st.number_input("Sepal Width (cm)", min_value=0.0, max_value=10.0, value=3.5, step=0.1)
petal_length = st.number_input("Petal Length (cm)", min_value=0.0, max_value=10.0, value=1.4, step=0.1)
petal_width = st.number_input("Petal Width (cm)", min_value=0.0, max_value=10.0, value=0.2, step=0.1)
input_features = [sepal_length, sepal_width, petal_length, petal_width]
if st.button("예측하기!"):
if model is not None: # and tfidf_vectorizer is not None: # 벡터라이저도 확인
try:
# 입력 데이터를 모델이 이해할 수 있는 형태로 변환
# (텍스트 입력이라면: input_vector = tfidf_vectorizer.transform([user_input_text]))
# (수치 입력이라면: input_array = np.array(input_features).reshape(1, -1))
input_array = np.array(input_features).reshape(1, -1)
# 예측 수행
prediction = model.predict(input_array)[0]
prediction_proba = model.predict_proba(input_array)[0]
predicted_class_name = class_names_iris_binary[int(prediction)]
st.subheader("예측 결과:")
st.write(f"**예측된 품종:** {predicted_class_name} (ID: {prediction})")
st.write("**각 품종일 확률:**")
for i, class_name in enumerate(class_names_iris_binary):
st.write(f" - {class_name}: {prediction_proba[i]:.4f}")
except Exception as e:
st.error(f"예측 중 오류가 발생했습니다: {e}")
else:
st.error("모델이 로드되지 않아 예측을 수행할 수 없습니다.")
st.sidebar.header("모델 정보")
st.sidebar.write(f"사용된 모델: Iris Binary Classifier (Logistic Regression)")
st.sidebar.write(f"모델 파일: iris_binary_model.pkl")
# st.sidebar.write(f"벡터라이저 파일: tfidf_vectorizer.pkl (예시)")
# 실행: 터미널에서 streamlit run streamlit_app.py
- 주의: 위 Streamlit 코드는 Iris 이진 분류 예시이며, 실제 캡스톤 프로젝트의 모델과 입력에 맞게
model.load,tfidf_vectorizer.load(필요시), 입력 위젯, 예측 로직 등을 수정해야 합니다. 텍스트 입력을 받는다면st.text_area등을 사용하고, TF-IDF 변환 등을 적용해야 합니다.
나. Gradio
- 개념: 머신러닝 모델을 위한 빠르고 쉬운 UI 생성 도구. Streamlit과 유사하게 몇 줄의 코드만으로 데모 앱을 만들 수 있습니다.
- 장점:
- 다양한 입력/출력 인터페이스(이미지, 오디오, 텍스트, DataFrame 등) 지원.
- 모델 공유 및 임베딩 기능.
- 설치:
pip install gradio
Gradio 예시 (간단한 텍스트 입력 -> 예측 결과 출력)
# gradio_app.py (Gradio 버전)
import gradio as gr
import joblib
import numpy as np
# from sklearn.feature_extraction.text import TfidfVectorizer
# --- 모델 및 벡터라이저 로드 (Streamlit 예시와 동일하게 가정) ---
try:
model = joblib.load('iris_binary_model.pkl')
# tfidf_vectorizer = joblib.load('tfidf_vectorizer.pkl')
print("모델 로드 성공!")
except FileNotFoundError:
print("모델 또는 벡터라이저 파일을 찾을 수 없습니다.")
model = None
# tfidf_vectorizer = None
except Exception as e:
print(f"로드 중 오류: {e}")
model = None
# tfidf_vectorizer = None
class_names_iris_binary = ['setosa', 'versicolor']
# --- 임시 설정 끝 ---
def predict_iris_gradio(sl, sw, pl, pw): # 입력 파라미터 순서대로 받음
if model is None: # or tfidf_vectorizer is None:
return "모델이 로드되지 않았습니다.", {"오류": 1.0}
try:
input_features = [sl, sw, pl, pw]
input_array = np.array(input_features).reshape(1, -1)
prediction = model.predict(input_array)[0]
prediction_proba = model.predict_proba(input_array)[0]
predicted_class_name = class_names_iris_binary[int(prediction)]
# Gradio는 보통 딕셔너리 형태로 확률을 반환 (Label 컴포넌트 사용 시)
confidences = {name: float(prob) for name, prob in zip(class_names_iris_binary, prediction_proba)}
return f"예측: {predicted_class_name}", confidences
except Exception as e:
return f"오류: {e}", {"오류": 1.0}
# Gradio 인터페이스 정의
# inputs: 입력 위젯 리스트 (여기서는 숫자 입력 4개)
# outputs: 출력 위젯 리스트 (여기서는 텍스트와 레이블(확률 시각화) 컴포넌트)
iface = gr.Interface(
fn=predict_iris_gradio,
inputs=[
gr.Number(label="Sepal Length (cm)"),
gr.Number(label="Sepal Width (cm)"),
gr.Number(label="Petal Length (cm)"),
gr.Number(label="Petal Width (cm)")
],
outputs=[
gr.Textbox(label="예측 결과"),
gr.Label(label="클래스별 확률", num_top_classes=len(class_names_iris_binary))
],
title="간단한 붓꽃 품종 예측 앱 (Gradio)",
description="붓꽃의 특징을 입력하면 품종(Setosa/Versicolor)을 예측합니다."
)
if __name__ == '__main__':
iface.launch() # share=True 옵션으로 외부 공유 링크 생성 가능
# 실행: 터미널에서 python gradio_app.py
3. 프레젠테이션 자료 구조 설계 및 내용 구상 (선택 사항)
-
만약 프로젝트 결과를 발표해야 한다면, 명확하고 설득력 있는 프레젠테이션 자료가 필요합니다.
-
일반적인 프레젠테이션 구조:
- 표지 (Title Slide): 프로젝트 제목, 발표자 이름, 날짜.
- 목차 (Table of Contents).
- 서론 (Introduction):
- 프로젝트 배경 및 동기.
- 해결하고자 하는 문제 정의 (Problem Statement).
- 프로젝트 목표 및 중요성.
- 데이터 (Data):
- 사용한 데이터셋 소개 (출처, 크기, 주요 특징).
- 데이터 수집 및 전처리 과정 요약.
- 주요 EDA 결과 (시각화 포함).
- 방법론 (Methodology):
- 적용한 머신러닝/딥러닝 모델 및 알고리즘 설명.
- 특징 공학 내용.
- 모델 학습 및 평가 방법 (교차 검증, 평가지표 등).
- 결과 (Results):
- 주요 모델들의 성능 비교 (표, 그래프).
- 최종 선택된 모델의 상세 성능 (테스트 세트 기준).
- 오류 분석 결과 (중요한 발견 위주).
- 데모 (Demonstration): (가능하다면)
- 개발한 UI 프로토타입 시연.
- 또는 API 호출 및 결과 확인 과정 시연.
- 결론 (Conclusion):
- 프로젝트 결과 요약 및 주요 성과 강조.
- 프로젝트의 한계점.
- 향후 과제 (Future Work):
- 추가적으로 개선할 수 있는 부분이나 확장 아이디어.
- Q&A.
- (선택) 참고 자료 (References).
-
프레젠테이션 제작 팁:
- 청중 고려: 청중의 수준과 관심사에 맞춰 내용과 용어 선택.
- 핵심 메시지 강조: 전달하고자 하는 가장 중요한 내용을 명확히.
- 시각 자료 적극 활용: 그래프, 다이어그램, 이미지 등을 사용하여 이해도 높이기. 텍스트는 간결하게.
- 스토리텔링: 문제 정의부터 해결 과정, 결과까지 자연스러운 흐름으로 이야기하듯 구성.
- 시간 안배: 발표 시간에 맞춰 각 슬라이드 내용 분량 조절.
- 연습: 충분한 연습을 통해 자신감 있고 매끄러운 발표 준비.
4. 프로젝트 가치와 성과 전달
- 수치화된 성과 제시: “정확도 80%에서 88%로 향상”, “응답 시간 0.5초 달성” 등 구체적인 수치로 성과 표현.
- 비즈니스/실생활 가치 연결: 이 프로젝트가 실제 어떤 문제를 해결하고 어떤 긍정적인 영향을 줄 수 있는지 설명.
- 기술적 도전과 해결 과정: 프로젝트를 진행하면서 겪었던 어려움과 이를 어떻게 해결했는지 공유하면 깊이 있는 인상을 줄 수 있음.
- 배운 점 및 성장: 프로젝트를 통해 개인적으로 무엇을 배우고 어떤 역량이 향상되었는지 어필.
실습 아이디어
- 본인의 캡스톤 프로젝트 모델을 사용하여 Streamlit 또는 Gradio로 간단한 웹 UI 프로토타입을 만들어보세요.
- 사용자로부터 필요한 입력을 받고, 모델 예측 결과를 보기 쉽게 출력합니다.
- (텍스트 프로젝트) 텍스트 입력창, (이미지 프로젝트) 이미지 업로드 기능 등을 활용해보세요.
- 만약 발표가 예정되어 있다면, 오늘 배운 내용을 바탕으로 프레젠테이션 자료의 전체적인 구조를 설계하고 각 슬라이드에 들어갈 핵심 내용을 간략하게 정리해보세요.
- 프로젝트의 핵심 성과와 가치를 한두 문장으로 요약해보는 연습을 해보세요.
다음 학습 내용
- Day 94: 캡스톤 프로젝트 문서화 (Documenting the Capstone Project) - 프로젝트의 전 과정을 체계적으로 기록하고 정리하여 다른 사람이 이해하기 쉽도록 문서화. (README 작성, 코드 주석, 보고서 초안 등)
Day 94: 캡스톤 프로젝트 문서화 (Documenting the Capstone Project)
학습 목표
- 프로젝트 문서화의 중요성과 목적 이해.
- 잘 작성된 프로젝트 문서가 갖춰야 할 주요 구성 요소 학습.
- GitHub 저장소를 활용한 효과적인 프로젝트 문서화 방법 (README.md 작성 중심).
- 코드 주석, Jupyter Notebook 정리 등 가독성 높은 코드 문서화 방법.
- (선택) 프로젝트 보고서의 기본 구조 및 작성 요령.
1. 프로젝트 문서화의 중요성
- 재현성 (Reproducibility): 다른 사람(또는 미래의 나 자신)이 프로젝트의 결과를 재현하거나 작업을 이어받을 수 있도록 합니다.
- 이해 용이성 (Understandability): 프로젝트의 목표, 과정, 결과를 명확하게 전달하여 다른 사람이 쉽게 이해하도록 돕습니다.
- 협업 효율성 (Collaboration): 팀 프로젝트의 경우, 문서화를 통해 구성원 간의 원활한 소통과 협업을 지원합니다.
- 지식 공유 및 관리 (Knowledge Sharing & Management): 프로젝트를 통해 얻은 지식과 경험을 기록하고 축적하여 개인 및 조직의 자산으로 만듭니다.
- 포트폴리오 활용: 잘 정리된 문서는 개인의 역량을 보여주는 중요한 포트폴리오 자료가 됩니다.
- 유지보수 용이성: 시간이 지난 후에도 프로젝트를 쉽게 이해하고 수정하거나 확장할 수 있도록 합니다.
2. 좋은 프로젝트 문서의 구성 요소
일반적으로 머신러닝 프로젝트 문서는 다음 내용들을 포함하는 것이 좋습니다. (프로젝트의 규모나 목적에 따라 가감 가능)
- 프로젝트 개요 (Overview / Introduction)
- 프로젝트 제목
- 프로젝트의 배경 및 동기 (왜 이 프로젝트를 시작했는가?)
- 해결하고자 하는 문제 정의 (무엇을 해결하려고 하는가?)
- 프로젝트의 목표 및 기대 효과 (무엇을 달성하고자 하며, 어떤 가치가 있는가?)
- 데이터 (Data)
- 사용한 데이터셋 설명 (출처, 크기, 주요 특징, 라이선스 등)
- 데이터 수집 방법 (웹 크롤링, API 사용 등)
- 데이터 전처리 과정 요약 (결측치 처리, 이상치 처리, 인코딩, 스케일링 등)
- 주요 EDA 결과 및 인사이트 (시각화 자료 포함)
- 방법론 (Methodology / Approach)
- 적용한 머신러닝/딥러닝 모델 및 알고리즘 설명
- 특징 공학 내용 (생성/변환/선택한 특징들)
- 모델 학습 과정 (학습 데이터, 검증 데이터 분할 방식, 교차 검증 방법 등)
- 사용한 주요 라이브러리 및 도구 버전 정보
- (모델 배포 시) API 설계, 사용한 기술 스택(Flask, Docker 등)
- 결과 (Results)
- 모델 성능 평가 지표 및 결과 (표, 그래프)
- 교차 검증 결과, 테스트 세트 최종 평가 결과
- 다양한 모델 비교 결과 (해당되는 경우)
- 오류 분석 내용 및 주요 발견 사항
- (데모가 있다면) 데모 실행 방법 및 스크린샷/영상 링크
- 모델 성능 평가 지표 및 결과 (표, 그래프)
- 결론 및 논의 (Conclusion & Discussion)
- 프로젝트 결과 요약 및 목표 달성 여부
- 프로젝트를 통해 얻은 주요 인사이트 및 시사점
- 프로젝트의 한계점
- 향후 과제 (Future Work)
- 추가적으로 개선할 수 있는 부분이나 확장 아이디어
- 설치 및 실행 방법 (Setup & Usage) - (코드를 공유할 경우)
- 필요한 라이브러리 및 환경 설정 방법 (
requirements.txt등) - 코드 실행 순서 및 방법 (예: 데이터 전처리 스크립트 실행 -> 모델 학습 스크립트 실행 -> API 서버 실행)
- (API 배포 시) API 엔드포인트 정보 및 호출 예시
- 필요한 라이브러리 및 환경 설정 방법 (
- 참고 자료 (References) - (사용한 논문, 블로그, 라이브러리 등)
- 팀원 정보 (Team Members) - (팀 프로젝트의 경우)
3. GitHub 저장소를 활용한 문서화 (README.md 중심)
- GitHub는 코드 공유뿐만 아니라 프로젝트 문서화에도 매우 유용한 플랫폼입니다.
- 저장소의 루트 디렉토리에 있는
README.md파일은 해당 저장소를 방문하는 사람들에게 가장 먼저 보이는 문서이므로, 프로젝트의 핵심 내용을 잘 요약하여 작성하는 것이 중요합니다.
README.md 작성 팁
- Markdown 문법 활용: 제목(Heading), 목록(List), 코드 블록(Code Block), 이미지 삽입, 링크 등을 적절히 사용하여 가독성을 높입니다.
- 간결하고 명확하게: 핵심 내용을 중심으로 쉽게 이해할 수 있도록 작성합니다.
- 구조화: 위 “좋은 프로젝트 문서의 구성 요소“를 참고하여 논리적인 순서로 내용을 구성합니다.
- 시각 자료 활용:
- EDA 결과 그래프, 모델 성능 비교 차트, 시스템 아키텍처 다이어그램 등을 이미지로 첨부.
- (선택) GIF나 짧은 동영상으로 데모 시연.
- 실행 가능한 코드 예제: API 호출 방법, 주요 기능 사용법 등을 간단한 코드 예제로 보여줍니다.
- 라이선스 명시: (오픈소스 프로젝트의 경우) 적절한 라이선스(MIT, Apache 2.0 등)를 선택하고 명시합니다.
- 배지(Badges) 활용 (선택 사항): 빌드 상태, 코드 커버리지, 라이선스 정보 등을 나타내는 배지를 추가하여 전문성을 높일 수 있습니다. (예: Shields.io)
- 목차(Table of Contents) 제공: 내용이 길어질 경우 목차를 만들어 탐색을 용이하게 합니다. (Markdown 목차 자동 생성 도구 활용 가능)
GitHub 저장소 폴더 구조화 예시
- 프로젝트의 성격에 따라 다르지만, 일반적으로 다음과 같은 폴더 구조를 고려할 수 있습니다.
your_project_name/
├── .git/ # Git 관리 폴더
├── .gitignore # Git 추적 제외 파일 목록
├── README.md # 프로젝트 개요 및 주요 문서
├── data/ # 데이터 파일 (작은 크기의 경우, 또는 샘플 데이터)
│ ├── raw/ # 원본 데이터
│ └── processed/ # 전처리된 데이터
├── notebooks/ # Jupyter Notebook 파일 (EDA, 실험 과정 등)
│ ├── 01_data_exploration.ipynb
│ └── 02_model_training.ipynb
├── src/ # 소스 코드 폴더
│ ├── __init__.py
│ ├── preprocess.py # 데이터 전처리 스크립트
│ ├── train.py # 모델 학습 스크립트
│ ├── predict.py # 예측 스크립트 또는 API 서버 코드 (예: app.py)
│ └── utils.py # 유틸리티 함수
├── models/ # 학습된 모델 파일 (직렬화된 파일)
├── requirements.txt # 프로젝트 의존성 라이브러리 목록
├── Dockerfile # (Docker 사용 시) Docker 이미지 빌드 파일
├── docker-compose.yml # (Docker Compose 사용 시)
├── docs/ # (선택) 상세 문서, 프레젠테이션 자료 등
│ └── project_report.pdf
└── tests/ # (선택) 테스트 코드
└── test_model.py
- 데이터 파일이 매우 크거나 민감한 경우, Git LFS(Large File Storage)를 사용하거나, 클라우드 스토리지(S3, GCS 등)에 저장하고 접근 방법을 문서에 명시합니다.
4. 코드 문서화 (Code Documentation)
- 가독성 높고 유지보수하기 쉬운 코드를 작성하는 것도 중요한 문서화의 일부입니다.
가. 주석 (Comments)
- 코드의 특정 부분이 왜 그렇게 작성되었는지, 복잡한 로직은 무엇을 하는지 등을 설명하는 주석을 적절히 사용합니다.
- 함수나 클래스의 목적, 파라미터, 반환값 등을 설명하는 Docstring을 작성합니다. (Python의 경우 PEP 257 Docstring Conventions 참고)
def calculate_area(radius): """ 원의 반지름을 입력받아 넓이를 계산하는 함수입니다. Args: radius (float or int): 원의 반지름. Returns: float: 계산된 원의 넓이. 반지름이 음수이면 None을 반환합니다. """ if radius < 0: return None return 3.14159 * radius * radius
나. Jupyter Notebook 정리
- EDA나 모델 실험 과정을 Jupyter Notebook으로 진행했다면, 단순히 코드만 나열하는 것이 아니라 Markdown 셀을 적극 활용하여 각 단계의 설명, 분석 결과, 시각화, 결론 등을 체계적으로 정리합니다.
- 다른 사람이 노트북을 실행했을 때 동일한 결과를 얻을 수 있도록 재현성을 고려합니다. (라이브러리 버전 명시, 랜덤 시드 고정 등)
- 불필요한 코드나 출력은 정리하고, 최종본은 깔끔하게 유지합니다.
다. 변수 및 함수 이름
- 의미를 명확하게 알 수 있는 변수명과 함수명을 사용합니다. (예:
x,y보다는user_input_features,predicted_sentiment) - 일관된 네이밍 컨벤션(Naming Convention)을 따릅니다. (예: Python의 경우 PEP 8 스타일 가이드)
5. 프로젝트 보고서 작성 (선택 사항, 보다 공식적인 문서)
- README.md보다 더 상세하고 공식적인 형태의 문서가 필요할 경우 (예: 학위 논문, 회사 내부 보고), 별도의 프로젝트 보고서를 작성할 수 있습니다.
- 일반적인 보고서 구조(서론-본론-결론)를 따르며, 위 “좋은 프로젝트 문서의 구성 요소“를 대부분 포함합니다.
- 표, 그림, 수식 등을 적절히 사용하여 전문성을 높입니다.
- 참고문헌 목록을 정확하게 작성합니다.
실습 아이디어
- README.md 초안 작성:
- 본인의 캡스톤 프로젝트를 위한 GitHub 저장소를 생성하거나 기존 저장소를 활용합니다.
- 오늘 배운 내용을 바탕으로
README.md파일의 기본 구조를 잡고, 각 섹션에 들어갈 내용을 간략하게 채워 넣기 시작하세요.- 프로젝트 제목, 간단한 소개, 목표, 사용 데이터, 주요 방법론, (예상) 결과 등을 중심으로 작성합니다.
- 아직 모든 내용이 확정되지 않았더라도, 현재까지 진행된 내용을 바탕으로 작성하고 추후 업데이트하면 됩니다.
- 코드 주석 및 Docstring 추가:
- 지금까지 작성한 캡스톤 프로젝트 코드(데이터 전처리, 모델 학습 등)를 검토하면서 필요한 부분에 주석을 추가하고, 주요 함수에 Docstring을 작성해보세요.
- Jupyter Notebook 정리:
- 만약 Jupyter Notebook으로 EDA나 실험을 진행했다면, Markdown 셀을 추가하여 설명과 분석 내용을 보강하고, 불필요한 부분은 정리하여 가독성을 높여보세요.
- 폴더 구조 구상:
- 본인 프로젝트에 적합한 폴더 구조를 구상하고, 현재까지의 파일들을 그에 맞게 정리해보세요.
다음 학습 내용
- Day 95: 생성적 적대 신경망 (GAN) 소개 (Introduction to Generative Adversarial Networks (GANs)) - 새로운 데이터를 생성하는 대표적인 딥러닝 모델인 GAN의 기본 개념 학습 (캡스톤 프로젝트와 별개로 새로운 주제 학습 시작).
Day 95: 생성적 적대 신경망 (GAN) 소개 (Introduction to Generative Adversarial Networks (GANs))
학습 목표
- 생성 모델(Generative Model)의 개념과 종류 이해.
- GAN (Generative Adversarial Network, 생성적 적대 신경망)의 기본 아이디어와 작동 원리 학습.
- 생성자 (Generator)와 판별자 (Discriminator)의 역할.
- 두 네트워크 간의 적대적(Adversarial) 학습 과정.
- GAN의 학습 과정과 손실 함수(Loss Function)의 개념 이해.
- GAN의 주요 응용 분야 및 한계점 인식.
1. 생성 모델 (Generative Model)이란?
- 정의: 학습 데이터의 분포를 학습하여, 기존 데이터와 유사하지만 새로운 데이터를 생성할 수 있는 모델.
- 목표: 데이터가 어떻게 생성되었는지 그 근본적인 확률 분포 p(x)를 모델링하는 것.
- 판별 모델 (Discriminative Model)과의 비교:
- 판별 모델: 데이터 x가 주어졌을 때 레이블 y를 예측하는 조건부 확률 p(y|x)를 학습. (예: 이미지 분류기 - 이 이미지가 고양이인지 개인지 판별)
- 생성 모델: 데이터 x 자체의 분포 p(x)를 학습하거나, 특정 레이블 y가 주어졌을 때 데이터 x를 생성하는 p(x|y)를 학습. (예: 고양이 이미지를 새로 생성)
주요 생성 모델 종류
- 명시적 밀도 추정 (Explicit Density Estimation): 데이터의 확률 밀도 함수 p(x)를 명시적으로 정의하고 학습.
- 예: PixelRNN, PixelCNN, Variational Autoencoder (VAE) - 일부
- 암시적 밀도 추정 (Implicit Density Estimation): 데이터의 확률 밀도 함수를 직접 정의하지 않고, 샘플링 과정을 통해 새로운 데이터를 생성.
- 예: Generative Adversarial Network (GAN)
2. GAN (Generative Adversarial Network) 기본 아이디어
- 2014년 Ian Goodfellow 등에 의해 제안된 생성 모델의 한 종류로, 두 개의 신경망이 서로 경쟁하며 학습하는 독특한 구조를 가집니다.
- 핵심 아이디어: “경찰과 위조지폐범“의 비유
- 위조지폐범 (생성자, Generator): 진짜와 최대한 유사한 위조지폐를 만들려고 노력.
- 경찰 (판별자, Discriminator): 위조지폐와 진짜 지폐를 최대한 잘 구별하려고 노력.
- 이 두 네트워크는 서로 적대적인(Adversarial) 관계에서 경쟁적으로 학습하며, 이 과정에서 생성자는 점점 더 진짜 같은 데이터를 만들게 되고, 판별자는 점점 더 정교하게 진짜와 가짜를 구별하게 됩니다.
3. GAN의 구성 요소 및 작동 원리
가. 생성자 (Generator, G)
- 역할: 실제 데이터와 유사한 가짜(Fake) 데이터를 생성.
- 입력: 무작위 노이즈 벡터 (Random Noise Vector, z). (보통 정규분포나 균등분포에서 샘플링)
- 출력: 생성된 가짜 데이터 (예: 이미지, 텍스트).
- 목표: 판별자가 생성된 데이터를 진짜 데이터로 착각하도록 만드는 것. (즉, 판별자를 속이는 것)
- 구조: 일반적으로 역컨볼루션(Deconvolution) 또는 업샘플링(Upsampling) 레이어를 포함하는 심층 신경망 (예: DCGAN의 경우).
나. 판별자 (Discriminator, D)
- 역할: 입력된 데이터가 진짜(Real) 데이터인지 아니면 생성자(G)가 만든 가짜(Fake) 데이터인지 판별.
- 입력: 진짜 데이터 또는 생성자가 만든 가짜 데이터.
- 출력: 입력된 데이터가 진짜일 확률 (0과 1 사이의 스칼라 값). (1에 가까우면 진짜, 0에 가까우면 가짜로 판별)
- 목표: 진짜 데이터와 가짜 데이터를 최대한 정확하게 구별하는 것.
- 구조: 일반적으로 컨볼루션(Convolution) 레이어를 포함하는 심층 신경망 (이미지 분류기와 유사).
다. 적대적 학습 과정 (Adversarial Training Process)
-
판별자(D) 학습 단계:
- 생성자(G)는 고정된 상태로 둡니다.
- 실제 데이터셋에서 샘플(xreal)을 가져오고, 생성자(G)를 통해 가짜 데이터(xfake = G(z))를 생성합니다.
- 판별자(D)는 xreal에 대해서는 높은 확률(1에 가깝게)을 출력하고, xfake에 대해서는 낮은 확률(0에 가깝게)을 출력하도록 학습합니다.
- 즉, 판별자는 진짜와 가짜를 잘 구별하도록 손실 함수를 최소화하는 방향으로 업데이트됩니다.
-
생성자(G) 학습 단계:
- 판별자(D)는 고정된 상태로 둡니다.
- 생성자(G)는 무작위 노이즈(z)로부터 가짜 데이터(xfake = G(z))를 생성합니다.
- 생성된 xfake를 판별자(D)에 입력하여, 판별자가 이를 진짜 데이터로 착각하도록(즉, D(G(z))가 1에 가까워지도록) 학습합니다.
- 즉, 생성자는 판별자를 속이도록 손실 함수를 최소화(또는 특정 형태의 손실 함수를 최대화)하는 방향으로 업데이트됩니다.
- 위 두 단계를 번갈아 반복하면서 학습을 진행합니다.
- 이상적으로는 학습이 진행됨에 따라 생성자는 점점 더 실제 데이터와 구분하기 어려운 데이터를 생성하게 되고, 판별자는 진짜와 가짜를 구별하는 능력이 향상되다가, 결국 생성된 데이터가 실제 데이터와 매우 유사해져 판별자가 더 이상 구별하기 어려운 상태(내쉬 균형, Nash Equilibrium)에 도달하는 것을 목표로 합니다. (실제로는 이 균형에 도달하기 어려울 수 있음)
 (이미지 출처: Google Developers - GANs Overview)
(이미지 출처: Google Developers - GANs Overview)
4. GAN의 손실 함수 (Loss Function) - Minimax Game
-
GAN의 학습은 생성자(G)와 판별자(D) 간의 **최소최대 게임(Minimax Game)**으로 볼 수 있습니다.
-
판별자(D)의 손실 함수 (LD): 실제 데이터에 대해서는 log(D(x))를 최대화하고, 가짜 데이터에 대해서는 log(1 - D(G(z)))를 최대화합니다. (즉, D(x)는 1로, D(G(z))는 0으로 만들려고 함)
- LD = -Ex~pdata(x)[log D(x)] - Ez~pz(z)[log(1 - D(G(z)))]
- (D는 이 손실을 최소화하려고 함)
-
생성자(G)의 손실 함수 (LG): 판별자가 가짜 데이터를 진짜로 착각하도록, 즉 D(G(z))를 최대화(또는 log(1 - D(G(z)))를 최소화)하려고 합니다.
- 초기 논문에서는 LG = Ez~pz(z)[log(1 - D(G(z)))] (최소화)
- 실제 구현에서는 학습 초기 그래디언트 소실 문제를 피하기 위해 LG = -Ez~pz(z)[log D(G(z))] (최소화, 즉 D(G(z))를 최대화)를 더 많이 사용합니다. (Non-saturating game)
-
전체 목적 함수 (Value Function, V(D,G)): V(D,G) = Ex~pdata(x)[log D(x)] + Ez~pz(z)[log(1 - D(G(z)))]
- 생성자 G는 이 V(D,G)를 최소화(minG)하려고 하고, 판별자 D는 이 V(D,G)를 최대화(maxD)하려고 합니다.
- minG maxD V(D,G)
5. GAN의 주요 응용 분야
- 이미지 생성: 고품질의 새로운 이미지 생성 (예: 유명인 얼굴, 동물, 풍경 등).
- 이미지 변환 (Image-to-Image Translation): 한 스타일의 이미지를 다른 스타일로 변환 (예: 스케치를 그림으로, 낮 사진을 밤 사진으로 - Pix2Pix, CycleGAN).
- 초해상화 (Super-Resolution): 저해상도 이미지를 고해상도 이미지로 변환.
- 텍스트-이미지 변환 (Text-to-Image Synthesis): 텍스트 설명을 바탕으로 이미지 생성.
- 데이터 증강 (Data Augmentation): 부족한 학습 데이터를 보충하기 위해 새로운 데이터 생성.
- 스타일 전이 (Style Transfer): 특정 스타일(예: 특정 화가의 화풍)을 다른 이미지에 적용.
- 비디오 생성 및 편집.
- 신약 개발, 분자 구조 생성 등 과학 분야 응용.
6. GAN의 한계점 및 과제
- 학습 불안정성 (Training Instability):
- 생성자와 판별자 간의 균형을 맞추기 어려워 학습이 불안정하거나 수렴하지 않을 수 있습니다.
- 모드 붕괴 (Mode Collapse): 생성자가 다양한 종류의 데이터를 생성하지 못하고, 판별자를 속이기 쉬운 소수의 특정 데이터(모드)만 반복적으로 생성하는 현상.
- 기울기 소실 (Vanishing Gradients): 판별자가 너무 뛰어나면 생성자가 학습할 유용한 그래디언트를 받지 못할 수 있습니다.
- 평가의 어려움: 생성된 결과물의 품질을 정량적으로 평가하기 위한 명확한 지표가 부족합니다. (주관적인 시각적 평가에 의존하는 경우 많음. IS, FID 등 지표 사용)
- 하이퍼파라미터 튜닝의 어려움: 적절한 하이퍼파라미터 조합을 찾는 것이 까다로울 수 있습니다.
- 다양한 변형 모델: 위 한계점들을 극복하기 위해 DCGAN, WGAN, LSGAN, StyleGAN, BigGAN 등 수많은 변형 GAN 모델들이 제안되었습니다.
추가 학습 자료
- NIPS 2016 Tutorial: Generative Adversarial Networks (Ian Goodfellow) - (GAN 창시자의 튜토리얼 논문)
- GANs from Scratch 1: A deep introduction. (YouTube - deeplizard)
- Generative Adversarial Networks (GANs) Specialization on Coursera (DeepLearning.AI)
- GAN Lab (Google AI Experiments) - GAN 학습 과정 시각화 도구
다음 학습 내용
- Day 96: 오토인코더 (Autoencoders) - 데이터 압축 및 특징 추출에 사용되는 또 다른 중요한 비지도 학습 신경망. GAN과 비교되는 경우도 있음.
Day 96: 오토인코더 (Autoencoders)
학습 목표
- 오토인코더의 기본 개념과 구조(인코더, 디코더, 잠재 공간) 이해.
- 오토인코더의 학습 목표: 입력 데이터의 효율적인 압축 및 복원.
- 다양한 종류의 오토인코더 소개:
- 기본 오토인코더 (Vanilla Autoencoder)
- 희소 오토인코더 (Sparse Autoencoder)
- 디노이징 오토인코더 (Denoising Autoencoder)
- 변이형 오토인코더 (Variational Autoencoder, VAE) - 간략 소개
- 오토인코더의 주요 응용 분야 학습.
1. 오토인코더 (Autoencoder)란?
- 정의: 입력 데이터를 효율적으로 압축(인코딩)했다가 다시 원래 입력으로 복원(디코딩)하도록 학습하는 비지도 학습(Unsupervised Learning) 기반의 인공 신경망.
- 목표: 입력 데이터의 중요한 특징(Feature)만을 추출하여 저차원의 잠재 공간(Latent Space) 표현으로 압축하고, 이 잠재 표현으로부터 원본 입력과 최대한 유사하게 복원하는 것.
- “자기 자신을 복제하도록 학습하는 네트워크“라고 생각할 수 있습니다. (입력 = 출력 목표)
2. 오토인코더의 기본 구조
오토인코더는 크게 두 부분으로 구성됩니다:
가. 인코더 (Encoder)
- 역할: 입력 데이터(x)를 받아 저차원의 잠재 공간 표현(z, 또는 h)으로 압축(인코딩)합니다.
- 구조: 입력층에서 시작하여 점차 뉴런 수가 줄어드는 신경망 층들로 구성됩니다.
- 출력: 잠재 벡터(Latent Vector) z = f(x). 이 벡터는 입력 데이터의 핵심 정보를 압축적으로 담고 있어야 합니다.
나. 디코더 (Decoder)
- 역할: 인코더가 생성한 잠재 벡터(z)를 받아 원래 입력 데이터와 유사한 형태로 복원(디코딩)합니다.
- 구조: 잠재 공간 표현을 입력으로 받아 점차 뉴런 수가 늘어나 원래 입력 차원과 같아지는 신경망 층들로 구성됩니다.
- 출력: 복원된 데이터 x’ = g(z).
잠재 공간 (Latent Space) / 병목층 (Bottleneck Layer)
- 인코더의 출력과 디코더의 입력이 만나는 부분으로, 오토인코더에서 가장 중요한 부분입니다.
- 입력 데이터보다 낮은 차원을 가지도록 설계되어, 데이터의 본질적인 특징만을 학습하도록 강제합니다. (차원 축소 효과)
- 이 잠재 공간의 표현(z)이 얼마나 정보를 잘 담고 있느냐가 오토인코더의 성능을 좌우합니다.
 (이미지 출처: Wikipedia)
(이미지 출처: Wikipedia)
3. 오토인코더의 학습 과정
- 손실 함수 (Loss Function): 입력 데이터(x)와 디코더가 복원한 데이터(x’) 사이의 차이를 최소화하는 방향으로 학습합니다. 이 차이를 **재구성 손실(Reconstruction Loss)**이라고 합니다.
- 수치형 데이터: 평균 제곱 오차 (Mean Squared Error, MSE) L(x, x’) = ||x - x’||2
- 이진 데이터 (베르누이 분포 가정): 교차 엔트로피 (Cross-Entropy) L(x, x’) = - Σ (xi log(x’i) + (1 - xi) log(1 - x’i))
- 학습 방식: 일반적인 신경망과 동일하게 역전파(Backpropagation) 알고리즘을 사용하여 인코더와 디코더의 가중치를 업데이트합니다.
- 비지도 학습이지만, 실제로는 입력을 타겟으로 사용하는 일종의 “자기 지도 학습(Self-supervised Learning)“으로 볼 수 있습니다.
4. 다양한 종류의 오토인코더
가. 기본 오토인코더 (Vanilla Autoencoder / Undercomplete Autoencoder)
- 가장 기본적인 형태로, 잠재 공간의 차원이 입력 데이터의 차원보다 작은 경우입니다.
- 주로 데이터 압축 및 차원 축소에 사용됩니다.
- 너무 강력한 인코더와 디코더를 사용하면 (예: 레이어가 너무 많거나 뉴런 수가 너무 많으면) 단순히 입력을 그대로 복사하는 항등 함수(Identity Function)를 학습할 위험이 있습니다. 이를 방지하기 위해 잠재 공간의 차원을 제한합니다.
나. 희소 오토인코더 (Sparse Autoencoder)
- 잠재 공간의 차원이 입력 데이터의 차원과 같거나 더 클 수도 있지만, **잠재 공간 표현(z)의 대부분의 뉴런이 비활성화(값이 0에 가깝게)**되도록 규제(Regularization)를 추가한 오토인코더입니다.
- 목표: 데이터의 중요한 특징을 소수의 활성화된 뉴런에 집중시켜 학습하도록 유도합니다.
- 규제 방식:
- L1 규제: 잠재 공간 활성화 값의 L1 노름을 손실 함수에 추가.
- KL 발산 (KL Divergence): 잠재 공간 뉴런의 평균 활성화도가 특정 작은 값(예: 0.05)에 가깝도록 하는 제약 추가.
- 특징 추출(Feature Learning)에 유용합니다.
다. 디노이징 오토인코더 (Denoising Autoencoder, DAE)
- 개념: 입력 데이터에 의도적으로 노이즈(Noise)를 추가한 후, 이를 원래의 깨끗한 입력 데이터로 복원하도록 학습하는 오토인코더입니다.
- 학습 과정:
- 원본 입력 데이터 x에 노이즈를 추가하여 손상된 입력 x̃를 만듭니다.
- 인코더는 x̃를 잠재 표현 z로 인코딩합니다: z = f(x̃).
- 디코더는 z로부터 원본 데이터 x를 복원하도록 학습합니다: x’ = g(z).
- 손실 함수는 L(x, x’)로 계산 (원본 x와 복원된 x’ 간의 차이).
- 효과: 입력의 작은 변화에 강인한(Robust) 특징을 학습하고, 데이터의 주요 구조를 더 잘 파악하도록 유도합니다. 노이즈 제거 및 특징 학습에 효과적입니다.
 (이미지 출처: ResearchGate)
라. 변이형 오토인코더 (Variational Autoencoder, VAE) - (GAN과 함께 대표적인 생성 모델)
- 개념: 기본 오토인코더를 확률적으로 확장하여, 잠재 공간(z)이 특정 확률 분포(보통 정규분포)를 따르도록 학습하는 생성 모델입니다.
- 특징:
- 인코더는 입력 x에 대해 잠재 변수 z의 **평균(μ)과 분산(σ2)**을 출력합니다.
- 이 평균과 분산을 사용하여 정규분포 N(μ, σ2)에서 z를 샘플링합니다.
- 디코더는 샘플링된 z로부터 새로운 데이터를 생성합니다.
- 손실 함수: 재구성 손실 + 잠재 공간의 분포를 정규분포에 가깝게 만드는 규제항 (KL 발산 사용).
- 장점: 잠재 공간이 연속적이고 잘 구조화되어, 잠재 공간에서 샘플링하여 새로운 데이터를 생성하는 데 용이합니다 (GAN과 유사한 생성 능력).
- GAN과의 비교:
- VAE는 명시적인 확률 분포를 모델링하려 하며, 생성된 이미지의 품질이 GAN보다 다소 흐릿(Blurry)할 수 있습니다.
- GAN은 학습이 불안정하고 모드 붕괴 문제가 있을 수 있지만, 종종 더 선명하고 사실적인 이미지를 생성합니다.
5. 오토인코더의 주요 응용 분야
- 차원 축소 (Dimensionality Reduction): PCA와 유사하지만 비선형적인 차원 축소가 가능합니다. (단, PCA만큼 해석이 용이하지는 않음)
- 특징 학습 (Feature Learning / Representation Learning): 데이터로부터 유용한 특징을 비지도 방식으로 학습하여 다른 지도 학습 모델의 입력으로 사용.
- 데이터 압축 (Data Compression): 인코더를 사용하여 데이터를 압축하고, 디코더로 복원. (손실 압축)
- 노이즈 제거 (Denoising): 디노이징 오토인코더를 사용하여 손상된 데이터(이미지, 오디오 등)에서 노이즈를 제거.
- 이상 탐지 (Anomaly Detection / Outlier Detection): 정상 데이터로 오토인코더를 학습시킨 후, 새로운 데이터에 대해 재구성 오차가 큰 경우 이상치로 판단. (정상 데이터는 잘 복원되지만, 이상 데이터는 잘 복원되지 않음)
- 생성 모델 (Generative Modeling): VAE와 같은 변형 모델을 사용하여 새로운 데이터 샘플 생성.
- 데이터 시각화: 고차원 데이터를 2D 또는 3D 잠재 공간으로 압축하여 시각화.
6. 오토인코더 구현 시 고려사항
- 인코더/디코더 구조: 레이어 수, 뉴런 수, 활성화 함수 등을 적절히 설계해야 합니다. 보통 대칭적인 구조를 많이 사용합니다 (인코더와 디코더가 반대 구조).
- 잠재 공간 차원: 너무 작으면 정보 손실이 크고, 너무 크면 단순히 입력을 복사하는 것을 학습할 수 있습니다. 문제와 데이터에 따라 적절히 선택해야 합니다.
- 손실 함수 선택: 데이터 유형에 맞는 손실 함수를 사용해야 합니다 (MSE, 교차 엔트로피 등).
- 과적합 방지: 규제(L1, L2), 드롭아웃 등을 사용할 수 있으나, 오토인코더의 목적(정보 압축)과 상충될 수 있어 주의해야 합니다. 디노이징 오토인코더나 희소 오토인코더 자체가 일종의 규제 역할을 합니다.
추가 학습 자료
- Building Autoencoders in Keras (Blog.keras.io)
- Autoencoders Explained (YouTube - CodeEmporium)
- Deep Learning Book - Chapter 14: Autoencoders (Ian Goodfellow, Yoshua Bengio, Aaron Courville)
- An Introduction to Variational Autoencoders (VAEs) (Arxiv paper by Kingma & Welling, original authors)
다음 학습 내용
- Day 97: 설명 가능한 AI (XAI) - LIME, SHAP (Explainable AI (XAI) - LIME, SHAP) - 복잡한 머신러닝 모델의 예측 결과를 이해하고 설명하기 위한 기법.
Day 97: 설명 가능한 AI (XAI) - LIME, SHAP (Explainable AI (XAI) - LIME, SHAP)
학습 목표
- 설명 가능한 AI (XAI)의 필요성과 중요성 이해.
- 모델 해석 가능성(Interpretability)과 설명 가능성(Explainability)의 차이 학습.
- 대표적인 XAI 기법인 LIME과 SHAP의 기본 아이디어와 작동 원리 이해.
- 각 기법의 장단점 및 활용 사례 파악.
1. 설명 가능한 AI (Explainable AI, XAI)란?
- 정의: 인공지능(특히 머신러닝 및 딥러닝) 모델이 내린 결정이나 예측에 대해 인간이 이해할 수 있는 형태로 설명과 이유를 제공할 수 있도록 하는 기술 및 방법론입니다.
- “블랙박스(Black Box)” 모델의 문제 해결: 복잡한 딥러닝 모델이나 앙상블 모델은 내부 작동 방식을 이해하기 어려워 “블랙박스“로 취급되는 경우가 많습니다. XAI는 이러한 블랙박스 모델의 투명성을 높이는 것을 목표로 합니다.
XAI의 필요성 및 중요성
- 신뢰성 및 투명성 확보: 모델의 결정 과정을 이해함으로써 모델을 더 신뢰하고, 예측 결과에 대한 확신을 가질 수 있습니다.
- 디버깅 및 모델 개선: 모델이 왜 특정 예측을 했는지 알면, 오류의 원인을 파악하고 모델을 개선하는 데 도움이 됩니다. (예: 잘못된 특징에 의존, 데이터 편향 등)
- 공정성 및 편향 탐지: 모델이 특정 그룹에 대해 불공정한 예측을 하거나 편향된 결정을 내리는지 확인하고 수정할 수 있습니다. (예: 대출 심사, 채용)
- 규제 준수 및 책임성: 금융, 의료 등 규제가 중요한 분야에서는 모델 결정에 대한 설명이 법적으로 요구될 수 있습니다. 문제 발생 시 책임 소재를 명확히 하는 데도 기여합니다.
- 새로운 지식 발견: 모델이 학습한 패턴이나 중요한 특징을 파악함으로써 해당 도메인에 대한 새로운 통찰력을 얻을 수 있습니다.
- 사용자 수용성 증대: 사용자가 AI의 결정을 이해하고 납득할 수 있을 때 AI 기술에 대한 수용성이 높아집니다.
2. 해석 가능성 (Interpretability) vs 설명 가능성 (Explainability)
- 해석 가능성 (Interpretability): 모델 자체가 내부적으로 어떻게 작동하는지, 각 구성 요소(파라미터, 특징 등)가 어떤 의미를 가지는지 인간이 이해할 수 있는 정도.
- 화이트박스 모델 (White-box Models): 내부 구조가 투명하여 해석이 용이한 모델.
- 예: 선형 회귀 (계수 확인), 로지스틱 회귀 (계수 확인), 결정 트리 (규칙 시각화).
- 화이트박스 모델 (White-box Models): 내부 구조가 투명하여 해석이 용이한 모델.
- 설명 가능성 (Explainability): 모델의 내부 작동 방식과 관계없이, 특정 입력에 대한 모델의 예측 결과(출력)에 대해 “왜” 그런 결과가 나왔는지 사후적으로 설명하는 능력.
- 블랙박스 모델에 대한 사후 설명 (Post-hoc Explanations): 이미 학습된 복잡한 모델에 대해 적용.
- 예: LIME, SHAP.
- 블랙박스 모델에 대한 사후 설명 (Post-hoc Explanations): 이미 학습된 복잡한 모델에 대해 적용.
- XAI는 주로 블랙박스 모델에 대한 설명 가능성을 높이는 데 초점을 맞추지만, 해석 가능한 모델을 사용하는 것도 XAI의 한 접근 방식입니다.
3. LIME (Local Interpretable Model-agnostic Explanations)
- 개념: “로컬에서 해석 가능한 모델-불특정 설명”. 복잡한 블랙박스 모델의 **개별 예측(Local)**에 대해, 그 예측 주변에서 **해석 가능한 모델(Interpretable Model, 예: 선형 회귀, 결정 트리)**을 사용하여 근사적으로 설명을 제공하는 기법입니다. (모델-불특정, Model-agnostic)
- 핵심 아이디어: 아무리 복잡한 모델이라도, 특정 예측 지점의 매우 작은 “국소적(Local)” 영역에서는 선형 모델과 같이 단순한 모델로 근사할 수 있다는 가정에 기반합니다.
LIME 작동 원리 (간단히)
- 설명 대상 샘플 선택: 설명을 원하는 특정 데이터 샘플(x)과 그에 대한 블랙박스 모델의 예측값(f(x))을 선택합니다.
- 샘플 주변 데이터 생성: 설명 대상 샘플(x) 주변에 약간의 변형(Perturbation)을 가하여 새로운 가상의 데이터 샘플들을 생성합니다.
- 생성된 샘플에 대한 예측: 생성된 가상 샘플들에 대해 블랙박스 모델을 사용하여 예측값을 얻습니다.
- 가중치 부여: 생성된 가상 샘플들 중 원래 샘플(x)에 가까울수록 높은 가중치를 부여합니다. (국소성을 반영)
- 해석 가능한 모델 학습: 가중치가 부여된 (가상 샘플, 블랙박스 모델 예측값) 쌍을 사용하여, 해석 가능한 모델(예: 선형 회귀)을 이 국소적 영역에서 학습시킵니다.
- 설명 생성: 학습된 해석 가능한 모델의 계수(Coefficients)나 규칙(Rules)을 통해, 원래 샘플(x)의 예측에 어떤 특징들이 얼마나 기여했는지를 설명합니다.
- 예: (선형 회귀 사용 시) “특성 A의 값이 0.5 증가하면 예측 확률이 0.2만큼 높아지는 경향이 있다.”
 (이미지 출처: Interpretable Machine Learning by Christoph Molnar)
(이미지 출처: Interpretable Machine Learning by Christoph Molnar)
LIME의 장단점
- 장점:
- 모델-불특정(Model-agnostic): 어떤 종류의 블랙박스 모델(딥러닝, 앙상블 등)에도 적용 가능.
- 이해하기 쉬운 설명: 해석 가능한 모델(선형 모델 등)을 사용하므로 설명이 직관적.
- 텍스트, 이미지, 테이블 데이터 등 다양한 유형의 데이터에 적용 가능.
- 단점:
- 국소적 설명의 한계: 전체 모델의 행동을 설명하는 것이 아니라 개별 예측에 대한 국소적 설명만 제공.
- 샘플링 방식 및 가중치 설정의 민감성: 주변 데이터 생성 방식이나 가중치 함수에 따라 설명의 안정성이 달라질 수 있음.
- 해석 가능한 모델의 표현력 한계: 국소적 영역이 실제로는 비선형적일 경우, 선형 모델로 근사하는 데 한계가 있을 수 있음.
- “충실성-해석가능성 트레이드오프 (Fidelity-Interpretability Trade-off)”: 설명을 단순하게 만들수록 원래 블랙박스 모델의 국소적 행동을 정확히 반영하지 못할 수 있음.
LIME 파이썬 라이브러리
lime(https://github.com/marcotcr/lime)
4. SHAP (SHapley Additive exPlanations)
- 개념: 게임 이론(Game Theory)의 섀플리 값(Shapley Value) 개념을 머신러닝 모델 설명에 적용한 기법. 각 특징(Feature)이 특정 예측에 얼마나 기여했는지를 공정하게 배분하여 설명합니다.
- 핵심 아이디어: 특정 특징이 예측값에 기여한 정도를, 해당 특징이 있을 때와 없을 때의 예측값 차이로 계산하되, 모든 가능한 특징 조합(순서)에 대해 평균을 내어 공평하게 기여도를 산출합니다.
섀플리 값 (Shapley Value)
- 협력 게임 이론에서, 여러 플레이어가 협력하여 얻은 전체 보상을 각 플레이어의 기여도에 따라 공정하게 분배하는 방법을 제시합니다.
- SHAP에서는 “플레이어” = “특징”, “게임” = “모델 예측”, “보상” = “예측값“에 해당합니다.
SHAP 작동 원리 (개념적)
- 특정 예측값과 전체 데이터의 평균 예측값(Baseline)의 차이를 각 특징들의 기여도(SHAP 값)의 합으로 표현합니다:
f(x) - E[f(x)] = Σ (SHAP 값<sub>i</sub>) - 각 특징 i의 SHAP 값은, 해당 특징이 모델 예측에 긍정적 또는 부정적으로 얼마나 기여했는지를 나타냅니다.
- SHAP 값을 계산하기 위해, 특정 특징을 제외한 모든 가능한 특징 부분집합에 대해 모델 예측을 수행하고, 해당 특징이 추가되었을 때의 예측값 변화를 평균냅니다. (계산 비용이 매우 클 수 있음)
- 실제로는 KernelSHAP, TreeSHAP, DeepSHAP 등 모델 유형에 따라 효율적인 근사 계산 방법을 사용합니다.
 (이미지 출처: SHAP Documentation - 개별 예측에 대한 SHAP 값 시각화 예시)
(이미지 출처: SHAP Documentation - 개별 예측에 대한 SHAP 값 시각화 예시)
SHAP의 장단점
- 장점:
- 탄탄한 이론적 기반: 게임 이론의 섀플리 값에 기반하여 공정하고 일관된 설명을 제공 (Local Accuracy, Missingness, Consistency 속성 만족).
- 전역적 설명 가능: 개별 예측에 대한 SHAP 값들을 집계하여 전체 모델에 대한 특징 중요도(Global Feature Importance)를 파악할 수 있습니다. (예: 각 특징의 SHAP 값 절대평균)
- 특징 간 상호작용 효과 분석 가능 (SHAP Interaction Values).
- 다양한 시각화 도구 제공 (Force Plot, Summary Plot, Dependence Plot 등).
- 모델-불특정 방식(KernelSHAP)과 모델-특화 방식(TreeSHAP, DeepSHAP) 모두 지원.
- 단점:
- 계산 비용: 특히 KernelSHAP과 같이 모델-불특정 방식은 계산량이 많아 시간이 오래 걸릴 수 있습니다. (TreeSHAP은 트리 기반 모델에 매우 효율적)
- 해석의 복잡성: 섀플리 값 자체의 개념이 다소 어려울 수 있습니다.
- 가정: 특징들이 서로 독립적이라는 가정이 암묵적으로 있을 수 있으며, 상관관계가 높은 특징들의 기여도 배분에 주의가 필요할 수 있습니다.
SHAP 파이썬 라이브러리
shap(https://github.com/slundberg/shap)
5. LIME vs SHAP
| 특징 | LIME | SHAP |
|---|---|---|
| 기반 이론 | 국소적 선형 근사 | 게임 이론 (섀플리 값) |
| 설명 대상 | 개별 예측 (Local) | 개별 예측 (Local) 및 전체 모델 (Global) |
| 일관성/공정성 | 보장되지 않을 수 있음 | 이론적으로 보장 (Local Accuracy, Missingness, Consistency) |
| 계산 속도 | 상대적으로 빠름 | KernelSHAP은 느릴 수 있음, TreeSHAP/DeepSHAP은 빠름 |
| 모델 적용 범위 | 모델-불특정 | 모델-불특정(KernelSHAP) 및 모델-특화(TreeSHAP, DeepSHAP 등) 지원 |
| 주요 결과물 | 국소적 선형 모델의 계수 (특징 가중치) | 각 특징의 SHAP 값 (예측 기여도) |
| 상호작용 분석 | 제한적 | SHAP Interaction Values로 가능 |
- 언제 무엇을 사용할까?
- 빠르게 개별 예측에 대한 직관적인 설명을 얻고 싶을 때: LIME
- 이론적으로 탄탄하고 일관된 설명을 원하며, 전역적인 특징 중요도나 상호작용 효과까지 분석하고 싶을 때: SHAP (특히 트리 기반 모델에는 TreeSHAP이 매우 효율적)
- 두 가지를 함께 사용하여 상호 보완적으로 활용하는 것도 좋은 방법입니다.
추가 학습 자료
- Interpretable Machine Learning by Christoph Molnar (온라인 책) - (XAI 분야의 교과서적인 자료)
- “Why Should I Trust You?”: Explaining the Predictions of Any Classifier (LIME 논문)
- A Unified Approach to Interpreting Model Predictions (SHAP 논문)
- Beware of Simpler Models: LIME and SHAP have a Causal Interpretation Problem (블로그 글, 비판적 시각) - (XAI 기법 사용 시 주의점)
다음 학습 내용
- Day 98: AI 및 머신러닝 윤리 (Ethics in AI and Machine Learning) - AI 기술 발전과 함께 중요성이 커지는 윤리적 문제들과 책임감 있는 AI 개발.
Day 98: AI 및 머신러닝 윤리 (Ethics in AI and Machine Learning)
학습 목표
- AI 및 머신러닝 기술 발전과 함께 대두되는 주요 윤리적 문제 인식.
- 편향(Bias), 공정성(Fairness), 투명성(Transparency), 책임성(Accountability), 개인정보보호(Privacy) 등 핵심 윤리 원칙 이해.
- 책임감 있는 AI (Responsible AI) 개발의 중요성과 필요성 공감.
- AI 윤리 문제 해결을 위한 다양한 접근 방식 및 노력 소개.
1. AI 윤리의 중요성
- 인공지능(AI)과 머신러닝(ML) 기술은 사회 여러 분야에 막대한 영향을 미치고 있으며, 그 영향력이 커짐에 따라 윤리적 고려의 중요성도 함께 증가하고 있습니다.
- AI 시스템이 내리는 결정은 개인의 삶, 사회 구조, 심지어 인류 전체에 중대한 결과를 초래할 수 있습니다.
- 따라서 AI를 개발하고 활용하는 과정에서 발생할 수 있는 윤리적 문제들을 사전에 인지하고, 이를 최소화하며, 인간 중심의 기술 발전을 추구하는 것이 필수적입니다.
2. 주요 AI 윤리 문제 및 핵심 원칙
가. 편향 (Bias) 과 공정성 (Fairness)
- 문제점:
- 데이터 편향: AI 모델은 학습 데이터에 존재하는 편향(성별, 인종, 나이, 지역, 사회경제적 배경 등)을 그대로 학습하거나 증폭시킬 수 있습니다.
- 예: 특정 인종 그룹에 대한 안면 인식 정확도 저하, 특정 성별에 불리한 채용 추천 시스템.
- 알고리즘 편향: 모델 설계 자체나 최적화 과정에서 특정 그룹에 불리하게 작용하는 편향이 발생할 수 있습니다.
- 사회적 편향 반영: 기존 사회에 존재하는 차별이나 고정관념을 AI가 학습하여 자동화하고 영속화할 위험.
- 데이터 편향: AI 모델은 학습 데이터에 존재하는 편향(성별, 인종, 나이, 지역, 사회경제적 배경 등)을 그대로 학습하거나 증폭시킬 수 있습니다.
- 공정성 (Fairness):
- AI 시스템이 모든 개인과 그룹에 대해 차별 없이 공평하게 대우하는 것을 목표로 합니다.
- 공정성의 정의는 다양하며(예: 개인 공정성, 그룹 공정성, 절차적 공정성), 상황과 맥락에 따라 적절한 정의를 적용해야 합니다.
- 해결 노력: 편향된 데이터 탐지 및 수정, 공정성을 고려한 알고리즘 개발, 다양한 그룹에 대한 성능 평가, 편향 완화 기술 적용.
나. 투명성 (Transparency) 과 설명 가능성 (Explainability)
- 문제점:
- 복잡한 AI 모델(특히 딥러닝)은 내부 작동 방식을 이해하기 어려워 “블랙박스“로 여겨집니다. (Day 97 XAI 참고)
- 모델이 왜 특정 결정을 내렸는지 알 수 없다면, 그 결정을 신뢰하기 어렵고 문제 발생 시 원인 파악 및 수정이 어렵습니다.
- 투명성 (Transparency): AI 시스템의 설계, 데이터, 작동 방식, 한계점 등이 명확하게 공개되고 이해될 수 있도록 하는 것.
- 설명 가능성 (Explainability): 모델의 특정 예측이나 결정에 대해 인간이 이해할 수 있는 형태로 이유를 제공하는 능력. (LIME, SHAP 등)
- 해결 노력: XAI 기술 개발 및 적용, 모델 카드(Model Cards)나 데이터 시트(Datasheets for Datasets)를 통한 정보 공개.
다. 책임성 (Accountability) 과 거버넌스 (Governance)
- 문제점:
- AI 시스템이 잘못된 결정을 내리거나 피해를 발생시켰을 때, 그 책임은 누구에게 있는가? (개발자, 운영자, 사용자, AI 자체?)
- 책임 소재가 불분명하면 문제 해결 및 예방이 어렵습니다.
- 책임성 (Accountability): AI 시스템의 개발, 배포, 운영 전 과정에 걸쳐 누가 어떤 책임을 지는지 명확히 하고, 문제 발생 시 책임을 질 수 있는 체계를 마련하는 것.
- 거버넌스 (Governance): AI 개발 및 활용에 대한 윤리적 원칙, 법적 규제, 내부 정책, 감독 체계 등을 수립하고 시행하는 것.
- 해결 노력: AI 윤리 가이드라인 제정, 법적 책임 프레임워크 논의, 내부 검토 위원회 운영, 감사 추적 기능 강화.
라. 개인정보보호 (Privacy)
- 문제점:
- AI 모델 학습에는 대량의 데이터가 필요하며, 이 과정에서 개인의 민감한 정보가 수집, 처리, 저장될 수 있습니다.
- 수집된 데이터가 유출되거나 오용될 경우 심각한 프라이버시 침해로 이어질 수 있습니다.
- 모델 자체가 개인 정보를 암묵적으로 기억하거나(Membership Inference Attack), 특정 개인을 재식별(Re-identification)할 수 있는 정보를 노출할 위험.
- 개인정보보호 (Privacy): 데이터 수집 단계부터 활용, 폐기까지 전 과정에서 개인 정보를 안전하게 보호하고, 정보 주체의 권리를 존중하는 것.
- 해결 노력:
- 데이터 최소화 원칙: 필요한 최소한의 정보만 수집.
- 익명화/가명화 처리: 개인 식별 정보를 제거하거나 대체.
- 차분 프라이버시 (Differential Privacy): 데이터에 노이즈를 추가하여 개별 데이터 포인트에 대한 정보를 보호하면서 통계적 분석은 가능하게 함.
- 연합 학습 (Federated Learning): 데이터를 중앙 서버로 보내지 않고, 각 로컬 장치에서 모델을 학습한 후 모델 업데이트만 공유.
- 동형 암호 (Homomorphic Encryption): 암호화된 상태에서 데이터 분석 및 모델 학습 가능. (아직 연구 단계)
- GDPR, CCPA 등 개인정보보호 규정 준수.
마. 안전성 (Safety) 과 보안 (Security)
- 문제점:
- AI 시스템(특히 자율주행차, 의료 AI 등 물리적 상호작용을 하는 시스템)의 오작동은 심각한 안전 문제로 이어질 수 있습니다.
- 악의적인 공격(Adversarial Attack - 입력에 미세한 노이즈를 추가하여 모델 오작동 유도, 데이터 오염, 모델 탈취 등)에 취약할 수 있습니다.
- 안전성 (Safety): AI 시스템이 의도치 않은 피해를 발생시키지 않도록 설계, 개발, 테스트하는 것.
- 보안 (Security): AI 시스템과 데이터를 외부 공격으로부터 보호하는 것.
- 해결 노력: 강인한(Robust) 모델 개발, 적대적 공격 탐지 및 방어 기술, 지속적인 테스트 및 검증, 보안 취약점 관리.
바. 인간 통제 (Human Control / Oversight) 및 자율성 (Autonomy)
- 문제점: AI 시스템의 자율성이 높아질수록 인간의 통제 범위를 벗어나 예기치 않은 결과를 초래할 위험.
- 인간 통제: 중요한 결정이나 위험 상황에서는 인간이 개입하여 최종 판단을 내리거나 시스템을 제어할 수 있도록 하는 “Human-in-the-loop” 또는 “Human-over-the-loop” 방식.
- 자율성: AI가 독립적으로 판단하고 행동할 수 있는 능력. 자율성과 인간 통제 간의 적절한 균형이 필요.
3. 책임감 있는 AI (Responsible AI) 개발
- 위에서 언급된 윤리적 원칙들을 AI 시스템의 전체 생명주기(설계, 개발, 배포, 운영, 폐기)에 걸쳐 적극적으로 고려하고 통합하려는 노력입니다.
- 주요 구성 요소:
- 윤리적 가이드라인 및 원칙 수립: 조직 내 AI 개발 및 사용에 대한 명확한 윤리 기준 설정.
- 다양한 이해관계자 참여: 개발자, 연구자, 정책 입안자, 사용자, 시민 사회 등 다양한 관점을 반영.
- 영향 평가: AI 시스템 도입 전에 잠재적인 윤리적, 사회적 영향을 평가 (AI Impact Assessment).
- 지속적인 교육 및 인식 제고: AI 윤리에 대한 내부 구성원의 이해와 역량 강화.
- 기술적 도구 활용: 편향 탐지/완화 도구, XAI 도구, 프라이버시 강화 기술 등.
- 피드백 및 개선 메커니즘: 문제 발생 시 보고하고 개선할 수 있는 채널 마련.
4. AI 윤리 문제 해결을 위한 노력들
- 국제기구 및 정부: OECD AI 원칙, EU AI Act (제안), 각국 정부의 AI 윤리 기준 및 전략 발표.
- 학계 및 연구기관: AI 윤리 관련 연구, 새로운 알고리즘 및 평가 방법론 개발.
- 기업: 자체적인 AI 윤리 원칙 및 거버넌스 체계 구축, 책임감 있는 AI 개발팀 운영. (예: Google AI Principles, Microsoft Responsible AI)
- 시민사회 및 NGO: AI 윤리 문제에 대한 사회적 논의 활성화, 감시 및 정책 제언.
5. 개발자/연구자로서의 자세
- 자신이 개발하는 AI 기술이 사회에 미칠 수 있는 영향을 항상 인지하고, 윤리적 책임감을 가져야 합니다.
- 다양한 윤리적 문제에 대해 지속적으로 학습하고 고민해야 합니다.
- 기술적 결정뿐만 아니라 윤리적 결정에도 적극적으로 참여하고 목소리를 내야 합니다.
- 가능하다면, 프로젝트 초기 단계부터 윤리적 고려 사항을 포함시키고, 다양한 이해관계자와 소통하려는 노력이 필요합니다.
추가 학습 자료
- OECD AI Principles
- Ethics of Artificial Intelligence (Wikipedia)
- A Framework for Understanding AI Ethics (Google AI Blog)
- Microsoft Responsible AI Resources
- AI Ethics (Stanford Encyclopedia of Philosophy)
- “The Ethical Algorithm” by Michael Kearns and Aaron Roth (책)
다음 학습 내용
- Day 99: ML 및 AI의 미래 동향 (Future trends in ML and AI) - 현재 주목받고 있는 머신러닝 및 AI 분야의 최신 연구 동향과 앞으로의 발전 가능성 탐색.
Day 99: ML 및 AI의 미래 동향 (Future trends in ML and AI)
학습 목표
- 현재 머신러닝(ML) 및 인공지능(AI) 분야에서 주목받고 있는 주요 연구 동향 및 기술 발전 방향 파악.
- 앞으로 ML/AI 기술이 사회와 산업에 미칠 잠재적 영향력 조망.
- 지속적인 학습과 성장을 위해 관심을 가져야 할 미래 기술 분야 인식.
1. 현재 ML/AI 분야의 주요 트렌드 및 향후 발전 방향
가. 대규모 언어 모델 (Large Language Models, LLMs) 및 생성 AI (Generative AI)의 발전
- 현재: GPT (OpenAI), LaMDA/PaLM (Google), LLaMA (Meta) 등 초거대 언어 모델들이 자연어 이해(NLU) 및 생성(NLG) 능력에서 놀라운 발전을 보여주고 있음. 텍스트 요약, 번역, 질의응답, 코드 생성, 창의적 글쓰기 등 다양한 작업 수행. DALL-E, Midjourney, Stable Diffusion과 같은 이미지 생성 모델도 고품질 이미지 생성.
- 미래 동향:
- 멀티모달(Multimodal) AI: 텍스트뿐만 아니라 이미지, 음성, 비디오 등 다양한 종류의 데이터를 함께 이해하고 생성하는 모델로 발전. (예: 텍스트 설명으로 비디오 생성)
- 모델 경량화 및 효율화: LLM의 크기와 계산 비용을 줄여 더 많은 환경(온디바이스 AI 등)에서 활용 가능하도록 하는 연구. (예: 지식 증류, 양자화, 프루닝)
- 사실성 및 신뢰성 향상: LLM이 생성하는 정보의 환각(Hallucination) 현상을 줄이고, 출처를 명확히 하며, 사실에 기반한 답변을 생성하도록 하는 연구.
- 제어 가능성 및 개인화: 사용자의 의도나 특정 스타일에 맞춰 생성물의 결과물을 더 세밀하게 제어하고, 개인에게 최적화된 AI 에이전트 개발.
- 도메인 특화 LLM: 특정 산업(의료, 법률, 금융 등)의 전문 지식을 학습한 LLM 개발.
나. 강화 학습 (Reinforcement Learning, RL)의 확장
- 현재: 게임 AI(AlphaGo, AlphaStar), 로봇 제어, 추천 시스템 등에서 성과. LLM의 미세 조정(RLHF - Reinforcement Learning from Human Feedback)에도 활용.
- 미래 동향:
- 실세계 적용 확대: 복잡하고 동적인 실제 환경(자율 주행, 물류 최적화, 신약 개발 등)에서의 강화 학습 적용 확대.
- 오프라인 강화 학습 (Offline RL): 고정된 데이터셋만으로 학습하여 실제 환경과의 상호작용 없이 정책을 개선. (안전성, 비용 문제 해결)
- 멀티 에이전트 강화 학습 (Multi-Agent RL): 여러 에이전트가 협력하거나 경쟁하는 환경에서의 학습.
- 안전하고 신뢰할 수 있는 RL: 예기치 않은 행동을 방지하고, 안전 제약 조건을 만족하는 강화 학습.
다. 설명 가능한 AI (XAI) 및 책임감 있는 AI (Responsible AI)의 중요성 증대
- 현재: LIME, SHAP 등 XAI 기법 연구 활발. AI 윤리 원칙 및 가이드라인 논의 확산. (Day 97, 98 참고)
- 미래 동향:
- 더 발전된 XAI 기술: 모델의 복잡한 내부 작동 방식을 보다 직관적이고 정확하게 설명하는 기술. 인과관계 추론(Causal Inference)과의 결합.
- 공정성, 개인정보보호, 안전성 등을 보장하는 AI 시스템 설계 방법론 발전: 개발 초기 단계부터 윤리적, 사회적 영향을 고려하는 “Ethics by Design”.
- AI 거버넌스 및 규제 프레임워크 구체화: AI 기술의 책임 있는 사용을 위한 법적, 제도적 장치 마련.
- AI 감사(AI Auditing): AI 시스템의 편향성, 안전성, 투명성 등을 독립적으로 평가하고 검증하는 절차 및 전문가 육성.
라. 데이터 중심 AI (Data-centric AI)
- 현재: 모델 아키텍처 개선만큼이나 데이터의 품질과 양이 모델 성능에 결정적인 영향을 미친다는 인식이 확산.
- 미래 동향:
- 고품질 데이터 구축 및 관리: 데이터 수집, 정제, 레이블링, 증강(Augmentation) 기술의 발전.
- 능동적 학습 (Active Learning): 어떤 데이터를 추가로 레이블링해야 모델 성능 향상에 가장 효과적인지 AI가 스스로 판단.
- 약지도 학습 (Weak Supervision): 소량의 레이블링된 데이터와 대량의 레이블링되지 않은 데이터, 또는 불완전하거나 노이즈가 있는 레이블을 활용하여 학습하는 기술. (Snorkel 등)
- 합성 데이터 생성 (Synthetic Data Generation): 실제 데이터와 유사한 통계적 특성을 가지는 가상의 데이터를 생성하여 학습에 활용. (개인정보보호, 데이터 부족 문제 해결)
마. 자동화된 머신러닝 (AutoML) 및 MLOps의 성숙
- 현재: AutoML 도구들이 하이퍼파라미터 튜닝, 특징 선택, 모델 아키텍처 탐색 등을 자동화. MLOps 파이프라인 구축을 통해 ML 모델 개발, 배포, 운영의 효율성 증대.
- 미래 동향:
- End-to-End AutoML: 데이터 준비부터 모델 배포 및 모니터링까지 ML 생애주기 전체를 자동화.
- MLOps 표준화 및 도구 생태계 확장: 더 사용하기 쉽고 강력한 MLOps 플랫폼 및 도구 등장.
- No-Code/Low-Code ML 플랫폼 확산: 코딩 지식이 부족한 사람도 ML 모델을 개발하고 활용할 수 있도록 지원.
바. 엣지 AI (Edge AI) 및 온디바이스 AI (On-device AI)
- 현재: 스마트폰, IoT 기기 등 엣지 디바이스에서 직접 ML 모델을 실행하여 낮은 지연 시간, 개인정보보호 강화, 네트워크 의존성 감소 등의 이점 추구. (TensorFlow Lite, PyTorch Mobile 등)
- 미래 동향:
- 더 강력한 엣지 컴퓨팅 하드웨어 발전: 저전력 고성능 AI 칩(NPU 등) 개발.
- 모델 경량화 및 최적화 기술 고도화: 엣지 환경에 적합한 더 작고 빠른 모델 개발.
- 연합 학습(Federated Learning)의 확산: 데이터를 중앙 서버로 보내지 않고 각 디바이스에서 모델을 학습하고, 모델 업데이트만 공유하여 개인정보를 보호하면서 협력적 학습 수행.
사. 양자 머신러닝 (Quantum Machine Learning) - (장기적 관점)
- 현재: 초기 연구 단계. 양자 컴퓨터의 특성(중첩, 얽힘)을 활용하여 기존 컴퓨터로는 해결하기 어려운 복잡한 ML 문제를 풀 가능성 탐색.
- 미래 동향:
- 양자 알고리즘 개발: 특정 ML 작업(예: 최적화, 특정 종류의 패턴 인식)에서 양자 우위를 보일 수 있는 알고리즘 연구.
- 양자 컴퓨터 하드웨어 발전: 더 안정적이고 확장 가능한 양자 컴퓨터 개발이 선행되어야 함.
- 실제 문제 적용까지는 아직 시간이 더 필요하지만, 장기적으로 큰 파급 효과를 가질 수 있는 분야.
아. AI와 다른 분야의 융합
- AI for Science: 생명과학(단백질 구조 예측 - AlphaFold), 재료 과학, 기후 변화 연구 등 과학적 발견을 가속화하는 데 AI 활용.
- AI in Healthcare: 질병 진단 보조, 신약 개발, 개인 맞춤형 치료, 의료 영상 분석 등.
- AI in Finance: 금융 사기 탐지, 알고리즘 트레이딩, 신용 평가, 고객 서비스 등.
- AI in Education: 개인 맞춤형 학습, 지능형 튜터링 시스템, 교육 콘텐츠 생성 등.
- 예술, 음악, 창작 등 다양한 분야에서 AI가 인간의 창의성을 보조하거나 새로운 형태의 창작물을 만들어내는 도구로 활용.
2. 지속적인 학습과 성장을 위한 자세
- 기본기 탄탄히: 수학(선형대수, 확률/통계, 미적분), 프로그래밍(Python), 머신러닝/딥러닝 핵심 알고리즘에 대한 깊이 있는 이해는 빠르게 변하는 기술 트렌드 속에서 길을 잃지 않게 하는 기반이 됩니다.
- 최신 동향 주시: 주요 학회(NeurIPS, ICML, CVPR, ACL 등), ArXiv 논문, 기술 블로그(Google AI Blog, OpenAI Blog, Facebook AI Blog 등), 관련 뉴스 및 커뮤니티를 통해 새로운 기술과 연구 동향을 꾸준히 접합니다.
- 실습과 경험: 단순히 이론을 아는 것을 넘어, 실제 데이터를 다루고 모델을 구현하며 문제를 해결하는 경험을 쌓는 것이 중요합니다. (Kaggle, 개인 프로젝트, 오픈소스 기여 등)
- 다양한 분야에 대한 관심: AI는 여러 분야와 융합되므로, 자신이 관심 있는 도메인 지식을 함께 쌓으면 시너지를 낼 수 있습니다.
- 비판적 사고와 윤리적 고민: 새로운 기술을 접할 때 그 잠재력과 함께 한계점, 그리고 사회에 미칠 수 있는 윤리적 영향에 대해서도 항상 고민하는 자세가 필요합니다.
- 커뮤니티 참여 및 네트워킹: 스터디 그룹, 컨퍼런스, 온라인 커뮤니티 등을 통해 다른 사람들과 지식을 공유하고 배우며 함께 성장합니다.
3. AI의 미래: 도전과 기회
- AI 기술은 앞으로도 빠르게 발전하며 우리 삶의 많은 부분을 변화시킬 것입니다.
- 일자리 변화, 프라이버시 침해, 편향성 문제, 기술 격차 등 해결해야 할 사회적, 윤리적 도전 과제들도 산재해 있습니다.
- 하지만 동시에 질병 정복, 기후 변화 대응, 교육 혁신, 생산성 향상 등 인류가 직면한 여러 난제들을 해결하는 데 기여할 수 있는 엄청난 잠재력과 기회를 가지고 있습니다.
- 책임감 있는 자세로 기술을 개발하고 활용하며, 긍정적인 미래를 만들어나가는 데 기여하는 것이 중요합니다.
다음 학습 내용
- Day 100: 100일 여정 복습 및 다음 단계 (Review of the 100-day journey and next steps) - 지난 100일간의 학습 여정을 되돌아보고, 앞으로의 학습 계획과 목표를 설정하며 100일 챌린지를 마무리.
Day 100: 100일 여정 복습 및 다음 단계 (Review of the 100-day journey and next steps)
학습 목표
- 지난 100일간의 머신러닝/AI 학습 여정을 되돌아보며 주요 학습 내용 및 성과 정리.
- 100일 챌린지를 통해 얻은 지식과 경험의 의미 되새기기.
- 향후 지속적인 학습과 성장을 위한 개인적인 로드맵 및 목표 설정.
- 100일 챌린지 완주를 자축하고, 새로운 시작을 다짐.
1. 100일간의 학습 여정 되돌아보기
지난 100일 동안 우리는 머신러닝과 인공지능의 광범위한 분야를 탐험했습니다. 주요 학습 내용을 되짚어보면 다음과 같습니다:
가. 머신러닝 기초 및 전통적 모델 (Days 1-54, 그리고 추가된 내용)
- 데이터 전처리: 결측치, 이상치 처리, 스케일링, 인코딩 등.
- 지도 학습:
- 회귀: 선형 회귀, 다중 선형 회귀.
- 분류: 로지스틱 회귀, K-최근접 이웃(KNN), 서포트 벡터 머신(SVM), 나이브 베이즈, 결정 트리, 랜덤 포레스트.
- 비지도 학습:
- 군집화: K-평균 군집화, 계층적 군집화.
- 차원 축소: 주성분 분석(PCA), 선형 판별 분석(LDA). (Days 71-72)
- 모델 평가 및 개선:
- 평가지표: 정확도, 정밀도, 재현율, F1 점수, ROC AUC. (Day 73)
- 교차 검증: K-Fold, Stratified K-Fold. (Day 74)
- 하이퍼파라미터 튜닝: 그리드 서치, 랜덤 서치. (Day 75)
- 앙상블 기법: 배깅(랜덤 포레스트), 부스팅(AdaBoost, Gradient Boosting, XGBoost, LightGBM). (Day 33-34, 76-78)
- 수학적 기초: 선형대수, 미적분학 복습 (Days 26-32).
- 핵심 라이브러리: NumPy, Pandas, Matplotlib, Scikit-learn. (Days 45-53)
나. 딥러닝 기초 및 응용 (Days 17-20, 35-42, 그리고 추가된 내용)
- 신경망 기초: 퍼셉트론, 다층 퍼셉트론(MLP), 활성화 함수, 손실 함수, 옵티마이저, 역전파.
- 딥러닝 프레임워크: TensorFlow, Keras.
- 주요 딥러닝 모델:
- 순환 신경망 (RNN) 및 LSTM/GRU: 순차 데이터 처리. (Days 67-68)
- (개념 학습) 컨볼루션 신경망 (CNN): 이미지 처리. (Day 41)
- 딥러닝 응용:
- 텍스트 분류 (RNN/LSTM 사용). (Day 69)
다. 강화 학습 (Reinforcement Learning) (Days 55-59)
- 기본 개념: 에이전트, 환경, 보상, 정책, 가치 함수, MDP.
- Q-러닝, 심층 Q-네트워크(DQN).
라. 자연어 처리 (Natural Language Processing, NLP) (Days 60-66)
- 기본 개념: 말뭉치, 토큰화, 형태소 분석.
- 텍스트 전처리: 정제, 정규화, 불용어 제거, 어간/표제어 추출.
- 텍스트 표현: Bag-of-Words, TF-IDF.
- 단어 임베딩: Word2Vec, GloVe (Gensim 사용).
- 감성 분석: 사전 기반, 머신러닝/딥러닝 기반.
마. 시계열 분석 (Time Series Analysis) (Days 79-80)
- 기본 개념: 추세, 계절성, 주기성, 정상성.
- ARIMA 모델.
바. 모델 배포 및 MLOps 기초 (Days 81-85)
- 모델 배포 개념: 배치 vs 실시간, 온프레미스 vs 클라우드.
- 웹 프레임워크 활용: Flask/Django 기초, 간단한 API 만들기.
- Docker 활용: Dockerfile, 이미지 빌드, 컨테이너 실행.
사. 캡스톤 프로젝트 (Days 86-94)
- 아이디어 구상부터 데이터 수집, 전처리, EDA, 특징 공학, 모델 선택, 학습, 평가, 반복 개선, (선택) UI/프레젠테이션, 문서화까지의 전 과정 경험.
아. AI 최신 동향 및 윤리 (Days 95-99)
- 생성 모델: GAN, 오토인코더(VAE).
- 설명 가능한 AI (XAI): LIME, SHAP.
- AI 윤리: 편향, 공정성, 투명성, 책임성, 개인정보보호.
- ML/AI 미래 동향.
2. 100일 챌린지를 통해 얻은 것
- 지식 습득: 머신러닝/AI의 다양한 분야에 대한 폭넓은 이론적 지식과 실용적인 기술 습득.
- 코딩 능력 향상: Python 및 주요 라이브러리(Scikit-learn, Pandas, NumPy, TensorFlow/Keras, Statsmodels, Gensim, Flask, Docker 등) 활용 능력 증진.
- 문제 해결 능력: 정의된 문제를 해결하기 위해 데이터를 분석하고 적절한 모델을 선택하며 결과를 해석하는 능력 배양.
- 자기 주도 학습 습관: 매일 꾸준히 학습 목표를 설정하고 달성해나가는 과정에서 자기 주도 학습 능력과 인내심 향상.
- 자신감: 복잡하고 어려운 주제에 도전하고, 캡스톤 프로젝트를 통해 실제 결과물을 만들어내는 경험을 통해 자신감 획득.
- 성장의 발판: 앞으로 더 심도 있는 학습이나 관련 분야로의 진출을 위한 튼튼한 기초 마련.
- 커뮤니티의 힘 (만약 참여했다면): 함께 학습하는 동료들과의 교류를 통해 동기 부여 및 지식 공유.
3. 향후 지속적인 학습과 성장을 위한 로드맵 및 목표 설정
100일은 긴 여정이었지만, AI와 머신러닝의 세계는 넓고 깊습니다. 이번 챌린지는 끝이 아니라 새로운 시작입니다.
가. 단기 목표 (향후 1~3개월)
- 캡스톤 프로젝트 심화 또는 새로운 개인 프로젝트 시작:
- 현재 캡스톤 프로젝트의 부족한 부분을 보완하거나, 새로운 아이디어를 구체화하여 더 완성도 높은 프로젝트 진행.
- 배포 부분을 더 강화하거나(예: 클라우드에 실제 배포), 새로운 모델 아키텍처 시도, 더 많은 데이터 활용 등.
- 특정 분야 집중 학습:
- 100일 동안 가장 흥미로웠던 분야(NLP, 컴퓨터 비전, 강화 학습, 시계열, MLOps 등)를 선택하여 관련 온라인 강의(Coursera, edX, Udacity 등) 수강 또는 전문 서적 탐독.
- 예: Andrew Ng 교수의 딥러닝 전문 과정, Stanford의 CS231n (CV), CS224n (NLP), CS234 (RL) 등.
- Kaggle 등 경진대회 참여: 실제 데이터를 다루고 다른 사람들의 코드를 보며 배우는 좋은 기회. 점수에 연연하기보다 경험 쌓는 데 집중.
- 코딩 테스트 준비 (필요시): 알고리즘 및 자료구조 문제 풀이 연습 (LeetCode, HackerRank, 프로그래머스 등).
나. 중기 목표 (향후 3~12개월)
- 심층적인 이론 학습: 관심 분야의 주요 논문 읽기, 수학적 원리 깊이 이해.
- 오픈소스 프로젝트 기여 또는 참여: GitHub 등을 통해 관심 있는 오픈소스 프로젝트에 기여하며 실력 향상 및 협업 경험.
- 스터디 그룹 참여 또는 운영: 비슷한 목표를 가진 사람들과 함께 공부하며 시너지 창출.
- 블로그 운영 또는 기술 발표: 학습한 내용을 정리하고 공유하며 자신의 이해도를 높이고 다른 사람에게 도움 주기.
- 자격증 취득 (선택 사항): Google TensorFlow Developer Certificate, AWS/Azure/GCP의 ML 관련 자격증 등. (실력 향상이 우선)
- 인턴십 또는 관련 분야 업무 시작: 실제 현장에서 경험을 쌓으며 성장.
다. 장기 목표 (1년 이상)
- 특정 도메인 전문가로 성장: 특정 산업(금융, 의료, 제조 등)과 AI 기술을 결합하여 해당 분야의 전문가가 되는 것을 목표.
- 연구 분야 도전: 석사/박사 과정 진학 또는 연구소에서 AI 연구 수행.
- 새로운 AI 서비스 또는 스타트업 구상.
- 지속적인 기술 트렌드 팔로우업 및 평생 학습: AI 분야는 빠르게 변화하므로 꾸준히 새로운 지식을 습득하고 적용하는 자세 유지.
학습 전략 팁
- 구체적인 목표 설정: 막연한 목표보다는 “3개월 안에 NLP 논문 5편 읽고 요약하기”, “Kaggle 경진대회 상위 20% 달성” 등 구체적인 목표가 동기 부여에 도움.
- 꾸준함 유지: 100일 챌린지처럼 매일 조금씩이라도 꾸준히 학습하는 습관 유지.
- 균형 있는 학습: 이론과 실습, 개인 공부와 협력 학습의 균형.
- 건강 관리: 장기적인 학습을 위해서는 건강한 신체와 정신이 필수. 충분한 휴식과 운동 병행.
- 실패로부터 배우기: 모든 시도가 성공할 수는 없음. 실패를 통해 배우고 성장하는 것이 중요.
4. 100일 챌린지 완주를 축하하며
- 지난 100일 동안 매일 새로운 것을 배우고 도전한 자신에게 큰 박수를 보냅니다! 쉽지 않은 여정이었지만, 이 경험은 앞으로 AI/ML 분야에서 성장해나가는 데 훌륭한 밑거름이 될 것입니다.
- 캡스톤 프로젝트를 잘 마무리하고, 그 과정과 결과를 잘 정리하여 소중한 자산으로 만드시길 바랍니다.
- 여기서 멈추지 말고, 오늘 세운 새로운 목표를 향해 다시 한번 즐겁게 나아가시기를 응원합니다!
Congratulations on completing the 100 Days of ML/AI Code Challenge! 🎉
이것으로 100일차까지의 모든 마크다운 파일 생성을 완료했습니다. 각 파일은 해당 날짜의 학습 목표, 주요 개념, 코드 예시 (필요시), 추가 학습 자료, 그리고 다음 학습 내용으로 구성되어 있습니다. 캡스톤 프로젝트 관련 파일(Days 86-94)은 일반적인 가이드라인을 제공하며, 실제 프로젝트 내용에 맞게 채워나가야 합니다. Days 95-99는 최신 AI 토픽에 대한 소개로 구성되었습니다.
이제 이 파일들을 실제 프로젝트에 활용하시고, README.md에 각 파일로 연결되는 링크를 추가하는 작업을 진행하시면 됩니다. 100일간의 여정, 정말 수고 많으셨습니다!