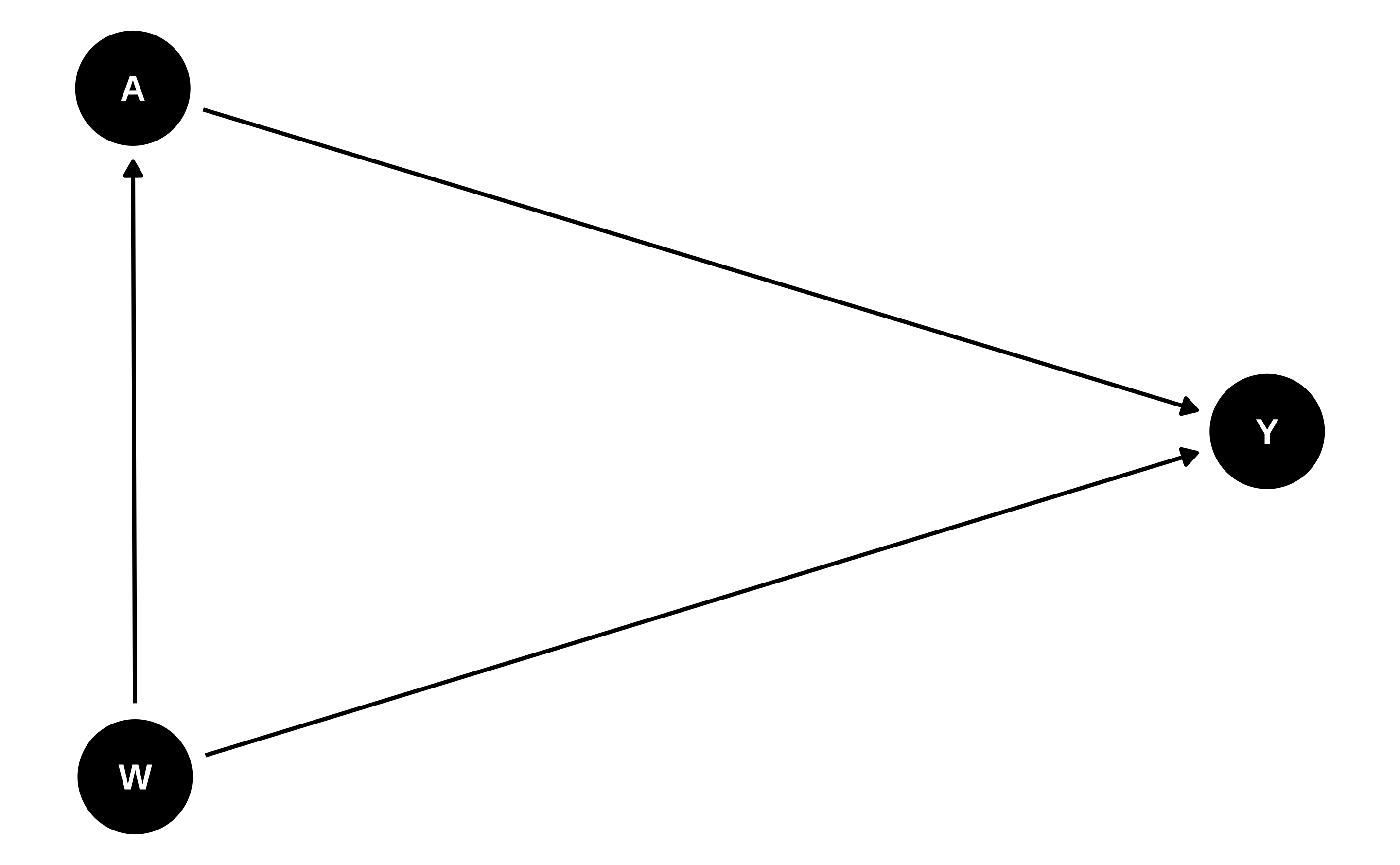
엄밀히 말하면 SCM 프레임워크 내에서 작업할 때는 뒤의 두 가지만 필요합니다. 처음 두 가지는 i.i.d. 데이터에 대한 SCM의 함축된 속성이기 때문입니다(정말 궁금하시다면 Pearl (2010) 의 논평을 참조하십시오). 우리는 이 네 가지 식별 가정을 모두 소개하는데, 이는 대개 함께 고려되며 잠재적 결과 프레임워크 내에서 작업할 때 네 가지 모두가 필수적이기 때문입니다 (Rubin 2005; Imbens and Rubin 2015).
Dı́az, Iván, and Mark J van der Laan. 2013.
“Sensitivity Analysis for Causal Inference Under Unmeasured Confounding and Measurement Error Problems.” The International Journal of Biostatistics 9 (2): 149–60.
https://doi.org/10.1515/ijb-2013-0004.
Donoho, David. 2017. “50 Years of Data Science.” Journal of Computational and Graphical Statistics 26 (4): 745–66.
Gruber, Susan, Rachael V Phillips, Hana Lee, John Concato, and Mark van der Laan. 2022. “Evaluating and Improving Real-World Evidence with Targeted Learning.” arXiv Preprint arXiv:2208.07283.
Gruber, Susan, Rachael V Phillips, Hana Lee, Martin Ho, John Concato, and Mark J van der Laan. 2023.
“Targeted Learning: Toward a Future Informed by Real-World Evidence.” Statistics in Biopharmaceutical Research.
https://doi.org/10.1080/19466315.2023.2182356.
Hernán, Miguel A, and James M Robins. 2022. Causal Inference: What If. CRC Press.
Holland, Paul W. 1986. “Statistics and Causal Inference.” Journal of the American Statistical Association 81 (396): 945–60.
Imbens, Guido W, and Donald B Rubin. 2015. Causal Inference in Statistics, Social, and Biomedical Sciences. Cambridge University Press.
Kennedy, Edward H. 2016. “Semiparametric Theory and Empirical Processes in Causal Inference.” In Statistical Causal Inferences and Their Applications in Public Health Research, 141–67. Springer.
Neyman, Jerzy. 1938. “Contribution to the Theory of Sampling Human Populations.” Journal of the American Statistical Association 33 (201): 101–16.
Pearl, Judea. 1995. “Causal Diagrams for Empirical Research.” Biometrika 82 (4): 669–88.
———. 2009. Causality: Models, Reasoning, and Inference. Cambridge University Press.
———. 2010. “Brief Report: On the Consistency Rule in Causal Inference: ‘Axiom, Definition, Assumption, or Theorem?’” Epidemiology, 872–75.
Rubin, Donald B. 2005. “Causal Inference Using Potential Outcomes: Design, Modeling, Decisions.” Journal of the American Statistical Association 100 (469): 322–31.
Textor, Johannes, Juliane Hardt, and Sven Knüppel. 2011. “DAGitty: A Graphical Tool for Analyzing Causal Diagrams.” Epidemiology 22 (5): 745.
Tukey, John W. 1962. “The Future of Data Analysis.” The Annals of Mathematical Statistics 33 (1): 1–67.
van der Laan, Mark J, and Sherri Rose. 2011. Targeted Learning: Causal Inference for Observational and Experimental Data. Springer Science & Business Media.