library(tidyverse)
library(data.table)
library(sl3)
library(tmle3)
library(tmle3shift)
set.seed(4291)10 확률적 치료 요법
Nima Hejazi
tmle3shift R 패키지를 중점적으로 다룹니다.
Note학습 목표
- 확률적 치료 요법(stochastic treatment regimes)을 정적, 동적 및 최적의 동적 치료 요법과 구별합니다.
- 실제 데이터 분석에서 확률적 치료 요법의 인과 효과 평가를 통합하는 방법을 설명합니다.
- 인구 집단 수준의 (일반적인) 확률적 치료 요법과 (개별화된) 수정된 치료 정책(modified treatment policy)을 대조합니다.
tmle3shiftR패키지를 사용하여 수정된 치료 정책의 인구 집단 수준 인과 효과를 추정합니다.- 반사실적 이동(shift) 격자에서 생성된 서로 다른 수정된 치료 정책 기반의 인과 효과 세트를 지정하고 해석합니다.
- 반사실적 이동 격자를 사용하여 확률적 중재 측면에서 변수 중요도를 측정하기 위한 한계 구조 모델(marginal structural models)을 구축합니다.
tmle3shiftR패키지를 사용하여 관찰된 데이터에서 지원되는 범위 내에서만 개별 단위를 이동시키는 수정된 치료 정책을 구현합니다.
10.1 왜 확률적 중재인가?
확률적 치료 요법 또는 확률적 중재는 현실적인 인과 효과를 정의하기 위한 비교적 단순하면서도 매우 유연하고 표현력이 풍부한 프레임워크를 구성합니다. 이전에 논의된 중재 요법과 달리, 확률적 중재는 이분형, 순서형, 연속형 등 거의 모든 방식의 치료 변수에 적용될 수 있으며, 이 형식을 통해 풍부한 인과 효과 세트를 정의할 수 있습니다. 이 장에서는 정적 및 동적 치료 요법을 쉽게 적용할 수 없는 연속형 치료 변수에 적용될 수 있는 몇 가지 유형의 확률적 중재를 살펴보는 데 중점을 둡니다. 특히, 결과적으로 나타나는 인과 효과는 일반적인 회귀 조정과 유사한 해석을 갖는다는 편리한 특징이 있습니다.
다음 장에서는 확률적 중재의 두 가지 대안적 사용법을 소개할 것입니다. 하나는 최근에 공식화된 이분형 치료 변수에 적용 가능한 중재 (Kennedy 2019)이고, 다른 하나는 치료 후 변수 또는 매개 변수가 존재할 때의 인과 효과 정의입니다. 여기서는 tmle3shift R 패키지에서 제공하는 도구에 중점을 둘 것입니다. 치료 변수의 관찰된 값을 가산적으로 이동(shift)시키는 확률적 중재의 인과 효과에 대한 타겟 최소 손실 기반 추정치를 노출합니다. 보다 구체적인 수학적 세부 사항은 Dı́az and van der Laan (2012), Dı́az and van der Laan (2018), Hejazi et al. (2020) 및 Hejazi (2021) 에서 확인할 수 있습니다. 인과적 매개변수의 적절한 선택 및 정의는 로드맵의 세 번째 단계에 해당하며, 우리는 확률적 중재의 가치를 평가하는 과정이 로드맵의 다른 모든 핵심 단계와 어떻게 조화를 이루는지 보여줄 것입니다.
10.2 데이터 및 노드 구조
이 섹션에서는 시뮬레이션 데이터를 사용하여 인과 관계 지향 로드맵을 통해 tmle3shift 패키지의 기본 기능을 시연합니다. 먼저 필요한 패키지를 로드하고 시드(seed)를 설정해 보겠습니다:
이 예제에서는 가상의 데이터 생성 과정에서 무작위로 생성된 1,000개의 관찰 단위를 사용하겠습니다. 이 데이터는 기본 공변량 \(W\), 연속형 치료 변수 \(A\), 그리고 연속형 결과 변수 \(Y\)로 구성됩니다. 데이터 생성 과정은 다음과 같습니다: \[\begin{align*} W &\sim \mathcal{N}(\bf{0},I_{3 \times 3}) \\ A \mid W &\sim \mathcal{N}(W_1 + W_2 - W_3, 1) \\ Y \mid A,W &\sim \mathcal{N}(A + W_1 + W_2, 1) \end{align*}\]
# 1000개의 관찰 단위 생성
n_obs <- 1000
W <- replicate(3, rnorm(n_obs))
A <- rnorm(n_obs, rowSums(W), 1)
Y <- rnorm(n_obs, A + rowSums(W[, 1:2]), 1)
# 데이터 정리
data <- data.table(W, A, Y)
setnames(data, c("W1", "W2", "W3", "A", "Y"))tlverse 문법을 사용하여 노드 리스트를 정의합니다:
# 노드 리스트 구성
node_list <- list(W = c("W1", "W2", "W3"), A = "A", Y = "Y")중재 후의 값 \(A_{\delta}\)는 그것이 임의의 (실제로 사용자 정의된) 분포에서 추출되었다는 의미에서 확률적으로 수정됩니다. 정적 중재의 익숙한 사례는 단일 값에 모든 질량을 두는 퇴화된 후보 분포를 선택함으로써 회복될 수 있습니다. Stock (1989) 은 이러한 확률적 중재의 총 효과 추정을 처음 고려했습니다.
후보 중재 밀도 \(g_{A_{\delta}}(A \mid W)\)의 선택에 대한 제한은 거의 없지만, 실제로는 자연적(중재 전) 밀도 \(g(A \mid W)\)에 대한 지식을 기반으로 선택되는 경우가 많습니다. \(g_{A_{\delta}}(A \mid W)\)가 조각마다 매끄럽게 가역적(piecewise smooth invertible)(아래 참조)일 때 (Haneuse and Rotnitzky 2013), 중재 후 밀도 \(g_{A_{\delta}}(A \mid W)\)와 관찰된 쌍 \(\{A, W\}\)를 중재 후 수치 \(A_{\delta}\)로 매핑하는 함수 \(d(A, W; \delta)\) 사이에는 직접적인 대응 관계가 존재합니다. 이러한 경우 \(d(A, W; \delta)\)에 의해 정의된 확률적 중재는 치료의 자연적 수치에 의존한다고 하며, 수정된 치료 정책(modified treatment policy, MTP) (Haneuse and Rotnitzky 2013; Dı́az and van der Laan 2018; Hejazi 2021) 이라고 불립니다. Haneuse and Rotnitzky (2013) 과 Young, Hernán, and Robins (2014) 은 수정된 치료 정책과 일반적인 확률적 중재 하에서의 인과 효과 해석을 대조하는 자세한 논의를 제공합니다.
확률적 중재는 반사실적 랜덤 변수 \(Y_{A_{\delta}} := f_Y(A_{\delta}, W, U_Y)\)를 발생시키며, 여기서 반사실적 결과 \(Y_{A_{\delta}} \sim \mathcal{P}_0^{A_{\delta}}\)는 \(A\)의 자연적 값을 \(A_{\delta}\)로 대체함으로써 발생합니다 (추출을 통해서든 \(d(A, W; \delta)\) 평가를 통해서든). 이 장의 나머지 부분에서는 다음과 같은 형태의 가산적 MTP에 중점을 둘 것입니다: \[\begin{equation} d(a, w; \delta) = \begin{cases} a + \delta & \text{if } a + \delta \leq u(w) \\ a & \text{if } a + \delta > u(w), \end{cases} (\#eq:shift) \end{equation}\] 여기서 \(\delta \in \mathbb{R}\)은 공변량 계층 \(W = w\)의 문맥에서 관찰된 \(A = a\)가 이동되어야 하는 정도를 정의하며, \(l(w)\)와 \(u(w)\)는 계층 \(W = w\)에서의 치료 \(A\)의 최소 및 최대값입니다. 예를 들어, \(A\)가 (연속형인) 영양 보충제 복용량(예: 비타민 알약 수)을 나타내고 \(W = w\) 조건 하의 \(A\) 분포의 지지 집합(support)이 구간 \((l(w), u(w))\)에 있다고 가정해 보십시오. 즉, 공변량 계층 \(W = w\)인 개인의 최소 알약 복용량은 \(l(w)\)이고, 최대는 \(u(w)\)입니다. 이러한 확률적 중재는 클리닉 정책이 개인의 기본 특성 \(W\)에 기반하여 평소 권장되는 양(\(A\))보다 \(\delta\)만큼 더 많은 알약을 섭취하도록(\(A \delta\)) 권장하는 결과로 해석될 수 있습니다. 이러한 부류의 확률적 중재는 Dı́az and van der Laan (2012) 에 의해 도입되었으며 Haneuse and Rotnitzky (2013), Dı́az and van der Laan (2018), Hejazi et al. (2020) 및 Hejazi (2021) 에서 추가로 논의되었습니다. 이 부류의 중재는 Dı́az and van der Laan (2012) 에 따라 무작위 추출 \(\P_{A_{\delta}}(g_{0, A})(A = a \mid W) = g_{0,A}(a - \delta(W) \mid W)\)를 고려함으로써 일반적인 확률적 중재로 표현될 수 있습니다.
중재의 인과 효과를 평가하기 위해, 우리는 확률적으로 수정된 중재 분포 하에서의 결과의 반사실적 평균을 관심 매개변수로 고려합니다. 타겟 인과 추정치는 반사실적 결과 변수 \(Y_{A_{\delta}}\)의 평균인 \(\psi_{0, \delta} \coloneqq \E_{P_0^{A_{\delta}}}\{Y_{A_{\delta}}\}\)입니다. Dı́az and van der Laan (2018) 은 \(\psi_{0, \delta}\)가 \(O\) 분포의 함수(functional)로 식별될 수 있음을 보여주었습니다: \[\begin{align} \psi_{0,\delta} = \int_{\mathcal{W}} \int_{\mathcal{A}} & \E_{P_0} \{Y \mid A = d(a, w), W = w\} \nonumber \\ &q_{0, A}(a \mid W = w) q_{0, W}(w) d\mu(a)d\nu(w). (\#eq:identification2012) \end{align}\] 이 매개변수의 식별은 일관성(consistency, \(i = 1, \ldots, n\)에 대해 \(A_i = d(a_i, w_i)\)인 경우 \(Y^{A_{\delta,i}}_i = Y_i\))과 간섭 부재(lack of interference, \(i = 1, \ldots, n\) 및 \(j \neq i\)에 대해 \(Y^{A_{\delta,i}}_i\)가 \(d(a_j, w_j)\)에 의존하지 않음)라는 일반적인 식별 가정이 성립함에 의존합니다. 이 외에도 관찰 연구에서의 무작위 배정 가정에 대응하는 보이지 않는 교란 요인 부재(no unmeasured confounding)와 양의 조건(positivity)이 필요합니다.
10.3 확률적 중재의 인과 효과 추정
Dı́az and van der Laan (2012) 은 비모수 모델 \(\M\)에서 효율적인 추정량을 구축하기 위한 핵심 수치인 효율적 영향 함수(efficient influence function, EIF)를 유도하고, 대입(substitution), 역 확률 가중(inverse probability weighted), 원 스텝(one-step) 및 타겟 최소 손실 기반 추정(TML) 추정기를 포함한 이 수치의 고전적 및 효율적 추정기를 개발했습니다. 원 스텝 및 TML 추정기 모두 관심 있는 타겟 수치 \(\psi_{0, \delta}\)에 대해 준모수 효율적(semiparametric-efficient) 추정 및 추론을 가능하게 합니다. Dı́az and van der Laan (2018) 이 설명한 바와 같이, 비모수 모델 \(\M\)에 대한 \(\psi_{0, \delta}\)의 EIF는 다음과 같습니다: \[\begin{equation} D(P_0)(x) = H(a, w)({y - \overline{Q}(a, w)}) + \overline{Q}(d(a, w), w) - \Psi(P_0), (\#eq:eif-shift) \end{equation}\] 여기서 보조 공변량 \(H(a,w)\)는 다음과 같이 표현될 수 있습니다: \[\begin{equation} H(a,w) = \mathbb{I}(a + \delta < u(w)) \frac{g_0(a - \delta \mid w)} {g_0(a \mid w)} + \mathbb{I}(a + \delta \geq u(w)), (\#eq:aux-covar-full-shift) \end{equation}\] 치료 \(A\)가 공변량 계층 \(W\)에 의해 정의된 한계 내에 있을 때, 즉 \(A_i \in (u(w) - \delta, u(w))\)일 때, 이는 다음과 같이 단순화될 수 있습니다: \[\begin{equation} H(a,w) = \frac{g_0(a - \delta \mid w)}{g_0(a \mid w)} + 1 (\#eq:aux-covar-simple-shift) \end{equation}\] 효율적 영향 함수는 준모수 효율적 추정기 구축의 핵심 요소입니다. 다음으로, Dı́az and van der Laan (2018) 이 제시한 타겟 최소 손실 기반 추정(TML) 추정기에 중점을 둡니다:
- 데이터 적응형 회귀 기법을 사용하여 \(g_0(A, W)\)의 초기 추정기 \(g_n\)과 \(\overline{Q}_0(A, W)\)의 초기 추정기 \(\overline{Q}_n\)을 구축합니다.
- 각 관찰값 \(i\)에 대해 보조 공변량 \(H(a_i,w_i)\)의 추정치 \(H_n(a_i, w_i)\)를 계산합니다.
- 다음과 같은 1차원 로지스틱 회귀 모델을 구축하거나, \[ \text{logit}\overline{Q}_{\epsilon, n}(a, w) = \text{logit}\overline{Q}_n(a, w) + \epsilon H_n(a, w),\] 또는 \(H_n\)을 가중치로 사용하는 유사한 회귀 모델을 구축합니다. 회귀 모델의 매개변수 \(\epsilon\)을 추정하여 \(\epsilon_n\)을 얻습니다. 이 회귀 모델의 결과는 \(\overline{Q}_n^{\star}\)가 됩니다.
- 타겟 매개변수의 TML 추정치 \(\Psi_n\)을 계산하며, 초기 추정치 \(\overline{Q}_{n, \epsilon_n}\)의 업데이트 \(\overline{Q}_n^{\star}\)를 정의합니다: \[\begin{equation} \psi_n = \Psi(P_n^{\star}) = \frac{1}{n} \sum_{i = 1}^n \overline{Q}_n^{\star}(d(A_i, W_i), W_i). (\#eq:tmle) \end{equation}\]
이전에 논의했듯이, TML 추정기는 점근적 선형성(asymptotically linear)을 갖도록 구축되며 보통 이중 로버스트(doubly robust)합니다. 점근적 선형성이란 추정기 \(\psi_n\)과 타겟 매개변수 \(\psi_0\) 사이의 점근적 차이가 EIF 측면에서 표현될 수 있음을 의미합니다: \[\begin{equation} \sqrt{n}(\psi_n - \psi_0) = \frac{1}{\sqrt{n}}\sum_{i=1}^n D(P_0)(O_i) + o_p(1). (\#eq:asymplin-shift) \end{equation}\] 점근적 선형성은 정규성(regularity)과 함께 점근적 분산이 EIF의 점근적 분산에 의해 하한이 정해지는 추정기 부류를 수립합니다. 이는 이러한 추정기가 EIF 추정 방정식의 해가 됨을 의미하며(즉, TML 추정기 \(\psi_n\)을 EIF 방정식에 대입하면 결과가 0에 가깝게 나옴), 샘플링 분산이 폐쇄형(closed form)으로 EIF의 분산에 의해 근사될 수 있음을 의미합니다. 후자의 사실은 분산 추정을 위해 재표본 추출 방법(예: 부트스트랩)이 반드시 필요하지 않기 때문에 계산적으로 편리합니다. 중심 극한 정리에 따라 추정기 \(\psi_n\)의 점근적 분포는 \(\psi_0\)를 중심으로 하며 가우스 분포를 따릅니다: \[\begin{equation} \sqrt{n}(\psi_n - \psi_0) \to \text{Normal}(0, \sigma^2(D(P_0))). (\#eq:tmle-gaussian-shift) \end{equation}\] 따라서 분산 \(\sigma^2(D(P_0))\)의 추정치 \(\sigma_n^2\)은 다음과 같이 계산될 수 있습니다: \[\begin{equation} \sigma_n^2 = \frac{1}{n} \sum_{i = 1}^{n} D^2(\overline{Q}_n^{\star}, g_n)(O_i), (\#eq:eif-var-shift) \end{equation}\] 이를 통해 포함 수준 \((1 - \alpha)\)에서 Wald 스타일의 신뢰 구간을 계산할 수 있습니다. 를 통해 \(\psi_n \pm z_{(1 - \alpha/2)} \cdot \sigma_n / \sqrt{n}\)으로 계산될 수 있습니다. 특정 조건 하에서는 \(\sigma_n^2\)을 계산하기 위해 부트스트랩(bootstrap)에 기반한 재표본 추출이 사용될 수도 있습니다 (van der Laan and Rose 2011).
10.4 확률적 중재의 인과 효과 해석
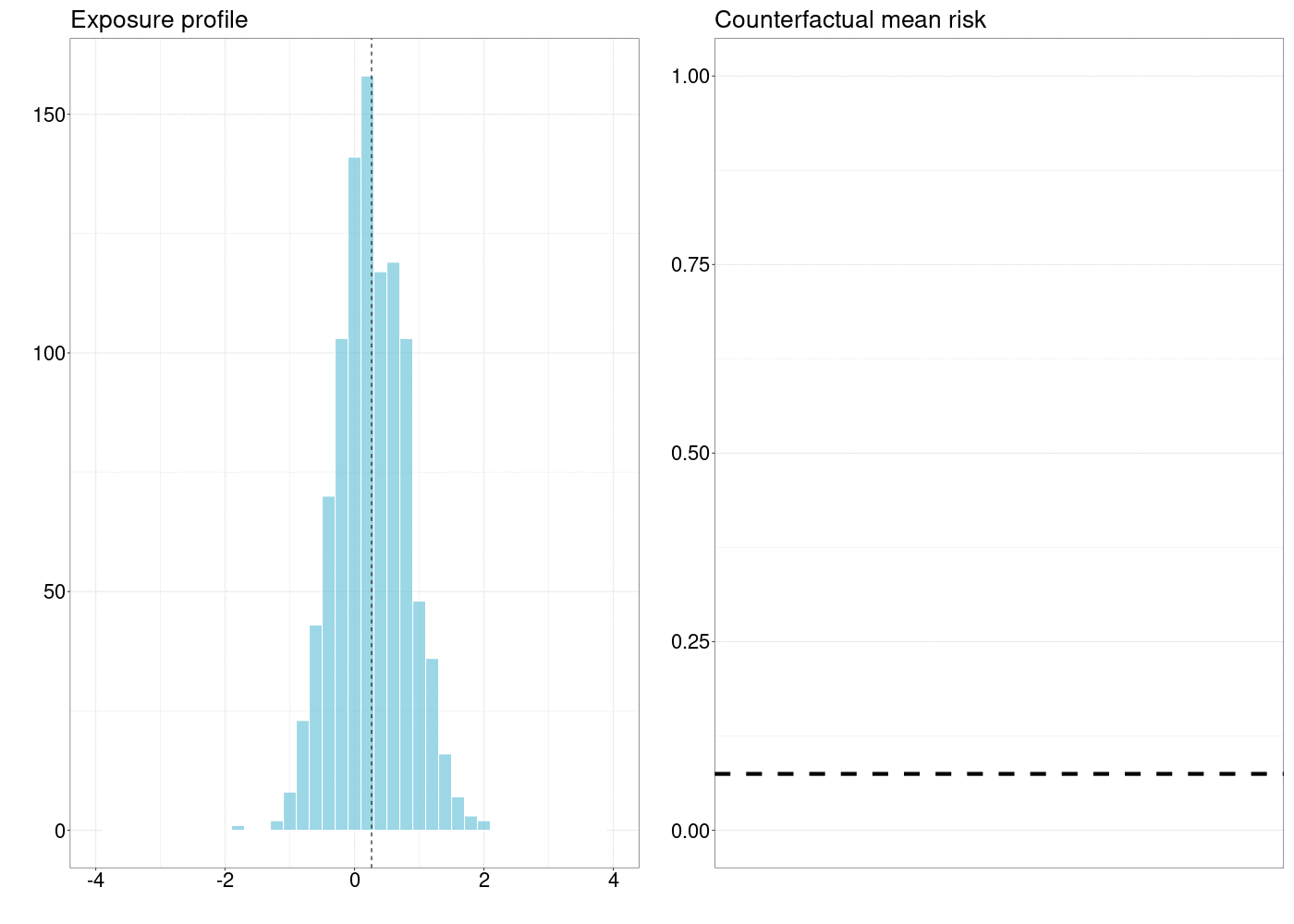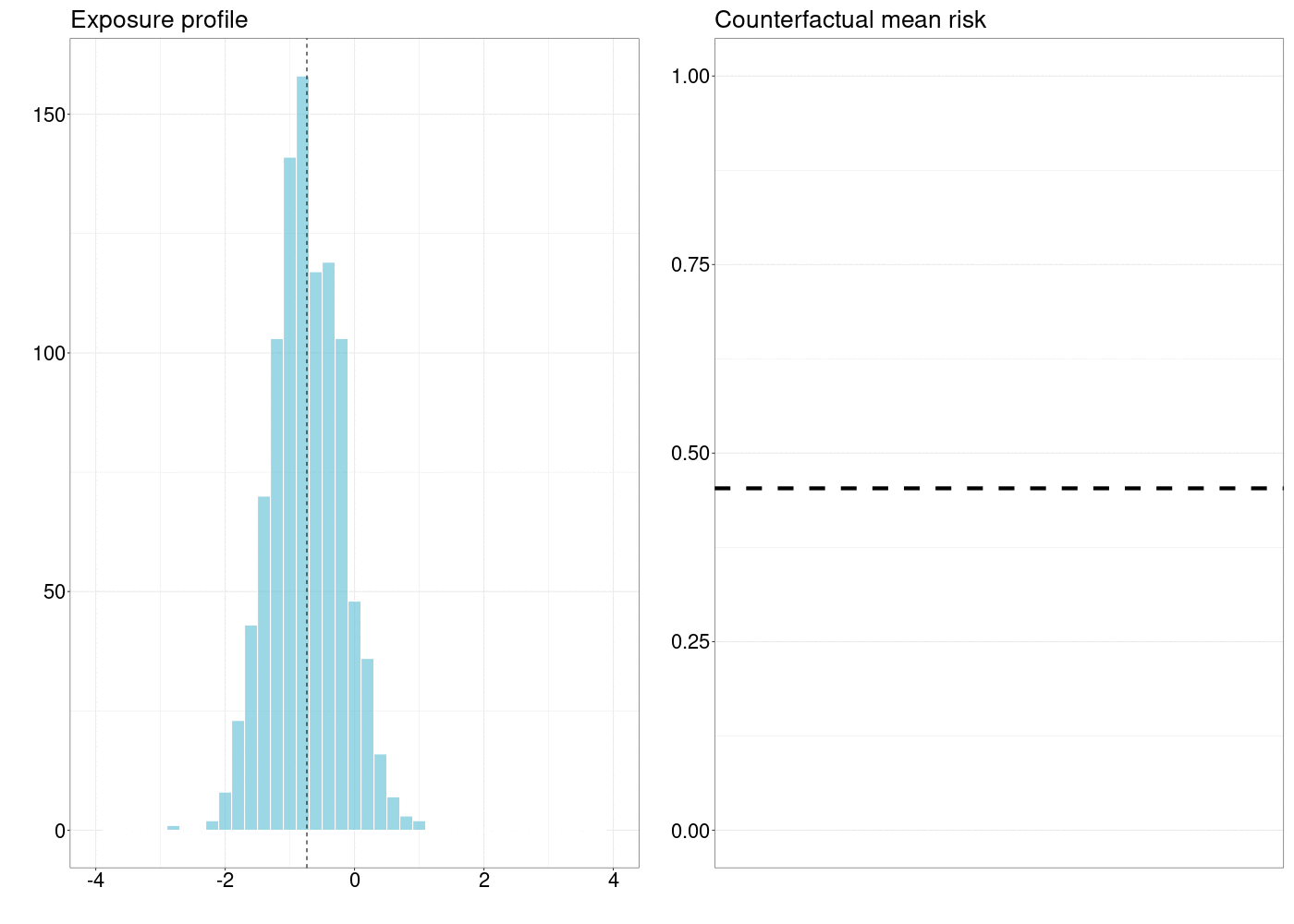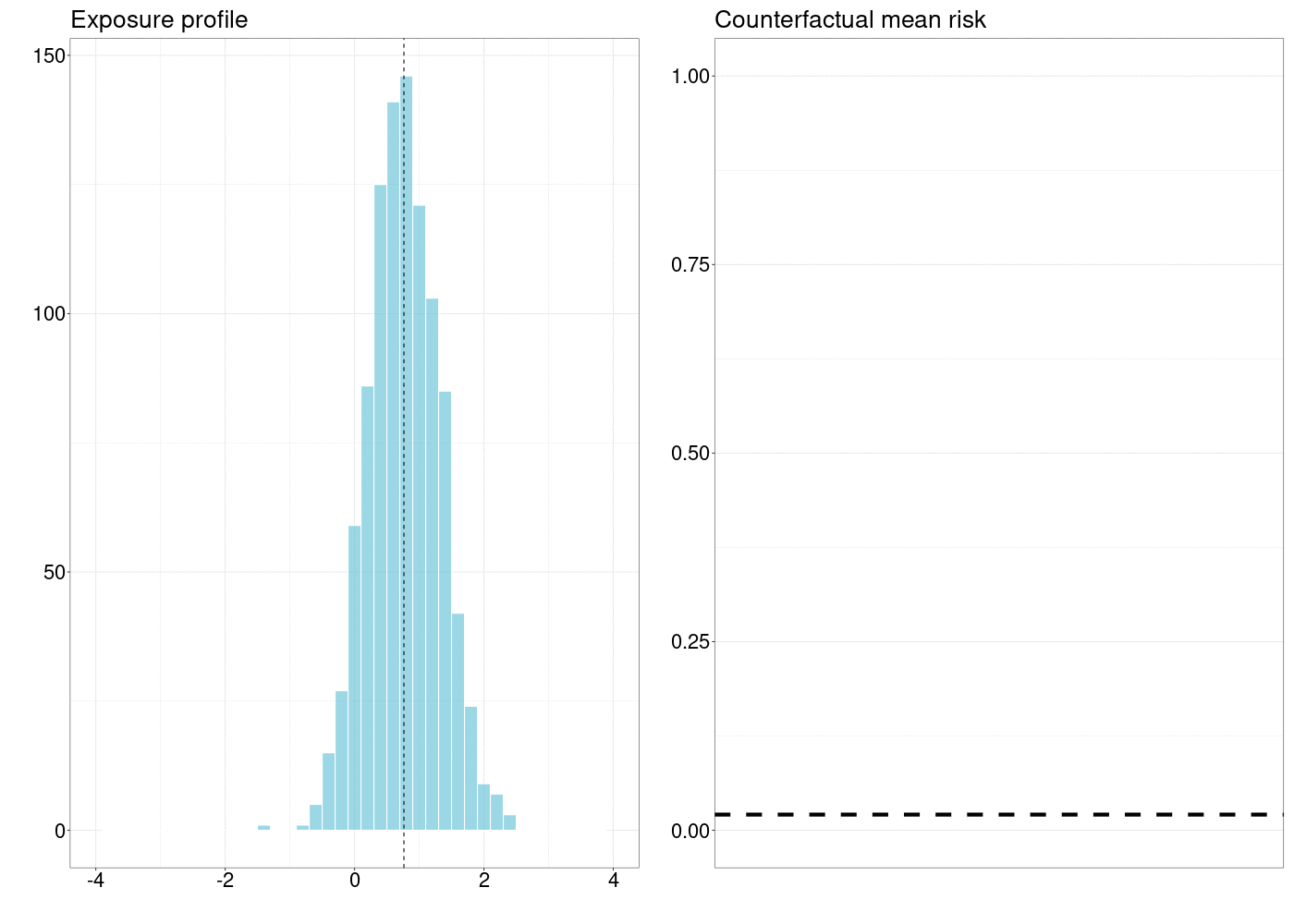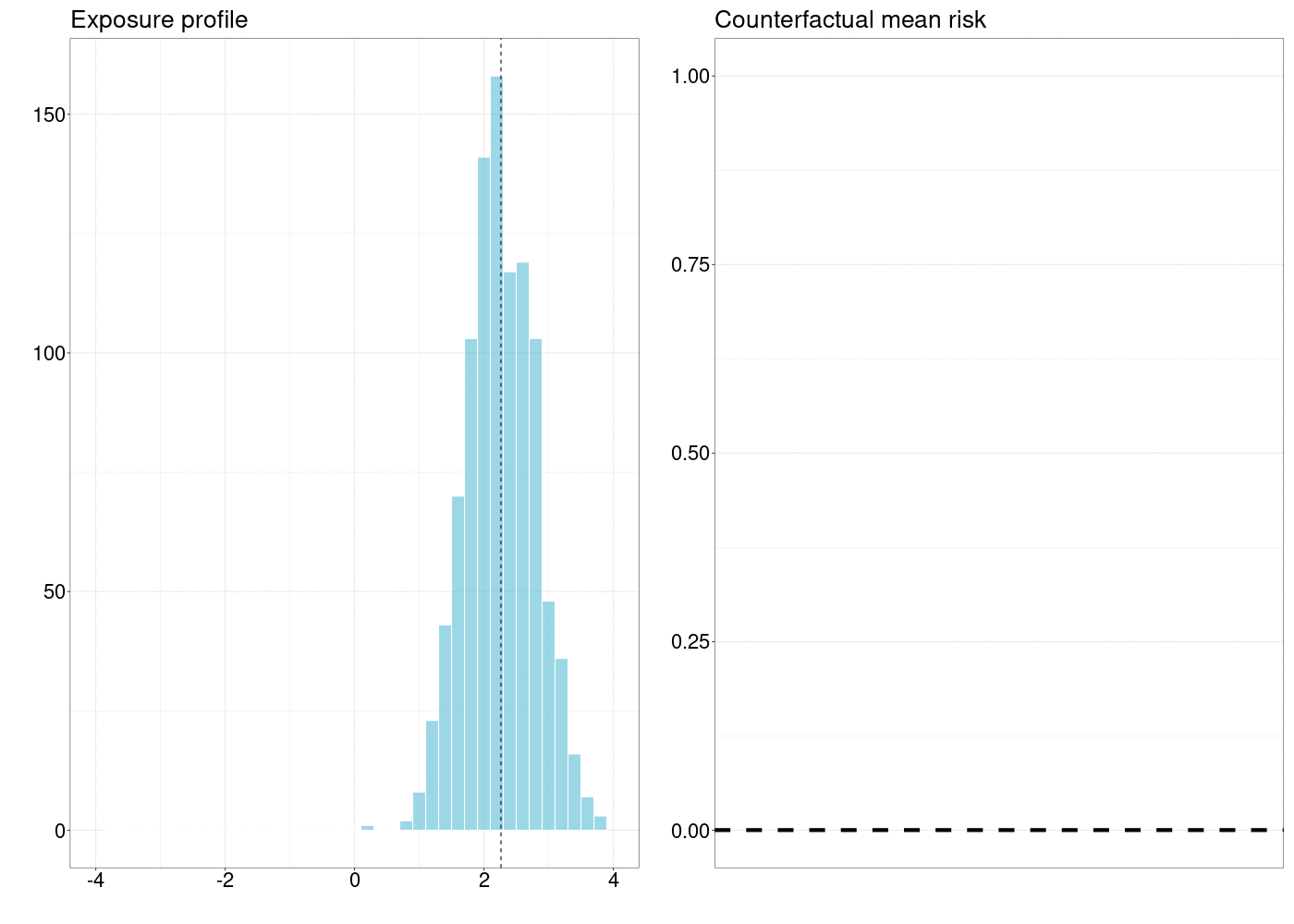
10.5 확률적 중재의 인과 효과 평가
먼저 간단한 데이터 예제 전체에서 사용할 패키지를 로드하겠습니다:
library(data.table)
library(haldensify)
library(sl3)
library(tmle3)
library(tmle3shift)TML 추정기를 구축하기 위해 가능성(likelihood)의 두 가지 구성 요소를 추정해야 합니다. 첫 번째 구성 요소는 결과 회귀 \(\overline{Q}_n\)으로, \(\E[Y \mid A,W]\) 형태의 단순 회귀입니다. 이러한 수치에 대한 추정치는 슈퍼 러너(Super Learner) 알고리즘을 사용하여 구축할 수 있습니다. 아래에서는 몇 가지 파라메트릭 및 비파라메트릭 회귀 기법을 사용하여 회귀를 위한 sl3 스타일의 슈퍼 러너 구성 요소를 구축합니다:
# 결과의 조건부 평균에 사용되는 학습기
mean_lrnr <- Lrnr_mean$new()
fglm_lrnr <- Lrnr_glm_fast$new()
rf_lrnr <- Lrnr_ranger$new()
hal_lrnr <- Lrnr_hal9001$new(max_degree = 3, n_folds = 3)
# 결과 회귀를 위한 SL
sl_reg_lrnr <- Lrnr_sl$new(
learners = list(mean_lrnr, fglm_lrnr, rf_lrnr, hal_lrnr),
metalearner = Lrnr_nnls$new()
)두 번째는 치료 메커니즘 \(g_n\), 즉 일반화된 성향 점수(generalized propensity score)의 추정치입니다. 연속형 중재 노드 \(A\)의 경우, 이러한 수치는 조건부 밀도인 \(p(A \mid W)\) 형태를 취합니다. 일반적으로 조건부 밀도 추정은 문헌에서 많은 관심을 받은 어려운 문제 부류입니다. 치료 메커니즘을 추정하려면 조건부 밀도 추정에 특화된 학습 알고리즘을 사용해야 합니다. sl3에서 사용할 수 있는 이러한 학습기 리스트는 sl3_list_learners()를 사용하여 추출할 수 있습니다:
sl3_list_learners("density")
[1] "Lrnr_density_discretize" "Lrnr_density_hse"
[3] "Lrnr_density_semiparametric" "Lrnr_haldensify"
[5] "Lrnr_solnp_density" 계속 진행하기 위해 위의 학습기 중 두 가지를 선택하겠습니다. 하나는 Dı́az and van der Laan (2011) 가 제시하고 Hejazi, Benkeser, and van der Laan (2022) 에 구현된 알고리즘을 기반으로 조건부 밀도 추정을 위해 고도의 적응형 올가미(Highly Adaptive Lasso)를 사용하는 Lrnr_haldensify이고, 다른 하나는 sl3 패키지에 구현된 준모수적 위치-척도(location-scale) 조건부 밀도 추정기입니다. 이러한 각 수정된 조건부 밀도 회귀 기법의 추정치를 풀링하여 슈퍼 러너를 구축할 수 있습니다 (참고: haldensify 학습기 기반의 접근 방식은 계산 집약적인 특성 때문에 여기서는 슈퍼 러너에서 제외합니다).
# (g_n)에 대한 조건부 밀도에 사용되는 학습기
haldensify_lrnr <- Lrnr_haldensify$new(
n_bins = c(5, 10, 20),
lambda_seq = exp(seq(-1, -10, length = 200))
)
# 동분산 오차(HOSE)를 갖는 준모수 밀도 추정기
hose_hal_lrnr <- make_learner(Lrnr_density_semiparametric,
mean_learner = hal_lrnr
)
# 이분산 오차(HESE)를 갖는 준모수 밀도 추정기
hese_rf_glm_lrnr <- make_learner(Lrnr_density_semiparametric,
mean_learner = rf_lrnr,
var_learner = fglm_lrnr
)
# 조건부 치료 밀도를 위한 SL
sl_dens_lrnr <- Lrnr_sl$new(
learners = list(hose_hal_lrnr, hese_rf_glm_lrnr),
metalearner = Lrnr_solnp_density$new()
)마지막으로 관심 있는 타겟 매개변수의 TML 추정치를 구축하는 데 사용할 learner_list 객체를 생성합니다:
learner_list <- list(Y = sl_reg_lrnr, A = sl_dens_lrnr)위의 learner_list 객체는 관심 있는 매개변수에 대한 TMLE를 구축하는 데 사용될 초기 추정치를 계산할 때 생성된 각 앙상블 학습기가 수행할 역할을 지정합니다. 특히 Q_learner는 결과 회귀를 적합하는 데 사용되고 g_learner는 치료 메커니즘을 추정하는 데 사용된다는 것을 명시합니다.
10.5.1 시뮬레이션 데이터를 사용한 예제
# tmle-shift 스케치를 위한 간단한 데이터 시뮬레이션
n_obs <- 400 # 관찰 단위 수
tx_mult <- 2 # W = 1이 치료에 미치는 영향의 승수
## 기본 공변량 -- 단순한 이분형
W <- replicate(2, rbinom(n_obs, 1, 0.5))
## 기본 W를 바탕으로 치료 생성
A <- rnorm(n_obs, mean = tx_mult * W, sd = 1)
## A, W의 선형 함수 + 백색 소음으로 결과 생성
Y <- rbinom(n_obs, 1, prob = plogis(A + W))
# tmle3를 위한 데이터 및 노드 정리
data <- data.table(W, A, Y)
setnames(data, c("W1", "W2", "A", "Y"))
node_list <- list(
W = c("W1", "W2"),
A = "A",
Y = "Y"
)
head(data)
W1 W2 A Y
<int> <int> <num> <int>
1: 0 0 -1.492 0
2: 1 1 2.369 1
3: 1 1 2.920 1
4: 0 1 1.432 1
5: 1 1 1.670 0
6: 1 0 3.049 1위의 과정은 관찰된 데이터 구조 \(O = (W, A, Y)\)를 구성합니다. tmle3 패키지에서 도입된 tlverse 문법을 사용하여 이를 공식적으로 표현하기 위해, 단일 데이터 객체를 생성하고 설정한 노드 리스트에 반영된 SCM을 통해 지향성 비순환 그래프(DAG) 내의 노드 간 기능적 관계를 지정합니다.
이제 관찰된 데이터 구조(data)와 데이터셋의 각 변수가 DAG의 노드로서 수행하는 역할에 대한 명세가 준비되었습니다.
시작하기 위해 단순히 tmle_shift를 호출하여 관심 있는 매개변수의 TMLE 사양(tlverse 명명법으로 tmle3_Spec이라고 함)을 초기화합니다. tmle3_Spec 객체를 초기화할 때 shift_val = 0.5 인수를 지정하여 치료 \(A\)의 척도에서 \(0.5\)의 이동에 관심이 있음을 알립니다 (즉, 이 예제에서는 임의로 선택된 값인 \(\delta = 0.5\)를 지정합니다).
# tmle 사양 초기화
tmle_spec <- tmle_shift(
shift_val = 0.5,
shift_fxn = shift_additive,
shift_fxn_inv = shift_additive_inv
)위에서 볼 수 있듯이 tmle_shift 사양 객체(모든 tmle3_Spec 객체와 마찬가지로)는 특정 분석을 위한 데이터를 저장하지 않습니다. 나중에 보겠지만, 인스턴스화된 tmle_spec과 함께 데이터 객체를 tmle3 래퍼 함수에 직접 전달하면 내부적으로 tmle3_Task 객체가 구축됩니다 (자세한 내용은 tmle3 문서를 참조하세요).
10.5.2 확률적 중재 효과의 타겟 추정
tmle_fit <- tmle3(tmle_spec, data, node_list, learner_list)
Iter: 1 fn: 582.9194 Pars: 0.92956 0.07044
Iter: 2 fn: 582.9194 Pars: 0.92956 0.07044
solnp--> Completed in 2 iterations
tmle_fit
A tmle3_Fit that took 1 step(s)
type param init_est tmle_est se lower upper psi_transformed
<char> <char> <num> <num> <num> <num> <num> <num>
1: TSM E[Y_{A=NULL}] 0.7789 0.7844 0.02019 0.7448 0.824 0.7844
lower_transformed upper_transformed
<num> <num>
1: 0.7448 0.824생성된 tmle_fit 객체의 print 메서드는 TML 추정치 \(\psi_n\)을 계산한 결과를 편리하게 표시합니다. 표준 오차 추정치는 추정된 EIF를 기반으로 계산됩니다.
10.6 안정적인 확률적 중재 선택
때때로 이동 매개변수 \(\delta\)를 특정하게 선택하면 양의 조건(positivity) 위반과 추정 과정에서의 하류 불안정성이 발생할 수 있습니다. 이러한 문제를 억제하기 위해 후보 값이 추정기에 미치는 영향을 바탕으로 \(\delta\)를 선택할 수 있습니다. \(\psi\)의 TMLE를 위한 보조 공변량의 단순화된 표현은 \(H = \frac{g(a - \delta \mid w)}{g(a \mid w)}\)이며, 여기서 \(g(a - \delta \mid w)\)는 관심 있는 확률적 중재에 의해 정의된다는 점을 상기하십시오. 우리는 \(C(\delta) = \frac{g(a - \delta \mid w)}{g(a \mid w)} < M\)이라는 경계를 고려하여 양의 조건 가정 위반을 피하도록 확률적 중재를 설계할 수 있습니다. 여기서 \(M\)은 사용자가 지정할 수 있는 \(C(\delta)\)의 상한입니다. \(C(\delta)\)는 반사실적 치료 값 \(A = a + \delta\), 자연적 치료 값 \(A = a\) 및 공변량 \(W = w\)를 갖는 관찰 단위에 할당된 역 가중치에 대응한다는 점에 유의하십시오. 따라서 \(C(\delta)\)는 주어진 관찰값이 추정치 \(\psi_n\)에 미치는 영향력의 척도로 볼 수 있습니다. \(M\)이나 \(\delta\)의 선택을 통해 \(C(\delta)\)를 제한함으로써 추정기의 잠재적 불안정성을 제한할 수 있습니다. 우리는 새로운 이동 함수 \(\delta(A, W)\)를 정의하여 이 절차를 공식화할 수 있습니다: \[\begin{equation} \delta(a, w) = \begin{cases} \delta, & \delta_{\text{min}}(a,w) \leq \delta \leq \delta_{\text{max}}(a,w) \\ \delta_{\text{max}}(a,w), & \delta \geq \delta_{\text{max}}(a,w) \\ \delta_{\text{min}}(a,w), & \delta \leq \delta_{\text{min}}(a,w) \\ \end{cases}, (\#eq:delta-min-max-shift) \end{equation}\] 여기서 \[\delta_{\text{max}}(a, w) = \text{argmax}_{\left\{\delta \geq 0, \frac{g(a - \delta \mid w)}{g(a \mid w)} \leq M \right\}} \frac{g(a - \delta \mid w)}{g(a \mid w)}\] 이고, \[\delta_{\text{min}}(a, w) = \text{argmin}_{\left\{\delta \leq 0, \frac{g(a - \delta \mid w)}{g(a \mid w)} \leq M \right\}} \frac{g(a - \delta \mid w)}{g(a \mid w)}\] 입니다.
위의 내용은 주어진 관찰값 \((a_i, w_i)\) 수준에서 이동(shift)을 구현하는 전략을 제공하며, 이를 통해 모든 관찰값이 \(\delta_{\text{min}}\), \(\delta\) 또는 \(\delta_{\text{max}}\) 중 적절한 값으로 이동될 수 있도록 합니다. tmle3shift 패키지는 이 전략의 변형을 정의하는 shift_additive_bounded 및 shift_additive_bounded_inv 함수를 구현합니다: \[\begin{equation}
\delta(a, w) =
\begin{cases}
\delta, & C(\delta) \leq M \\
0, \text{otherwise} \\
\end{cases},
(\#eq:shift-bounded-simple)
\end{equation}\] 이는 중재 후 밀도 \(g(a - \delta \mid w)\)와 자연적 치료 밀도 \(g(a \mid w)\)의 비율 \(C(\delta)\)가 경계 \(M\)을 초과하지 않을 때 자연적 치료 값 \(A = a\)를 \(\delta\)만큼 이동시키는 중재에 해당합니다. \(C(\delta)\)가 경계 \(M\)을 초과할 경우, 확률적 중재는 해당 단위를 치료 수정에서 제외하여 자연적 치료 값 \(A = a\)로 남겨둡니다.
10.6.1 tmle3_Spec을 통한 vimshift 초기화
시작하기 위해 단순히 tmle_shift를 호출하여 관심 있는 매개변수의 TMLE 사양(tlverse 명명법으로 tmle3_Spec이라고 함)을 초기화합니다. tmle3_Spec 객체를 초기화할 때 shift_grid = seq(-1, 1, by = 1) 인수를 지정하여 치료 \(A\)의 척도에서 이동 격자 \(\delta \in \{-1, 0, 1\}\)에 대해 반사실적 평균 결과를 평가하는 데 관심이 있음을 알립니다 (참고: 이 예제에서도 이동 값을 임의로 선택했습니다).
# 우리가 고려하고 싶은 이동 격자는 무엇인가요?
delta_grid <- seq(-1, 1, 1)
# tmle 사양 초기화
tmle_spec <- tmle_vimshift_delta(
shift_grid = delta_grid,
max_shifted_ratio = 2
)위에서 볼 수 있듯이 tmle_vimshift 사양 객체(모든 tmle3_Spec 객체와 마찬가지로)는 특정 분석을 위한 데이터를 저장하지 않습니다. 나중에 보겠지만, 인스턴스화된 tmle_spec과 함께 데이터 객체를 tmle3 래퍼 함수에 직접 전달하면 내부적으로 tmle3_Task 객체가 구축됩니다 (자세한 내용은 tmle3 문서를 참조하세요).
10.6.2 확률적 중재 효과의 타겟 추정
tmle3 R 패키지가 노출하는 메커니즘을 사용하여 격자의 각 이동에 대한 반사실적 평균 결과의 TML 추정치를 적합하는 단계별 절차를 거칠 수 있습니다.
tmle3 래퍼 함수(사용자 편의 유틸리티)를 호출하여 단일 함수 호출 내에서 일련의 TML 추정치(격자 델타에 의해 정의된 각 매개변수에 대해 하나씩)를 적합할 수 있습니다:
tmle_fit <- tmle3(tmle_spec, data, node_list, learner_list)
Iter: 1 fn: 579.2639 Pars: 0.999998798 0.000001201
Iter: 2 fn: 579.2639 Pars: 0.9999998049 0.0000001951
solnp--> Completed in 2 iterations
tmle_fit
A tmle3_Fit that took 1 step(s)
type param init_est tmle_est se lower upper
<char> <char> <num> <num> <num> <num> <num>
1: TSM E[Y_{A=NULL}] 0.5309 0.5517 0.02969 0.4935 0.6099
2: TSM E[Y_{A=NULL}] 0.7025 0.7025 0.02289 0.6576 0.7474
3: TSM E[Y_{A=NULL}] 0.8433 0.8530 0.01723 0.8192 0.8868
4: MSM_linear MSM(intercept) 0.6922 0.7024 0.02122 0.6608 0.7440
5: MSM_linear MSM(slope) 0.1562 0.1506 0.01266 0.1258 0.1755
psi_transformed lower_transformed upper_transformed
<num> <num> <num>
1: 0.5517 0.4935 0.6099
2: 0.7025 0.6576 0.7474
3: 0.8530 0.8192 0.8868
4: 0.7024 0.6608 0.7440
5: 0.1506 0.1258 0.1755비고: 생성된 tmle_fit 객체의 print 메서드는 TML 추정치를 계산한 결과를 편리하게 표시합니다.
10.6.3 한계 구조 모델을 사용한 추정 및 추론
이동 매개변수 \(\delta\)의 값을 미리 선택하는 것은 어려울 수 있습니다. 한가지 해결책은 일련의 관련 확률적 중재를 정의하는 데 사용될 이러한 이동 \(\delta\)의 격자(grid)를 지정하는 것입니다 (Hejazi et al. 2020). 여러 \(\delta\) 선택 하에서 반사실적 평균 \(\psi_n\)을 추정할 때, 이러한 추정된 수치들에 대한 단일 요약 측정치는 작동 한계 구조 모델(working MSMs)을 통해 수립될 수 있습니다. 작동 MSM을 통해 추정치 \(\psi_n\)을 요약하면 \(\delta\) 격자를 통해 나타나는 경향(trend)에 대한 추론이 가능하며, 이는 작동 MSM의 기울기 매개변수 \(\beta_1\)에 대한 단순 가설 검정을 통해 평가될 수 있습니다. 격자 \(\delta\), \(\{\delta_1, \ldots, \delta_k\}\)와 이에 대응하는 반사실적 평균 \(\{\psi_{\delta_1}, \ldots, \psi_{\delta_k}\}\)를 고려해 보십시오. 이제 \(\psi(\delta) = (\psi_{\delta}: \delta)\)를 \(\delta\)에 의해 정의된 격자 내의 반사실적 평균 격자라고 하고, \(\psi_n(\delta)\)를 \(\psi(\delta)\)의 TML 추정치라고 합시다. \(\delta\)의 함수로서 \(\psi_n\)의 변화를 요약하는 MSM은 \(m_{\beta}(\psi_{\delta}) = \beta_0 + \beta_1 \delta\)로 표현될 수 있습니다. 이 단순 작동 모델은 \(\psi_{\delta}\)의 변화를 매개변수 \((\beta_0, \beta_1)\)의 함수로 요약하며, 여기서 후자는 반사실적 평균을 이 단순한 2-매개변수 작동 모델에 투영하여 얻은 직선의 기울기입니다.
MSM \(m_{\beta}(\delta)\)에 대한 보다 일반적인 표현은 다음과 같으며, \(\beta_0 = \text{argmin}_{\beta} \sum_{\delta}(\psi_{\delta}(P_0) - m_{\beta}(\delta))^2 h(\delta)\)는 다음 추정 방정식의 해입니다: \[u(\beta, (\psi_{\delta}: \delta)) = \sum_{\delta}h(\delta) \left(\psi_{\delta}(P_0) - m_{\beta}(\delta) \right) \frac{d}{d\beta} m_{\beta}(\delta) = 0.\]
이제 \(\psi = (\psi(\delta): \delta)\)가 d-차원이라고 합시다. MSM 매개변수 \(\beta_0\)의 EIF를 개별 반사실적 평균의 EIF들로 표현할 수 있습니다: \[\begin{align} D_{\beta}(O) = &\left(\sum_{\delta} h(\delta) \frac{d}{d\beta} m_{\beta}(\delta) \frac{d}{d\beta} m_{\beta}(\delta)^t \right)^{-1} \\ \nonumber &\sum_{\delta} h(\delta) \frac{d}{d\beta} m_{\beta}(\delta) D_{\psi_{\delta}}(O). (\#eq:eif-msm-shift) \end{align}\] 여기서 식 @ref(eq:eif-msm-shift)의 첫 번째 구성 요소는 \(d \times d\) 차원이고 두 번째 구성 요소는 \(d \times 1\) 차원입니다. 위에서는 선형 작동 MSM을 가정했지만, GLM 기반의 작동 MSM에 대해서도 유사한 절차를 적용할 수 있습니다.
위에서 우리는 \(\beta\)의 EIF를 얻기 위해 단순한 델타 방법을 활용했습니다. 이 작동 MSM 매개변수에 대한 추론은 각 대응하는 추정치 \(\psi_n(\delta)\)의 EIF들로 표현되는 EIF \(D_{\beta}\)의 평가로부터 도출됩니다. \(\beta_n\)의 한계 분포는 다음과 같이 표현될 수 있습니다: \[\sqrt{n}(\beta_n - \beta_0) \to N(0, \Sigma),\] 여기서 \(\Sigma\)는 \(D_{\beta}(O)\)의 경험적 공분산 행렬입니다. 이를 통해 \(\delta\) 격자에 걸친 반사실적 평균들의 경향을 추정할 수 있을 뿐만 아니라, 기울기 추정치가 통계적으로 유의미한지 여부를 \((H_0: \beta_1 = 0; H_1: \beta_1 \neq 0)\) 형태의 가설 검정과 그에 대응하는 Wald 스타일 신뢰 구간을 통해 평가할 수 있습니다. MSM 매개변수 \(\beta_0\)의 추정기 \(\beta_n\)은 개별 TML 추정기들로부터 구축된 결과로 점근적 선형성(사실상 TML 추정기)을 갖는다는 점에 유의하십시오.
방금 논의한 전략은 먼저 격자 \(\{\delta_1, \ldots, \delta_k\}\)에서 반사실적 평균 \(\psi_{n,\delta}\)의 TML 추정치를 평가하여 작동 MSM 기울기 \(\beta_0\)의 추정치 \(\beta_n\)을 구축합니다. 그러나 이것이 반드시 최선의 전략은 아니며, 특히 소표본에서의 추정 안정성을 고려할 때 더욱 그렇습니다. 작은 표본에서는 여러 독립적으로 타겟팅된 TML 추정치에 델타 방법을 적용하여 구축하는 대신, 매개변수 \(\beta_0\)를 직접 타겟팅하여 TML 추정치를 수행하는 것이 현명할 수 있습니다.
그렇게 하기 위해, 모든 \(\delta\)에 대해 \(\overline{Q}_{n, \epsilon}(A,W) = \overline{Q}_n(A,W) + \epsilon (H_{\beta_0}(g), H_{\beta_1}(g))\) 형태의 타겟팅 업데이트 단계를 사용하는 \(\beta_0\)(작동 MSM \(m_{\beta}\)의 매개변수) 타겟 TML 추정기를 고려해 보십시오. 여기서 \(H_{\beta_0}(g)\)는 \(\beta_0\)(절편)에 대한 보조 공변량이고 \(H_{\beta_1}(g)\)는 \(\beta_1\)(기울기)에 대한 보조 공변량입니다. 이러한 보조 공변량의 형태는 EIF \(D_{\beta}\)에 의존한다는 점에 유의하십시오. 이러한 TML 추정기는 격자의 각 \(\psi_{\delta}\)를 직접 추정하는 것을 피하고, 대신 그들의 보조 공변량을 \(\beta_0\)와 \(\beta_1\)에 적합한 것으로 교묘하게 결합합니다. 작동 MSM의 매개변수를 직접 타겟팅하는 타겟 최소 손실 기반 추정기를 구축하려면 (tmle_vimshift_delta 사양 대신) tmle_vimshift_msm 사양을 사용할 수 있습니다.
# tmle 사양 초기화
tmle_msm_spec <- tmle_vimshift_msm(
shift_grid = delta_grid,
max_shifted_ratio = 2
)
# TML 추정기 적합 및 결과 확인
tmle_msm_fit <- tmle3(tmle_msm_spec, data, node_list, learner_list)
tmle_msm_fit10.6.4 WASH Benefits 데이터를 사용한 예제
둘러보기를 마치기 위해 확률적 중재를 사용하여 WASH Benefits 임상시험 데이터를 조사해 보겠습니다. 먼저 데이터를 로드하고 모든 열을 numeric 클래스로 변환한 뒤 간단히 살펴보겠습니다:
washb_data <- fread(
paste0(
"https://raw.githubusercontent.com/tlverse/tlverse-data/master/",
"wash-benefits/washb_data.csv"
),
stringsAsFactors = TRUE
)
washb_data <- washb_data[!is.na(momage), lapply(.SD, as.numeric)]
head(washb_data, 3)
whz tr fracode month aged sex momage momedu momheight hfiacat Nlt18
<num> <num> <num> <num> <num> <num> <num> <num> <num> <num> <num>
1: 0.00 1 4 9 268 2 30 2 146.4 1 3
2: -1.16 1 4 9 286 2 25 2 148.8 3 2
3: -1.05 1 20 9 264 2 25 2 152.2 1 1
Ncomp watmin elec floor walls roof asset_wardrobe asset_table asset_chair
<num> <num> <num> <num> <num> <num> <num> <num> <num>
1: 11 0 1 0 1 1 0 1 1
2: 4 0 1 0 1 1 0 1 0
3: 10 0 0 0 1 1 0 0 1
asset_khat asset_chouki asset_tv asset_refrig asset_bike asset_moto
<num> <num> <num> <num> <num> <num>
1: 1 0 1 0 0 0
2: 1 1 0 0 0 0
3: 0 1 0 0 0 0
asset_sewmach asset_mobile
<num> <num>
1: 0 1
2: 0 1
3: 0 1다음으로 node_list 객체를 통해 NPSEM을 지정합니다. 예제 분석을 위해 이전 장들과 마찬가지로 결과를 키 대비 몸무게 Z-점수(WHZ)로, 관심 있는 중재를 아이 출생 당시 어머니의 나이(momage)로 설정하고, 다른 모든 공변량은 잠재적 교란 요인으로 간주합니다.
node_list <- list(
W = names(washb_data)[!(names(washb_data) %in%
c("whz", "momage"))],
A = "momage",
Y = "whz"
)어머니의 출산 당시 나이의 변화에 따른 반사실적 WHZ 점수를 고려한다면, 매개변수 추정치를 어떻게 해석해야 할까요? 해석을 단순화하기 위해 어머니의 나이를 딱 1년만 이동한다고 가정해 봅시다(즉, \(\delta = 1\)). 이 설정에서 확률적 중재는 잠재적 어머니들이 출산을 1년 미루도록 권장하는 정책에 대응하며, 이는 임상 현장에서 배치된 권장 설계(encouragement design)를 통해 구현될 수 있습니다.
이 예제에서는 확률적 중재 격자를 고려하는 변수 중요도(variable importance) 전략을 사용하여 어머니의 나이가 2년 낮아지는(\((\delta = -2)\) 또는 2년 높아지는(\((\delta = 2)\) 경우의 WHZ 점수를 평가할 것입니다. 이를 위해 이전 예제에서 했던 것처럼 tmle_vimshift_delta 사양을 초기화합니다:
# 변수 중요도 매개변수를 위한 tmle 사양 초기화
washb_vim_spec <- tmle_vimshift_delta(
shift_grid = c(-2, 2),
max_shifted_ratio = 2
)분석을 실행하기 전에 생성한 learner_list 객체를 수정할 것입니다. 고도의 적응형 올가미(Highly Adaptive Lasso) 기반의 비파라메트릭 조건부 밀도 접근 방식 (Dı́az and van der Laan 2011; Benkeser and van der Laan 2016; Coyle et al. 2022; Hejazi, Coyle, and van der Laan 2020; Hejazi, Benkeser, and van der Laan 2022)은 현재 대규모 데이터셋을 수용할 수 없으므로, 밀도 추정 절차로는 위치-척도 조건부 밀도 추정 절차만을 사용할 것입니다.
# HOSE 학습기를 위해 교차 검증을 활성화해야 합니다.
cv_hose_hal_lrnr <- Lrnr_cv$new(
learner = hose_hal_lrnr,
full_fit = TRUE
)
# Q 적합을 위한 기존 SL을 사용하여 학습기 리스트 수정
learner_list <- list(Y = sl_reg_lrnr, A = cv_hose_hal_lrnr)위의 준비를 마쳤으므로 이제 아이 출생 당시 어머니 나이의 작은 이동 격자 하에서 반사실적 WHZ 평균을 추정할 준비가 되었습니다. 이전과 마찬가지로 tmle3 래퍼 함수를 호출하여 이를 수행합니다:
washb_tmle_fit <- tmle3(washb_vim_spec, washb_data, node_list, learner_list)
washb_tmle_fit10.7 연습 문제
10.7.1 개념의 실전 적용
Tip연습 문제 1
슈퍼 러너를 위한 알고리즘 sl3 라이브러리를 단순하고 해석 가능한 라이브러리로 설정하고, 이 새로운 라이브러리를 사용하여 이동 \(\delta = 0\)일 때 어머니의 출산 당시 나이(momage)의 반사실적 평균을 추정해 보세요. 이 반사실적 평균은 관찰된 데이터 측면에서 무엇과 같습니까?
:::
Tip연습 문제 2
이동 매개변수 \(\delta\)의 격자 값(예: \(\{-1, 0, +1\}\))을 사용하여 앞의 질문에서 선택한 변수에 대해 분석을 반복하고, 한계 구조 모델(MSM)을 사용하여 이 이동 시퀀스에 대한 경향을 요약해 보세요.
:::
Tip연습 문제 3
동일한 이동 격자를 사용하되, 이번에는 한계 구조 모델의 매개변수를 직접 타겟팅하여 앞의 분석을 반복해 보세요. 결과를 해석해 보세요. 즉, 한계 구조 모델의 기울기는 선택한 이동 시퀀스 전반의 경향에 대해 무엇을 말해줍니까?
:::
10.7.2 주요 개념 복습
Tip연습 문제 4
확률적 중재의 인과 효과를 해석할 수 있는 두 가지 (동등한) 방법에 대해 설명해 보세요.
Tip연습 문제 5
여러 이동 격자 \(\{ \delta_1, \ldots, \delta_k \}\)에 걸친 추정치와 경향을 요약하는 한계 구조 모델 매개변수가 제공하는 정보가 우리의 발견에 대한 해석을 어떻게 풍부하게 할 수 있을까요?
Tip연습 문제 6
한계 구조 모델의 매개변수를 직접 타겟팅할 때의 장점은 무엇입니까?