4 모델 성능 평가
이 장에서는 예측 모델에서 오차의 방법론적 측면, 교차 검증(cross-validation) 데이터를 통해 오차를 측정하는 방법, 그리고 부트스트래핑(bootstrapping) 기법과의 유사성을 다룹니다. 또한 이러한 전략들이 _랜덤 포레스트(random forest)_나 _그레디언트 부스팅 머신(gradient boosting machines)_과 같은 일부 예측 모델 내부에서 어떻게 사용되는지 살펴봅니다.
또한 시간이 포함된 모델을 검증하는 방법에 대한 내용도 포함되어 있는데, 이는 전통적인 훈련/테스트(train/test) 검증과 유사합니다.
4.1 오차 알기
모델 검증의 방법론적 측면

4.1.1 무엇에 대한 내용인가요?
예측 모델을 구축한 후, 그 품질에 대해 얼마나 확신할 수 있을까요? 모델이 (노이즈를 제외한) 일반적인 패턴(정보)을 잘 포착했을까요?
4.1.1.1 어떤 종류의 데이터인가요?
이 접근 방식은 시간 외 검증(Out-of-Time Validation)에서 다루는 방식과는 다릅니다. 이 방식은 날짜별로 사례를 필터링할 수 없는 경우, 예를 들어 더 이상 새로운 정보가 생성되지 않는 특정 시점의 데이터 스냅샷을 가지고 있는 경우에도 사용할 수 있습니다.
예를 들어 소수의 인원을 대상으로 한 건강 데이터 연구, 설문 조사 또는 연습 목적으로 인터넷에서 사용할 수 있는 일부 데이터 등이 있습니다. 새로운 사례를 추가하는 것이 비용이 많이 들거나, 실용적이지 않거나, 비윤리적이거나, 심지어 불가능할 수도 있습니다. funModeling 패키지에 포함된 heart_disease 데이터가 그러한 예입니다.
4.1.2 예상치 못한 동작 줄이기
모델이 훈련될 때, 그것은 실체의 일부분만을 봅니다. 그것은 전체를 다 볼 수 없는 모집단의 샘플입니다.
모델을 검증하는 방법에는 여러 가지가 있습니다 (정확도 / ROC 곡선 / 리프트 / 이득 등). 이러한 지표들은 모두 분산에 부수적이며, 이는 서로 다른 값을 얻게 됨을 의미합니다. 일부 사례를 제거한 다음 새로운 모델을 맞춤(fit)시키면, 약간 다른 값을 보게 될 것입니다.
정확도 81을 달성한 모델을 구축했다고 가정해 봅시다. 이제 사례의 10%를 제거하고 새로운 모델을 맞춤시키면, 정확도는 78.4가 됩니다. 진짜 정확도는 무엇일까요? 100% 데이터를 사용하여 얻은 것일까요, 아니면 90%를 기반으로 한 다른 것일까요? 예를 들어, 모델이 운영 체제(production environment)에서 실시간으로 실행된다면 다른 사례들을 보게 될 것이고 정확도 지점은 새로운 지점으로 이동할 것입니다.
그렇다면 실제 값은 무엇일까요? 보고해야 할 값은요? 재샘플링(Re-sampling)과 교차 검증(cross-validation) 기술은 가장 신뢰할 수 있는 값에 가까운 근사치를 얻기 위해 서로 다른 샘플링 및 테스트 기준을 기반으로 평균을 낼 것입니다.
그런데 왜 사례를 제거하나요?
그렇게 사례를 제거하는 것은 의미가 없어 보일 수 있지만, 정확도 지표가 얼마나 민감한지에 대한 아이디어를 제공합니다. 우리는 알 수 없는 모집단으로부터 추출된 샘플을 가지고 작업하고 있다는 점을 기억하십시오.
만약 우리가 연구하고 있는 모든 사례의 100%를 포함하는 완전한 결정론적 모델이 있고 모든 사례에서 100% 정확하게 예측했다면, 이 모든 것이 필요하지 않았을 것입니다.
우리는 항상 샘플을 분석하기 때문에 반복, 재샘플링, 교차 검증 등을 통해 데이터의 _실제적이고 알려지지 않은 진실성_에 더 가까워져야 할 뿐입니다…
4.1.3 교차 검증(Cross-Validation, CV)으로 설명해 보겠습니다
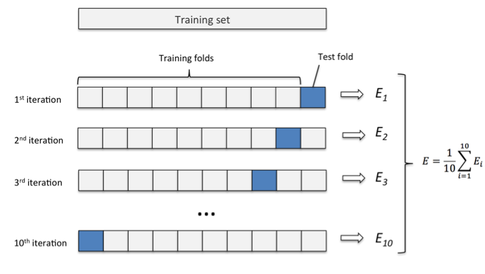
Figure 4.1: k-폴드 교차 검증
이미지 출처: Sebastian Raschka 참고 (Raschka 2017)
4.1.3.1 CV 요약
- 데이터를 똑같은 크기의 무작위 그룹(예:
10개)으로 나눕니다. 이러한 그룹을 흔히'k'라는 글자로 표현되는폴드(fold)라고 부릅니다. 9개의 폴드를 선택하여 모델을 구축한 다음, 제외된 나머지 폴드에 모델을 적용합니다. 이를 통해 정확도, ROC, Kappa 등 원하는 성능 지표를 얻게 됩니다. 이 예제에서는 정확도를 사용하고 있습니다.- 이 과정을
k번(이 예제에서는10번) 반복합니다. 그러면10개의 서로 다른 정확도를 얻게 됩니다. 최종 결과는 이들의 평균이 됩니다.
이 평균값은 모델이 좋은지 아닌지를 평가하는 기준이 되며, 보고서에도 포함될 수 있습니다.
4.1.3.2 실전 사례
iris 데이터 프레임에는 150개의 행이 있습니다. caret 패키지를 사용하여 교차 검증으로 랜덤 포레스트를 구축하면 내부적으로 10개의 랜덤 포레스트가 생성됩니다. 각 모델은 135개의 행(9/10 * 150)을 기반으로 구축되고, 나머지 15개(1/10 * 150)의 사례를 기반으로 정확도를 보고합니다. 이 절차는 10번 반복됩니다.
출력의 이 부분:
Figure 4.2: caret 교차 검증 출력
Summary of sample sizes: 135, 135, 135, 135, 135, 135, ...에서 각 135는 훈련 샘플을 나타냅니다. 총 10개가 있지만 출력은 잘렸습니다.
단일 숫자(평균)보다는 분포를 볼 수 있습니다:
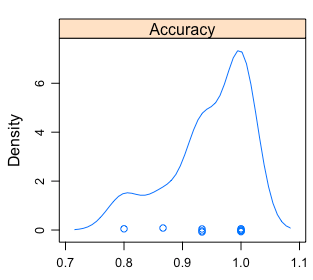
Figure 4.3: 정확도 분포의 시각적 분석

Figure 4.4: 정확도 분포
- 최소/최대 정확도는
~0.8에서~1사이가 될 것입니다. - 평균은
caret에 의해 보고된 값입니다. - 50%의 확률로 정확도는
~0.93에서~1사이에 위치할 것입니다.
forecast 패키지의 개발자인 Rob Hyndman의 추천 강의: 왜 모든 통계학자가 교차 검증에 대해 알아야 하는가? (Hyndman 2010)
4.1.4 그렇다면 오차란 무엇인가요?
데이터의 편향(Bias), 분산(Variance), 그리고 설명되지 않는 오차(inner noise)(또는 모델이 결코 줄일 수 없는 것)의 합입니다.
이 세 가지 요소가 보고된 오차를 나타냅니다.
4.1.4.1 편향(Bias)과 분산(Variance)의 성질은 무엇인가요?
모델이 제대로 작동하지 않을 때는 여러 가지 원인이 있을 수 있습니다:
- 모델이 너무 복잡함: 입력 변수가 아주 많을 때이며, 이는 높은 분산과 관련이 있습니다. 모델은 훈련 데이터에 과적합(overfit)되어, 보지 못한 데이터에 대해서는 과도한 세분화로 인해 정확도가 떨어지게 됩니다.
- 모델이 너무 단순함: 반대로, 모델이 너무 단순해서 데이터의 모든 정보를 포착하지 못할 수도 있습니다. 이는 높은 편향과 관련이 있습니다.
- 입력 데이터가 충분하지 않음: 데이터는 n차원 공간(
n은 모든 입력+타겟 변수)에서 형태를 형성합니다. 점이 충분하지 않으면 이 형태가 제대로 만들어지지 않습니다.
“머신러닝에서 더 좋은 것: 더 많은 데이터인가, 더 좋은 알고리즘인가” (Amatriain 2015)에서 더 많은 정보를 확인하세요.
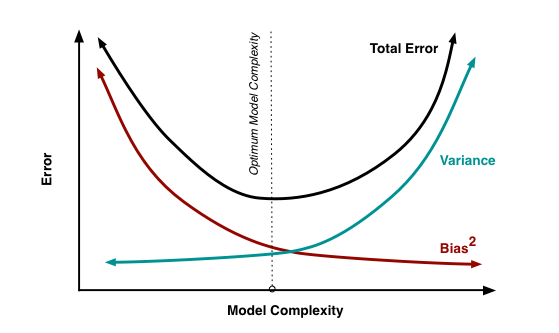
Figure 4.5: 편향 vs. 분산 타협(tradeoff)
이미지 출처: Scott Fortmann-Roe (Fortmann 2012). 애니메이션을 통해 편향과 분산을 통한 오차를 직관적으로 이해할 수 있는 방법도 포함되어 있습니다.
4.1.4.2 복잡도 vs 정확도 타협 (Tradeoff)

편향과 분산은 하나가 내려가면 다른 하나가 올라가는 관계이므로 둘 사이에는 타협(tradeoff)이 존재합니다. 이에 대한 실전 사례로는 아카이케 정보 기준(Akaike Information Criterion, AIC) 모델 품질 측정법이 있습니다.
AIC는 R의 forecast 패키지에 있는 auto.arima 함수에서 최적의 시계열 모델을 선택하는 휴리스틱으로 사용됩니다 (Hyndman 2017). AIC가 가장 낮은 모델을 선택합니다.
값이 낮을수록 좋습니다. 예측 정확도가 높을수록 값은 낮아지지만, 매개변수의 수가 많아지면 값이 높아집니다.
4.1.4.3 부트스트래핑(Bootstrapping) vs 교차 검증(Cross-Validation)
- 부트스트래핑은 주로 매개변수를 추정할 때 사용됩니다.
- 교차 검증은 서로 다른 예측 모델 중에서 선택할 때 주로 사용됩니다.
참고: 편향과 분산에 대해 더 자세히 알고 싶다면 페이지 하단의 (Fortmann 2012) 및 (Amatriain 2015)를 참조하십시오.
4.1.5 실무에 대한 제언이 있나요?
데이터에 따라 다르지만, 10-폴드 CV에 반복을 추가한 10-폴드 CV, 5회 반복과 같은 예시를 흔히 볼 수 있습니다. 때로는 5-폴드 CV, 3회 반복도 사용됩니다.
그리고 원하는 지표의 평균값을 사용합니다. 불균형한 타겟 변수에 대해 덜 편향된 ROC를 사용하는 것도 권장됩니다.
이러한 검증 기법은 시간이 많이 소요되므로, “짧은” 시간 내에 모델 튜닝, 다양한 설정 테스트, 여러 변수 시도 등이 가능하도록 빠르게 실행되는 모델을 선택하는 것을 고려해 보십시오. 랜덤 포레스트(Random Forest)는 빠르고 정확한 결과를 제공하는 훌륭한 옵션입니다. 랜덤 포레스트의 전반적인 성능에 대한 자세한 내용은 (Fernandez-Delgado 2014)에서 확인할 수 있습니다.
또 다른 좋은 옵션은 그레디언트 부스팅 머신(gradient boosting machines)입니다. 랜덤 포레스트보다 튜닝할 매개변수가 더 많지만, 적어도 R에서는 구현이 빠르게 작동합니다.
4.1.5.1 다시 편향과 분산으로 돌아가서
- 랜덤 포레스트는 편향을 줄이는 데 집중하는 반면…
- 그레디언트 부스팅 머신은 분산을 최소화하는 데 집중합니다. 더 많은 정보는 “Gradient boosting machine vs random forest” (stats.stackexchange.com 2015)에서 확인하세요.
4.1.6 잊지 마세요: 데이터 준비
데이터를 변환하고 정제하여 입력 데이터를 미세하게 조정하는 것은 모델의 품질에 영향을 미칩니다. 때로는 매개변수를 통해 모델을 최적화하는 것보다 더 큰 영향을 미칩니다.
이 점에 대해서는 데이터 준비(Data Preparation) 장에서 자세히 알아보세요.
4.1.7 마지막 생각
- 재샘플링 / 교차 검증을 통해 모델을 검증하는 것은 데이터에 존재하는 “실제” 오차를 추정하는 데 도움이 됩니다. 모델이 향후에 실행된다면, 그것이 예상되는 오차가 될 것입니다.
- 또 다른 장점은 모델 튜닝으로, 특정 모델에 대한 최적의 매개변수를 선택할 때 과적합을 피할 수 있습니다 (caret 예시). Python에서의 해당 내용은 Scikit Learn에 포함되어 있습니다.
- 가장 좋은 테스트는 여러분의 데이터와 요구 사항에 맞게 여러분이 직접 만든 테스트입니다. 다양한 모델을 시도해 보고 시간 소요와 정확도 지표 사이의 타협점을 분석해 보십시오.
이러한 재샘플링 기술은 stackoverflow.com과 같은 사이트나 협력적인 오픈 소스 소프트웨어 뒤에 있는 강력한 도구 중 하나일 수 있습니다. 편향이 적은 솔루션을 만들기 위해 많은 의견을 수렴하는 것이죠.
하지만 각 의견은 신뢰할 수 있어야 합니다. 여러 의사에게 진단을 요청하는 상황을 상상해 보십시오.
4.1.8 더 읽어보기
- 튜토리얼: R을 사용한 예측 분석을 위한 교차 검증
- Max Kuhn(caret 패키지 제작자)의 튜토리얼: 다양한 종류의 교차 검증 비교하기
- 교차 검증 접근 방식은 시간 의존적 모델에도 적용될 수 있습니다. 다른 장인 시간 외 검증(Out-of-time Validation)을 확인해 보세요.
![]()
4.2 시간 외 검증 (Out-of-Time Validation)

4.2.1 무엇에 대한 내용인가요?
예측 모델을 구축한 후, 그것이 단지 보았던 데이터만을 기억하는 것이 아니라(과적합) 일반적인 패턴을 잘 포착했는지 어떻게 확신할 수 있을까요?
운영 환경에서 실행되거나 실시간으로 작동할 때 모델이 잘 작동할까요? 예상되는 오차는 얼마일까요?
4.2.2 어떤 종류의 데이터인가요?
데이터가 시간에 따라 생성되고, 매일 “웹사이트 페이지 방문”이나 “의료 센터에 도착하는 새로운 환자”와 같은 새로운 사례가 발생한다면, 가장 강력한 검증 방법 중 하나는 시간 외(Out-Of-Time) 접근 방식입니다.
4.2.3 시간 외 검증 예시
방법은?
우리가 1월 1일에 모델을 구축하고 있다고 가정해 봅시다. 모델을 구축하기 위해 10월 31일 이전의 모든 데이터를 사용합니다. 이 두 날짜 사이에는 2개월의 간격이 있습니다.
이진/두 클래스 변수(또는 다중 클래스)를 예측할 때, 이는 매우 명확합니다: 10월 31일 이전의 데이터로 구축한 모델을 사용하여 그 정확한 날짜의 데이터에 점수(score)를 매기고, 그 후 두 달 동안 사용자/환자/개인/사례들이 어떻게 변했는지 측정합니다.
이진 모델의 출력은 각 사례가 특정 클래스에 속할 가능성을 나타내는 숫자여야 하므로(데이터 스코어링 장 참조), 우리는 10월 31일에 모델이 “말한” 것과 “1월 1일”에 실제로 일어난 일을 비교하여 테스트합니다.
다음 검증 워크플로우는 시간이 포함된 예측 모델을 구축할 때 도움이 될 수 있습니다.
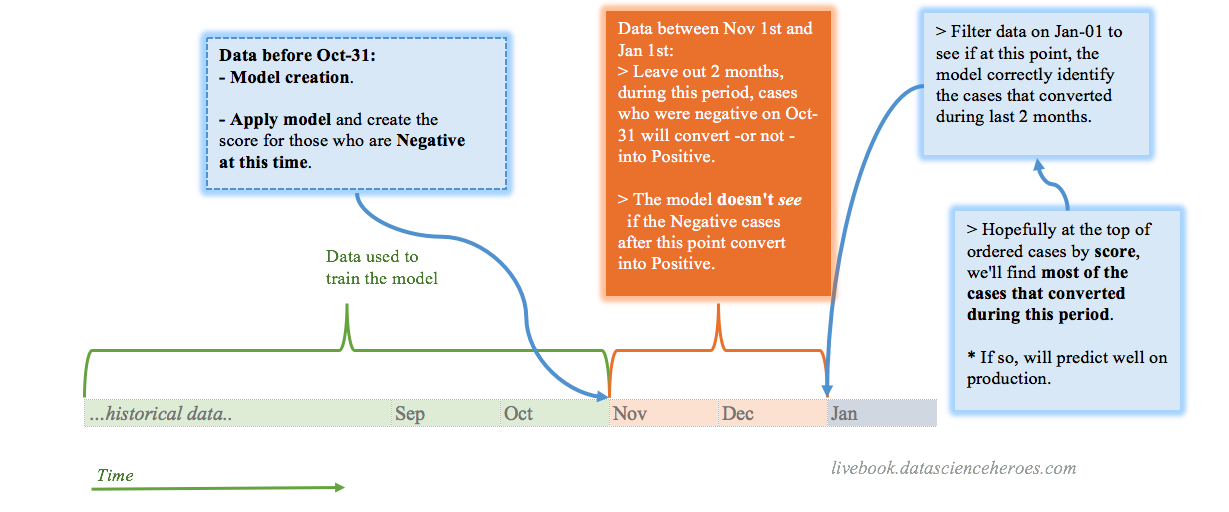
Figure 4.6: 시간 의존적 문제를 위한 검증 워크플로우
{kind=link}
4.2.4 이득 및 리프트 분석(Gain and Lift Analysis) 사용하기
이 분석은 다른 장(이득 및 리프트)에서 설명되며, 시간 외 검증에 이어서 사용할 수 있습니다.
10월 31일에 음성(negative)이었던 사례들만 유지하면서, 해당 날짜에 모델이 반환한 점수(score)를 얻고, 타겟(target) 변수는 1월 1일에 해당 사례들이 가졌던 값으로 설정합니다.
4.2.5 수치형 타겟 변수는 어떤가요?
이제 상식과 비즈니스 요구 사항이 더 중요해집니다. 수치형 결과는 어떤 값도 가질 수 있으며, 시간에 따라 증가하거나 감소할 수 있습니다. 따라서 무엇을 성공으로 간주할지 생각하는 데 도움이 되도록 이 두 가지 시나리오를 고려해야 할 수도 있습니다. 이것이 선형 회귀의 경우입니다.
시나리오 예시: 웹 앱 사용량(예: 홈뱅킹)을 측정한다고 했을 때, 일반적인 특징은 날짜가 지남에 따라 사용자가 더 많이 사용한다는 것입니다.
예시:
- 특정 성분의 혈중 농도 예측.
- 페이지 방문 수 예측.
- 시계열 분석.
이러한 경우에도 “예상했던 것” vs. “실제인 것” 사이의 차이가 발생합니다.
이 차이는 어떤 숫자든 될 수 있습니다. 이것이 오차(error) 또는 잔차(residuals)입니다.

Figure 4.7: 예측 및 오차 분석
모델이 좋다면, 이 오차는 백색 잡음(white noise)이어야 합니다. (Wikipedia 2017d) 내부의 “시계열 분석 및 회귀” 섹션에서 더 자세한 정보를 확인하세요. 주로 다음과 같은 논리적 특성이 있을 때 정규 곡선을 따릅니다:
- 오차는 0 주변에 있어야 합니다. 모델의 오차는 0으로 수렴해야 합니다.
- 이 오차의 표준 편차는 유한해야 합니다. 예측 불가능한 이상치를 피하기 위함입니다.
- 오차들 사이에는 상관관계가 없어야 합니다.
- 정규 분포: 대부분의 오차가 0 주변에 있고, 오차가 커질수록 더 작은 비율로 나타날 것을 기대합니다. 즉, 더 큰 오차를 발견할 가능성은 기하급수적으로 감소합니다.
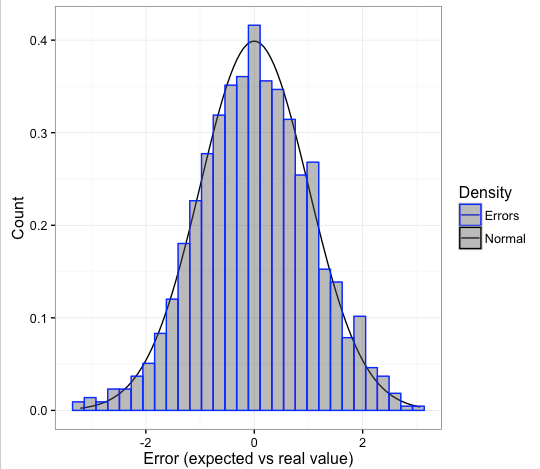
Figure 4.8: 좋은 오차 곡선 (정규 분포)
4.2.6 마지막 생각
시간 외 검증(Out-of-Time Validation)은 샘플링에 의존할 필요가 없는 데이터를 사용하여 운영 환경에서의 모델 실행을 시뮬레이션할 수 있는 강력한 검증 도구입니다.
오차 분석은 데이터 과학에서 큰 단원입니다. 이제 이와 관련된 핵심 개념을 다루는 다음 장으로 넘어갈 시간입니다: 오차 알기.
![]()
4.3 이득 및 리프트 분석 (Gain and Lift Analysis)
4.3.1 무엇에 대한 내용인가요?
두 지표 모두 예측 모델(이진 결과)의 품질을 검증하는 데 매우 유용합니다. 데이터 스코어링에 대한 더 많은 정보를 확인하세요.
최신 버전의 funModeling(>= 1.3)이 설치되어 있는지 확인하십시오.
# GLM 모델 생성
fit_glm = glm(has_heart_disease ~ age + oldpeak, data = heart_disease, family = binomial)
# 각 행의 스코어/확률값 가져오기
heart_disease$score = predict(fit_glm, newdata = heart_disease, type = 'response')
# 이득 및 리프트 곡선 그리기
gain_lift(data = heart_disease, score = 'score', target = 'has_heart_disease')## Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
## of ggplot2 3.3.4.
## ℹ The deprecated feature was likely used in the funModeling package.
## Please report the issue at <https://github.com/pablo14/funModeling/issues>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.## Warning: The `guide` argument in `scale_*()` cannot be `FALSE`. This was deprecated in
## ggplot2 3.3.4.
## ℹ Please use "none" instead.
## ℹ The deprecated feature was likely used in the funModeling package.
## Please report the issue at <https://github.com/pablo14/funModeling/issues>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.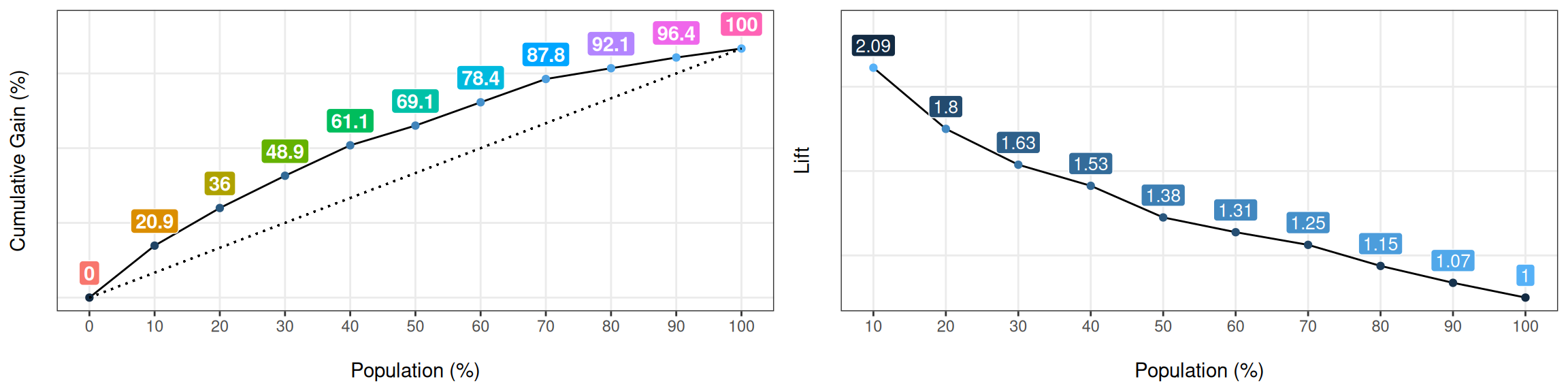
Figure 4.9: 이득 및 리프트 곡선
## Population Gain Lift Score.Point
## 1 10 20.86 2.09 0.8185793
## 2 20 35.97 1.80 0.6967124
## 3 30 48.92 1.63 0.5657817
## 4 40 61.15 1.53 0.4901940
## 5 50 69.06 1.38 0.4033640
## 6 60 78.42 1.31 0.3344170
## 7 70 87.77 1.25 0.2939878
## 8 80 92.09 1.15 0.2473671
## 9 90 96.40 1.07 0.1980453
## 10 100 100.00 1.00 0.11955114.3.2 어떻게 해석하나요?
먼저, 각 사례는 점수 값인 덜 대표적인 클래스(less representative class)일 가능성에 따라 정렬됩니다.
그 다음 Gain 열은 각 10%의 행(Population 열)에 대해 양성 클래스를 누적합니다.
따라서 첫 번째 행은 다음과 같이 읽을 수 있습니다:
“점수(score)순으로 정렬된 상위 10%의 인구는 전체 양성 사례의 20.86%를 포함합니다.”
예를 들어, 우리가 이 모델을 기반으로 이메일을 보내고 사용자의 20%에게만 도달할 예산이 있다면, 몇 명의 응답을 기대할 수 있을까요? 정답: 35.97%
4.3.3 모델을 사용하지 않는다면 어떨까요?
만약 우리가 모델을 사용하지 않고 무작위로 20%를 선택한다면, 우리는 몇 명의 사용자에게 도달해야 할까요? 당연히 20%입니다. 이것이 0%에서 시작하여 100%에서 끝나는 점선(dashed line)의 의미입니다. 다행히 예측 모델을 사용하면 무작위성보다 높은 성과를 낼 수 있습니다.
리프트(Lift) 열은 이득(Gain)과 우연에 의한 이득 사이의 비율을 나타냅니다. Population=20%를 예로 들면, 모델은 무작위보다 1.8배 더 좋습니다.
4.3.3.2 모델 비교하기
좋은 모델에서는 이득이 모집단의 “초기”에 100%에 도달하며, 이는 클래스를 잘 분리하고 있음을 나타냅니다.
모델을 비교할 때 빠른 지표는 모집단의 초기(10-30%) 이득이 더 높은지 확인하는 것입니다.
결과적으로, 초기에 더 높은 이득을 가진 모델이 데이터에서 더 많은 정보를 포착한 것이 됩니다.
설명을 위해…
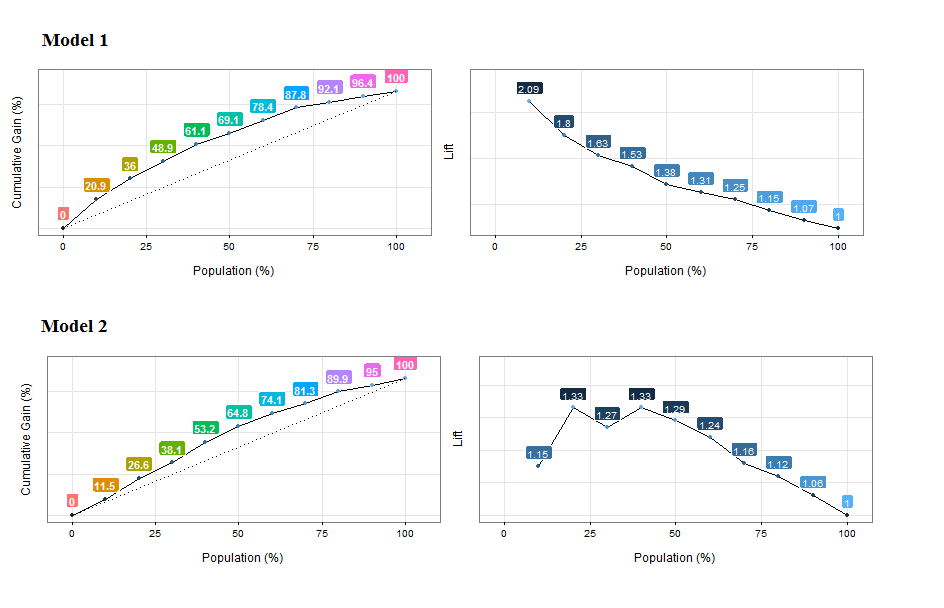
Figure 4.10: 두 모델의 이득 및 리프트 곡선 비교
{kind=link}
누적 이득 분석(Cumulative Gain Analysis): 모델 1은 인구의 약 10% 지점에서 양성 사례의 ~20%에 도달하는 반면, 모델 2는 인구의 20%에 가까워져야 유사한 비율에 도달합니다. 모델 1이 더 좋습니다.
리프트 분석(Lift analysis): 위와 동일하지만, 모든 리프트 숫자가 감소 패턴을 따르지 않는다는 점이 의심스럽습니다. 아마도 모델이 인구의 첫 번째 백분위수들을 제대로 정렬하지 못하고 있는 것일 수 있습니다. cross_plot을 사용한 타겟 프로파일링 장에서 보았던 것과 동일한 정렬 개념입니다.
![]()
4.4 데이터 스코어링 (Scoring Data)
4.4.1 숨겨진 직관
이벤트는 일어날 수도 있고, 일어나지 않을 수도 있습니다. 비록 우리에게 내일의 신문 📰은 없지만, 내일이 어떨지에 대해 좋은 추측을 할 수는 있습니다.

미래는 의심할 여지 없이 불확실성과 맞닿아 있으며, 이 불확실성은 추정될 수 있습니다.
4.4.1.1 그리고 다양한 타겟들이 있습니다…
현재 이 책은 고전적인 예/아니오 타겟(이진 또는 다중 클래스 예측이라고도 함)을 다룹니다.
따라서 이 추정치는 이벤트가 발생할 진실의 값(value of truth)이며, 0과 1 사이의 확률값입니다.
4.4.1.2 이진(Two-label) vs. 다중 클래스(multi-label) 결과
이 장은 이진 결과(두 개의 라벨 결과)를 위해 작성되었지만, 다중 클래스(multi-label) 타겟은 이진 클래스의 일반적인 접근 방식으로 볼 수 있습니다.
예를 들어 4개의 서로 다른 값을 가진 타겟이 있을 때, 특정 클래스에 속할 가능성을 예측하는 4개의 모델이 있을 수 있습니다. 그런 다음 이 4개 모델의 결과를 가져와 최종 클래스를 예측하는 더 상위의 모델이 있을 수 있습니다.
4.4.1.3 뭐라고요? 😯
몇 가지 예시: - 이 고객이 이 제품을 구매할 것인가? - 이 환자가 호전될 것인가? - 향후 몇 주 동안 특정 이벤트가 발생할 것인가?
이 질문들에 대한 대답은 참(True) 또는 거짓(False)이지만, 본질은 스코어(score), 즉 특정 이벤트가 발생할 가능성을 나타내는 숫자를 갖는 것입니다.
4.4.1.4 하지만 우리는 더 많은 통제가 필요합니다…
많은 머신러닝 리소스들은 시작하기에 좋은 단순화된 버전, 즉 최종 클래스를 출력으로 얻는 방식을 보여줍니다. 예를 들어:
단순화된 접근 방식:
- 질문: 이 사람이 심장 질환을 앓게 될까요?
- 답변: “아니오”
하지만 “예/아니오” 답변 이전에 다른 무언가가 있으며, 그것이 바로 스코어입니다:
- 질문: 이 사람이 심장 질환을 앓을 가능성은 얼마나 되나요?
- 답변: “25%”
따라서 우리는 먼저 스코어를 얻고, 우리의 필요에 따라 절단점(cut point)을 설정합니다. 그리고 이것은 정말로 중요합니다.
4.4.2 예제를 살펴봅시다
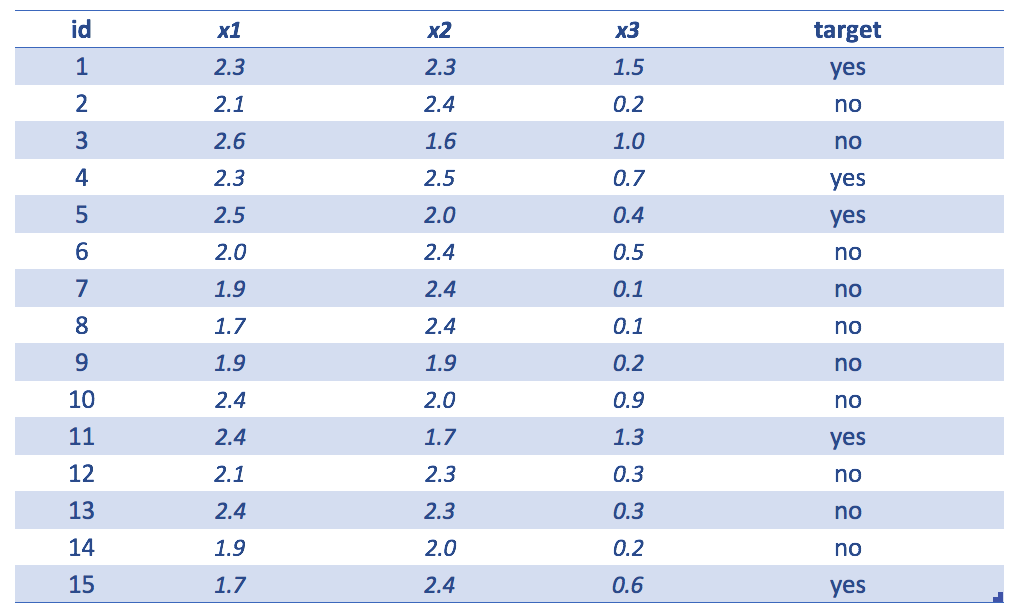
Figure 4.11: 간단한 데이터셋 예시
다음 내용을 보여주는 예제 테이블:
id= 식별자x1,x2,x3= 입력 변수target= 예측할 변수
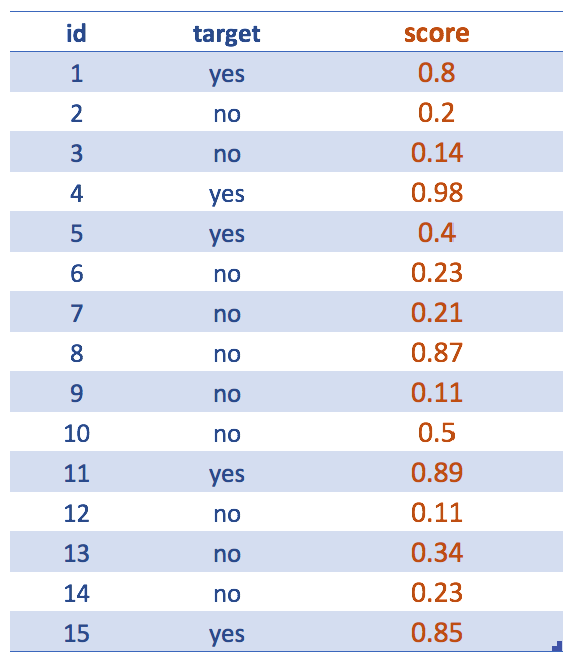
Figure 4.12: 스코어 얻기 (예측 모델 출력)
입력 변수는 잊어버리십시오… 랜덤 포레스트와 같은 예측 모델을 생성한 후, 우리가 관심을 갖는 것은 스코어(scores)입니다. 비록 우리의 최종 목표가 예/아니오로 예측된 변수를 전달하는 것이라 할지라도 말입니다.
예를 들어, 다음 두 문장은 같은 것을 표현합니다: 예일 가능성이 0.8이다 <=> 아니오일 확률이 0.2이다
이미 이해하셨겠지만 스코어는 대개 덜 대표적인 클래스인 예를 나타냅니다.
✋ R 구문 -코드를 보고 싶지 않다면 건너뛰셔도 됩니다-
다음 구문은 스코어를 반환합니다:
score = predict(randomForestModel, data, type = "prob")[, 2]
다른 모델의 경우 이 구문이 약간 다를 수 있지만, 개념은 동일하게 유지된다는 점에 유의하십시오. 다른 언어에서도 마찬가지입니다.
여기서 prob는 우리가 확률(또는 스코어)을 원한다는 것을 나타냅니다.
predict 함수에 type="prob" 매개변수를 더하면 15행 2열의 행렬을 반환합니다: 1열은 아니오일 가능성을 나타내고, 2열은 예 클래스에 대한 가능성을 보여줍니다.
타겟 변수가 아니오 또는 예일 수 있으므로, [, 2]는 (아니오 가능성의 보수인) 예일 가능성을 반환합니다.
4.4.3 모든 것은 절단점(cut point)에 달려 있습니다 📏
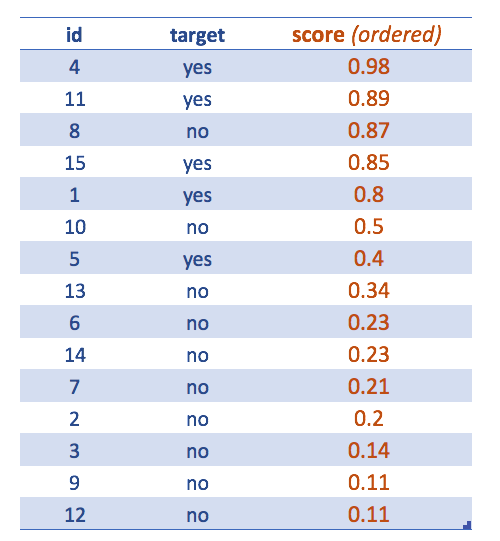
Figure 4.13: 가장 높은 스코어순으로 정렬된 사례들
이제 테이블이 스코어 내림차순으로 정렬되었습니다.
이는 기본적으로 0.5인 절단점을 가졌을 때 최종 클래스를 어떻게 추출하는지 보여주기 위함입니다. 절단점을 미세하게 조정하면 더 나은 분류가 가능합니다.
정확도 지표나 혼동 행렬은 항상 특정 절단점 값과 연결되어 있습니다.
절단점을 할당한 후, 다음과 같은 유명한 분류 결과를 볼 수 있습니다:
- ✅ 진양성 (True Positive, TP): 분류가 양성인 것이 참인 경우, 즉 “모델이 양성(
예) 클래스를 정확하게 맞춤”을 의미합니다. - ✅ 진음성 (True Negative, TN): 위와 동일하지만 음성 클래스(
아니오)의 경우입니다. - ❌ 가양성 (False Positive, FP): 분류가 양성인 것이 거짓인 경우, 즉 “모델이 틀렸고
예라고 예측했지만 결과는아니오임”을 의미합니다. - ❌ 가음성 (False Negative, FN): 위와 동일하지만 음성 클래스의 경우로, “모델이 음성이라고 예측했지만 결과는 양성이었음”, 즉 “모델이
아니오라고 예측했지만 클래스는예였음”을 의미합니다.
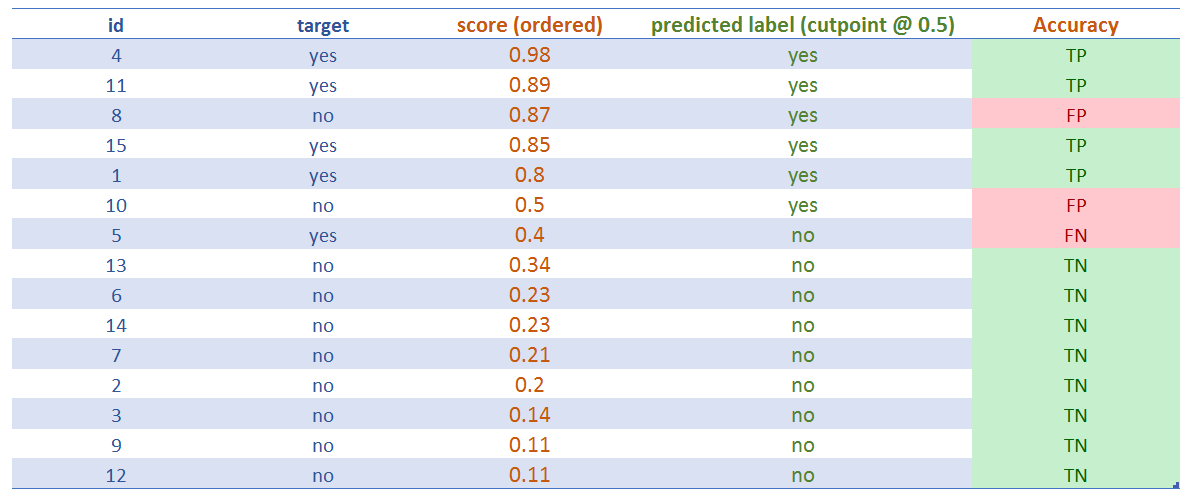
Figure 4.14: 예측 라벨 할당 (cutoff=0.5)
4.4.4 최선과 최악의 시나리오
선(Zen)이 가르치듯 극단을 분석하면 중간 지점을 찾는 데 도움이 됩니다.
👍 최선의 시나리오는 TP와 TN 비율이 100%일 때입니다. 이는 모델이 모든 예와 모든 아니오를 정확하게 예측했음을 의미합니다. (결과적으로 FP와 FN 비율은 0%가 됩니다).
하지만 잠깐만요 ✋! 완벽한 분류를 발견했다면, 그것은 아마도 과적합 때문일 것입니다!
👎 최악의 시나리오 —이전 예시와 정반대— 는 FP와 FN 비율이 100%일 때입니다. 무작위성조차도 이토록 끔찍한 시나리오를 만들어낼 수는 없습니다.
왜 그럴까요? 클래스가 50/50으로 균형 잡혀 있다면 동전을 던져서 결과의 약 절반은 맞힐 것입니다. 이것이 모델이 무작위성보다 우수한지 테스트하는 일반적인 기준선입니다.
제공된 예제에서 클래스 분포는 예가 5개, 아니오가 10개이므로 예는 33.3%(5/15)입니다.
4.4.5 분류기 비교
4.4.5.1 분류 결과 비교
❓ 퀴즈: 이 33.3%를 정확하게 예측하는 모델(TP 비율=100%)은 좋은 모델인가요?
정답: 그것은 모델이 얼마나 많은 예를 예측했는지에 달려 있습니다.
항상 예만 예측하는 분류기는 TP가 100%이지만, 실제로는 아니오인 많은 사례를 예로 분류하므로 전혀 쓸모가 없습니다. 실제로 이런 경우 FP 비율이 매우 높을 것입니다.
4.4.5.2 스코어에 기반한 라벨 정렬 비교
분류기는 신뢰할 수 있어야 하며, 이것이 바로 ROC 곡선이 TP 대 FP 비율을 도표로 나타낼 때 측정하는 것입니다. FP 대비 TP 비율이 높을수록 ROC 곡선 아래 면적(AUC)이 커집니다.
ROC 곡선 뒤에 숨겨진 직관은 스코어와 관련하여 무결성 측정(sanity measure)을 하는 것입니다. 즉, 스코어가 라벨을 얼마나 잘 정렬하느냐 하는 것입니다. 이상적으로는 모든 양성 라벨이 상단에 있고 음성 라벨이 하단에 있어야 합니다.
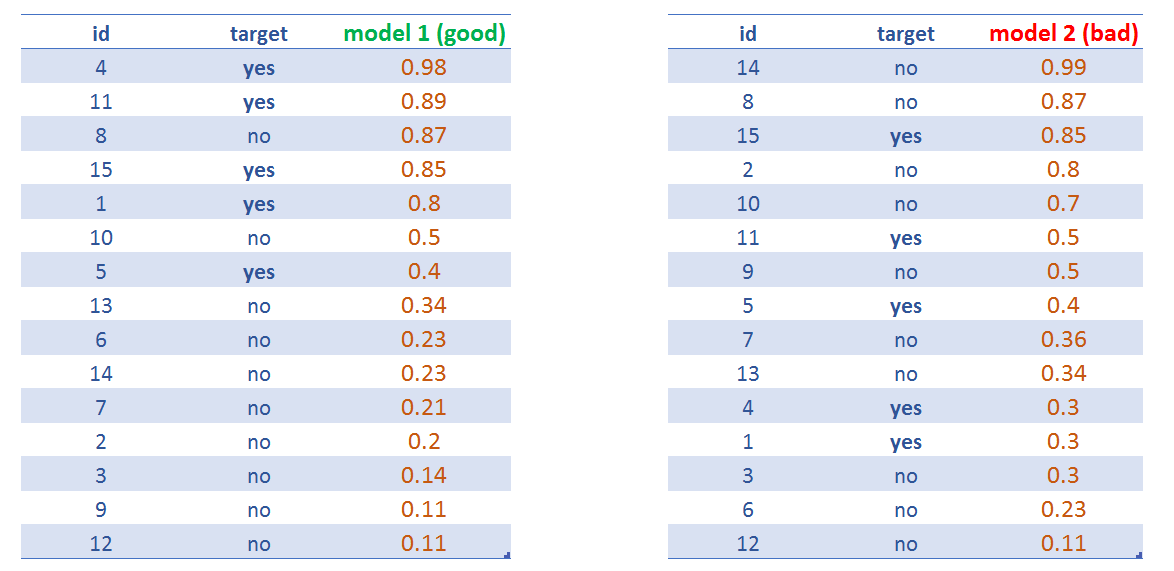
Figure 4.15: 두 예측 모델 스코어 비교
모델 1은 모델 2보다 더 높은 AUC를 가질 것입니다.
위키피디아에 이에 대한 자세하고 유용한 기사가 있습니다: https://en.wikipedia.org/wiki/Receiver_operating_characteristic
다음은 절단점이 0.5일 때 4개 모델을 비교한 것입니다:
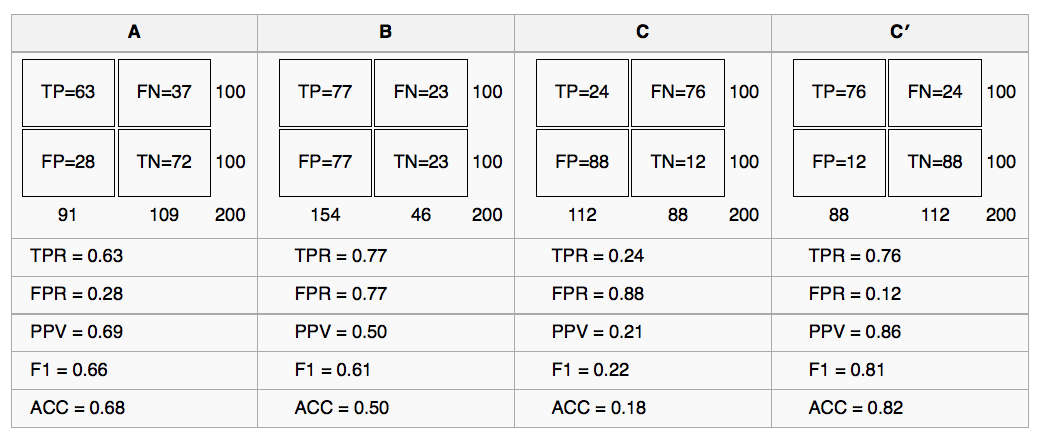
Figure 4.16: 4개 예측 모델 비교
4.4.6 R로 직접 해보기!
서로 다른 절단점에 따른 세 가지 시나리오를 분석해 보겠습니다.
# install.packages("rpivotTable")
# rpivotTable: 피벗 테이블을 동적으로 생성하며 플롯도 지원합니다. 더 많은 정보: https://github.com/smartinsightsfromdata/rpivotTable
library(rpivotTable)
## 데이터 읽기
data=read.delim(file="https://goo.gl/ac5AkG", sep="\t", header = T, stringsAsFactors=F)4.4.6.1 시나리오 1: 절단점 @ 0.5
실제 값 대비 예측 값의 교차점에 몇 개의 사례가 해당하는지 보여주는 고전적인 혼동 행렬:
data$predicted_target=ifelse(data$score>=0.5, "yes", "no")
rpivotTable(data = data, rows = "predicted_target", cols="target", aggregatorName = "Count", rendererName = "Table", width="100%", height="400px")
Figure 4.17: 혼동 행렬 (지표: 개수)
다른 뷰입니다. 이번에는 각 열의 합이 100%입니다. 다음 질문에 답하기 좋습니다:
rpivotTable(data = data, rows = "predicted_target", cols="target", aggregatorName = "Count as Fraction of Columns", rendererName = "Table", width="100%", height="400px")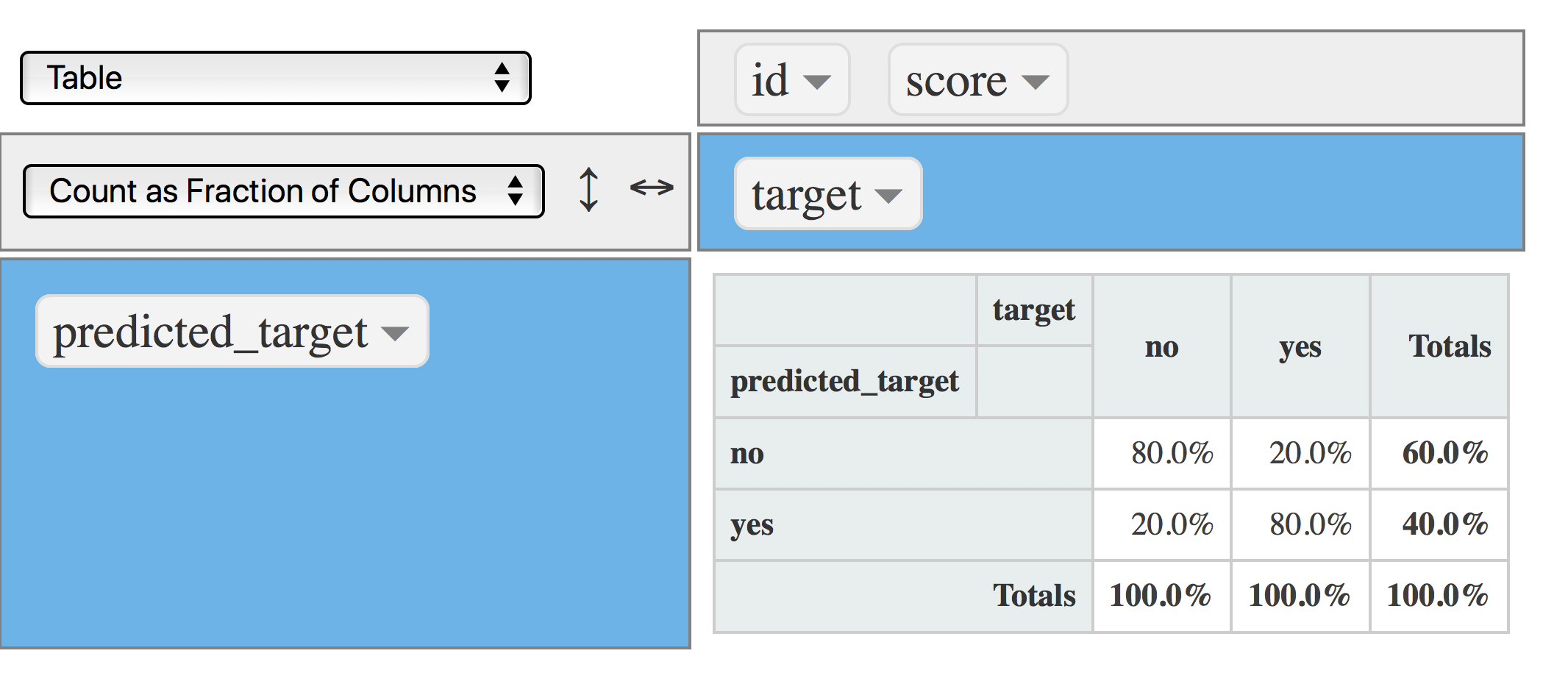
Figure 4.18: 혼동 행렬 (절단점 0.5)
- 모델에 의해 포착된 실제
예값의 비율은 얼마인가요? 정답: 80% 이를 정밀도(Precision, PPV)라고도 합니다. - 모델에 의해 던져진
예중 실제 확률은? 40%.
따라서 마지막 두 문장으로부터:
모델은 10개의 예측 중 4개를 예라고 던지며, 이 세그먼트(예) 중에서 80%를 맞춥니다.
또 다른 뷰: 모델은 10개의 예 예측에 대해 3건의 사례를 정확하게 맞춥니다 (0.4/0.8=3.2, 내림하여 3).
참고: 마지막 분석 방식은 연관 규칙(장바구니 분석) 및 의사결정 트리 모델을 구축할 때 찾아볼 수 있습니다.
4.4.6.2 시나리오 2: 절단점 @ 0.4
절단점을 0.4로 바꿀 때이므로, 예의 양이 더 많아질 것입니다:
data$predicted_target=ifelse(data$score>=0.4, "yes", "no")
rpivotTable(data = data, rows = "predicted_target", cols="target", aggregatorName = "Count as Fraction of Columns", rendererName = "Table", width="100%", height="400px")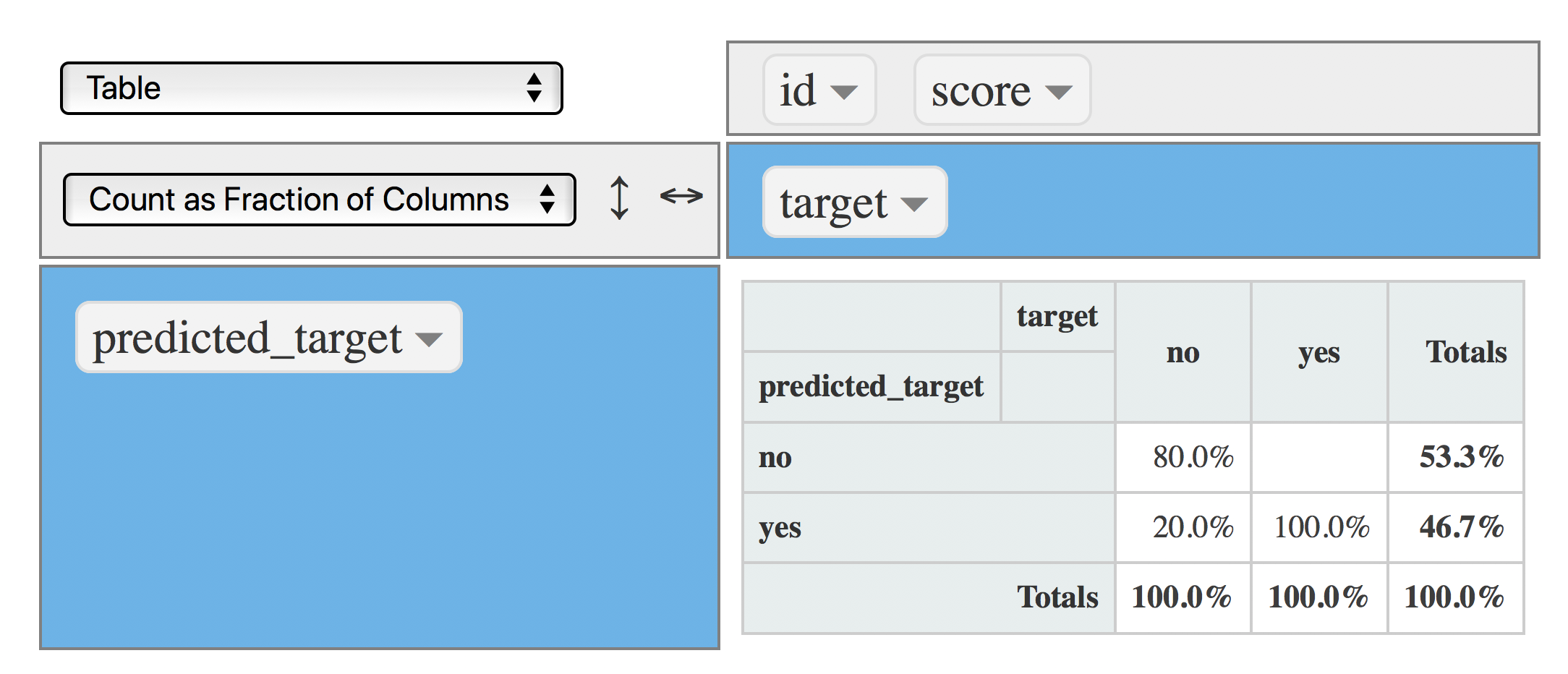
Figure 4.19: 혼동 행렬 (절단점 0.4)
이제 모델은 예(TP)를 100% 포착하므로, 모델에 의해 생성된 총 예의 양은 46.7%로 증가했지만, TN과 FP는 동일하게 유지 되었으므로 아무런 비용이 들지 않았습니다 :thumbsup:.
4.4.6.3 시나리오 3: 절단점 @ 0.8
FP 비율을 줄이고 싶으신가요? 절단점을 더 높은 값으로 설정하십시오. 예를 들어 0.8로 설정하면 모델에 의해 생성된 예가 감소합니다:
data$predicted_target=ifelse(data$score>=0.8, "yes", "no")
rpivotTable(data = data, rows = "predicted_target", cols="target", aggregatorName = "Count as Fraction of Columns", rendererName = "Table", width="100%", height="400px")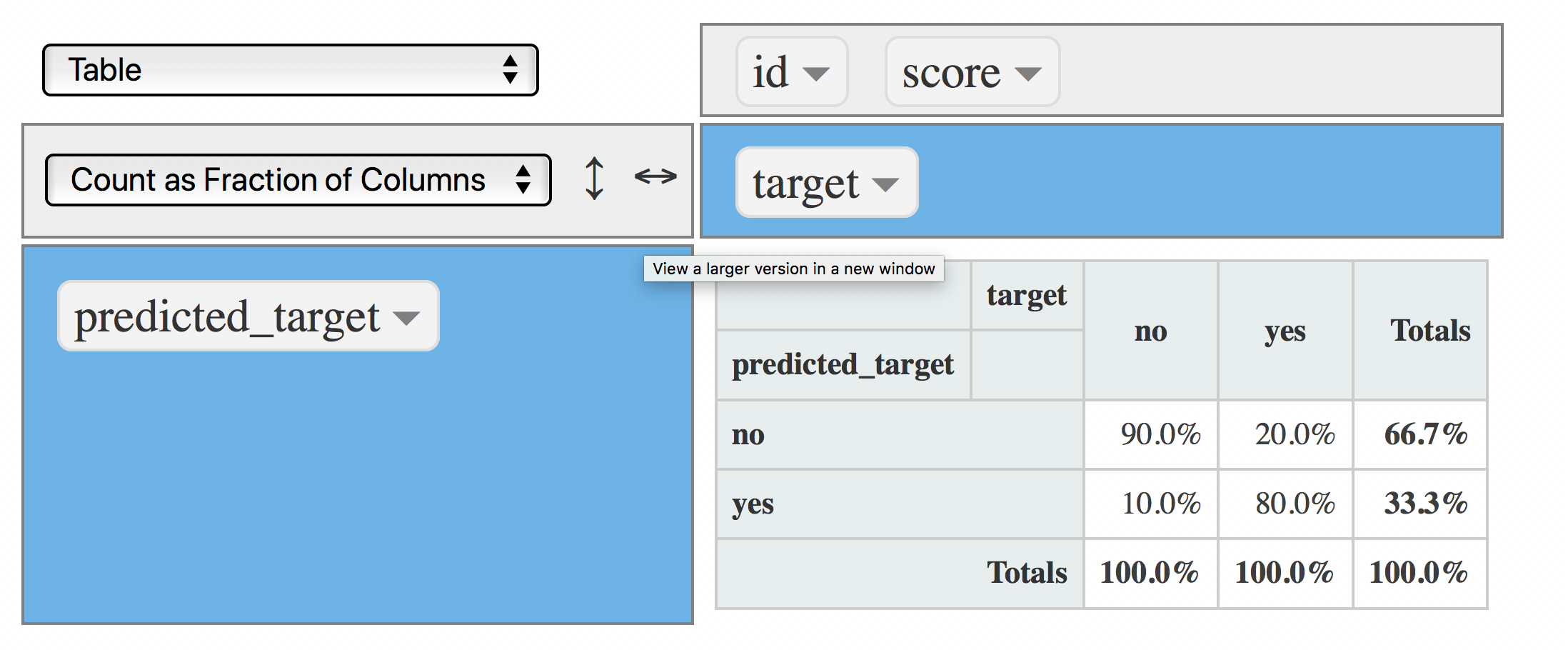
Figure 4.20: 혼동 행렬 (절단점 0.8)
이제 FP 비율이 20%에서 10%로 감소했으며, 모델은 여전히 절단점 0.5에서 얻은 것과 동일한 비율인 80%의 TP를 포착합니다 :thumbsup:.
절단점을 0.8로 높임으로써 비용 없이 모델을 개선했습니다.
4.4.7 결론
이 장은 이진 변수를 예측하는 본질에 초점을 맞추었습니다: 타겟 변수를 정렬하는 스코어 또는 가능성 숫자를 생성하는 것입니다.
예측 모델은 입력을 출력으로 매핑합니다.
유일하고 최선인 절단점 값은 존재하지 않습니다. 그것은 프로젝트의 요구 사항에 따라 달라지며, 우리가 수용할 수 있는
가양성(False Positive)과가음성(False Negative)비율에 의해 제한됩니다.
이 책은 오차 알기 장에서 모델 성능에 대한 전반적인 측면을 다룹니다.
![]()