이 프로젝트에서는 다음과 같은 인구통계 요약표(Demography Summary Table) 생성을 목표로 합니다.
구조를 모방하여 R 코딩에 익숙해지고, 성별 및 치료군별 빈도와 백분율을 계산해 보겠습니다.
목표
ADSL SAS (xpt) 데이터셋 읽기
유효성 분석 대상군(Efficacy Population) 서브셋 추출
그룹별 빈도(n) 산출 및 총 N 대비 백분율 계산
표 작성을 위한 데이터 전치(Transpose)
이 문서 사용법
이 문서에는 코드 청크와 설명 텍스트가 포함되어 있습니다. 지침에 따라 코드 청크를 수정하고 실행하며 출력을 확인해 보세요.
R 객체와 함수
R에서는 다양한 유형의 객체 를 사용하며 함수 를 적용합니다. 기본 구조는 <함수_이름>(<인수1>=값, <인수2>=값)입니다. RStudio IDE의 탭 완성 기능을 활용하면 인수를 쉽게 입력할 수 있습니다.
미니 프로젝트 시작
먼저 필요한 패키지인 tidyverse와 rio를 로드합니다.
Warning: package 'ggplot2' was built under R version 4.4.3
Warning: package 'tibble' was built under R version 4.4.3
Warning: package 'purrr' was built under R version 4.4.2
Warning: package 'lubridate' was built under R version 4.4.2
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
데이터를 읽어와 adsl 객체에 저장합니다. rio 패키지의 import() 함수를 사용합니다.
<- import (file = "./data/adsl.xpt" )head (adsl)
STUDYID USUBJID SUBJID SITEID SITEGR1 ARM
1 CDISCPILOT01 01-701-1015 1015 701 701 Placebo
2 CDISCPILOT01 01-701-1023 1023 701 701 Placebo
3 CDISCPILOT01 01-701-1028 1028 701 701 Xanomeline High Dose
4 CDISCPILOT01 01-701-1033 1033 701 701 Xanomeline Low Dose
5 CDISCPILOT01 01-701-1034 1034 701 701 Xanomeline High Dose
6 CDISCPILOT01 01-701-1047 1047 701 701 Placebo
TRT01P TRT01PN TRT01A TRT01AN TRTSDT
1 Placebo 0 Placebo 0 2014-01-02
2 Placebo 0 Placebo 0 2012-08-05
3 Xanomeline High Dose 81 Xanomeline High Dose 81 2013-07-19
4 Xanomeline Low Dose 54 Xanomeline Low Dose 54 2014-03-18
5 Xanomeline High Dose 81 Xanomeline High Dose 81 2014-07-01
6 Placebo 0 Placebo 0 2013-02-12
TRTEDT TRTDUR AVGDD CUMDOSE AGE AGEGR1 AGEGR1N AGEU RACE RACEN SEX
1 2014-07-02 182 0.0 0 63 <65 1 YEARS WHITE 1 F
2 2012-09-01 28 0.0 0 64 <65 1 YEARS WHITE 1 M
3 2014-01-14 180 77.7 13986 71 65-80 2 YEARS WHITE 1 M
4 2014-03-31 14 54.0 756 74 65-80 2 YEARS WHITE 1 M
5 2014-12-30 183 76.9 14067 77 65-80 2 YEARS WHITE 1 F
6 2013-03-09 26 0.0 0 85 >80 3 YEARS WHITE 1 F
ETHNIC SAFFL ITTFL EFFFL COMP8FL COMP16FL COMP24FL DISCONFL
1 HISPANIC OR LATINO Y Y Y Y Y Y
2 HISPANIC OR LATINO Y Y Y N N N Y
3 NOT HISPANIC OR LATINO Y Y Y Y Y Y
4 NOT HISPANIC OR LATINO Y Y Y N N N Y
5 NOT HISPANIC OR LATINO Y Y Y Y Y Y
6 NOT HISPANIC OR LATINO Y Y Y N N N Y
DSRAEFL DTHFL BMIBL BMIBLGR1 HEIGHTBL WEIGHTBL EDUCLVL DISONSDT DURDIS
1 25.1 25-<30 147.3 54.4 16 2010-04-30 43.9
2 Y 30.4 >=30 162.6 80.3 14 2006-03-11 76.4
3 31.4 >=30 177.8 99.3 16 2009-12-16 42.8
4 28.8 25-<30 175.3 88.5 12 2009-08-02 55.3
5 26.1 25-<30 154.9 62.6 9 2011-09-29 32.9
6 Y 30.4 >=30 148.6 67.1 8 2009-07-26 42.0
DURDSGR1 VISIT1DT RFSTDTC RFENDTC VISNUMEN RFENDT
1 >=12 2013-12-26 2014-01-02 2014-07-02 12 2014-07-02
2 >=12 2012-07-22 2012-08-05 2012-09-02 5 2012-09-02
3 >=12 2013-07-11 2013-07-19 2014-01-14 12 2014-01-14
4 >=12 2014-03-10 2014-03-18 2014-04-14 5 2014-04-14
5 >=12 2014-06-24 2014-07-01 2014-12-30 12 2014-12-30
6 >=12 2013-01-22 2013-02-12 2013-03-29 6 2013-03-29
DCDECOD DCREASCD MMSETOT
1 COMPLETED Completed 23
2 ADVERSE EVENT Adverse Event 23
3 COMPLETED Completed 23
4 STUDY TERMINATED BY SPONSOR Sponsor Decision 23
5 COMPLETED Completed 21
6 ADVERSE EVENT Adverse Event 23
유효성 분석 대상군 추출을 위해 EFFFL 변수가 “Y”인 데이터만 필터링합니다.
간단 퀴즈 : 다음 중 변수 EFFFL의 값이 “Y”인 데이터를 필터링하는 올바른 옵션은 무엇입니까?
filter(.data = adsl, EFFFL = Y)filter(.data = adsl, EFFFL == "Y")filter(.data = adsl, "EFFFL" == "Y")filter(.data = adsl, EFFFL = "y")
정답을 아래 코드 청크에 적용해 보세요.
<- adsl %>% filter (EFFFL == "Y" )head (adsl_eff)
STUDYID USUBJID SUBJID SITEID SITEGR1 ARM
1 CDISCPILOT01 01-701-1015 1015 701 701 Placebo
2 CDISCPILOT01 01-701-1023 1023 701 701 Placebo
3 CDISCPILOT01 01-701-1028 1028 701 701 Xanomeline High Dose
4 CDISCPILOT01 01-701-1033 1033 701 701 Xanomeline Low Dose
5 CDISCPILOT01 01-701-1034 1034 701 701 Xanomeline High Dose
6 CDISCPILOT01 01-701-1047 1047 701 701 Placebo
TRT01P TRT01PN TRT01A TRT01AN TRTSDT
1 Placebo 0 Placebo 0 2014-01-02
2 Placebo 0 Placebo 0 2012-08-05
3 Xanomeline High Dose 81 Xanomeline High Dose 81 2013-07-19
4 Xanomeline Low Dose 54 Xanomeline Low Dose 54 2014-03-18
5 Xanomeline High Dose 81 Xanomeline High Dose 81 2014-07-01
6 Placebo 0 Placebo 0 2013-02-12
TRTEDT TRTDUR AVGDD CUMDOSE AGE AGEGR1 AGEGR1N AGEU RACE RACEN SEX
1 2014-07-02 182 0.0 0 63 <65 1 YEARS WHITE 1 F
2 2012-09-01 28 0.0 0 64 <65 1 YEARS WHITE 1 M
3 2014-01-14 180 77.7 13986 71 65-80 2 YEARS WHITE 1 M
4 2014-03-31 14 54.0 756 74 65-80 2 YEARS WHITE 1 M
5 2014-12-30 183 76.9 14067 77 65-80 2 YEARS WHITE 1 F
6 2013-03-09 26 0.0 0 85 >80 3 YEARS WHITE 1 F
ETHNIC SAFFL ITTFL EFFFL COMP8FL COMP16FL COMP24FL DISCONFL
1 HISPANIC OR LATINO Y Y Y Y Y Y
2 HISPANIC OR LATINO Y Y Y N N N Y
3 NOT HISPANIC OR LATINO Y Y Y Y Y Y
4 NOT HISPANIC OR LATINO Y Y Y N N N Y
5 NOT HISPANIC OR LATINO Y Y Y Y Y Y
6 NOT HISPANIC OR LATINO Y Y Y N N N Y
DSRAEFL DTHFL BMIBL BMIBLGR1 HEIGHTBL WEIGHTBL EDUCLVL DISONSDT DURDIS
1 25.1 25-<30 147.3 54.4 16 2010-04-30 43.9
2 Y 30.4 >=30 162.6 80.3 14 2006-03-11 76.4
3 31.4 >=30 177.8 99.3 16 2009-12-16 42.8
4 28.8 25-<30 175.3 88.5 12 2009-08-02 55.3
5 26.1 25-<30 154.9 62.6 9 2011-09-29 32.9
6 Y 30.4 >=30 148.6 67.1 8 2009-07-26 42.0
DURDSGR1 VISIT1DT RFSTDTC RFENDTC VISNUMEN RFENDT
1 >=12 2013-12-26 2014-01-02 2014-07-02 12 2014-07-02
2 >=12 2012-07-22 2012-08-05 2012-09-02 5 2012-09-02
3 >=12 2013-07-11 2013-07-19 2014-01-14 12 2014-01-14
4 >=12 2014-03-10 2014-03-18 2014-04-14 5 2014-04-14
5 >=12 2014-06-24 2014-07-01 2014-12-30 12 2014-12-30
6 >=12 2013-01-22 2013-02-12 2013-03-29 6 2013-03-29
DCDECOD DCREASCD MMSETOT
1 COMPLETED Completed 23
2 ADVERSE EVENT Adverse Event 23
3 COMPLETED Completed 23
4 STUDY TERMINATED BY SPONSOR Sponsor Decision 23
5 COMPLETED Completed 21
6 ADVERSE EVENT Adverse Event 23
팁 : 대소문자가 확실하지 않을 때는 casefold(EFFFL, upper=TRUE) == "Y"와 같이 처리하는 것이 안전합니다.
주변 합계(Marginal Totals, N) 산출 - 각 치료군별 대상자 수 계산.
백분율 계산의 분모가 될 큰 N을 산출합니다. group_by()와 count()를 사용합니다.
SAS 사용자를 위한 팁 : group_by()는 SAS의 BY 문과 유사하게 작동합니다. 이후의 모든 작업은 그룹별로 수행됩니다.
%>% group_by (TRT01A) %>% count (name = "N" )
# A tibble: 3 × 2
# Groups: TRT01A [3]
TRT01A N
<chr> <int>
1 Placebo 79
2 Xanomeline High Dose 74
3 Xanomeline Low Dose 81
정렬을 위해 TRT01AN(숫자)과 TRT01A(레이블)를 함께 그룹화하는 것이 유용합니다.
<- adsl_eff %>% group_by (TRT01AN, TRT01A) %>% count (name = "N" )head (Big_N_cnt)
# A tibble: 3 × 3
# Groups: TRT01AN, TRT01A [3]
TRT01AN TRT01A N
<dbl> <chr> <int>
1 0 Placebo 79
2 54 Xanomeline Low Dose 81
3 81 Xanomeline High Dose 74
치료군 내 성별(SEX) 빈도(small n) 산출.
그룹화 변수에 SEX를 추가합니다.
<- adsl_eff %>% group_by (TRT01AN, TRT01A, SEX) %>% count (name = "n" )head (small_n_cnt)
# A tibble: 6 × 4
# Groups: TRT01AN, TRT01A, SEX [6]
TRT01AN TRT01A SEX n
<dbl> <chr> <chr> <int>
1 0 Placebo F 46
2 0 Placebo M 33
3 54 Xanomeline Low Dose F 47
4 54 Xanomeline Low Dose M 34
5 81 Xanomeline High Dose F 35
6 81 Xanomeline High Dose M 39
백분율 계산을 위한 데이터 병합.
left_join()을 사용하여 빈도 데이터(small_n_cnt)와 합계 데이터(Big_N_cnt)를 결합합니다. SQL의 JOIN과 유사합니다.
<- small_n_cnt %>% left_join (Big_N_cnt, by = c ("TRT01A" , "TRT01AN" ))head (adsl_mrg_cnt)
# A tibble: 6 × 5
# Groups: TRT01AN, TRT01A, SEX [6]
TRT01AN TRT01A SEX n N
<dbl> <chr> <chr> <int> <int>
1 0 Placebo F 46 79
2 0 Placebo M 33 79
3 54 Xanomeline Low Dose F 47 81
4 54 Xanomeline Low Dose M 34 81
5 81 Xanomeline High Dose F 35 74
6 81 Xanomeline High Dose M 39 74
백분율 산출.
mutate() 함수로 새로운 열 perc를 만듭니다.
%>% mutate (perc = (n/ N)* 100 )
# A tibble: 6 × 6
# Groups: TRT01AN, TRT01A, SEX [6]
TRT01AN TRT01A SEX n N perc
<dbl> <chr> <chr> <int> <int> <dbl>
1 0 Placebo F 46 79 58.2
2 0 Placebo M 33 79 41.8
3 54 Xanomeline Low Dose F 47 81 58.0
4 54 Xanomeline Low Dose M 34 81 42.0
5 81 Xanomeline High Dose F 35 74 47.3
6 81 Xanomeline High Dose M 39 74 52.7
소수점 반올림.
round() 함수를 사용합니다.
주의 : R의 round()는 ‘Round to Even’ 방식을 따르므로 SAS와 결과가 다를 수 있습니다. 정밀한 비교가 필요한 경우 주의하세요.
%>% mutate (perc = round ((n/ N)* 100 , digits= 1 ))
# A tibble: 6 × 6
# Groups: TRT01AN, TRT01A, SEX [6]
TRT01AN TRT01A SEX n N perc
<dbl> <chr> <chr> <int> <int> <dbl>
1 0 Placebo F 46 79 58.2
2 0 Placebo M 33 79 41.8
3 54 Xanomeline Low Dose F 47 81 58
4 54 Xanomeline Low Dose M 34 81 42
5 81 Xanomeline High Dose F 35 74 47.3
6 81 Xanomeline High Dose M 39 74 52.7
수치 데이터 서식 지정.
표에 표시할 때 “20.0”과 같이 일관된 소수점 자릿수를 보여주기 위해 format(nsmall=1)을 사용합니다. 수치 데이터가 문자(character) 타입으로 변환됩니다.
%>% mutate (perc = round ((n/ N)* 100 , digits= 1 )) %>% mutate (perc_char = format (perc, nsmall= 1 ))
# A tibble: 6 × 7
# Groups: TRT01AN, TRT01A, SEX [6]
TRT01AN TRT01A SEX n N perc perc_char
<dbl> <chr> <chr> <int> <int> <dbl> <chr>
1 0 Placebo F 46 79 58.2 58.2
2 0 Placebo M 33 79 41.8 41.8
3 54 Xanomeline Low Dose F 47 81 58 58.0
4 54 Xanomeline Low Dose M 34 81 42 42.0
5 81 Xanomeline High Dose F 35 74 47.3 47.3
6 81 Xanomeline High Dose M 39 74 52.7 52.7
빈도와 백분율 합치기.
paste() 또는 paste0()를 사용하여 “n (perc%)” 형식을 만듭니다.
%>% mutate (perc = round ((n/ N)* 100 , digits= 1 )) %>% mutate (perc_char = format (perc, nsmall= 1 )) %>% mutate (npct = paste (n, paste0 ("(" , perc_char, ")" )))
# A tibble: 6 × 8
# Groups: TRT01AN, TRT01A, SEX [6]
TRT01AN TRT01A SEX n N perc perc_char npct
<dbl> <chr> <chr> <int> <int> <dbl> <chr> <chr>
1 0 Placebo F 46 79 58.2 58.2 46 (58.2)
2 0 Placebo M 33 79 41.8 41.8 33 (41.8)
3 54 Xanomeline Low Dose F 47 81 58 58.0 47 (58.0)
4 54 Xanomeline Low Dose M 34 81 42 42.0 34 (42.0)
5 81 Xanomeline High Dose F 35 74 47.3 47.3 35 (47.3)
6 81 Xanomeline High Dose M 39 74 52.7 52.7 39 (52.7)
성별 레이블 재코딩.
“M”, “F”를 “Male”, “Female”로 변경합니다. recode() 함수를 활용합니다.
%>% mutate (perc = round ((n/ N)* 100 , digits= 1 )) %>% mutate (perc_char = format (perc, nsmall= 1 )) %>% mutate (npct = paste (n, paste0 ("(" , perc_char, ")" ))) %>% mutate (SEX = recode (SEX, "M" = "Male" , "F" = "Female" ))
# A tibble: 6 × 8
# Groups: TRT01AN, TRT01A, SEX [6]
TRT01AN TRT01A SEX n N perc perc_char npct
<dbl> <chr> <chr> <int> <int> <dbl> <chr> <chr>
1 0 Placebo Female 46 79 58.2 58.2 46 (58.2)
2 0 Placebo Male 33 79 41.8 41.8 33 (41.8)
3 54 Xanomeline Low Dose Female 47 81 58 58.0 47 (58.0)
4 54 Xanomeline Low Dose Male 34 81 42 42.0 34 (42.0)
5 81 Xanomeline High Dose Female 35 74 47.3 47.3 35 (47.3)
6 81 Xanomeline High Dose Male 39 74 52.7 52.7 39 (52.7)
그룹 해제.
이후 작업에 영향을 주지 않도록 ungroup()을 수행합니다.
%>% ungroup ()
# A tibble: 6 × 5
TRT01AN TRT01A SEX n N
<dbl> <chr> <chr> <int> <int>
1 0 Placebo F 46 79
2 0 Placebo M 33 79
3 54 Xanomeline Low Dose F 47 81
4 54 Xanomeline Low Dose M 34 81
5 81 Xanomeline High Dose F 35 74
6 81 Xanomeline High Dose M 39 74
파이프를 이용한 워크플로 통합.
위의 모든 과정을 하나의 파이프라인으로 연결합니다.
<- small_n_cnt %>% left_join (Big_N_cnt, by = c ("TRT01A" , "TRT01AN" )) %>% mutate (perc = round (n/ N* 100 , digits= 1 )) %>% mutate (perc_char = format (perc, nsmall= 1 )) %>% mutate (npct = paste (n, paste0 ("(" , perc_char, ")" ))) %>% mutate (SEX = recode (SEX, "M" = "Male" , "F" = "Female" )) %>% ungroup () %>% select (TRT01A, SEX, npct)head (adsl_mrg_cnt)
# A tibble: 6 × 3
TRT01A SEX npct
<chr> <chr> <chr>
1 Placebo Female 46 (58.2)
2 Placebo Male 33 (41.8)
3 Xanomeline Low Dose Female 47 (58.0)
4 Xanomeline Low Dose Male 34 (42.0)
5 Xanomeline High Dose Female 35 (47.3)
6 Xanomeline High Dose Male 39 (52.7)
데이터 전치 (Wide Format).
표 형식에 맞게 pivot_wider()를 사용하여 데이터를 펼칩니다.
%>% pivot_wider (names_from = TRT01A, values_from = npct)
# A tibble: 2 × 4
SEX Placebo `Xanomeline Low Dose` `Xanomeline High Dose`
<chr> <chr> <chr> <chr>
1 Female 46 (58.2) 47 (58.0) 35 (47.3)
2 Male 33 (41.8) 34 (42.0) 39 (52.7)
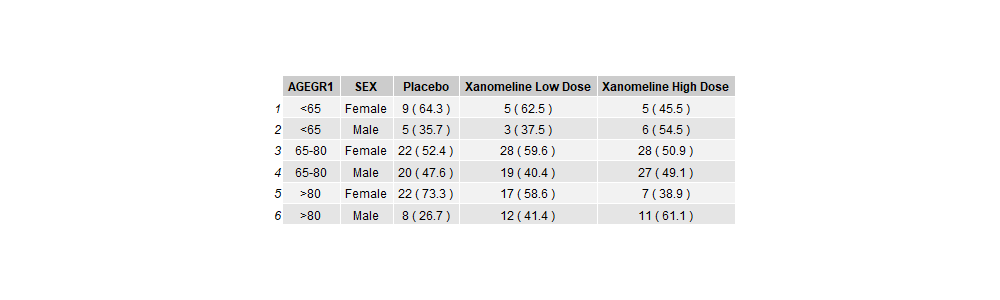
챌린지 1: 연령 그룹(AGEGRP) 추가
위 단계를 반복하되, 그룹화 변수에 AGEGR1을 추가하여 분석해 보세요.
챌린지 2: 이상반응 데이터(adae.xpt) 활용
adae.xpt 데이터를 읽어와 안전성 분석 대상군(SAFFL)에 대한 신체기관별 이상반응(AEBODSYS) 빈도와 백분율을 산출해 보세요.