5 부록 (APPENDIX)
보충 자료입니다.
5.1 백분위수의 마법
백분위수는 데이터 분석에서 매우 중요한 개념이므로 이 책에서 광범위하게 다룰 것입니다. 백분위수는 다른 관측치와 비교하여 각 관측치를 고려합니다. 고립된 숫자는 의미가 없을 수 있지만, 다른 숫자와 비교할 때 분포의 개념이 나타납니다.
백분위수는 프로파일링뿐만 아니라 예측 모델의 성능을 평가하는 데에도 사용됩니다.
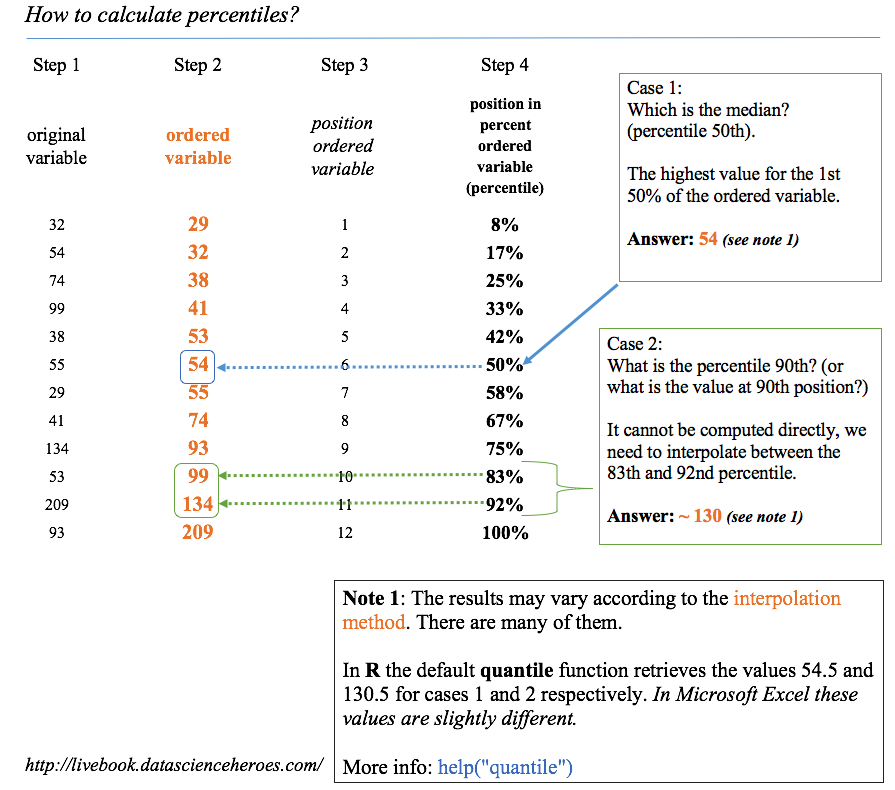
Figure 5.1: 백분위수 계산 방법
데이터셋, 계속하기 전의 제언:
이 데이터셋은 세계 개발과 관련된 많은 지표를 포함하고 있습니다. 프로파일링 예제와 상관없이, 사회학자, 연구자 등 이러한 종류의 데이터 분석에 관심이 있는 사람들에게 바로 사용할 수 있는 표를 제공하는 것이 목적입니다.
원본 데이터 소스는 http://databank.worldbank.org입니다. 거기에서 모든 변수를 설명하는 데이터 사전을 찾을 수 있습니다.
이 섹션에서는 이미 분석을 위해 준비된 표를 사용할 것입니다. 단계별 데이터 준비 과정 전체는 프로파일링 장에 있습니다.
지표의 의미는 data.worldbank.org에서 확인할 수 있습니다. 예를 들어, EN.POP.SLUM.UR.ZS가 무엇을 의미하는지 알고 싶다면 http://data.worldbank.org/indicator/EN.POP.SLUM.UR.ZS를 입력하면 됩니다.
5.1.1 백분위수를 계산하는 방법
백분위수를 얻는 방법은 여러 가지가 있습니다. 보간법(interpolation)을 기반으로 할 때 가장 쉬운 방법은 변수를 오름차순으로 정렬하고, 원하는 백분위수(예: 75%)를 선택한 다음, 정렬된 모집단의 75%를 선택하고자 할 때 최대값이 무엇인지 관찰하는 것입니다.
이제 계산 과정 배후에서 무슨 일이 일어나고 있는지 최대한 제어할 수 있도록 작은 샘플을 유지하는 기술을 사용할 것입니다.
무작위로 10개 국가를 추출하고, 사용할 변수인 rural_poverty_headcount 벡터를 출력합니다.
data_sample = data_world_wide %>%
filter(Country.Name %in% c("Kazakhstan", "Zambia", "Mauritania", "Malaysia", "Sao Tome and Principe", "Colombia", "Haiti", "Fiji", "Sierra Leone", "Morocco")) %>%
arrange(rural_poverty_headcount)
data_sample %>% select(Country.Name, rural_poverty_headcount)## Country.Name rural_poverty_headcount
## 1 Malaysia 1.6
## 2 Kazakhstan 4.4
## 3 Morocco 14.4
## 4 Colombia 40.3
## 5 Fiji 44.0
## 6 Mauritania 59.4
## 7 Sao Tome and Principe 59.4
## 8 Sierra Leone 66.1
## 9 Haiti 74.9
## 10 Zambia 77.9벡터는 학습 목적으로만 정렬되었음을 유의하십시오. 프로파일링 장에서 언급했듯이, 우리의 눈은 순서를 좋아합니다.
이제 rural_poverty_headcount 변수(국가 빈곤선 이하로 생활하는 농촌 인구의 비율)에 quantile 함수를 적용합니다:
## 0% 25% 50% 75% 100%
## 1.600 20.875 51.700 64.425 77.900분석
- 백분위수 50%: 국가의 50%(5개 국가)가
rural_poverty_headcount51.7 미만입니다. 마지막 도표에서 확인할 수 있습니다. 해당 국가는 피지, 콜롬비아, 모로코, 카자흐스탄, 말레이시아입니다. - 백분위수 25%: 국가의 25%가 20.87 미만입니다. 여기서 보간법이 사용된 것을 볼 수 있는데, 25%는 약 2.5개 국가를 나타내기 때문입니다. 이 값을 사용하여 국가를 필터링하면 모로코, 카자흐스탄, 말레이시아의 세 국가를 얻게 됩니다.
다양한 유형의 분위수와 그 보간법에 대한 더 많은 정보는 help("quantile")를 참조하십시오.
5.1.2 사용자 정의 분위수 계산
일반적으로 우리는 특정 분위수를 계산하고 싶어 합니다. 예시 변수는 gini_index입니다.
지니 계수(Gini index)란 무엇인가요?
소득이나 부의 불평등을 측정하는 지표입니다.
- 지니 계수가 0이면 모든 값이 동일한(예: 모든 사람의 소득이 동일함) 완전 평등을 의미합니다.
- 지니 계수가 1(또는 100%)이면 값 사이의 최대 불평등을 의미합니다(예: 많은 사람들 중 단 한 사람만 모든 소득이나 소비를 가지고 있고 다른 모든 사람들은 전혀 없는 경우, 지니 계수는 1에 매우 가까워집니다).
출처: https://en.wikipedia.org/wiki/Gini_coefficient
R 예제:
지니 계수 변수의 20, 40, 60, 80분위수를 얻으려면 다시 quantile 함수를 사용합니다.
이 사례와 같이 빈 값이 있는 경우 na.rm=TRUE 매개변수가 필요합니다:
# 여러 분위수를 한 번에 얻을 수도 있습니다.
p_custom = quantile(data_world_wide$gini_index, probs = c(0.2, 0.4, 0.6, 0.8), na.rm = TRUE)
p_custom## 20% 40% 60% 80%
## 31.624 35.244 41.076 46.1485.1.3 대부분의 값이 어디에 있는지 표시하기
기술 통계에서 우리는 모집단을 일반적인 용어로 설명하고자 합니다. 두 개의 백분위수를 사용하여 범위에 대해 말할 수 있습니다. 모집단의 80%를 설명하기 위해 10% 및 90% 백분위수를 사용해 봅시다.
국가의 80%에서 빈곤율은 0.075%에서 54.4% 사이입니다. (여기서 80%인 이유는 모집단의 가운데에 집중하여 90번째 백분위수에서 10번째 백분위수를 뺐기 때문입니다.)
80%를 모집단의 대다수로 간주한다면 이렇게 말할 수 있을 것입니다: “일반적으로(또는 일반적인 용어로) 빈곤율은 0.07%에서 54.4%까지입니다.” 이것이 의미적인 설명입니다.
우리는 대부분의 사례가 어디에 있는지 설명하기 위해 모집단의 80%를 살펴보았는데, 이는 좋은 숫자로 보입니다. 또한 90% 범위(95번째 백분위수 - 0.5번째 백분위수)를 사용할 수도 있었을 것입니다.
5.1.3.1 백분위수(Percentile)는 사분위수(Quartile)와 관련이 있나요?
사분위수(Quartile)는 25, 50, 75번째 백분위수(분기 또는 ‘Q’)를 가리키는 정식 명칭입니다. 인구의 50%를 살펴보려면 제3사분위수(또는 75번째 백분위수)에서 제1사분위수(25번째 백분위수)를 빼서 데이터의 50%가 집중된 위치를 구해야 하며, 이를 사분위수 범위(inter-quartile range) 또는 IQR이라고 합니다.
백분위수 vs. 분위수 vs. 사분위수
0 사분위수 = 0 분위수 = 0 백분위수
1 사분위수 = 0.25 분위수 = 25 백분위수
2 사분위수 = .5 분위수 = 50 백분위수 (중앙값)
3 사분위수 = .75 분위수 = 75 백분위수
4 사분위수 = 1 분위수 = 100 백분위수5.1.4 백분위수 시각화
각 백분위수가 위치한 곳과 함께 히스토그램을 그리면 개념을 이해하는 데 도움이 될 수 있습니다:
quantiles_var =
quantile(data_world_wide$poverty_headcount_1.9,
c(0.25, 0.5, 0.75),
na.rm = TRUE
)
df_p = data.frame(value=quantiles_var,
quantile=c("25th", "50th", "75th")
)
library(ggplot2)
ggplot(data_world_wide, aes(poverty_headcount_1.9)) +
geom_histogram() +
geom_vline(data=df_p,
aes(xintercept=value,
colour = quantile),
show.legend = TRUE,
linetype="dashed"
) +
theme_light()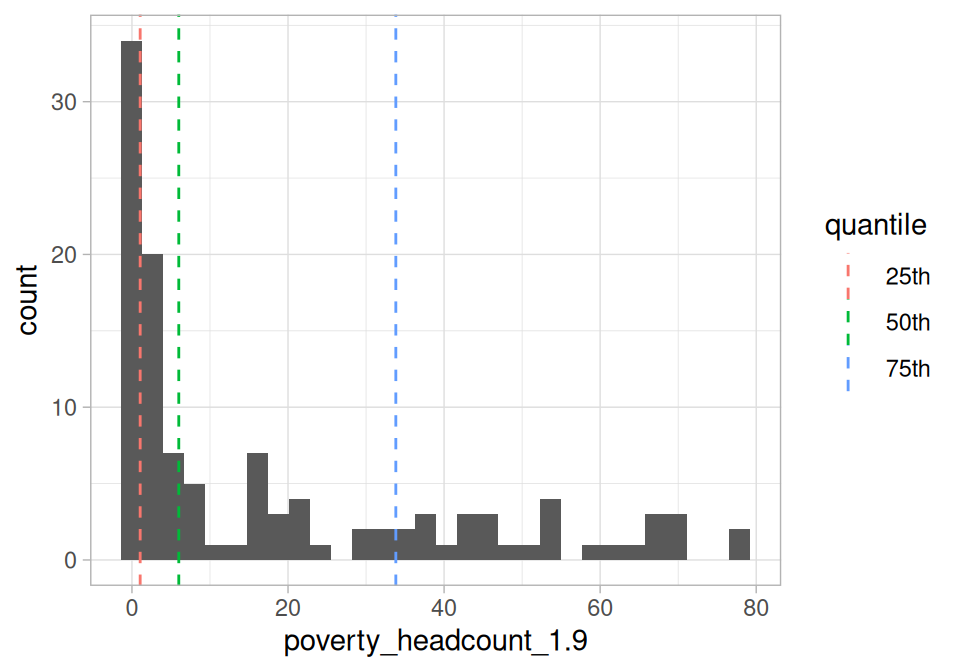
Figure 5.2: 백분위수 시각화
25번째 백분위수 이전의 모든 회색 막대를 모두 합하면, 75번째 백분위수 이후의 회색 막대 합계와 거의 비슷할 것입니다.
마지막 도표에서 IQR은 첫 번째와 마지막 점선 사이에 나타나며 인구의 50%를 포함하고 있습니다.
5.1.5 순위 및 상위/하위 ‘X%’ 개념
순위 개념은 경기에서 보는 것과 동일합니다. 이는 _pop_living_slums 변수에서 가장 높은 비율을 가진 국가는 어디인가요?_와 같은 질문에 답할 수 있게 해줍니다.
우리는 dplyr 패키지의 dense_rank 함수를 사용할 것입니다. 각 국가에 위치(순위)를 할당하지만, 우리는 내림차순(가장 높은 값이 1순위)으로 할당하고 싶습니다.
이제 살펴볼 변수는 다음과 같습니다: 슬럼(slums)에 거주하는 인구는 슬럼 가구에 거주하는 도시 인구의 비율입니다. 슬럼 가구는 동일한 지붕 아래 거주하며 다음 조건 중 하나 이상이 부족한 개인들의 집합으로 정의됩니다: 개선된 식수 이용, 개선된 위생 시설 이용, 충분한 주거 면적, 주택의 내구성.
답변할 질문: 슬럼 거주 비율이 가장 높은 상위 6개 국가는 어디인가요?
# 순위 변수 생성
data_world_wide$rank_pop_living_slums =
dense_rank(desc(data_world_wide$pop_living_slums))# 순위별로 데이터 정렬
data_world_wide = data_world_wide %>% arrange(rank_pop_living_slums)
# 상위 6개 결과 출력
data_world_wide %>% select(Country.Name, rank_pop_living_slums) %>% head()## Country.Name rank_pop_living_slums
## 1 South Sudan 1
## 2 Central African Republic 2
## 3 Sudan 3
## 4 Chad 4
## 5 Sao Tome and Principe 5
## 6 Guinea-Bissau 6또한 _에콰도르(Ecuador)는 몇 위인가요?_라고 물을 수 있습니다:
## rank_pop_living_slums
## 1 575.1.6 데이터 스코어링에서의 백분위수
이 개념을 사용하는 두 개의 장이 있습니다:
기본적인 아이디어는 이진 변수(예/아니오)를 예측하는 예측 모델을 개발하는 것입니다. 예를 들어 마케팅 캠페인에서 사용할 새로운 케이스의 스코어를 매겨야 한다고 가정해 봅시다. 답변해야 할 질문은 다음과 같습니다:
잠재적인 신규 매출의 50%를 포착하기 위해 영업 사원에게 제안할 스코어 값은 얼마인가요? 정답은 스코어링 값에 대한 백분위수 분석과 현재 타겟의 누적 분석을 결합하여 얻을 수 있습니다.
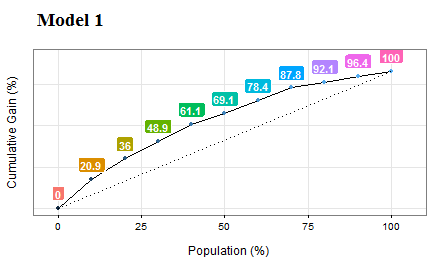
Figure 5.3: 이득 및 리프트 곡선 (모델 성능)
5.1.6.1 사례 연구: 부의 분포
부의 분포는 지니 계수와 유사하며 불평등에 초점을 맞춥니다. 이는 (소득과는 다른) 소유 자산을 측정하여, 사람들이 사는 곳에 따라 무엇을 획득할 수 있는지에 대해 국가 간 비교를 더 공정하게 만듭니다. 더 정확한 정의는 Wikipedia 기사와 _Global Wealth Report 2013_을 참조하십시오. 각각 자료 (Wikipedia 2017a)와 (Suisse 2013)입니다.
_Wikipedia_의 인용(자료 (Wikipedia 2017a)):
세계 부의 절반은 인구의 상위 1%가 소유하고 있습니다.
상위 10%의 성인이 85%를 보유하고 있으며, 나머지 하위 90%가 전 세계 총자산의 15%를 보유하고 있습니다.
상위 30%의 성인이 총자산의 97%를 보유하고 있습니다.
앞에서 했던 것처럼 세 번째 문장으로부터 다음과 같이 말할 수 있습니다: “전체 부의 3%가 성인 70%에게 분배되어 있습니다.”
상위 10% 및 상위 30% 지표는 분위수 0.1 및 0.3에 해당합니다. 여기서 부(Wealth)는 수치 변수입니다.
![]()
5.2 funModeling 퀵스타트
이 패키지에는 탐색적 데이터 분석, 데이터 준비 및 모델 성능과 관련된 일련의 함수들이 포함되어 있습니다. 비즈니스, 연구 및 교육(교수 및 학생) 분야의 사람들이 주로 사용합니다.
funModeling은 이 책에서 다루는 다양한 주제를 설명하는 데 대부분의 기능이 사용된다는 점에서 이 책과 밀접한 관련이 있습니다.
5.2.1 블랙박스 열어보기
일부 함수에는 인라인 주석이 있어 사용자가 블랙박스를 열고 어떻게 개발되었는지 배우거나, 함수를 조정하거나 개선할 수 있습니다.
모든 함수는 잘 문서화되어 있으며, 많은 짧은 예제의 도움을 받아 모든 매개변수를 설명합니다. R 문서는 help("함수_이름")으로 접속할 수 있습니다.
최신 버전 1.6.7의 중요한 변경 사항 (이전 버전을 사용하던 경우에만 해당):
최신 버전인 1.6.7(2018년 1월 21일)부터 매개변수 str_input, str_target 및 str_score의 이름이 각각 input, target 및 score로 변경됩니다. 기능은 동일하게 유지됩니다. 프로덕션 환경에서 이전 매개변수 이름을 사용하고 있었다면 다음 릴리스까지는 계속 작동할 것입니다. 즉, 현재로서는 예를 들어 str_input 또는 input을 모두 사용할 수 있습니다.
또 다른 중요한 변경 사항은 discretize_get_bins였으며, 이는 이 문서의 뒷부분에서 자세히 설명합니다.
5.2.2 탐색적 데이터 분석 (EDA)
5.2.2.1 df_status: 데이터셋 상태 확인
사용 사례: 주어진 데이터셋에 대해 0(zeros), 결측값(NA), 무한대, 데이터 유형 및 고유 값의 개수를 분석합니다.
## variable q_zeros p_zeros q_na p_na q_inf p_inf type unique
## 1 age 0 0.00 0 0.00 0 0 integer 41
## 2 gender 0 0.00 0 0.00 0 0 factor 2
## 3 chest_pain 0 0.00 0 0.00 0 0 factor 4
## 4 resting_blood_pressure 0 0.00 0 0.00 0 0 integer 50
## 5 serum_cholestoral 0 0.00 0 0.00 0 0 integer 152
## 6 fasting_blood_sugar 258 85.15 0 0.00 0 0 factor 2
## 7 resting_electro 151 49.83 0 0.00 0 0 factor 3
## 8 max_heart_rate 0 0.00 0 0.00 0 0 integer 91
## 9 exer_angina 204 67.33 0 0.00 0 0 integer 2
## 10 oldpeak 99 32.67 0 0.00 0 0 numeric 40
## 11 slope 0 0.00 0 0.00 0 0 integer 3
## 12 num_vessels_flour 176 58.09 4 1.32 0 0 integer 4
## 13 thal 0 0.00 2 0.66 0 0 factor 3
## 14 heart_disease_severity 164 54.13 0 0.00 0 0 integer 5
## 15 exter_angina 204 67.33 0 0.00 0 0 factor 2
## 16 has_heart_disease 0 0.00 0 0.00 0 0 factor 2[🔎 여기서 더 읽어보기]
5.2.2.2 plot_num: 수치 변수의 분포 시각화
수치 변수만을 시각화합니다.
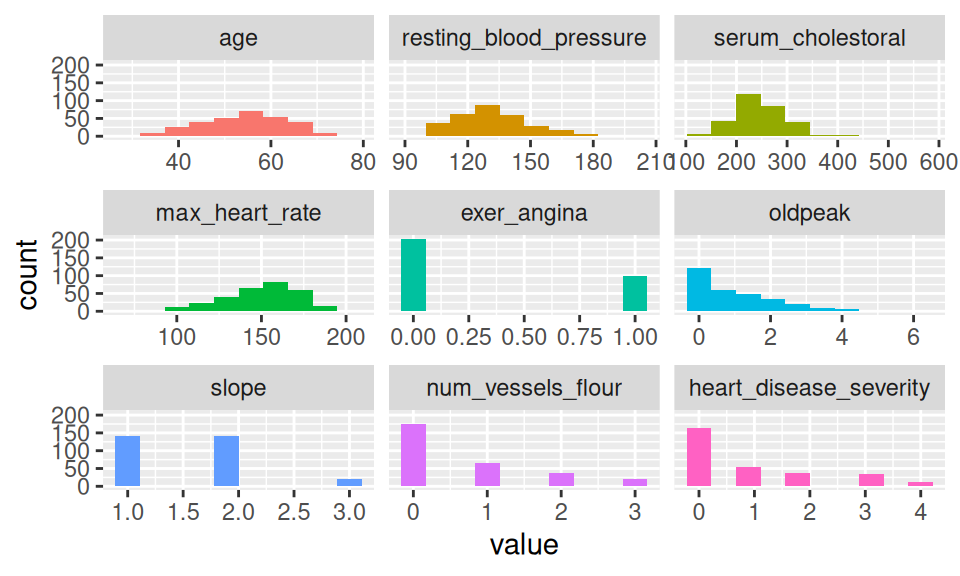
Figure 5.4: plot_num: 수치 변수 시각화
Notes:
bins: 구간(bin)의 개수를 설정합니다(기본값은 10).path_out: 경로 디렉토리를 나타냅니다. 값이 있으면 플롯이 jpeg로 내보내집니다. 현재 디렉토리에 저장하려면 점(“.”)을 사용합니다.
[🔎 여기서 더 읽어보기]
5.2.2.3 profiling_num: 수치 변수에 대한 여러 통계량 계산
수치 변수에 대한 여러 통계량을 검색합니다.
## variable mean std_dev variation_coef p_01 p_05
## 1 age 54.4389439 9.0386624 0.1660330 35.00 40.0
## 2 resting_blood_pressure 131.6897690 17.5997477 0.1336455 100.00 108.0
## 3 serum_cholestoral 246.6930693 51.7769175 0.2098840 149.00 175.1
## 4 max_heart_rate 149.6072607 22.8750033 0.1529004 95.02 108.1
## 5 exer_angina 0.3267327 0.4697945 1.4378558 0.00 0.0
## 6 oldpeak 1.0396040 1.1610750 1.1168436 0.00 0.0
## 7 slope 1.6006601 0.6162261 0.3849825 1.00 1.0
## 8 num_vessels_flour 0.6722408 0.9374383 1.3944978 0.00 0.0
## 9 heart_disease_severity 0.9372937 1.2285357 1.3107265 0.00 0.0
## p_25 p_50 p_75 p_95 p_99 skewness kurtosis iqr range_98
## 1 48.0 56.0 61.0 68.0 71.00 -0.2080241 2.465477 13.0 [35, 71]
## 2 120.0 130.0 140.0 160.0 180.00 0.7025346 3.845881 20.0 [100, 180]
## 3 211.0 241.0 275.0 326.9 406.74 1.1298741 7.398208 64.0 [149, 406.74]
## 4 133.5 153.0 166.0 181.9 191.96 -0.5347844 2.927602 32.5 [95.02, 191.96]
## 5 0.0 0.0 1.0 1.0 1.00 0.7388506 1.545900 1.0 [0, 1]
## 6 0.0 0.8 1.6 3.4 4.20 1.2634255 4.530193 1.6 [0, 4.2]
## 7 1.0 2.0 2.0 3.0 3.00 0.5057957 2.363050 1.0 [1, 3]
## 8 0.0 0.0 1.0 3.0 3.00 1.1833771 3.234941 1.0 [0, 3]
## 9 0.0 0.0 2.0 3.0 4.00 1.0532483 2.843788 2.0 [0, 4]
## range_80
## 1 [42, 66]
## 2 [110, 152]
## 3 [188.8, 308.8]
## 4 [116, 176.6]
## 5 [0, 1]
## 6 [0, 2.8]
## 7 [1, 2]
## 8 [0, 2]
## 9 [0, 3]Note:
plot_num과profiling_num은 수치가 아닌 변수를 자동으로 제외합니다.
[🔎 여기서 더 읽어보기]
5.2.2.4 freq: 범주형 변수의 빈도 분포 확인
library(dplyr)
# 이 예시를 위해 두 개의 변수만 선택합니다.
heart_disease_2 = heart_disease %>% select(chest_pain, thal)
# 빈도 분포
freq(heart_disease_2)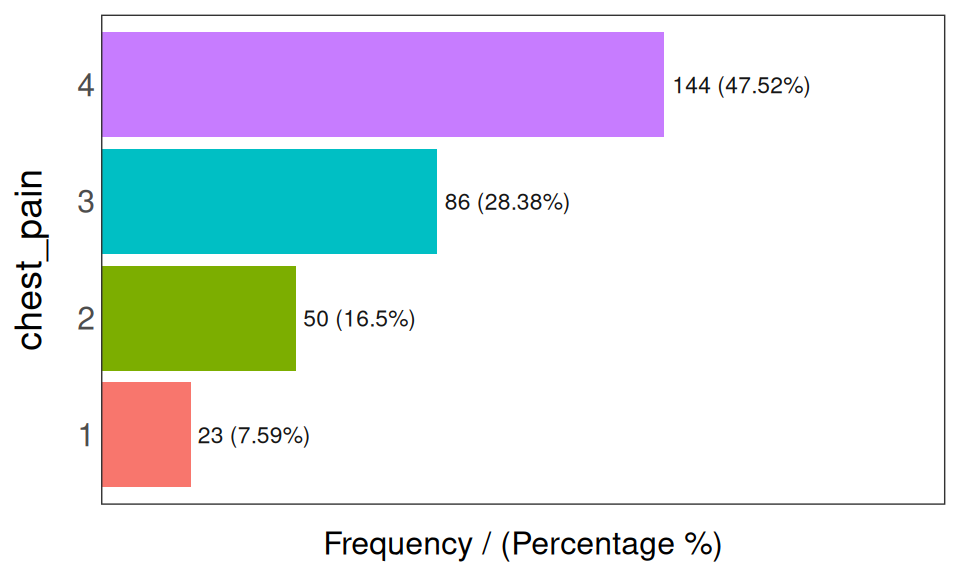
Figure 5.5: freq: 범주형 변수 시각화
## chest_pain frequency percentage cumulative_perc
## 1 4 144 47.52 47.52
## 2 3 86 28.38 75.90
## 3 2 50 16.50 92.40
## 4 1 23 7.59 100.00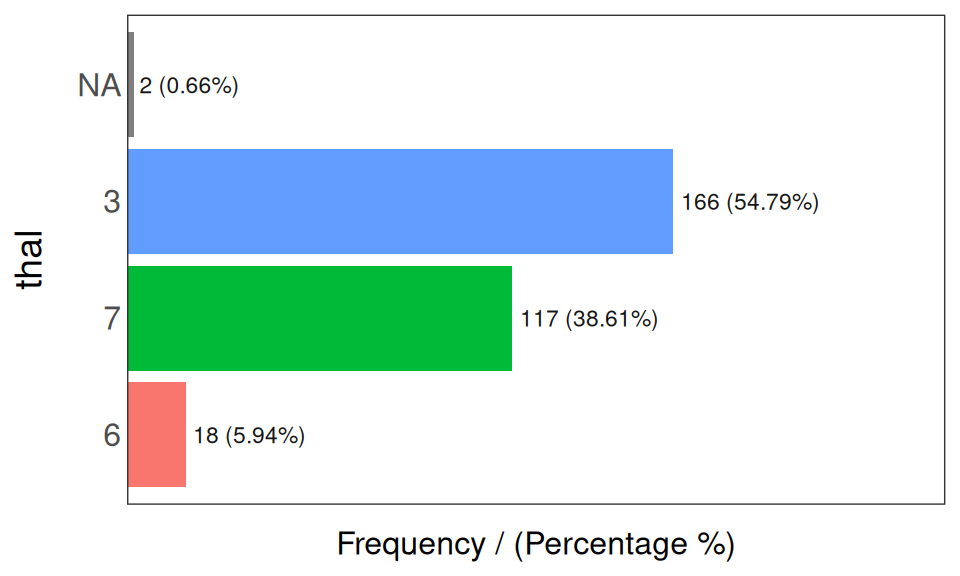
Figure 5.6: freq: 범주형 변수 시각화
## thal frequency percentage cumulative_perc
## 1 3 166 54.79 54.79
## 2 7 117 38.61 93.40
## 3 6 18 5.94 99.34
## 4 <NA> 2 0.66 100.00## [1] "Variables processed: chest_pain, thal"Notes:
freq는factor및character만 처리하며, 범주형이 아닌 변수는 제외합니다.- 분포표를 데이터 프레임으로 반환합니다.
input이 비어 있으면 모든 범주형 변수에 대해 실행됩니다.path_out은 경로 디렉토리를 나타냅니다. 값이 있으면 플롯이 jpeg로 내보내집니다. 현재 디렉토리에 저장하려면 점(“.”)을 사용합니다.na.rm은NA값을 제외할지 여부를 나타냅니다(기본값은FALSE).
[🔎 여기서 더 읽어보기]
5.2.3 상관관계
5.2.3.1 correlation_table: R 통계량 계산
범주형 변수는 건너뛰고 모든 수치 변수에 대한 R 지표(또는 피어슨 상관계수)를 검색합니다.
## Variable has_heart_disease
## 1 has_heart_disease 1.00
## 2 heart_disease_severity 0.83
## 3 num_vessels_flour 0.46
## 4 oldpeak 0.42
## 5 slope 0.34
## 6 age 0.23
## 7 resting_blood_pressure 0.15
## 8 serum_cholestoral 0.08
## 9 max_heart_rate -0.42Notes:
- 수치 변수만 분석됩니다. 타겟 변수는 반드시 수치형이어야 합니다.
- 타겟이 범주형인 경우 수치형으로 변환됩니다.
[🔎 여기서 더 읽어보기]
5.2.3.2 var_rank_info: 정보 이론에 기반한 상관관계
데이터 프레임의 모든 변수와 타겟 변수 사이의 여러 정보 이론 지표에 기반하여 상관관계를 계산합니다.
## Warning: `funs()` was deprecated in dplyr 0.8.0.
## ℹ Please use a list of either functions or lambdas:
##
## # Simple named list: list(mean = mean, median = median)
##
## # Auto named with `tibble::lst()`: tibble::lst(mean, median)
##
## # Using lambdas list(~ mean(., trim = .2), ~ median(., na.rm = TRUE))
## ℹ The deprecated feature was likely used in the funModeling package.
## Please report the issue at <https://github.com/pablo14/funModeling/issues>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.## var en mi ig gr
## en13 heart_disease_severity 1.846 0.995 0.9950837595 0.5390655068
## en12 thal 2.032 0.209 0.2094550580 0.1680456709
## en8 exer_angina 1.767 0.139 0.1391389302 0.1526393841
## en14 exter_angina 1.767 0.139 0.1391389302 0.1526393841
## en2 chest_pain 2.527 0.205 0.2050188327 0.1180286190
## en11 num_vessels_flour 2.381 0.182 0.1815217813 0.1157736478
## en10 slope 2.177 0.112 0.1124219069 0.0868799615
## en4 serum_cholestoral 7.481 0.561 0.5605556771 0.0795557228
## en1 gender 1.842 0.057 0.0572537665 0.0632970555
## en9 oldpeak 4.874 0.249 0.2491668741 0.0603576874
## en7 max_heart_rate 6.832 0.334 0.3336174096 0.0540697329
## en3 resting_blood_pressure 5.567 0.143 0.1425548155 0.0302394591
## en age 5.928 0.137 0.1371752885 0.0270548944
## en6 resting_electro 2.059 0.024 0.0241482908 0.0221938072
## en5 fasting_blood_sugar 1.601 0.000 0.0004593775 0.0007579095참고: 수치 및 범주형 변수를 분석합니다. 또한 discretize_df와 같이 이전에 사용된 수치 이산화 방법과 함께 사용됩니다.
[🔎 여기서 더 읽어보기]
5.2.3.3 cross_plot: 입력 변수와 타겟 변수 간의 분포 플롯
입력 변수와 타겟 변수 사이의 상대적 및 절대적 분포를 검색합니다. 변수가 중요한지 여부를 설명하고 보고하는 데 유용합니다.
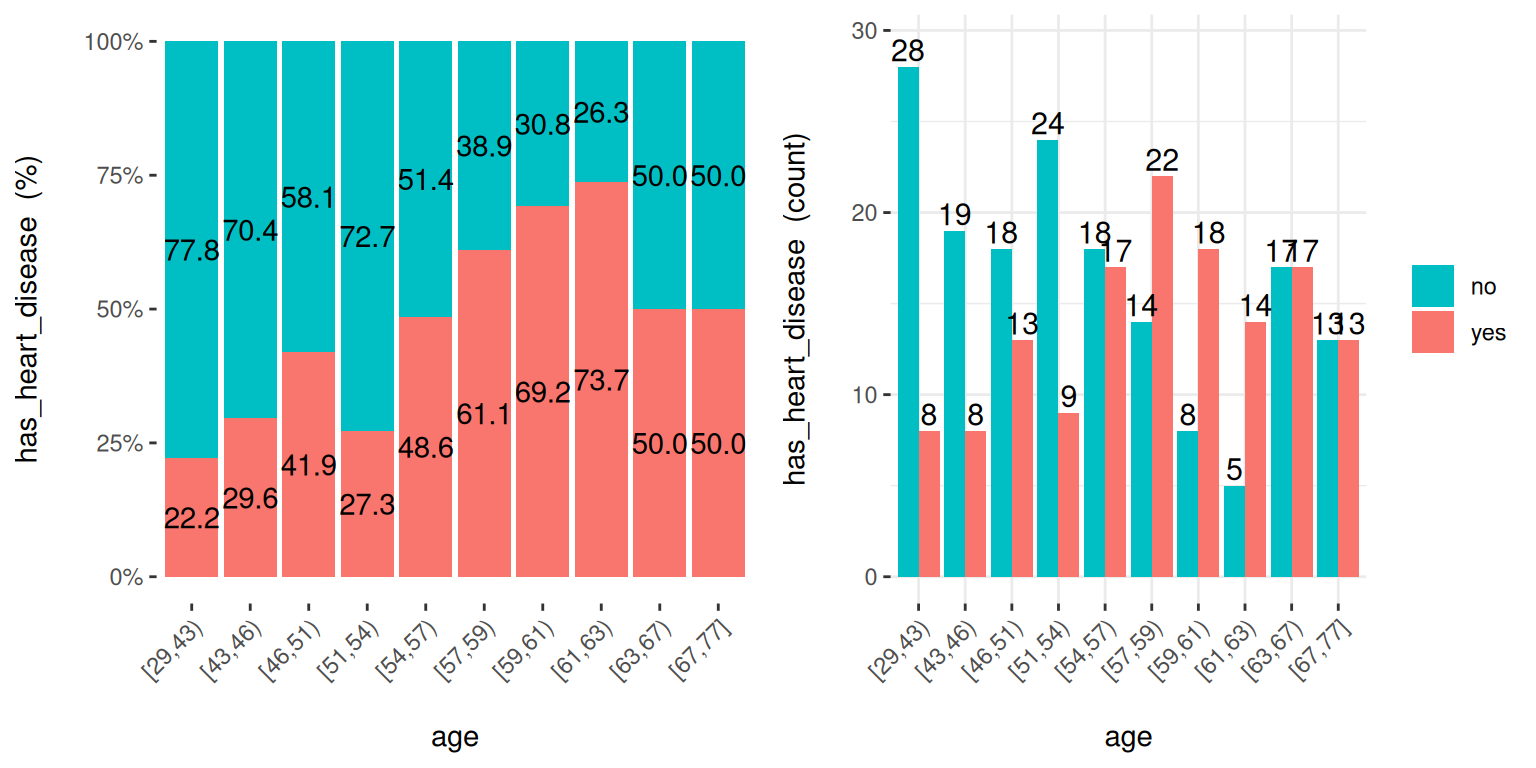
Figure 5.7: cross_plot: 입력 vs. 타겟 변수 시각화
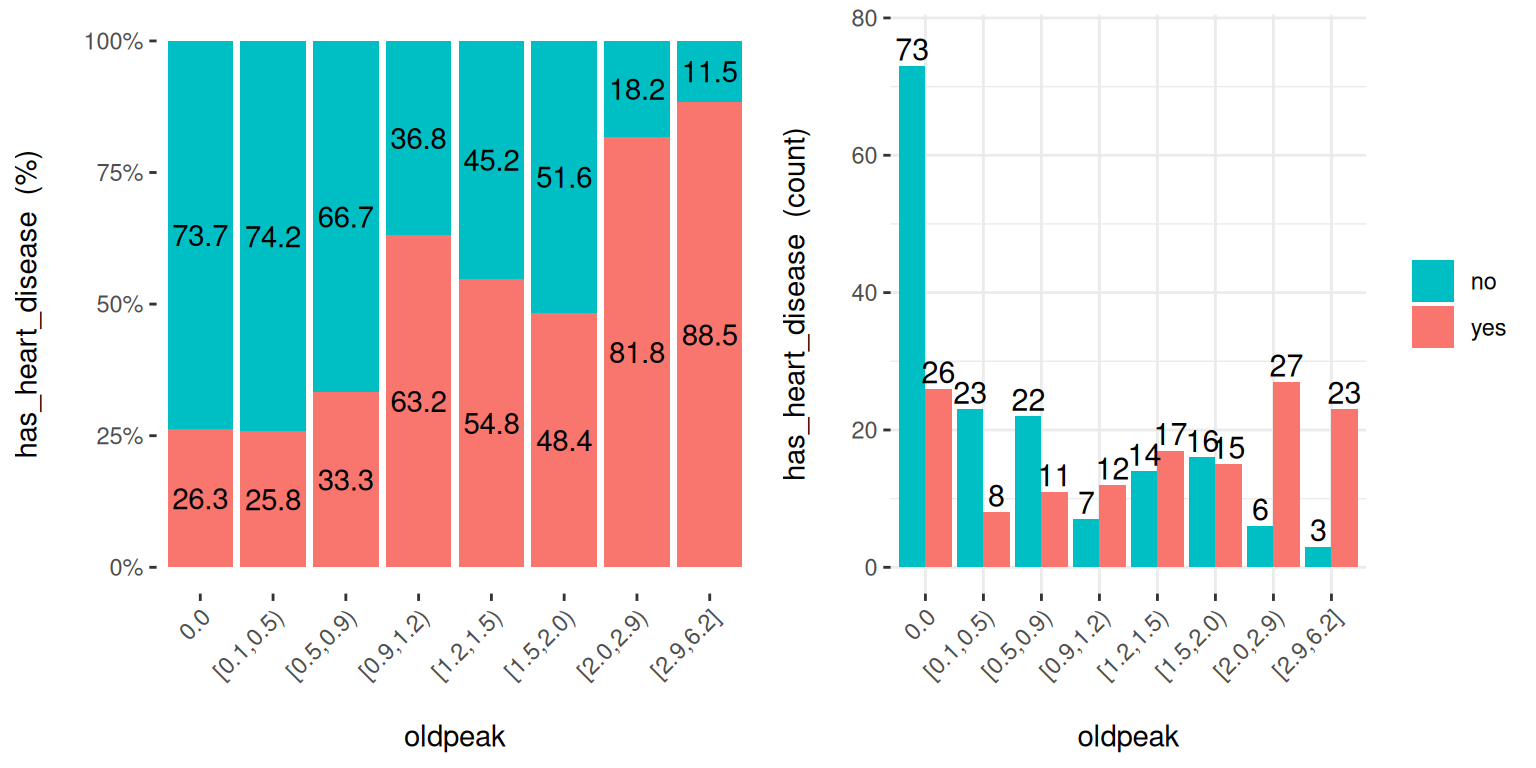
Figure 5.8: cross_plot: 입력 vs. 타겟 변수 시각화
Notes:
auto_binning: 기본값은TRUE이며, 수치 변수를 범주형으로 보여줍니다.path_out: 경로 디렉토리를 나타내며, 값이 있으면 플롯이 jpeg로 내보내집니다.input은 수치형 또는 범주형일 수 있으며,target은 반드시 이진(두 개의 클래스) 변수여야 합니다.input이 비어 있으면 모든 변수에 대해 실행됩니다.
[🔎 여기서 더 읽어보기]
5.2.3.4 plotar: 입력 변수와 타겟 변수 간의 박스플롯 및 밀도 히스토그램
변수가 중요한지 여부를 설명하고 보고하는 데 유용합니다.
박스플롯(Boxplot):
plotar(data = heart_disease, input = c("age", "oldpeak"), target = "has_heart_disease", plot_type = "boxplot")## Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
## ℹ Please use tidy evaluation idioms with `aes()`.
## ℹ See also `vignette("ggplot2-in-packages")` for more information.
## ℹ The deprecated feature was likely used in the funModeling package.
## Please report the issue at <https://github.com/pablo14/funModeling/issues>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.## Warning: The `fun.y` argument of `stat_summary()` is deprecated as of ggplot2 3.3.0.
## ℹ Please use the `fun` argument instead.
## ℹ The deprecated feature was likely used in the funModeling package.
## Please report the issue at <https://github.com/pablo14/funModeling/issues>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.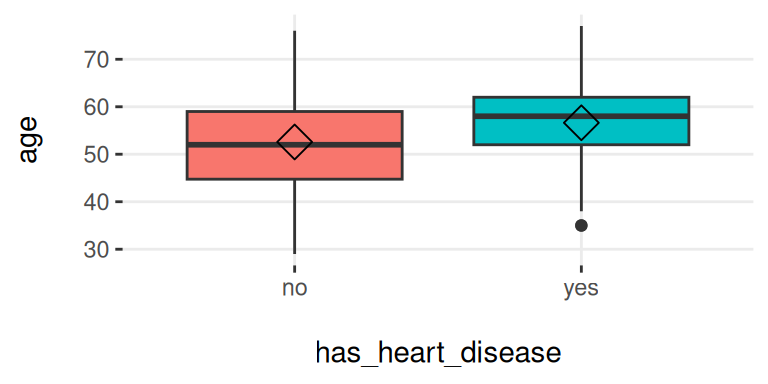
Figure 5.9: plotar (1): 박스플롯 시각화
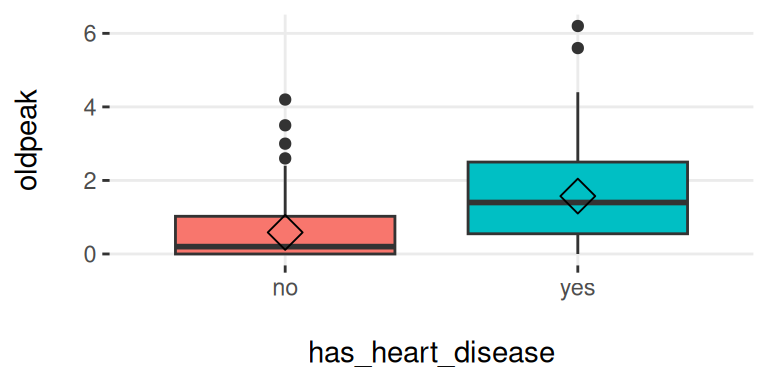
Figure 5.10: plotar (1): 박스플롯 시각화
[🔎 여기서 더 읽어보기]
밀도 히스토그램(Density histograms):
## Warning: `summarise_()` was deprecated in dplyr 0.7.0.
## ℹ Please use `summarise()` instead.
## ℹ The deprecated feature was likely used in the funModeling package.
## Please report the issue at <https://github.com/pablo14/funModeling/issues>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.## Warning: `group_by_()` was deprecated in dplyr 0.7.0.
## ℹ Please use `group_by()` instead.
## ℹ See vignette('programming') for more help
## ℹ The deprecated feature was likely used in the funModeling package.
## Please report the issue at <https://github.com/pablo14/funModeling/issues>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## ℹ The deprecated feature was likely used in the funModeling package.
## Please report the issue at <https://github.com/pablo14/funModeling/issues>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.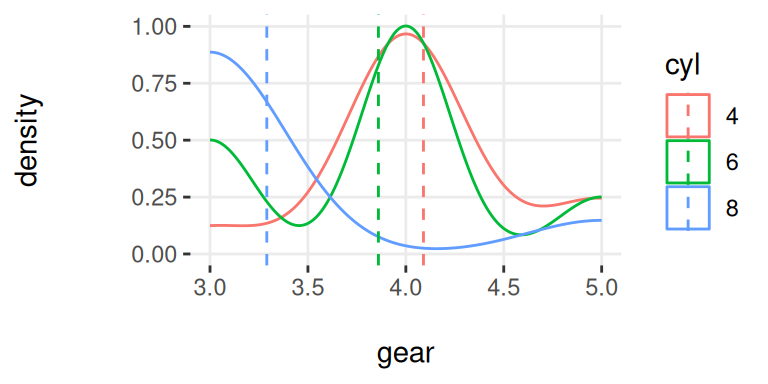
Figure 5.11: plotar (2): 밀도 히스토그램 시각화
[🔎 여기서 더 읽어보기]
Notes:
path_out: 경로 디렉토리를 나타내며, 값이 있으면 플롯이 jpeg로 내보내집니다.input이 비어 있으면 모든 수치 변수에 대해 실행됩니다(범주형 변수는 건너뜀).input은 수치형이어야 하고 타겟은 범주형이어야 합니다.target은 다중 클래스(이진 클래스뿐만 아니라)일 수 있습니다.
5.2.3.5 categ_analysis: 이진 결과에 대한 정량적 분석
범주형 입력 변수를 기반으로 이진 타겟의 대푯성(perc_rows)과 정확도(perc_target)를 각각의 입력 값별로 프로파일링합니다. 예를 들어 국가별 독감 감염률 등이 있습니다.
## country mean_target sum_target perc_target q_rows perc_rows
## 1 Malaysia 1.000 1 0.012 1 0.001
## 2 Mexico 0.667 2 0.024 3 0.003
## 3 Portugal 0.200 1 0.012 5 0.005
## 4 United Kingdom 0.178 8 0.096 45 0.049
## 5 Uruguay 0.175 11 0.133 63 0.069
## 6 Israel 0.167 1 0.012 6 0.007Note:
input변수는 반드시 범주형이어야 합니다.target변수는 반드시 이진(두 개의 값)이어야 합니다.
이 함수는 예측 모델링에서 변수의 카디널리티(cardinality)를 줄여야 할 때 데이터를 분석하는 데 사용됩니다.
[🔎 여기서 더 읽어보기]
5.2.4 데이터 준비
5.2.4.1 데이터 이산화 (Data discretization)
5.2.4.1.1 discretize_get_bins + discretize_df: 수치 변수를 범주형으로 변환
두 개의 함수가 필요합니다: discretize_get_bins는 각 변수에 대한 임계값(bins)을 반환하고, discretize_df는 첫 번째 함수의 결과를 가져와 원하는 변수를 변환합니다. 구간화(binning) 기준은 동일 빈도(equal frequency)입니다.
데이터셋에서 두 개의 변수만 변환하는 예시입니다.
# 1단계: 원하는 변수인 "max_heart_rate"와 "oldpeak"에 대한 임계값 가져오기
d_bins = discretize_get_bins(data = heart_disease, input = c("max_heart_rate", "oldpeak"), n_bins = 5)## Variables processed: max_heart_rate, oldpeak# 2단계: 임계값을 적용하여 최종 처리된 데이터 프레임 얻기
heart_disease_discretized =
discretize_df(data = heart_disease,
data_bins = d_bins,
stringsAsFactors = TRUE
)## Variables processed: max_heart_rate, oldpeak다음 이미지는 결과를 보여줍니다. 변수 이름은 동일하게 유지됨을 유의하십시오.
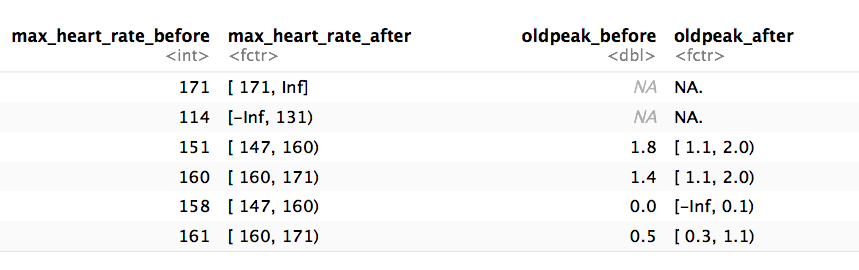
Figure 5.12: 자동 이산화 과정의 결과
Notes:
- 이 2단계 절차는 새로운 데이터가 들어오는 운영 환경(production)에서 사용하도록 고안되었습니다.
- 각 구간의 최소값과 최대값은 각각
-Inf와Inf가 됩니다. - 최신
funModeling릴리스(1.6.7)에서 수정된 사항으로 인해 특정 시나리오에서 출력이 변경될 수 있습니다. 버전 1.6.6을 사용하고 있었다면 결과를 확인하십시오. 이 변경 사항에 대한 자세한 정보는 여기를 참조하십시오.
{kind=link}
[🔎 여기서 더 읽어보기]
5.2.4.2 convert_df_to_categoric: 데이터 프레임의 모든 열을 범주형 변수로 변환
수치 변수에 대한 구간화 또는 이산화 기준은 동일 빈도입니다. 팩터(factor) 변수는 문자형(character) 변수로 직접 변환됩니다.
5.2.4.3 equal_freq: 수치 변수를 범주형으로 변환
동일 빈도 기준을 사용하여 수치 벡터를 팩터(factor)로 변환합니다.
## new_age
## n missing distinct
## 303 0 5
##
## Value [29,46) [46,54) [54,59) [59,63) [63,77]
## Frequency 63 64 71 45 60
## Proportion 0.208 0.211 0.234 0.149 0.198[🔎 여기서 더 읽어보기]
Notes:
discretize_get_bins와 달리, 이 함수는-Inf와Inf를 각각 최소값과 최대값으로 삽입하지 않습니다.
5.2.5 이상치(Outliers) 데이터 준비
5.2.5.1 hampel_outlier 및 tukey_outlier: 이상치 임계값 계산
두 함수 모두 이상치로 간주되는 값의 임계값을 나타내는 두 값으로 된 벡터를 검색합니다.
tukey_outlier와 hampel_outlier 함수는 prep_outliers 내부에서 사용됩니다.
터키(Tukey) 방식 사용:
## bottom_threshold top_threshold
## 60 200[🔎 여기서 더 읽어보기]
햄펠(Hampel) 방식 사용:
## bottom_threshold top_threshold
## 85.522 174.478[🔎 여기서 더 읽어보기]
5.2.5.2 prep_outliers: 데이터 프레임의 이상치 준비
데이터 프레임을 가져와 input 매개변수에 지정된 변수들에 대해 변환된 데이터 프레임을 반환합니다. 단일 벡터로도 작동합니다.
두 개의 변수를 입력으로 사용하는 예시입니다:
## bottom_threshold top_threshold
## 86.283 219.717# 임계값에서 이상치를 멈추게(stop) 하는 함수 적용
data_prep = prep_outliers(data = heart_disease, input = c('max_heart_rate', 'resting_blood_pressure'), method = "hampel", type = 'stop')max_heart_rate 변수의 변환 전후를 확인합니다:
## [1] "변환 전 -> 최소값: 71; 최대값: 202"## [1] "변환 후 -> 최소값: 71; 최대값: 202"최소값은 71에서 86.23으로 변경되었으며, 최대값은 202로 동일하게 유지되었습니다.
참고:
method는bottom_top,tukey또는hampel이 될 수 있습니다.type은stop또는set_na가 될 수 있습니다.stop인 경우 이상치로 플래그가 지정된 모든 값이 임계값으로 설정됩니다.set_na인 경우 플래그가 지정된 값은NA로 설정됩니다.
[🔎 여기서 더 읽어보기]
5.2.6 예측 모델 성능
5.2.6.1 gain_lift: 이득 및 리프트 성능 곡선
예측하고자 하는 클래스에 대한 스코어나 확률을 계산한 후, 이를 gain_lift 함수에 전달하면 성능 지표가 포함된 데이터 프레임을 반환합니다.
# 머신러닝 모델 생성 및 양성 케이스에 대한 스코어 가져오기
fit_glm = glm(has_heart_disease ~ age + oldpeak, data = heart_disease, family = binomial)
heart_disease$score = predict(fit_glm, newdata = heart_disease, type = 'response')
# 성능 지표 계산
gain_lift(data = heart_disease, score = 'score', target = 'has_heart_disease')## Warning: The `guide` argument in `scale_*()` cannot be `FALSE`. This was deprecated in
## ggplot2 3.3.4.
## ℹ Please use "none" instead.
## ℹ The deprecated feature was likely used in the funModeling package.
## Please report the issue at <https://github.com/pablo14/funModeling/issues>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.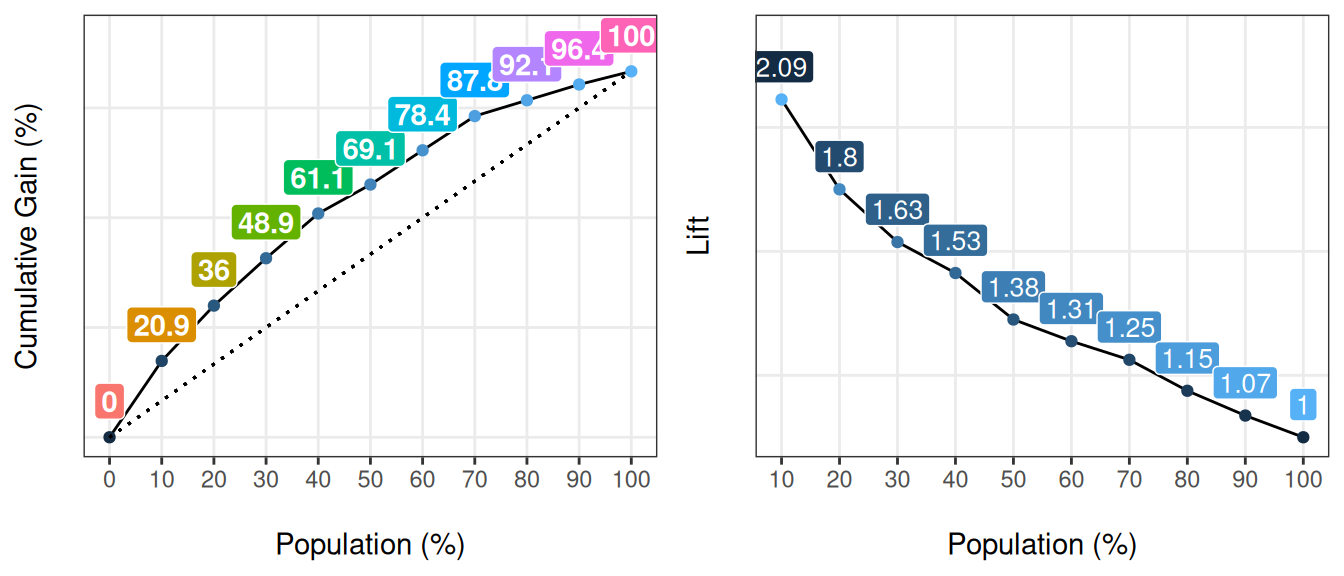
Figure 5.13: gain_lift: 예측 모델 성능 시각화
## Population Gain Lift Score.Point
## 1 10 20.86 2.09 0.8185793
## 2 20 35.97 1.80 0.6967124
## 3 30 48.92 1.63 0.5657817
## 4 40 61.15 1.53 0.4901940
## 5 50 69.06 1.38 0.4033640
## 6 60 78.42 1.31 0.3344170
## 7 70 87.77 1.25 0.2939878
## 8 80 92.09 1.15 0.2473671
## 9 90 96.40 1.07 0.1980453
## 10 100 100.00 1.00 0.1195511[🔎 여기서 더 읽어보기]
![]()