1 탐색적 데이터 분석
숫자들의 소리에 귀 기울이기 :)
1.1 프로파일링: 숫자의 목소리

“숫자의 목소리” – 에두아르도 갈레아노, 작가이자 소설가의 비유.
우리가 탐색하는 데이터는 제대로 해석하지 못하면 이집트 상형문자와 같을 수 있습니다. 프로파일링은 데이터가 우리에게 무엇을 말하고 싶어 하는지, 우리가 충분히 인내심을 갖고 귀 기울인다면, 그 메시지를 찾는 일련의 반복적인 단계 중 첫걸음입니다.
이 장에서는 몇 가지 함수를 사용하여 완벽한 데이터 프로파일링을 다룰 것입니다. 이는 데이터 프로젝트의 첫 단계가 되어야 하며, 올바른 데이터 유형을 파악하고 수치형 및 범주형 변수의 분포를 탐색하는 것부터 시작합니다.
또한 비전문가에게 보고서를 작성할 때 유용한 의미론적 결론을 도출하는 데 중점을 둡니다.
이 장에서 무엇을 살펴볼까요?
- 데이터셋 상태:
- 총 행, 열, 데이터 유형, 0 값, 결측치와 같은 지표 얻기
- 각 항목이 다양한 분석에 미치는 영향
- 데이터를 정리하기 위해 이를 빠르게 필터링하고 조작하는 방법
- 범주형 변수의 단변량 분석:
- 빈도, 백분율, 누적 값, 시각적으로 매력적인 플롯
- 수치형 변수의 단변량 분석:
- 백분위수, 분산, 표준 편차, 평균, 상위 및 하위 값
- 백분위수 vs. 분위수 vs. 사분위수
- 왜도, 첨도, 사분위 범위, 변동 계수
- 분포 플로팅
- “데이터 월드”를 기반으로 한 데이터 준비 및 데이터 분석의 완벽한 사례 연구
이 장에서 다룰 함수 요약:
df_status(data): 데이터셋 구조 프로파일링describe(data): 수치형 및 범주형 프로파일링 (정량적)freq(data): 범주형 프로파일링 (정량적 및 플롯).profiling_num(data): 수치형 변수 프로파일링 (정량적)plot_num(data): 수치형 변수 프로파일링 (플롯)
참고: describe는 Hmisc 패키지에 있으며, 나머지 함수는 funModeling에 있습니다.
–
1.1.1 데이터셋 상태
0, NA, Inf, 고유 값의 양과 데이터 유형은 모델의 좋고 나쁨에 영향을 미칠 수 있습니다. 다음은 데이터 모델링의 첫 단계를 다루는 접근 방식입니다.
먼저, funModeling 및 dplyr 라이브러리를 로드합니다.
1.1.1.1 결측치, 0 값, 데이터 유형 및 고유 값 확인
새로운 데이터셋을 분석할 때 가장 먼저 해야 할 일 중 하나는 결측치(R에서는 NA)가 있는지와 데이터 유형을 파악하는 것입니다.
funModeling에 포함된 df_status 함수는 상대적 값과 백분율로 이러한 수치를 보여주는 데 도움이 됩니다. 또한 무한대 값과 0 값에 대한 통계도 검색합니다.
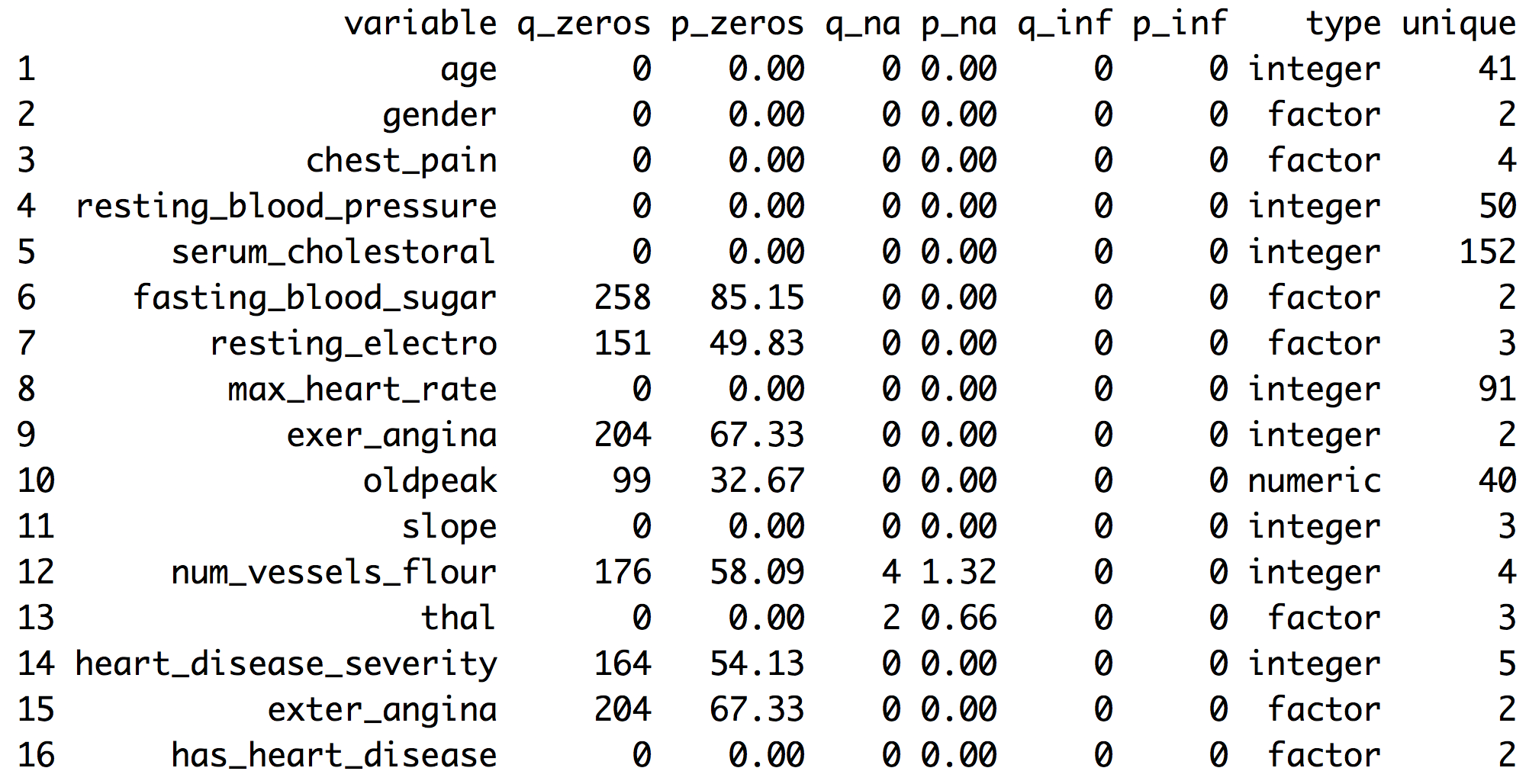
Figure 1.1: 데이터셋 상태
q_zeros: 0 값의 수 (p_zeros: 백분율)q_inf: 무한대 값의 수 (p_inf: 백분율)q_na: NA 값의 수 (p_na: 백분율)type: factor 또는 numericunique: 고유 값의 수
1.1.1.2 이러한 지표가 왜 중요할까요?
- 0 값: 0 값이 많은 변수는 모델링에 유용하지 않을 수 있으며, 어떤 경우에는 모델을 심각하게 편향시킬 수 있습니다.
- NA: 여러 모델은 NA가 있는 행을 자동으로 제외합니다(예: 랜덤 포레스트). 결과적으로 단 하나의 변수 때문에 여러 행이 누락되어 최종 모델이 편향될 수 있습니다. 예를 들어, 데이터에 100개 변수 중 90%가 NA인 변수가 하나만 있다면, 모델은 원본 행의 10%만으로 학습하게 될 것입니다.
- Inf: 무한대 값은 R의 일부 함수에서 예상치 못한 동작을 유발할 수 있습니다.
- Type: 일부 변수는 숫자로 인코딩되어 있지만, 코드나 범주이며 모델이 이를 동일한 방식으로 처리하지 않습니다.
- Unique: 고유 값의 수가 많은(약 30개) Factor/범주형 변수는 범주의 카디널리티가 낮으면 과적합되는 경향이 있습니다(예: 의사결정 트리).
1.1.1.3 불필요한 사례 필터링
df_status 함수는 데이터 프레임을 받아 앞 섹션에서 설명한 모든 지표를 기반으로 피처(또는 변수)를 빠르게 제거하는 데 도움이 되는 상태 테이블을 반환합니다. 예를 들어:
0 값이 많은 변수 제거
## variable q_zeros p_zeros q_na p_na q_inf p_inf type unique
## 1 age 0 0.00 0 0.00 0 0 integer 41
## 2 gender 0 0.00 0 0.00 0 0 factor 2
## 3 chest_pain 0 0.00 0 0.00 0 0 factor 4
## 4 resting_blood_pressure 0 0.00 0 0.00 0 0 integer 50
## 5 serum_cholestoral 0 0.00 0 0.00 0 0 integer 152
## 6 fasting_blood_sugar 258 85.15 0 0.00 0 0 factor 2
## 7 resting_electro 151 49.83 0 0.00 0 0 factor 3
## 8 max_heart_rate 0 0.00 0 0.00 0 0 integer 91
## 9 exer_angina 204 67.33 0 0.00 0 0 integer 2
## 10 oldpeak 99 32.67 0 0.00 0 0 numeric 40
## 11 slope 0 0.00 0 0.00 0 0 integer 3
## 12 num_vessels_flour 176 58.09 4 1.32 0 0 integer 4
## 13 thal 0 0.00 2 0.66 0 0 factor 3
## 14 heart_disease_severity 164 54.13 0 0.00 0 0 integer 5
## 15 exter_angina 204 67.33 0 0.00 0 0 factor 2
## 16 has_heart_disease 0 0.00 0 0.00 0 0 factor 2# Removing variables with 60% of zero values
vars_to_remove=filter(my_data_status, p_zeros > 60) %>% pull(variable)
vars_to_remove## [1] "fasting_blood_sugar" "exer_angina" "exter_angina"# Keeping all columns except the ones present in 'vars_to_remove' vector
heart_disease_2=select(heart_disease, -any_of(vars_to_remove))0 값 백분율에 따라 데이터 정렬
## variable q_zeros p_zeros
## 1 fasting_blood_sugar 258 85.15
## 2 exer_angina 204 67.33
## 3 exter_angina 204 67.33
## 4 num_vessels_flour 176 58.09
## 5 heart_disease_severity 164 54.13
## 6 resting_electro 151 49.83
## 7 oldpeak 99 32.67
## 8 age 0 0.00
## 9 gender 0 0.00
## 10 chest_pain 0 0.00
## 11 resting_blood_pressure 0 0.00
## 12 serum_cholestoral 0 0.00
## 13 max_heart_rate 0 0.00
## 14 slope 0 0.00
## 15 thal 0 0.00
## 16 has_heart_disease 0 0.00동일한 논리가 특정 임계값 이상 또는 이하의 변수를 제거(또는 유지)하려는 경우에도 적용됩니다. 결측치가 포함된 변수를 다룰 때의 함의에 대한 자세한 정보는 결측치 장을 참조하십시오.
1.1.1.4 이러한 주제에 대해 더 깊이 알아보기
df_status가 반환하는 값은 다른 장에서 심층적으로 다루고 있습니다:
1.1.1.5 기타 일반적인 통계 얻기: 총 행 수, 총 열 수 및 열 이름:
## [1] 303## [1] 16## [1] "age" "gender" "chest_pain"
## [4] "resting_blood_pressure" "serum_cholestoral" "fasting_blood_sugar"
## [7] "resting_electro" "max_heart_rate" "exer_angina"
## [10] "oldpeak" "slope" "num_vessels_flour"
## [13] "thal" "heart_disease_severity" "exter_angina"
## [16] "has_heart_disease"–
1.1.2 범주형 변수 프로파일링
최신 ‘funModeling’ 버전(>= 1.6)을 사용하고 있는지 확인하십시오.
freq 함수는 빈도 또는 분포 분석을 간편하게 만듭니다. 이 함수는 분포를 테이블과 플롯(기본값)으로 검색하고 절대 및 상대 숫자의 분포를 보여줍니다.
두 변수에 대한 분포를 원한다면:
## Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
## of ggplot2 3.3.4.
## ℹ The deprecated feature was likely used in the funModeling package.
## Please report the issue at <https://github.com/pablo14/funModeling/issues>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.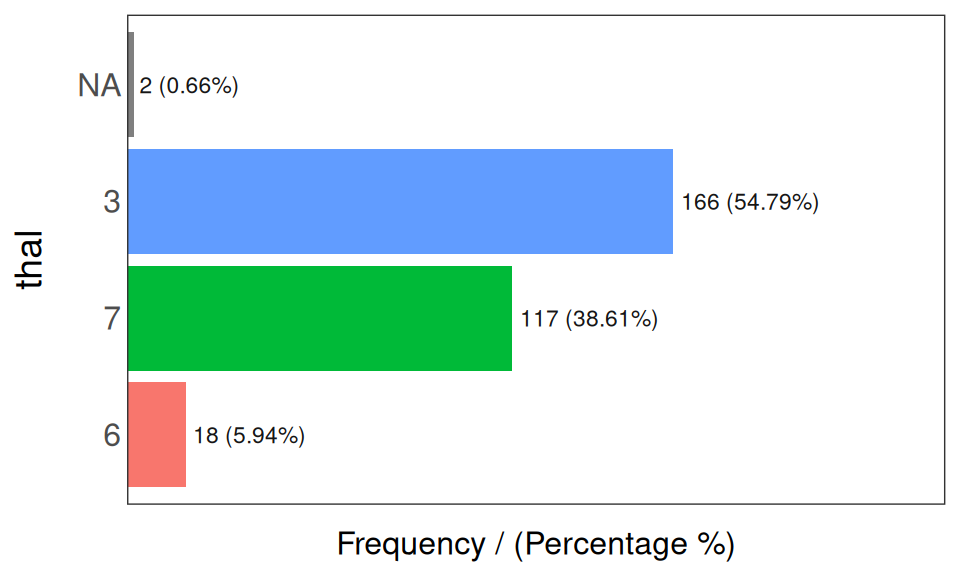
Figure 1.2: 빈도 분석 1
## thal frequency percentage cumulative_perc
## 1 3 166 54.79 54.79
## 2 7 117 38.61 93.40
## 3 6 18 5.94 99.34
## 4 <NA> 2 0.66 100.00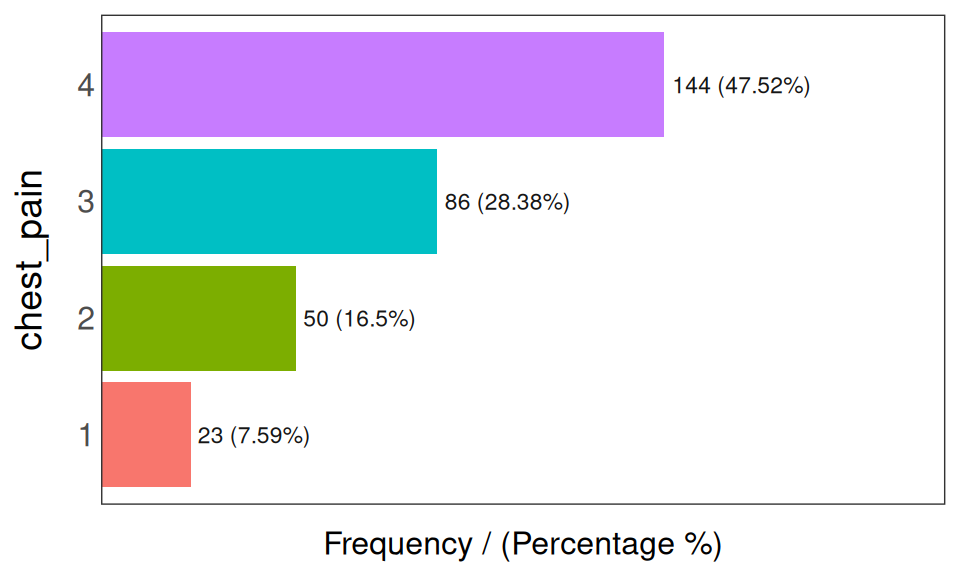
Figure 1.3: 빈도 분석 2
## chest_pain frequency percentage cumulative_perc
## 1 4 144 47.52 47.52
## 2 3 86 28.38 75.90
## 3 2 50 16.50 92.40
## 4 1 23 7.59 100.00## [1] "Variables processed: thal, chest_pain"나머지 funModeling 함수와 마찬가지로 input이 없으면 주어진 데이터 프레임에 있는 모든 factor 또는 character 변수에 대해 실행됩니다.
플롯을 제외하고 테이블만 출력하려면 plot 매개변수를 FALSE로 설정합니다.
freq 예시는 단일 변수를 입력으로 처리할 수도 있습니다.
기본적으로 NA 값은 테이블과 플롯 모두에서 고려됩니다. NA를 제외해야 한다면 na.rm = TRUE로 설정하십시오.
다음 줄에 있는 두 가지 예시:
하나의 변수만 제공되면 freq는 출력된 테이블을 반환하므로, 제공되는 변수를 기반으로 일부 계산을 쉽게 수행할 수 있습니다.
- 예를 들어, 공유의 80% 이상을 차지하는 범주를 출력하는 것(
cumulative_perc < 80을 기반으로). - 긴 꼬리에 속하는 범주를 얻는 것, 즉
percentage < 1로 필터링하여 1% 미만으로 나타나는 범주를 검색하는 것.
또한, 패키지의 다른 플롯 함수와 마찬가지로 플롯을 내보내야 하는 경우 path_out 매개변수를 추가하면 폴더가 아직 생성되지 않았다면 생성됩니다.
1.1.2.0.1 분석
출력은 frequency 변수에 따라 정렬되므로, 가장 빈번한 범주와 이들이 차지하는 비중(cummulative_perc 변수)을 빠르게 분석할 수 있습니다. 일반적으로 우리는 인간으로서 질서를 좋아합니다. 변수가 정렬되어 있지 않으면 우리의 눈은 모든 막대를 비교하기 위해 움직이고, 우리의 뇌는 각 막대를 다른 막대와 관련하여 배치합니다.
동일한 데이터 입력에 대해 정렬되지 않은 경우와 정렬된 경우의 차이를 확인해 보세요:
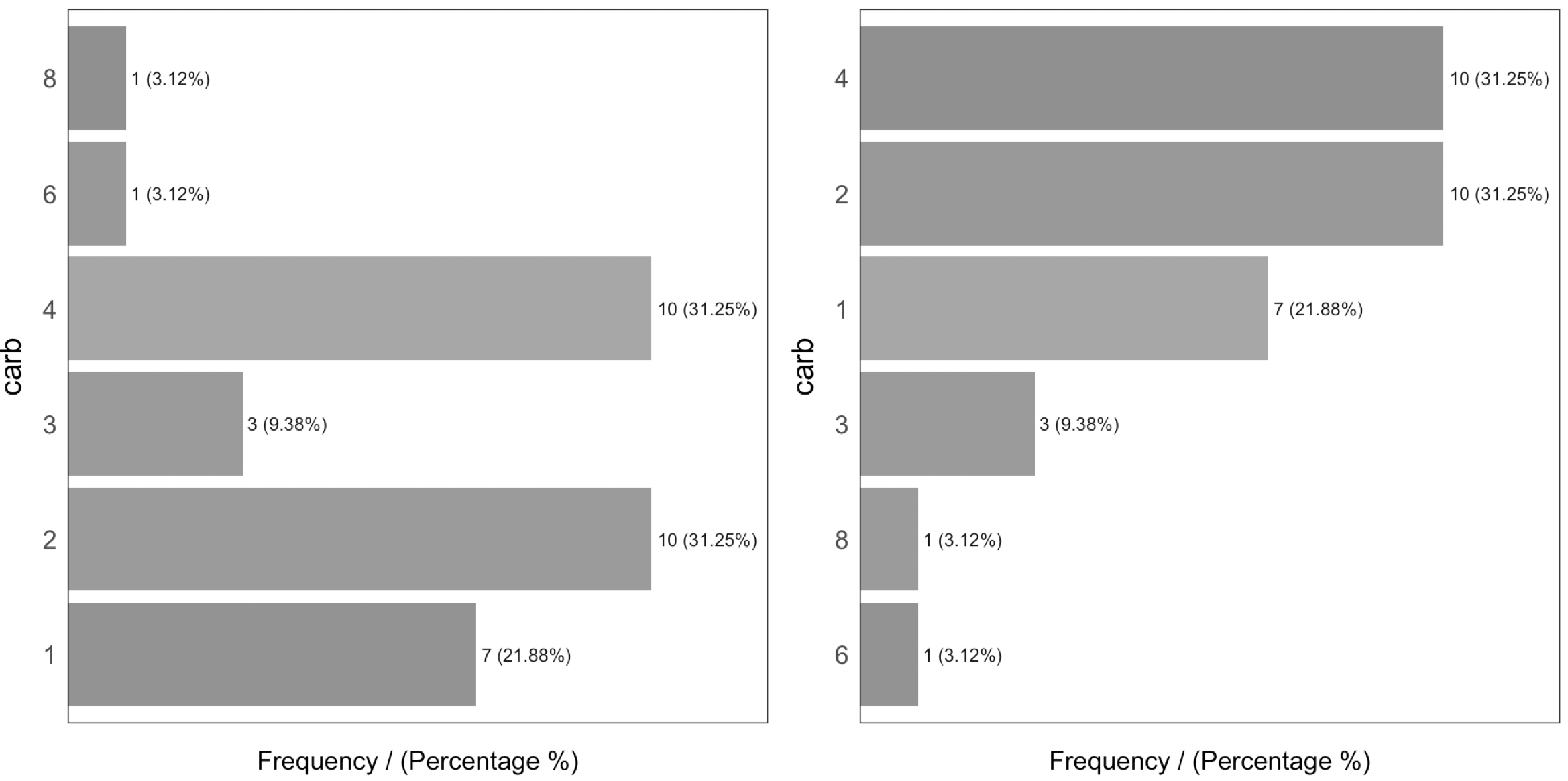
Figure 1.4: 순서와 아름다움
일반적으로 대부분의 경우에 나타나는 범주는 소수에 불과합니다.
더 자세한 분석은 기술 통계에서의 고카디널리티 변수에서 확인하세요.
1.1.2.1 describe 함수 소개
이 함수는 Hmisc 패키지에 포함되어 있으며, 수치형 및 범주형 변수 모두에 대해 전체 데이터셋을 빠르게 프로파일링할 수 있게 해줍니다. 이 경우, 우리는 두 개의 변수만 선택하고 결과를 분석할 것입니다.
# Just keeping two variables to use in this example
heart_disease_3=select(heart_disease, thal, chest_pain)
# Profiling the data!
describe(heart_disease_3)## heart_disease_3
##
## 2 Variables 303 Observations
## --------------------------------------------------------------------------------
## thal
## n missing distinct
## 301 2 3
##
## Value 3 6 7
## Frequency 166 18 117
## Proportion 0.551 0.060 0.389
## --------------------------------------------------------------------------------
## chest_pain
## n missing distinct
## 303 0 4
##
## Value 1 2 3 4
## Frequency 23 50 86 144
## Proportion 0.076 0.165 0.284 0.475
## --------------------------------------------------------------------------------여기서:
n:NA가 아닌 행의 수. 이 경우, 숫자를 포함하는 환자가301명있음을 나타냅니다.missing: 결측치의 수. 이 지표를n에 더하면 총 행 수가 됩니다.unique: 고유(또는 구별되는) 값의 수.
다른 정보는 freq 함수와 매우 유사하며, 각기 다른 범주에 대해 상대적 및 절대적 값으로 총 수를 괄호 안에 반환합니다.
–
1.1.3 수치형 변수 프로파일링
이 섹션은 두 부분으로 나뉩니다:
- 파트 1: “월드 데이터” 사례 연구 소개
- 파트 2: R에서 수치형 프로파일링 수행
데이터 월드의 데이터 준비 단계가 어떻게 계산되는지 알고 싶지 않다면, 프로파일링이 시작되는 “파트 2: R에서 수치형 프로파일링 수행”으로 건너뛰셔도 좋습니다.
1.1.3.1 파트 1: 월드 데이터 사례 연구 소개
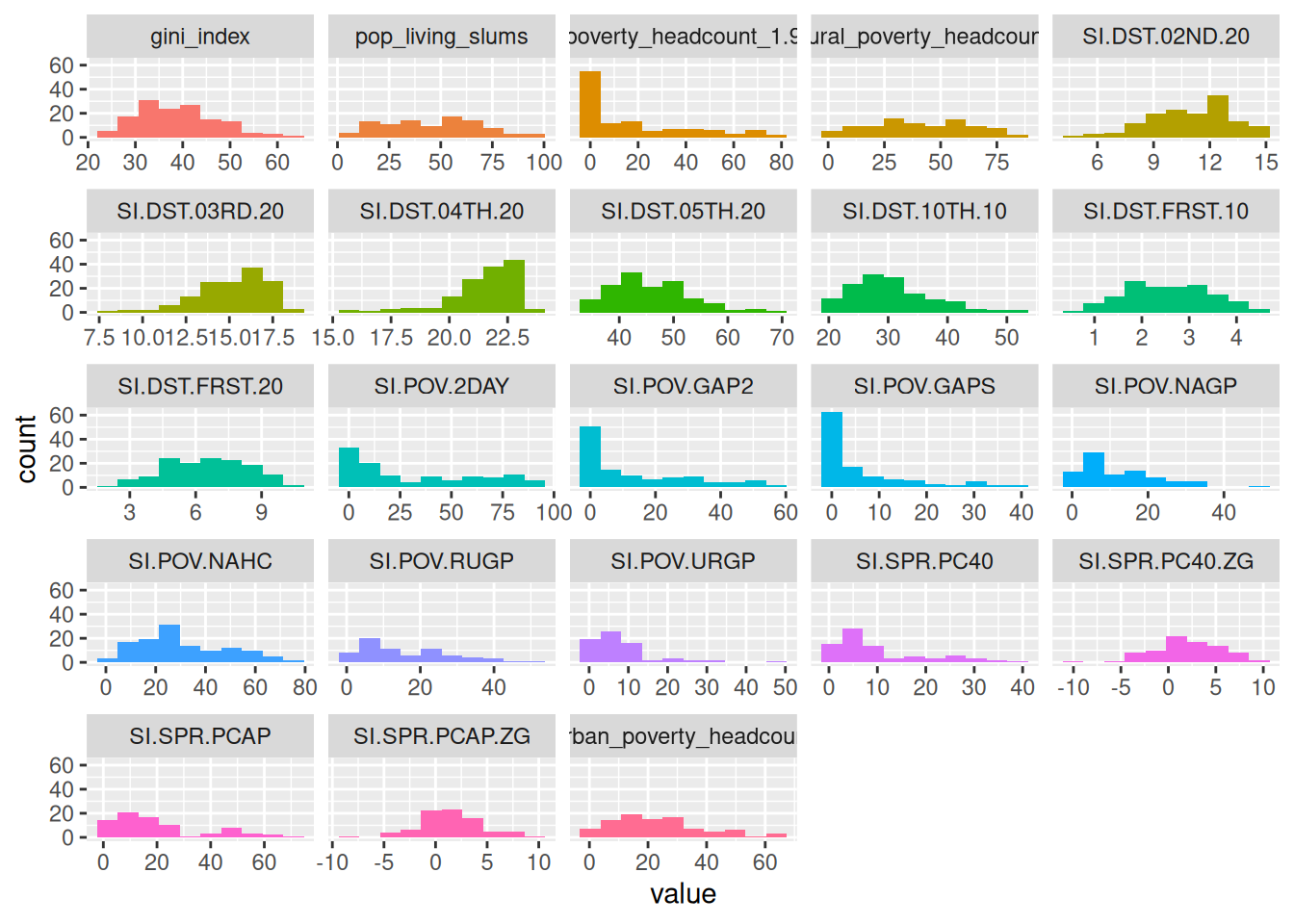
이 데이터에는 세계 개발과 관련된 많은 지표가 포함되어 있습니다. 프로파일링 예제와는 별개로, 이 종류의 데이터 분석에 관심이 있는 사회학자, 연구원 등을 위해 바로 사용할 수 있는 테이블을 제공하는 것이 목적입니다.
원본 데이터 출처는 다음과 같습니다: http://databank.worldbank.org. 거기서 모든 변수를 설명하는 데이터 사전을 찾을 수 있습니다.
먼저, 데이터 정리가 필요합니다. 각 지표별로 가장 최신 값을 유지할 것입니다.
library(Hmisc)
# Loading data from the book repository without altering the format
data_world=read.csv(file = "https://goo.gl/2TrDgN", header = T, stringsAsFactors = F, na.strings = "..")
# Excluding missing values in Series.Code. The data downloaded from the web page contains four lines with "free-text" at the bottom of the file.
data_world=filter(data_world, Series.Code!="")
# The magical function that keeps the newest values for each metric. If you're not familiar with R, then skip it.
max_ix<-function(d)
{
ix=which(!is.na(d))
res=ifelse(length(ix)==0, NA, d[max(ix)])
return(res)
}
data_world$newest_value=apply(data_world[,5:ncol(data_world)], 1, FUN=max_ix)
# Printing the first three rows
head(data_world, 3)## Series.Name Series.Code
## 1 Population living in slums (% of urban population) EN.POP.SLUM.UR.ZS
## 2 Population living in slums (% of urban population) EN.POP.SLUM.UR.ZS
## 3 Population living in slums (% of urban population) EN.POP.SLUM.UR.ZS
## Country.Name Country.Code X1990..YR1990. X2000..YR2000. X2007..YR2007.
## 1 Afghanistan AFG NA NA NA
## 2 Albania ALB NA NA NA
## 3 Algeria DZA 11.8 NA NA
## X2008..YR2008. X2009..YR2009. X2010..YR2010. X2011..YR2011. X2012..YR2012.
## 1 NA NA NA NA NA
## 2 NA NA NA NA NA
## 3 NA NA NA NA NA
## X2013..YR2013. X2014..YR2014. X2015..YR2015. X2016..YR2016. newest_value
## 1 NA 62.7 NA NA 62.7
## 2 NA NA NA NA NA
## 3 NA NA NA NA 11.8Series.Name과 Series.Code 열은 분석할 지표입니다.
Country.Name과 Country.Code는 국가입니다. 각 행은 국가와 지표의 고유한 조합을 나타냅니다.
나머지 열인 X1990..YR1990. (1990년), X2000..YR2000. (2000년), X2007..YR2007. (2007년) 등은 해당 연도의 지표 값을 나타내며, 각 열은 연도입니다.
1.1.3.2 데이터 과학자의 의사결정
일부 국가에서는 해당 연도에 지표 측정이 없어 NA 값이 많습니다. 이 시점에서 우리는 데이터 과학자로서 결정을 내려야 합니다. 전문가(예: 사회학자)에게 묻지 않는다면 최적의 결정은 아닐 것입니다.
NA 값은 어떻게 처리할까요? 이 경우, 모든 지표에 대해 가장 최신 값을 유지할 것입니다. 아마도 어떤 국가의 정보는 2016년까지 업데이트되어 있고, 다른 국가는 2009년까지만 업데이트되어 있을 것이므로, 논문 결론을 도출하는 데 최선의 방법은 아닐 수 있습니다. 하지만 첫 번째 분석을 위해 모든 지표를 최신 데이터와 비교하는 것은 유효한 접근 방식입니다.
다른 해결책은 가장 최신 값을 유지하되, 이 숫자가 지난 5년 이내의 값인 경우에만 유지하는 것이었을 수 있습니다. 이렇게 하면 분석할 국가의 수가 줄어들 것입니다.
이러한 질문들은 인공지능 시스템이 답하기 불가능하지만, 이 결정은 결과에 극적인 영향을 미칠 수 있습니다.
마지막 변환
다음 단계는 마지막 테이블을 ‘롱(long)’ 형식에서 ‘와이드(wide)’ 형식으로 변환하는 것입니다. 즉, 각 행은 국가를 나타내고 각 열은 지표를 나타냅니다(지표-국가 조합별 ’최신 값’을 포함하는 이전 변환 덕분입니다).
지표 이름이 명확하지 않으므로, 그중 몇 가지를 “번역”할 것입니다.
# Get the list of indicator descriptions.
names=unique(select(data_world, Series.Name, Series.Code))
head(names, 5)## Series.Name Series.Code
## 1 Population living in slums (% of urban population) EN.POP.SLUM.UR.ZS
## 218 Income share held by second 20% SI.DST.02ND.20
## 435 Income share held by third 20% SI.DST.03RD.20
## 652 Income share held by fourth 20% SI.DST.04TH.20
## 869 Income share held by highest 20% SI.DST.05TH.20# Convert a few
df_conv_world=data.frame(
new_name=c("urban_poverty_headcount",
"rural_poverty_headcount",
"gini_index",
"pop_living_slums",
"poverty_headcount_1.9"),
Series.Code=c("SI.POV.URHC",
"SI.POV.RUHC",
"SI.POV.GINI",
"EN.POP.SLUM.UR.ZS",
"SI.POV.DDAY"),
stringsAsFactors = F)
# adding the new indicator value
data_world_2 = left_join(data_world,
df_conv_world,
by="Series.Code")
data_world_2 =
mutate(data_world_2, Series.Code_2=
ifelse(!is.na(new_name),
as.character(data_world_2$new_name),
data_world_2$Series.Code)
)모든 지표의 의미는 data.worldbank.org에서 확인할 수 있습니다. 예를 들어, EN.POP.SLUM.UR.ZS가 무엇을 의미하는지 알고 싶다면, http://data.worldbank.org/indicator/EN.POP.SLUM.UR.ZS를 입력하면 됩니다.
# The package 'reshape2' contains both 'dcast' and 'melt' functions
library(reshape2)
data_world_wide=dcast(data_world_2, Country.Name ~ Series.Code_2, value.var = "newest_value")참고: reshape2 패키지를 사용하여 long 및 wide 형식에 대해 더 자세히 이해하고, 이들 간에 변환하는 방법에 대해 알아보려면 http://seananderson.ca/2013/10/19/reshape.html을 참조하십시오.
이제 분석할 최종 테이블이 준비되었습니다:
## Country.Name gini_index pop_living_slums poverty_headcount_1.9
## 1 Afghanistan NA 62.7 NA
## 2 Albania 28.96 NA 1.06
## 3 Algeria NA 11.8 NA
## rural_poverty_headcount SI.DST.02ND.20 SI.DST.03RD.20 SI.DST.04TH.20
## 1 38.3 NA NA NA
## 2 15.3 13.17 17.34 22.81
## 3 4.8 NA NA NA
## SI.DST.05TH.20 SI.DST.10TH.10 SI.DST.FRST.10 SI.DST.FRST.20 SI.POV.2DAY
## 1 NA NA NA NA NA
## 2 37.82 22.93 3.66 8.85 6.79
## 3 NA NA NA NA NA
## SI.POV.GAP2 SI.POV.GAPS SI.POV.NAGP SI.POV.NAHC SI.POV.RUGP SI.POV.URGP
## 1 NA NA 8.4 35.8 9.3 5.6
## 2 1.43 0.22 2.9 14.3 3.0 2.9
## 3 NA NA NA 5.5 0.8 1.1
## SI.SPR.PC40 SI.SPR.PC40.ZG SI.SPR.PCAP SI.SPR.PCAP.ZG urban_poverty_headcount
## 1 NA NA NA NA 27.6
## 2 4.08 -1.2205 7.41 -1.3143 13.6
## 3 NA NA NA NA 5.8–
1.1.3.3 파트 2: R에서 수치형 프로파일링 수행 {#numerical-profiling-in-r}
다음 함수들을 살펴볼 것입니다:
Hmisc패키지의describefunModeling패키지의profiling_num(전체 단변량 분석) 및plot_num(히스토그램)
예시로 두 변수만 선택할 것입니다:
library(Hmisc) # contains the `describe` function
vars_to_profile=c("gini_index", "poverty_headcount_1.9")
data_subset=select(data_world_wide, any_of(vars_to_profile))
# Using the `describe` on a complete dataset. # It can be run with one variable; for example, describe(data_subset$poverty_headcount_1.9)
describe(data_subset)## data_subset
##
## 2 Variables 217 Observations
## --------------------------------------------------------------------------------
## gini_index
## n missing distinct Info Mean pMedian Gmd .05
## 140 77 136 1 38.8 38.39 9.594 26.81
## .10 .25 .50 .75 .90 .95
## 27.58 32.35 37.69 43.92 50.47 53.53
##
## lowest : 24.09 25.59 25.9 26.12 26.13, highest: 56.24 60.46 60.79 60.97 63.38
## --------------------------------------------------------------------------------
## poverty_headcount_1.9
## n missing distinct Info Mean pMedian Gmd .05
## 116 101 107 1 18.33 15.18 23.56 0.025
## .10 .25 .50 .75 .90 .95
## 0.075 1.052 6.000 33.815 54.045 67.328
##
## lowest : 0 0.01 0.03 0.04 0.06 , highest: 68.64 68.74 70.91 77.08 77.84
## --------------------------------------------------------------------------------poverty_headcount_1.9 (2011년 국제 가격 기준 하루 1.90달러 미만으로 생활하는 인구의 비율)를 다음과 같이 설명할 수 있습니다:
n: 결측치가 없는 행의 수. 이 경우, 숫자를 포함하는 국가가116개임을 나타냅니다.missing: 결측치 수. 이 지표를n에 더하면 총 행 수가 됩니다. 거의 절반의 국가에 데이터가 없습니다.unique: 고유(또는 구분되는) 값의 수.Info: 변수에 존재하는 정보량의 추정치이며 이 시점에서는 중요하지 않습니다.Mean: 고전적인 평균.- Numbers:
.05,.10,.25,.50,.75,.90,.95는 백분위수를 나타냅니다. 이 값들은 분포를 설명하는 데 매우 유용합니다. 나중에 심층적으로 다룰 것입니다. 예를 들어,.05는 5번째 백분위수입니다. lowest및highest: 가장 낮은/가장 높은 다섯 가지 값. 여기서 이상치와 데이터 오류를 발견할 수 있습니다. 예를 들어, 변수가 백분율을 나타낸다면 음수 값을 포함할 수 없습니다.
다음 함수는 profiling_num이며, 데이터 프레임을 받아들여 방대한 테이블을 검색합니다. 이 테이블은 마치 영화 ’매트릭스’에서 볼 수 있는 것과 유사하게 수많은 지표의 바다 속에서 압도당하기 쉽습니다.

Figure 1.5: 데이터의 매트릭스
영화 “매트릭스”(1999). 워쇼스키 형제(감독).
다음 테이블의 목적은 사용자에게 완벽한 지표 세트를 제공하여, 연구에 어떤 지표를 선택할지 결정할 수 있도록 하는 것입니다.
참고: 모든 지표 뒤에는 많은 통계 이론이 있습니다. 여기서는 개념을 소개하기 위해 작고 매우 단순화된 접근 방식을 다룰 것입니다.
library(funModeling)
# Full numerical profiling in one function automatically excludes non-numerical variables
profiling_num(data_world_wide)## variable mean std_dev variation_coef p_01
## 1 gini_index 38.798571 8.4918157 0.21886929 25.710900
## 2 pop_living_slums 45.698958 23.6568472 0.51766710 6.830000
## 3 poverty_headcount_1.9 18.333707 22.7448672 1.24060384 0.000000
## 4 rural_poverty_headcount 41.239393 21.9073185 0.53122311 2.902000
## 5 SI.DST.02ND.20 10.940286 2.1659949 0.19798339 5.568000
## 6 SI.DST.03RD.20 15.187571 2.0341395 0.13393448 9.137400
## 7 SI.DST.04TH.20 21.456357 1.4915663 0.06951629 16.286100
## 8 SI.DST.05TH.20 45.891714 7.1385549 0.15555215 35.004300
## 9 SI.DST.10TH.10 30.510786 6.7513063 0.22127606 20.729200
## 10 SI.DST.FRST.10 2.544571 0.8695044 0.34170958 0.915600
## 11 SI.DST.FRST.20 6.524714 1.8737104 0.28717125 2.614300
## 12 SI.POV.2DAY 32.370603 30.6360176 0.94641478 0.060500
## 13 SI.POV.GAP2 14.163017 16.4036041 1.15819983 0.011500
## 14 SI.POV.GAPS 6.892241 10.0965534 1.46491581 0.000000
## 15 SI.POV.NAGP 12.246689 10.1167055 0.82607676 0.420700
## 16 SI.POV.NAHC 30.695310 17.8844702 0.58264503 1.842000
## 17 SI.POV.RUGP 15.870000 11.8254018 0.74514189 0.740000
## 18 SI.POV.URGP 8.281972 8.2393371 0.99485211 0.300000
## 19 SI.SPR.PC40 10.306375 9.7539668 0.94640131 0.856500
## 20 SI.SPR.PC40.ZG 1.958495 3.6212194 1.84898052 -6.231772
## 21 SI.SPR.PCAP 21.066000 17.4406999 0.82790752 2.426400
## 22 SI.SPR.PCAP.ZG 1.457513 3.2074948 2.20066251 -5.897152
## 23 urban_poverty_headcount 23.281195 15.0598876 0.64686918 0.579000
## p_05 p_25 p_50 p_75 p_95 p_99 skewness kurtosis
## 1 26.81450 32.34750 37.6850 43.92250 53.53400 60.899800 0.55162475 2.874236
## 2 10.75000 25.17500 46.2000 65.62500 83.37500 93.415000 0.08655596 2.045147
## 3 0.02500 1.05250 6.0000 33.81500 67.32750 76.154500 1.12464564 2.947020
## 4 6.46500 25.25000 38.1000 57.60000 75.77601 81.696000 0.05070376 1.967226
## 5 7.36050 9.52750 11.1350 12.61250 14.20050 14.572200 -0.41139253 2.695430
## 6 11.82750 13.87750 15.4600 16.69750 17.86200 18.144400 -0.87594286 3.843357
## 7 18.28850 20.75750 21.9100 22.52250 23.01300 23.387600 -1.53741889 5.599431
## 8 36.35950 40.49500 44.8250 49.82750 58.11500 65.894000 0.73763641 3.317412
## 9 21.98850 25.71000 29.4950 34.11500 42.21150 50.616500 0.90532034 3.596310
## 10 1.14750 1.88500 2.5400 3.23750 3.88200 4.346600 0.04275050 2.212272
## 11 3.36950 5.09250 6.5050 8.00000 9.39200 9.996600 -0.11850862 2.232570
## 12 0.39250 3.82750 20.2700 63.20500 84.57750 90.341000 0.53561716 1.757298
## 13 0.08500 1.30500 5.5250 26.30000 48.53000 56.178500 1.06276529 2.871285
## 14 0.00000 0.28750 1.4150 10.29250 31.45500 38.288000 1.65405890 4.701748
## 15 1.22500 4.50000 8.6500 16.95000 32.42500 36.720000 1.12937489 3.982550
## 16 6.43000 16.35000 26.6000 44.25000 62.98000 71.640000 0.52875485 2.375444
## 17 1.65000 5.95000 13.6000 22.45000 37.70000 45.290000 0.80102636 2.955030
## 18 0.90000 2.90000 6.3000 9.95000 25.15000 35.170000 2.31559531 9.765938
## 19 1.22850 3.47500 6.9450 12.69250 28.86750 35.350200 1.25086949 3.366531
## 20 -3.02107 -0.08445 1.7137 4.64300 7.92913 8.996918 -0.29366391 3.271338
## 21 3.13750 8.00250 15.2750 25.41500 52.83700 67.168600 1.13166760 3.296606
## 22 -3.80500 -0.48640 1.3242 3.55805 7.01655 8.481370 -0.01843620 3.593681
## 23 3.14000 12.70750 20.1000 31.17500 51.03500 61.754000 0.72974377 2.973982
## iqr range_98 range_80
## 1 11.57500 [25.7109, 60.8998] [27.576, 50.469]
## 2 40.45000 [6.83, 93.415] [12.5, 75.2]
## 3 32.76250 [0, 76.1545] [0.075, 54.045]
## 4 32.35000 [2.902, 81.696] [13.99, 71.99]
## 5 3.08500 [5.568, 14.5722] [8.283, 13.802]
## 6 2.82000 [9.1374, 18.1444] [12.667, 17.503]
## 7 1.76500 [16.2861, 23.3876] [19.733, 22.813]
## 8 9.33250 [35.0043, 65.894] [36.995, 55.242]
## 9 8.40500 [20.7292, 50.6165] [22.569, 39.89]
## 10 1.35250 [0.9156, 4.3466] [1.479, 3.674]
## 11 2.90750 [2.6143, 9.9966] [3.986, 8.891]
## 12 59.37750 [0.0605, 90.341] [0.79, 78.29]
## 13 24.99500 [0.0115, 56.1785] [0.155, 40.85]
## 14 10.00500 [0, 38.288] [0.025, 23.45]
## 15 12.45000 [0.4207, 36.7200000000001] [1.85, 27]
## 16 27.90000 [1.842, 71.64] [9.86, 58.22]
## 17 16.50000 [0.74, 45.29] [3.3, 32.2]
## 18 7.05000 [0.3, 35.17] [1.3, 19.1]
## 19 9.21750 [0.8565, 35.3502] [1.809, 27.627]
## 20 4.72745 [-6.231772, 8.99691799999999] [-2.64254, 6.48298]
## 21 17.41250 [2.4264, 67.1686] [4.247, 49.224]
## 22 4.04445 [-5.897152, 8.48136999999999] [-2.0726, 5.17284]
## 23 18.46749 [0.579, 61.754] [5.98, 46.11]각 지표에는 존재 이유가 있습니다:
variable: 변수 이름mean: 잘 알려진 평균.std_dev: 표준 편차, 평균값을 중심으로 한 분산 또는 퍼짐 정도를 나타내는 척도입니다.0에 가까운 값은 거의 변동이 없음을 의미하며(따라서 상수에 가깝게 보임), 반대로 _높음_의 기준을 정하기는 어렵지만, 변동이 클수록 퍼짐이 더 크다고 말할 수 있습니다. 혼돈은 무한한 표준 편차처럼 보일 수 있습니다. 단위는 평균과 동일하여 비교 가능합니다.variation_coef: 변동 계수=std_dev/mean.std_dev는 절대값이므로,std_dev를mean과 비교하여 상대적인 숫자로 나타내는 지표가 좋습니다.0.22는std_dev가mean의 22%임을 나타냅니다.0에 가까우면 변수가 평균을 중심으로 더 집중되는 경향이 있습니다. 두 분류기를 비교할 때, 정확도에서std_dev와variation_coef가 더 낮은 분류기를 선호할 수 있습니다.p_01,p_05,p_25,p_50,p_75,p_95,p_99: 백분위수 (1%, 5%, 25% 등). 이 장의 후반부에서 백분위수에 대한 완전한 검토가 있습니다.
백분위수에 대한 자세한 설명은 부록 1: 백분위수의 마법을 참조하십시오.
skewness: 비대칭성을 측정하는 척도입니다. 0에 가까우면 분포가 평균을 중심으로 동일하게 분포(또는 대칭)되어 있음을 나타냅니다. 양수는 오른쪽에 긴 꼬리가 있음을 의미하며, 음수는 그 반대를 의미합니다. 이 섹션 뒤에 플롯에서 왜도를 확인하십시오. 변수pop_living_slums는 0에 가깝고(“균등하게” 분포),poverty_headcount_1.9는 양수(오른쪽에 꼬리),SI.DST.04TH.20은 음수(왼쪽에 꼬리)입니다. 왜도가 0에서 멀어질수록 분포에 이상치가 있을 가능성이 높습니다.kurtosis: 분포의 꼬리를 설명합니다. 간단히 말해, 숫자가 높을수록 이상치의 존재를 나타낼 수 있습니다 (나중에SI.POV.URGP변수에서50근처에 이상치가 있는 것을 볼 수 있듯이). 왜도 및 첨도에 대한 완전한 검토는 참고 문헌 (McNeese 2016) 및 (Handbook 2013)를 참조하십시오.iqr: 사분위 범위는 백분위수0.25와0.75를 살펴본 결과이며, 동일한 변수 단위로 값의 50%의 분산 길이를 나타냅니다. 값이 높을수록 변수가 더 희소합니다.range_98및range_80: 값의98%가 있는 범위를 나타냅니다. 하위 및 상위 1%를 제거합니다(따라서98%숫자). 잠재적인 이상치 없이 변수 범위를 아는 것이 좋습니다. 예를 들어,pop_living_slums는0에서76.15까지입니다.min및max값을 비교하는 것보다 더 견고합니다.range_80은range_98과 동일하지만 하위 및 상위10%를 제외합니다.
iqr, range_98, range_80은 백분위수를 기반으로 하며, 이 장의 후반부에서 다룰 것입니다.
중요: 모든 지표는 NA 값을 제거한 후에 계산됩니다. 그렇지 않으면 테이블이 NA로 채워질 것입니다.
1.1.3.3.1 profiling_num 사용 시 조언
profiling_num의 목표는 데이터 과학자에게 모든 종류의 지표를 제공하여 가장 적절한 것을 선택할 수 있도록 돕는 것입니다. 이는 dplyr 패키지의 select 함수를 사용하면 쉽게 할 수 있습니다.
또한, profiling_num은 결과를 자동으로 콘솔에 출력하지 않을 수 있습니다.
예를 들어, mean, p_01, p_99, range_80을 가져와 보겠습니다.
my_profiling_table=profiling_num(data_world_wide) %>% select(variable, mean, p_01, p_99, range_80)
# Printing only the first three rows
head(my_profiling_table, 3)## variable mean p_01 p_99 range_80
## 1 gini_index 38.79857 25.7109 60.8998 [27.576, 50.469]
## 2 pop_living_slums 45.69896 6.8300 93.4150 [12.5, 75.2]
## 3 poverty_headcount_1.9 18.33371 0.0000 76.1545 [0.075, 54.045]profiling_num은 테이블을 반환하므로, 우리가 설정한 조건에 따라 데이터를 빠르게 필터링할 수 있다는 점을 기억해주세요.
1.1.4 최종 생각
지금까지 많은 숫자들이 등장했습니다. 백분위수 부록에는 훨씬 더 많은 숫자가 있죠. 여기서 중요한 점은 데이터를 탐색하는 올바른 접근 방식을 찾는 것입니다. 이는 다른 지표나 다른 기준에서 비롯될 수 있습니다.
df_status, describe, freq, profiling_num, plot_num 함수는 데이터 프로젝트 초기에 실행할 수 있습니다.
데이터의 정상 및 비정상적인 행동에 관해서는 둘 다 연구하는 것이 중요합니다. 데이터셋을 일반적인 용어로 설명하려면 극단값을 제외해야 합니다. 예를 들어, range_98 변수를 사용해서 말이죠. 극단값을 제외하면 평균은 감소해야 합니다.
이러한 분석은 단변량입니다. 즉, 다른 변수를 고려하지 않습니다(다변량 분석). 이는 이 책의 후반부에서 다룰 내용입니다. 한편, 입력(및 출력) 변수 간의 상관 관계는 상관 관계 장을 확인해 보세요.
![]()
1.2 상관 관계 및 관계

혼돈이 아름다움을 표현하는 만델브로트 프랙탈; 이미지 출처: Wikipedia.
1.2.1 이 장의 내용은 무엇일까요?
이 장은 변수에서 상관 관계를 측정하는 방법론적 및 실제적 측면을 모두 다룹니다. 우리는 ’상관 관계’라는 단어가 “함수적 관계”로 번역될 수 있음을 알게 될 것입니다.
방법론적인 측면에서는 Anscombe Quartet을 다룰 것입니다. 이는 공간적 분포는 다르지만 동일한 상관 관계 측정값을 공유하는 네 개의 플롯 세트입니다. 더 강력한 메트릭(MIC)을 통해 관계를 다시 계산하여 한 단계 더 나아갈 것입니다.
이 책에서는 수학적 수준으로 다루지는 않지만, 앞으로 다룰 예정인 정보 이론을 여러 번 언급할 것입니다. 딥 러닝을 포함하여 많은 알고리즘이 정보 이론을 기반으로 합니다.
낮은 차원(두 변수)과 소규모 데이터(소수의 행)에서 이러한 개념을 이해하면 고차원 데이터를 더 잘 이해하는 데 도움이 됩니다. 그럼에도 불구하고, 일부 실제 사례는 ‘작은’ 데이터일 뿐입니다.
실용적인 관점에서 볼 때, 자신의 데이터로 분석을 복제하고 멋진 플롯에서 관계를 프로파일링하고 시각화할 수 있을 것입니다.
이제 필요한 모든 라이브러리를 로드하는 것으로 시작하겠습니다.
# 필요한 라이브러리 로드
library(funModeling) # heart_disease 데이터 포함
library(minerva) # MIC 통계량 포함
library(ggplot2)
library(dplyr)
library(reshape2)
library(gridExtra) # 두 개의 플롯을 한 줄에 그릴 수 있도록 함
options(scipen=999) # 과학적 표기법 비활성화1.2.2 선형 상관 관계 {#linear-correlation}
아마도 수치형 변수에 대한 가장 표준적인 상관 관계 측정값은 R 통계량(또는 피어슨 계수)일 것입니다. 이는 1(양의 상관 관계)에서 -1(음의 상관 관계)까지의 값을 가집니다. 0에 가까운 값은 상관 관계가 없음을 의미합니다.
대상 변수(예: 특성 공학을 수행하기 위함)를 기반으로 R 측정값을 계산하는 다음 예제를 고려해 봅시다. correlation_table 함수는 범주형/명목형 변수를 건너뛰고 모든 수치형 변수에 대한 R 메트릭을 검색합니다.
## Variable has_heart_disease
## 1 has_heart_disease 1.00
## 2 heart_disease_severity 0.83
## 3 num_vessels_flour 0.46
## 4 oldpeak 0.42
## 5 slope 0.34
## 6 age 0.23
## 7 resting_blood_pressure 0.15
## 8 serum_cholestoral 0.08
## 9 max_heart_rate -0.42heart_disease_severity 변수는 가장 중요한 수치형 변수입니다. 이 값이 높을수록 심장 질환 발병 가능성이 높아집니다(양의 상관 관계). max_heart_rate는 음의 상관 관계를 가지므로 정반대입니다.
이 숫자를 제곱하면 R-제곱 통계량(일명 R2)이 반환되며, 0(상관 관계 없음)에서 1(높은 상관 관계)까지의 값을 가집니다.
R 통계량은 이상치와 비선형 관계에 크게 영향을 받습니다.
1.2.2.1 앤스콤 쿼텟(Anscombe’s Quartet)의 상관 관계
앤스콤 쿼텟을 살펴보시죠. 위키백과의 내용을 인용합니다:
이들은 통계학자 프랜시스 앤스콤이 1973년에 데이터를 분석하기 전에 그래프로 표시하는 것의 중요성과 이상치가 통계적 속성에 미치는 영향을 모두 보여주기 위해 구성되었습니다.
1973년에 만들어졌지만 여전히 유효하다니, 정말 대단하죠.
이 네 가지 관계는 서로 다르지만, 모두 동일한 R2 값인 0.816을 가집니다.
다음 예시는 R2를 계산하고 각 쌍을 플롯합니다.
# anscombe quartet 데이터 읽기
anscombe_data =
read.delim(file="https://goo.gl/mVLz5L", header = T)
# 모든 쌍에 대한 상관 관계 (R 제곱, R2) 계산
# 모든 값이 0.86으로 동일합니다.
cor_1 = cor(anscombe_data$x1, anscombe_data$y1)
cor_2 = cor(anscombe_data$x2, anscombe_data$y2)
cor_3 = cor(anscombe_data$x3, anscombe_data$y3)
cor_4 = cor(anscombe_data$x4, anscombe_data$y4)
# 함수 정의
plot_anscombe <- function(x, y, value, type)
{
# 'anscombe_data'는 전역 변수입니다. 이것은
# 좋은 프로그래밍 습관이 아닙니다 ;)
p=ggplot(anscombe_data, aes_string(x,y)) +
geom_smooth(method='lm', fill=NA) +
geom_point(aes(colour=factor(1),
fill = factor(1)),
shape=21, size = 2
) +
ylim(2, 13) +
xlim(4, 19) +
theme_minimal() +
theme(legend.position="none") +
annotate("text",
x = 12,
y =4.5,
label =
sprintf("%s: %s",
type,
round(value,2)
)
)
return(p)
}
# 2x2 그리드에 플로팅
grid.arrange(plot_anscombe("x1", "y1", cor_1, "R2"),
plot_anscombe("x2", "y2", cor_2, "R2"),
plot_anscombe("x3", "y3", cor_3, "R2"),
plot_anscombe("x4", "y4", cor_4, "R2"),
ncol=2,
nrow=2)## Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
## ℹ Please use tidy evaluation idioms with `aes()`.
## ℹ See also `vignette("ggplot2-in-packages")` for more information.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.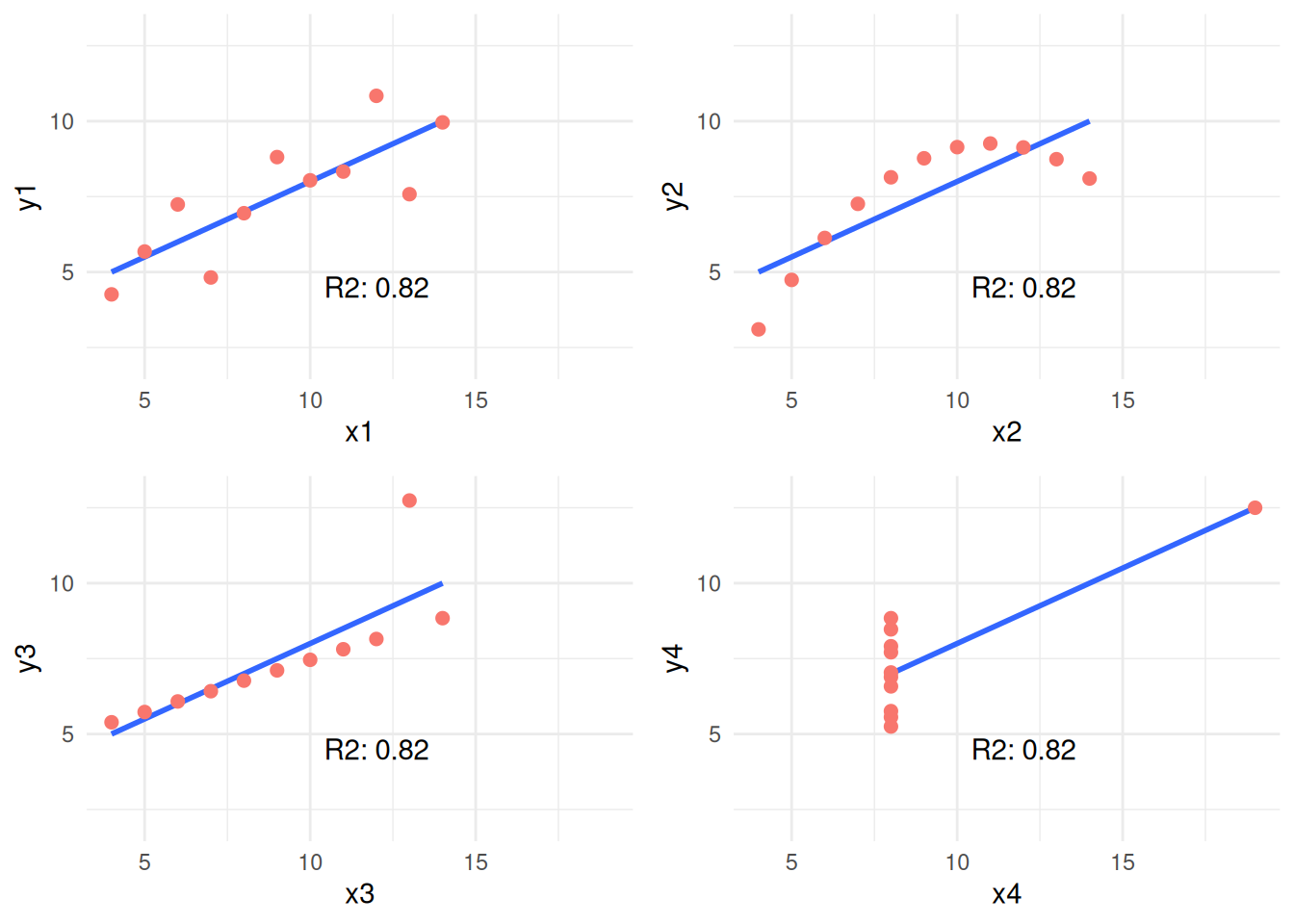
Figure 1.7: 앤스콤 셋
이 네 가지 다른 플롯은 모든 x 및 y 변수(각각 9와 7.501)에 대해 동일한 평균과 동일한 정도의 상관 관계를 가집니다. summary(anscombe_data)를 입력하여 모든 측정값을 확인할 수 있습니다.
이것이 상관 관계를 분석할 때 관계를 플롯하는 것이 매우 중요한 이유입니다.
이 데이터는 나중에 다시 다룰 것입니다. 개선될 수 있거든요! 먼저, 정보 이론의 몇 가지 개념을 소개하겠습니다.
1.2.3 정보 이론에 기반한 상관 관계
이러한 관계는 정보 이론 개념을 통해 더 잘 측정할 수 있습니다. 이를 기반으로 상관 관계를 측정하는 여러 알고리즘 중 하나는 Maximal Information-based nonparametric exploration의 약어인 MINE입니다.
R에서의 구현은 minerva 패키지에서 찾을 수 있습니다. Python과 같은 다른 언어에서도 사용할 수 있습니다.
1.2.3.1 R 예시: 완벽한 관계
함수(음의 지수 함수)를 기반으로 한 비선형 관계를 플롯하고 MIC 값을 인쇄해 보겠습니다.
x=seq(0, 20, length.out=500)
df_exp=data.frame(x=x, y=dexp(x, rate=0.65))
ggplot(df_exp, aes(x=x, y=y)) + geom_line(color='steelblue') + theme_minimal()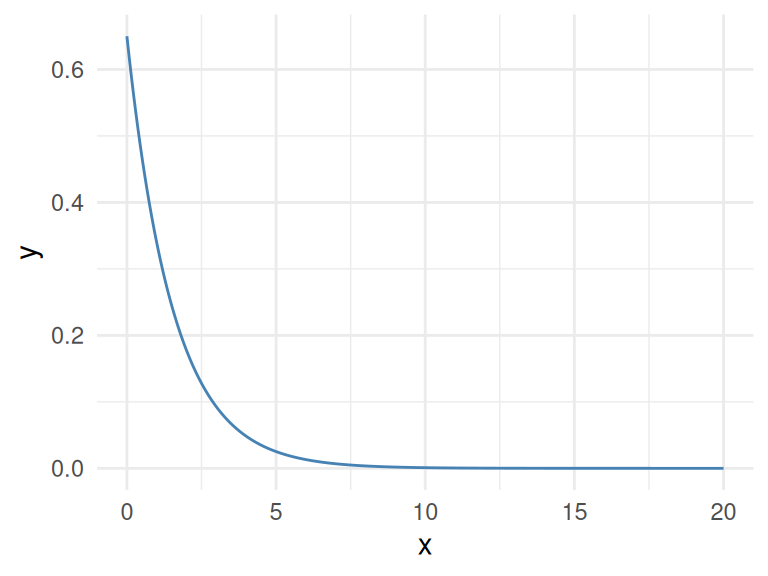
Figure 1.8: 완벽한 관계
# [1,2] 위치는 두 변수의 상관 관계를 포함하며, 각 변수 자체와의 상관 관계는 제외됩니다.
# 선형 상관 관계 계산
res_cor_R2=cor(df_exp)[1,2]^2
sprintf("R2: %s", round(res_cor_R2,2))## [1] "R2: 0.39"## [1] "MIC: 1"MIC 값은 0에서 1까지입니다. 0은 상관 관계가 없음을 의미하고 1은 가장 높은 상관 관계를 의미합니다. 해석은 R-제곱과 동일합니다.
1.2.3.2 결과 분석
MIC=1은 두 변수 사이에 완벽한 상관 관계가 있음을 나타냅니다. 만약 특성 공학을 수행하고 있다면 이 변수는 포함되어야 합니다.
단순한 상관 관계를 넘어 MIC가 말하는 것은 “이 두 변수는 함수적 관계를 보여줍니다”입니다.
기계 학습 용어(및 과도하게 단순화하자면): “변수 y는 변수 x에 종속되며, 그 관계를 모델링할 수 있는 함수(우리가 어떤 함수인지는 모르는)를 찾을 수 있습니다.”
이 관계는 실제로 함수, 즉 지수 함수를 기반으로 생성되었기 때문에 까다롭습니다.
하지만 다른 예제로 계속 진행해 봅시다…
1.2.4 노이즈 추가
노이즈는 원래 신호에 추가되는 원치 않는 신호입니다. 기계 학습에서 노이즈는 모델이 혼란스러워지는 데 일조합니다. 구체적으로 말하자면, 동일한 두 개의 입력 사례(예: 고객)가 서로 다른 결과(하나는 구매하고 다른 하나는 구매하지 않음)를 갖는 경우입니다.
이제 y_noise_1 변수를 생성하여 노이즈를 추가할 것입니다.
df_exp$y_noise_1=jitter(df_exp$y, factor = 1000, amount = NULL)
ggplot(df_exp, aes(x=x, y=y_noise_1)) +
geom_line(color='steelblue') + theme_minimal()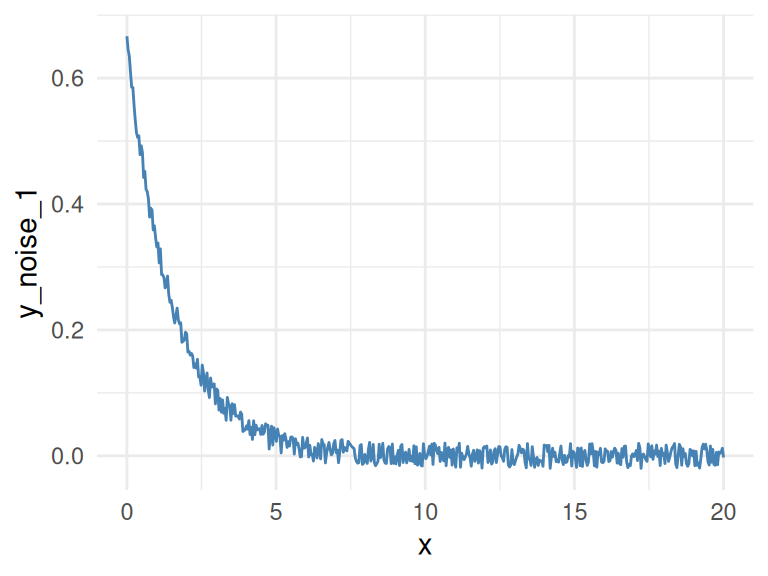
Figure 1.9: 노이즈 추가
상관 관계와 MIC를 다시 계산하고, 두 경우 모두 전체 행렬을 출력합니다. 이 행렬은 각 입력 변수가 자신을 포함한 다른 모든 변수에 대해 갖는 상관 관계/MIC 지표를 보여줍니다.
## x y y_noise_1
## x 1.0000000 0.3899148 0.3885751
## y 0.3899148 1.0000000 0.9907334
## y_noise_1 0.3885751 0.9907334 1.0000000## x y y_noise_1
## x 1.0000000 1.0000000 0.7656166
## y 1.0000000 1.0000000 0.7654646
## y_noise_1 0.7656166 0.7654646 1.0000000데이터에 노이즈를 추가하자 MIC 값은 1에서 0.7226365(-27%)로 감소했는데, 이는 훌륭합니다!
R2도 0.3899148에서 0.3866319(-0.8%)로 약간 감소했습니다.
결론: MIC는 R2보다 노이즈가 있는 관계를 훨씬 더 잘 반영하며, 상관 관계가 있는 연관성을 찾는 데 유용합니다.
마지막 예시에 대해: 함수를 기반으로 데이터를 생성하는 것은 교육 목적으로만 사용됩니다. 그러나 변수의 노이즈 개념은 출처에 관계없이 거의 모든 데이터셋에서 매우 일반적입니다. 변수에 노이즈를 추가하기 위해 아무것도 할 필요가 없습니다. 이미 거기에 있습니다. 기계 학습 모델은 데이터의 실제 형태에 접근하여 이 노이즈를 처리합니다.
두 변수 간의 관계에 존재하는 정보의 의미를 파악하는 데 MIC 측정을 사용하는 것이 매우 유용합니다.
1.2.5 비선형성 측정 (MIC-R2)
mine 함수는 여러 지표를 반환합니다. 우리는 MIC만 확인했지만, 알고리즘의 특성상(원본 논문 (Reshef et al. 2011)을 확인할 수 있습니다) 더 흥미로운 지표들을 계산합니다. res_mine_2 객체를 검사하여 모든 지표를 확인해 보세요.
그중 하나는 비선형성의 척도로 사용되는 MICR2입니다. 이는 MIC - R2를 수행하여 계산됩니다. R2가 선형성을 측정하므로, 높은 MICR2는 비선형 관계를 나타냅니다.
MICR2를 수동으로 계산하여 확인할 수 있습니다. 다음 두 행렬은 동일한 결과를 반환합니다.
비선형 관계는 모델을 구축하기가 더 어렵습니다. 특히 의사 결정 트리나 선형 회귀와 같은 선형 알고리즘을 사용하는 경우에는 더욱 그렇습니다.
다른 사람에게 관계를 설명해야 한다고 상상해 보세요. 그렇게 하려면 “더 많은 단어”가 필요할 것입니다. “A는 B가 증가함에 따라 증가하고 비율은 항상 3배입니다”(A=1이면 B=3, 선형)라고 말하는 것이 더 쉽습니다.
다음과 비교해 보세요: “A는 B가 증가함에 따라 증가하지만, B가 값 10에 도달할 때까지 A는 거의 0에 가깝다가 300으로 올라갑니다. 그리고 B가 15에 도달하면 A는 1000으로 갑니다.”
# 데이터 예시 생성
df_example=data.frame(x=df_exp$x,
y_exp=df_exp$y,
y_linear=3*df_exp$x+2)
# mine 지표 가져오기
res_mine_3=mine(df_example)
# 결과를 출력할 라벨 생성
results_linear =
sprintf("MIC: %s \n MIC-R2 (비선형성): %s",
res_mine_3$MIC[1,3],
round(res_mine_3$MICR2[1,3],2)
)
results_exp =
sprintf("MIC: %s \n MIC-R2 (비선형성): %s",
res_mine_3$MIC[1,2],
round(res_mine_3$MICR2[1,2],4)
)
# 결과 플로팅
# 지수 변수 플롯 생성
p_exp=ggplot(df_example, aes(x=x, y=y_exp)) +
geom_line(color='steelblue') +
annotate("text", x = 11, y =0.4, label = results_exp) +
theme_minimal()
# 선형 변수 플롯 생성
p_linear=ggplot(df_example, aes(x=x, y=y_linear)) +
geom_line(color='steelblue') +
annotate("text", x = 8, y = 55,
label = results_linear) +
theme_minimal()
grid.arrange(p_exp,p_linear,ncol=2)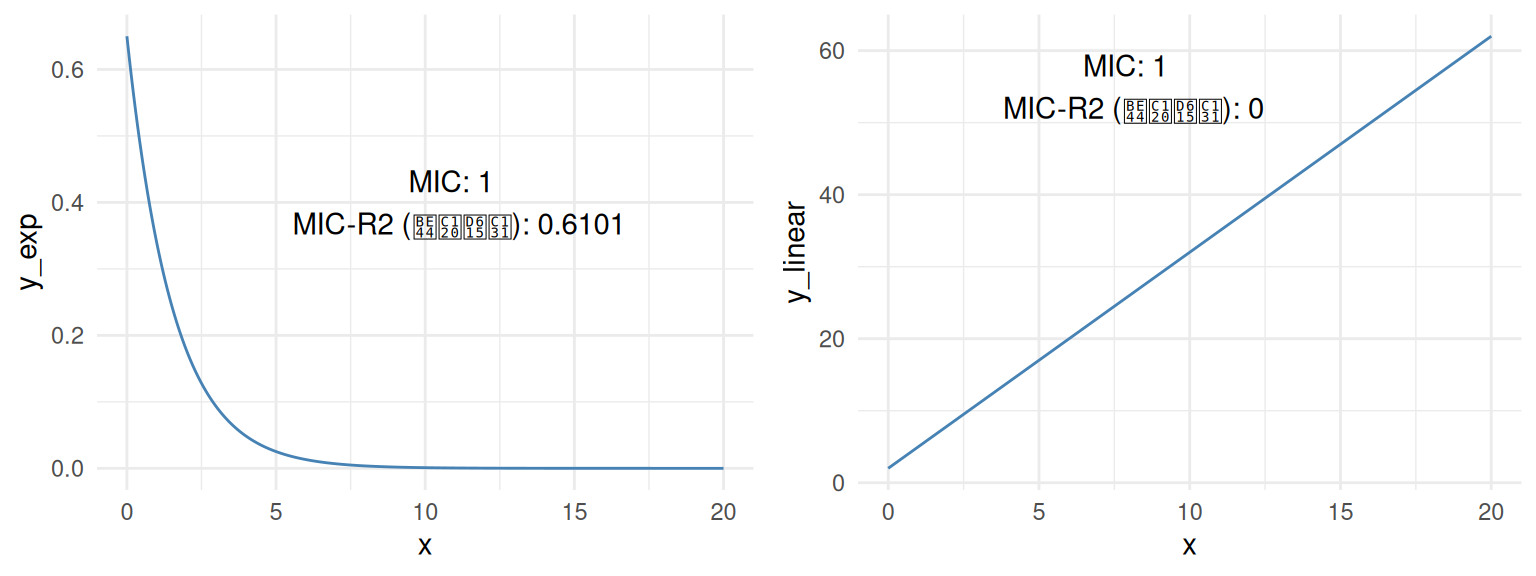
Figure 1.10: 관계 비교
두 플롯 모두 MIC=1을 가지는 완벽한 상관 관계(또는 관계)를 보여줍니다.
비선형성에 관해서는, MICR2는 예상대로 y_exp에서 0.6101, y_linear에서는 0으로 동작합니다.
이 점은 중요한데, MIC는 선형 관계에서 R2처럼 동작하며, 이전에 보았듯이 비선형 관계에도 매우 잘 적응하여 관계를 프로파일링하는 특정 점수 지표(MICR2)를 검색하기 때문입니다.
1.2.6 앤스콤 쿼텟에서 정보 측정하기
앞서 검토했던 예시를 기억하시나요? 앤스콤 쿼텟의 모든 쌍은 R2가 0.86으로 나옵니다. 그러나 플롯을 기반으로 볼 때 모든 쌍이 좋은 상관 관계나 유사한 x와 y의 분포를 보이는 것은 아니었습니다.
그러나 정보 이론에 기반한 메트릭으로 관계를 측정하면 어떻게 될까요? 네, 다시 MIC입니다.
# 모든 쌍에 대한 MIC 계산
mic_1=mine(anscombe_data$x1, anscombe_data$y1, alpha=0.8)$MIC
mic_2=mine(anscombe_data$x2, anscombe_data$y2, alpha=0.8)$MIC
mic_3=mine(anscombe_data$x3, anscombe_data$y3, alpha=0.8)$MIC
mic_4=mine(anscombe_data$x4, anscombe_data$y4, alpha=0.8)$MIC
# 2x2 그리드에 MIC 플로팅
grid.arrange(plot_anscombe("x1", "y1", mic_1, "MIC"), plot_anscombe("x2", "y2", mic_2,"MIC"), plot_anscombe("x3", "y3", mic_3,"MIC"), plot_anscombe("x4", "y4", mic_4,"MIC"), ncol=2, nrow=2)## `geom_smooth()` using formula = 'y ~ x'
## `geom_smooth()` using formula = 'y ~ x'
## `geom_smooth()` using formula = 'y ~ x'
## `geom_smooth()` using formula = 'y ~ x'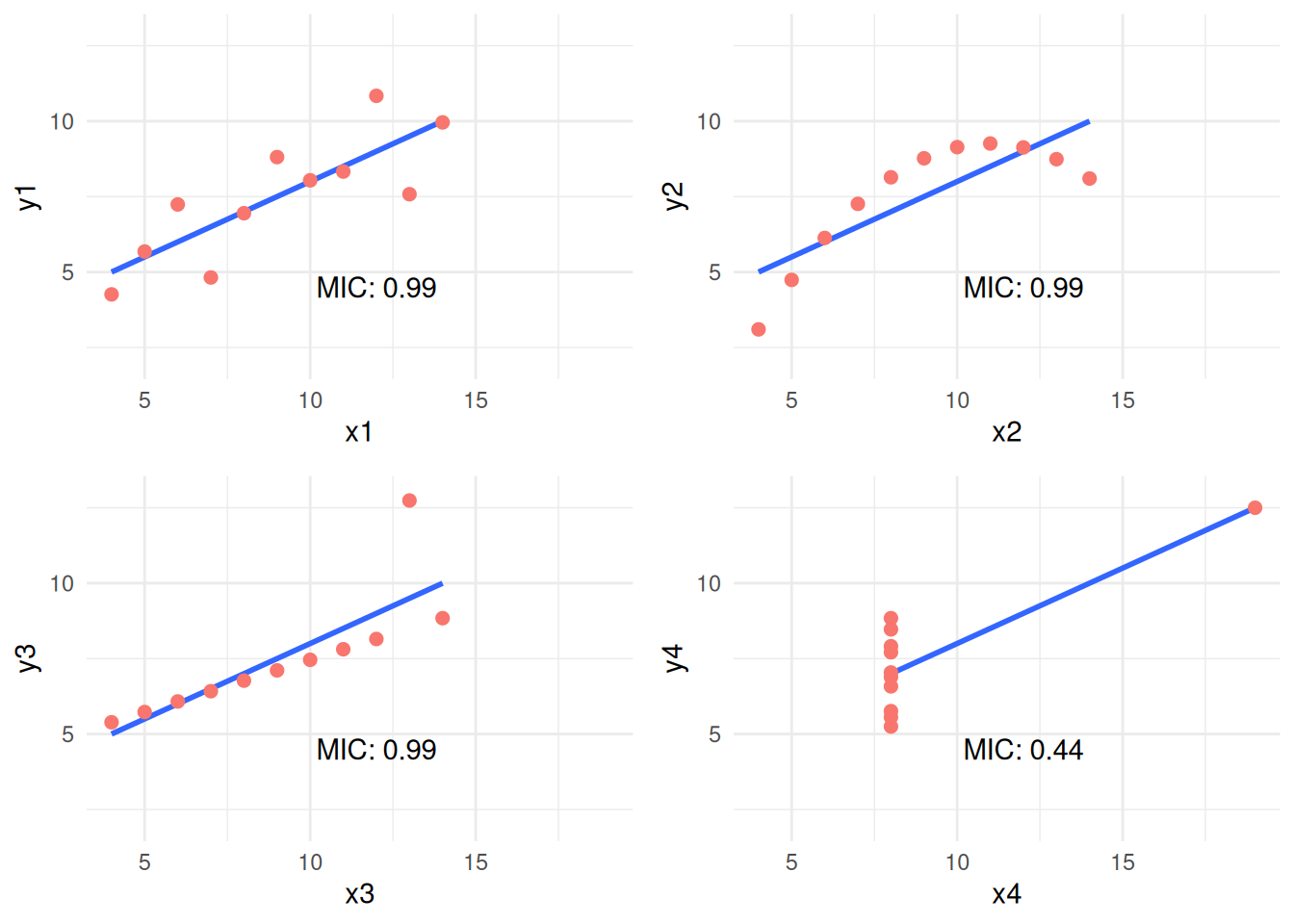
Figure 1.11: MIC 통계량
보시다시피 alpha 값을 0.8로 늘렸습니다. 이는 작은 샘플을 분석할 때 문서에 따라 좋은 방법입니다. 기본값은 0.6이고 최대값은 1입니다.
이 경우 MIC 값은 쌍 x4 - y4에서 가장 가짜 관계를 발견했습니다. 플롯당 몇 개의 케이스(11행) 때문에 MIC가 다른 모든 쌍에 대해 동일했을 수 있습니다. 더 많은 케이스가 있으면 다른 MIC 값이 표시됩니다.
그러나 MIC를 MIC-R2(비선형성 측정)와 결합하면 새로운 통찰력이 나타납니다.
# 모든 쌍에 대한 MIC 계산, 입력이 두 개의 벡터일 때는 "MIC-R2" 객체에 하이픈이 있고 데이터 프레임을 사용할 때는 "MICR2"인 것에 유의하세요.
mic_r2_1=mine(anscombe_data$x1, anscombe_data$y1, alpha = 0.8)$`MIC-R2`
mic_r2_2=mine(anscombe_data$x2, anscombe_data$y2, alpha = 0.8)$`MIC-R2`
mic_r2_3=mine(anscombe_data$x3, anscombe_data$y3, alpha = 0.8)$`MIC-R2`
mic_r2_4=mine(anscombe_data$x4, anscombe_data$y4, alpha = 0.8)$`MIC-R2`
# mic_r2에 따라 정렬
df_mic_r2=data.frame(pair=c(1,2,3,4), mic_r2=c(mic_r2_1,mic_r2_2,mic_r2_3,mic_r2_4)) %>% arrange(-mic_r2)
df_mic_r2## pair mic_r2
## 1 2 0.3277882
## 2 3 0.3277062
## 3 1 0.3274878
## 4 4 -0.2272103비선형성에 따라 내림차순으로 정렬하면 결과는 플롯과 일치합니다: 2 > 3 > 1 > 4. 쌍 4에 대한 이상한 점, 음수입니다. 이는 MIC가 R2보다 낮기 때문입니다. 플롯할 가치가 있는 관계입니다.
1.2.7 비단조성 측정: MAS 측정
MINE는 MAS(최대 비대칭 점수)를 사용하여 시계열의 비단조성을 프로파일링하는 데에도 도움이 될 수 있습니다.
단조 시계열은 경향이 바뀌지 않고 항상 위 또는 아래로 이동하는 시계열입니다. 이에 대한 자세한 내용은 (Wikipedia 2017b)에서 확인할 수 있습니다.
다음 예시는 비단조 y_1와 단조 y_2의 두 시계열을 시뮬레이션합니다.
# 샘플 데이터 생성 (시계열 시뮬레이션)
time_x=sort(runif(n=1000, min=0, max=1))
y_1=4*(time_x-0.5)^2
y_2=4*(time_x-0.5)^3
# 두 시계열에 대한 MAS 계산
mas_y1=round(mine(time_x,y_1)$MAS,2)
mas_y2=mine(time_x,y_2)$MAS
# 모두 함께 넣기
df_mono=data.frame(time_x=time_x, y_1=y_1, y_2=y_2)
# 플로팅
label_p_y_1 =
sprintf("MAS=%s (goes down \n and up => not-monotonic)",
mas_y1)
p_y_1=ggplot(df_mono, aes(x=time_x, y=y_1)) +
geom_line(color='steelblue') +
theme_minimal() +
annotate("text", x = 0.45, y =0.75,
label = label_p_y_1)
label_p_y_2=
sprintf("MAS=%s (goes up => monotonic)", mas_y2)
p_y_2=ggplot(df_mono, aes(x=time_x, y=y_2)) +
geom_line(color='steelblue') +
theme_minimal() +
annotate("text", x = 0.43, y =0.35,
label = label_p_y_2)
grid.arrange(p_y_1,p_y_2,ncol=2)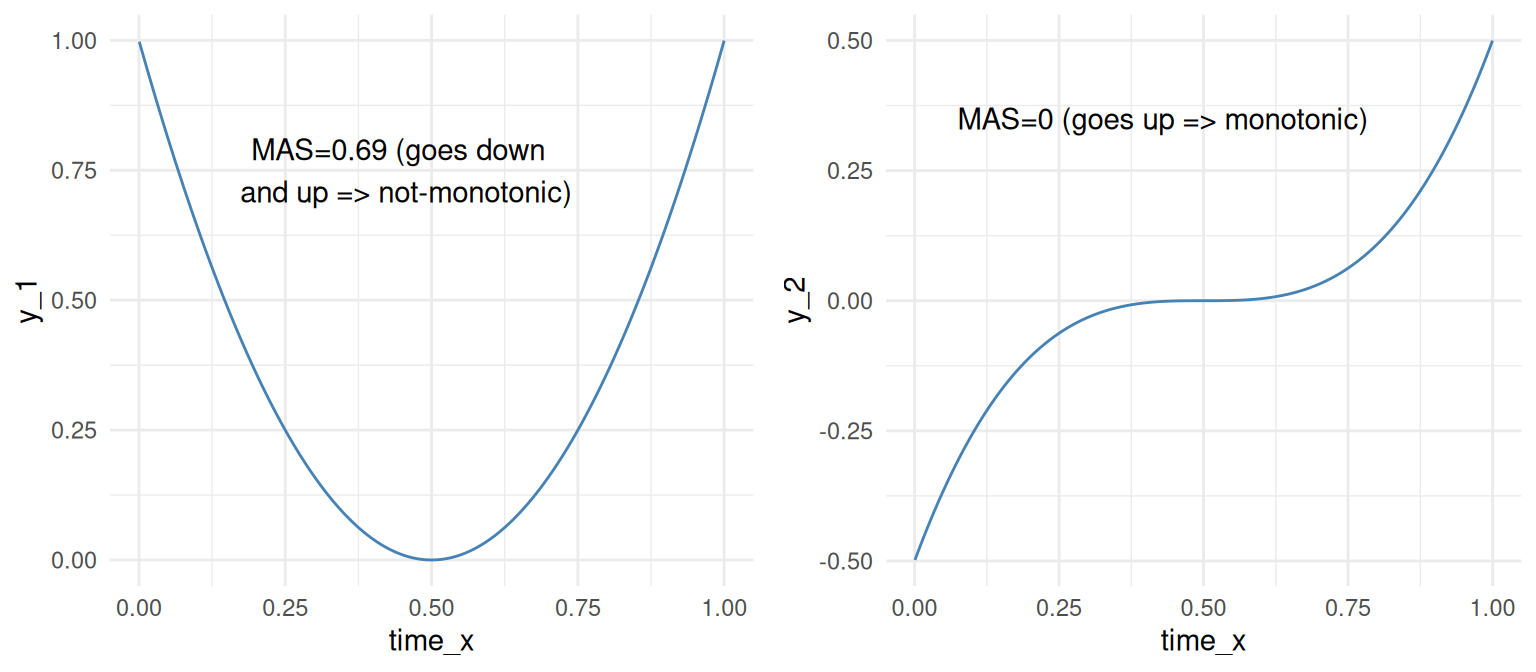
Figure 1.12: 함수의 단조성
다른 관점에서 MAS는 주기적 관계를 감지하는 데에도 유용합니다. 예시를 통해 이를 설명해 보겠습니다.
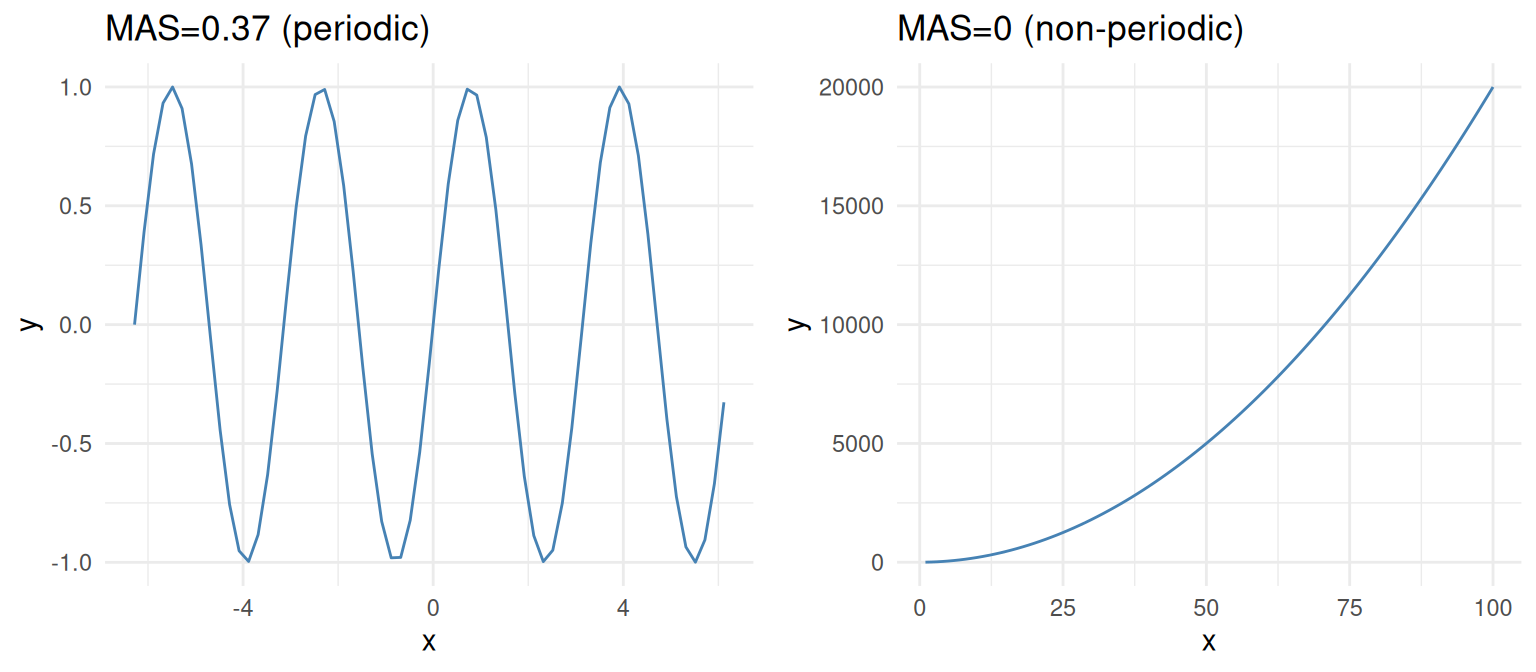
Figure 1.13: 함수의 주기성
1.2.7.1 더 실제적인 예시: 시계열
세 개의 시계열(y1, y2, y3)을 포함하는 다음 사례를 고려해 보겠습니다. 이들은 비단조성 또는 전체 성장 추세에 따라 프로파일링할 수 있습니다.
# 데이터 읽기
df_time_series =
read.delim(file="https://goo.gl/QDUjfd")
# 플롯할 수 있도록 긴 형식으로 변환
df_time_series_long=melt(df_time_series, id="time")
# 플로팅
plot_time_series =
ggplot(data=df_time_series_long,
aes(x=time, y=value, colour=variable)) +
geom_line() +
theme_minimal() +
scale_color_brewer(palette="Set2")
plot_time_series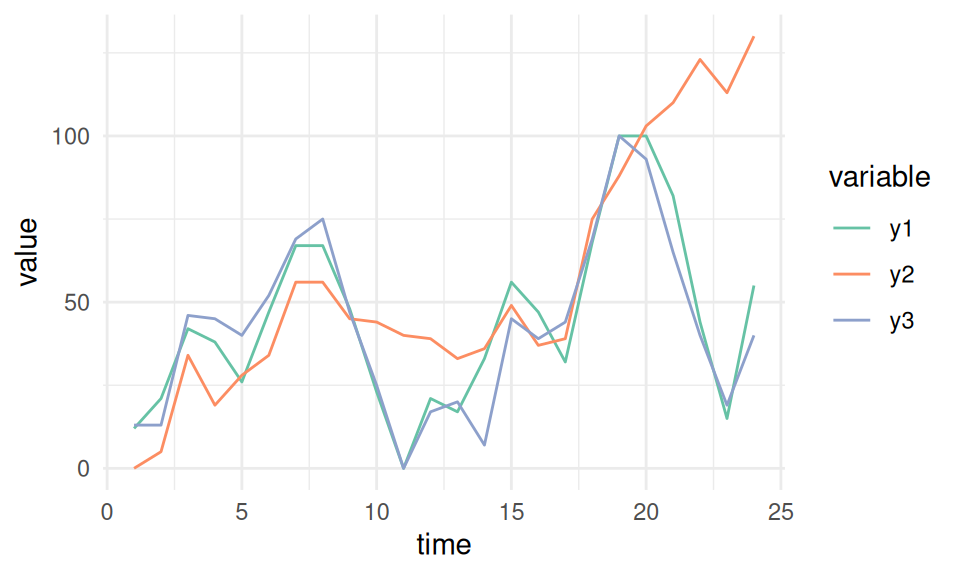
Figure 1.14: 시계열 예제
## time y1 y2 y3
## time 0.0000000 0.12031227 0.10538854 0.19115290
## y1 0.1203123 0.00000000 0.06777813 0.08109624
## y2 0.1053885 0.06777813 0.00000000 0.05700273
## y3 0.1911529 0.08109624 0.05700273 0.00000000time 열을 봐야 하므로 각 시계열의 시간에 대한 MAS 값을 얻었습니다.
y2는 가장 단조적(그리고 가장 덜 주기적)인 시계열이며, 이를 보면 확인할 수 있습니다. 항상 올라가는 것처럼 보입니다.
MAS 요약:
- MAS ~ 0은 단조 또는 비주기적 함수(“항상” 위 또는 아래로 이동)를 나타냅니다.
- MAS ~ 1은 비단조 또는 주기적 함수를 나타냅니다.
1.2.8 시계열 간의 상관 관계
MIC 메트릭은 시계열의 상관 관계도 측정할 수 있습니다. 일반적인 목적의 도구는 아니지만 서로 다른 시계열을 빠르게 비교하는 데 유용할 수 있습니다.
이 섹션은 MAS 예시에서 사용한 동일한 데이터를 기반으로 합니다.
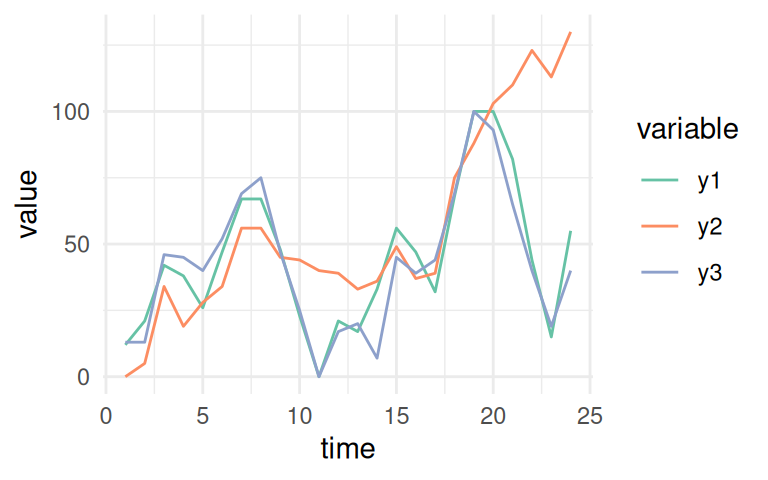
Figure 1.15: 시계열 예제
## time y1 y2 y3
## time 1.0000000 0.3770052 0.6896763 0.3408671
## y1 0.3770052 1.0000000 0.6174925 0.7094427
## y2 0.6896763 0.6174925 1.0000000 0.5176504
## y3 0.3408671 0.7094427 0.5176504 1.0000000이제 y1 열을 봐야 합니다. MIC 측정값에 따르면 마지막 플롯에 표시된 것과 동일한 내용을 확인할 수 있습니다.
y1은 y2(MIC=0.61)보다 y3(MIC=0.709)과 더 유사합니다.
1.2.8.1 더 나아가기: 동적 시간 워핑
MIC는 속도가 다른 시계열이 있는 더 복잡한 시나리오에는 유용하지 않습니다. 동적 시간 워핑(DTW) 기술을 사용해야 합니다.
개념을 시각적으로 파악하기 위해 이미지를 사용해 보겠습니다.

Figure 1.16: 동적 시간 워핑 (DTW)
이미지 출처: Dynamic time wrapping Converting images into time series for data mining (Izbicki 2011).
마지막 이미지는 시계열을 비교하는 두 가지 다른 접근 방식을 보여주며, 유클리드는 MIC 측정값과 더 유사합니다. 반면 DTW는 서로 다른 시간에 발생하는 유사성을 추적할 수 있습니다.
R에서의 멋진 구현: dtw 패키지.
시계열 간의 상관 관계를 찾는 것은 시계열 클러스터링을 수행하는 또 다른 방법입니다.
1.2.9 범주형 변수의 상관 관계
MINE와 다른 많은 알고리즘은 수치형 데이터에서만 작동합니다. 모든 범주형 변수를 플래그(또는 더미 변수)로 변환하는 데이터 준비 트릭을 수행해야 합니다.
원래 범주형 변수에 30개의 가능한 값이 있는 경우, 행에 해당 범주가 존재하는 경우 값 1을 보유하는 30개의 새 열이 생성됩니다.
R의 caret 패키지를 사용하는 경우 이 변환은 두 줄의 코드만 필요합니다.
library(caret)
# 몇 개의 변수만 선택
heart_disease_2 =
select(heart_disease, max_heart_rate, oldpeak,
thal, chest_pain,exer_angina, has_heart_disease)
# 범주형에서 수치형으로의 이 변환은 단순히
# 더 깔끔한 플롯을 만들기 위한 것입니다.
heart_disease_2$has_heart_disease=
ifelse(heart_disease_2$has_heart_disease=="yes", 1, 0)
# R의 모든 범주형 변수(factor 및
# character)를 수치형 변수로 변환합니다.
# 원본을 건너뛰어 데이터를 사용할 준비가 되도록 합니다.
dmy = dummyVars(" ~ .", data = heart_disease_2)
heart_disease_3 =
data.frame(predict(dmy, newdata = heart_disease_2))
# 중요: 이 메시지를 받으면
# `Error: Missing values present in input variable 'x'.
# Consider using use = 'pairwise.complete.obs'.`
# 데이터에 결측값이 있기 때문입니다.
# 먼저 영향 분석 없이 NA를 생략하지 마세요.
# 이 경우에는 중요하지 않습니다.
heart_disease_4=na.omit(heart_disease_3)
# mic 계산!
mine_res_hd=mine(heart_disease_4)샘플 인쇄…
## max_heart_rate oldpeak thal.3 thal.6 thal.7
## max_heart_rate 0.9999920 0.2440874 0.24448436 0.11965365 0.18392352
## oldpeak 0.2440874 0.9999283 0.17511070 0.11086221 0.15706631
## thal.3 0.2444844 0.1751107 0.99233512 0.07257079 0.70987597
## thal.6 0.1196536 0.1108622 0.07257079 0.32665312 0.04419397
## thal.7 0.1839235 0.1570663 0.70987597 0.04419397 0.96395831여기서 thal.3 열은 thal=3일 때 1의 값을 가집니다.
1.2.9.1 멋진 플롯 인쇄!
R에서 corrplot 패키지를 사용합니다. 이 패키지는 cor 객체(클래식 상관 관계 행렬) 또는 다른 행렬을 플롯할 수 있습니다. 이 경우 MIC 행렬을 플롯하지만, 예를 들어 MAS 또는 상관 관계의 제곱 행렬을 반환하는 다른 메트릭도 사용할 수 있습니다.
두 플롯은 동일한 데이터를 기반으로 하지만 상관 관계를 다른 방식으로 표시합니다.
## corrplot 0.95 loaded# color pallete brewer.pal을 사용합니다.
library(RColorBrewer)
# 대각선(변수 자체)을 제외한
# 스케일의 최대값을 시각화하는 해킹
diag(mine_res_hd$MIC)=0
# 원이 있는 상관 관계 플롯.
corrplot(mine_res_hd$MIC,
method="circle",
col=brewer.pal(n=10, name="PuOr"),
# 상단 대각선만 표시
type="lower",
# 레이블 색상, 크기 및 회전
tl.col="red",
tl.cex = 0.9,
tl.srt=90,
# 대각선(변수 자체)을 인쇄하지 않음
diag=FALSE,
# 모든 행렬(이 경우 mic)을 허용합니다.
#(상관 요소가 아님)
is.corr = F
)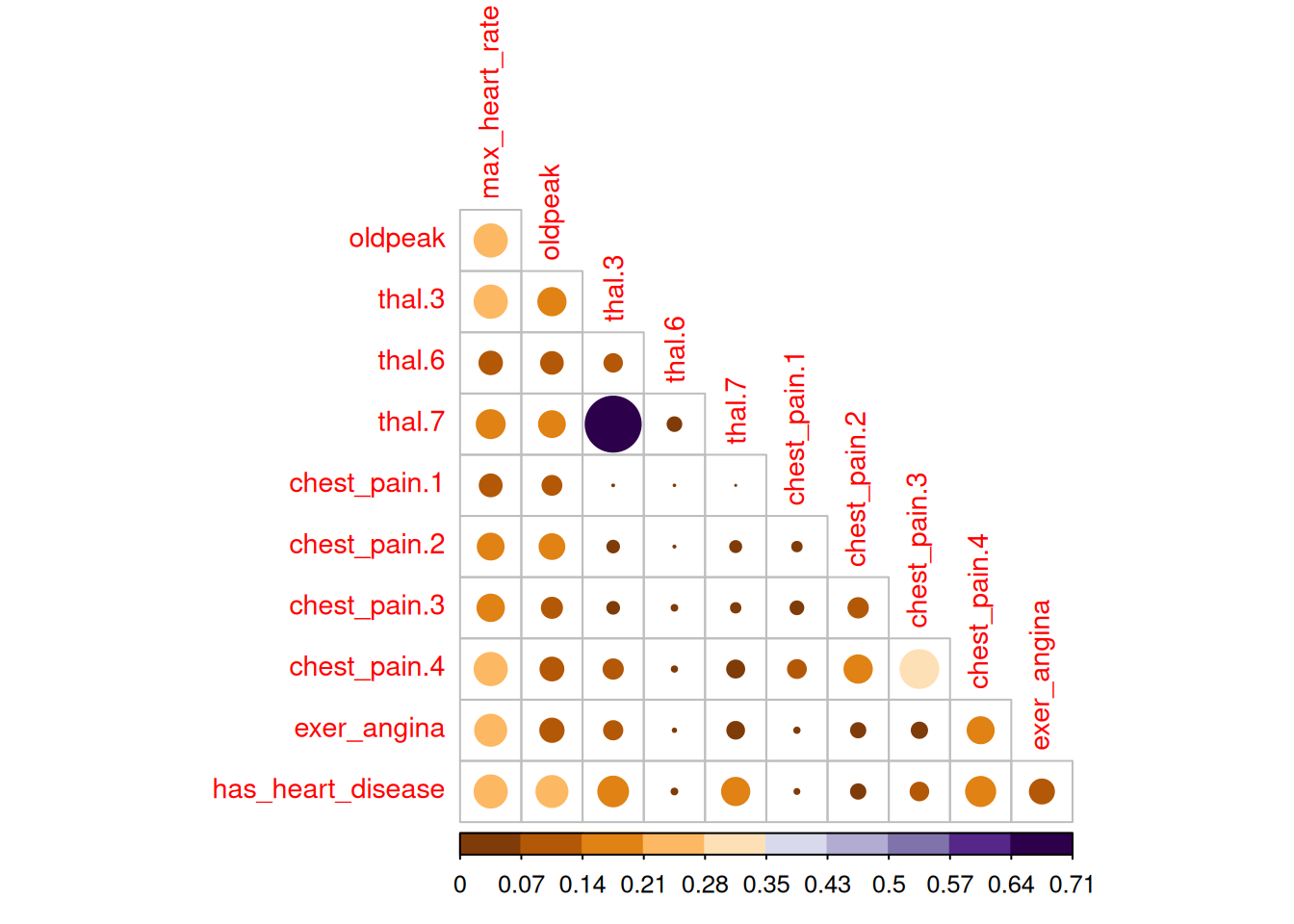
Figure 1.17: 상관 관계 플롯
# 색상 및 상관 관계 MIC가 있는 상관 관계 플롯
corrplot(mine_res_hd$MIC,
method="color",
type="lower",
number.cex=0.7,
# 상관 계수 추가
addCoef.col = "black",
tl.col="red",
tl.srt=90,
tl.cex = 0.9,
diag=FALSE,
is.corr = F
)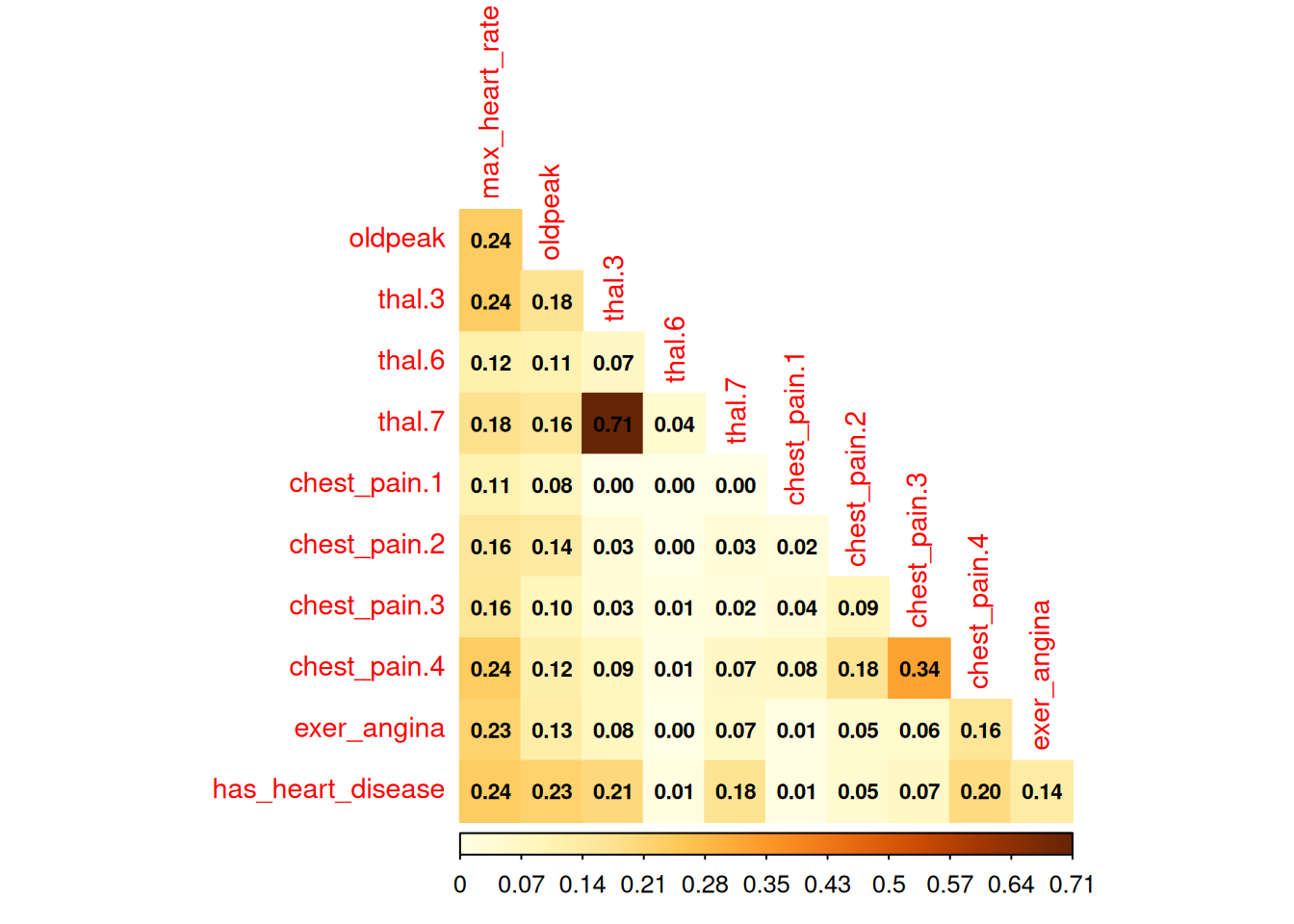
Figure 1.18: 상관 관계 플롯
첫 번째 매개변수 -mine_res_hd$MIC-를 원하는 행렬로 변경하고 자신의 데이터와 함께 다시 사용하면 됩니다.
1.2.9.2 이러한 종류의 플롯에 대한 의견
이러한 플롯은 변수 수가 많지 않을 때만 유용합니다. 또는 모든 변수가 수치형이어야 한다는 점을 염두에 두고 먼저 변수 선택을 수행하는 경우에 유용합니다.
선택에 범주형 변수가 있다면 먼저 이를 수치형으로 변환한 다음 변수 간의 관계를 검토하여 특정 범주형 변수의 값이 특정 결과와 어떻게 더 관련되어 있는지 (이 경우처럼) 미리 엿볼 수 있습니다.
1.2.9.3 플롯에서 얻을 수 있는 몇 가지 통찰력은 어떠한가요?
예측하려는 변수가 has_heart_disease이므로 흥미로운 점이 나타납니다. 심장 질환을 앓는 것은 thal=6 값보다 thal=3과 더 밀접하게 관련되어 있습니다.
변수 chest_pain에 대한 동일한 분석에서, 4의 값은 1의 값보다 더 위험합니다.
다른 플롯으로 확인할 수도 있습니다.
cross_plot(heart_disease, input = "chest_pain", target = "has_heart_disease", plot_type = "percentual")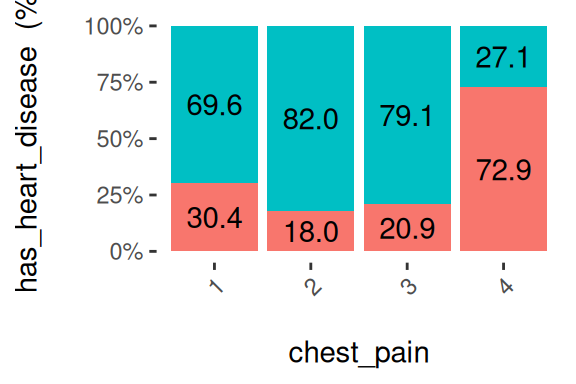
Figure 1.19: cross-plot을 사용한 시각적 분석
환자가 chest_pain=4인 경우 심장 질환 발병 가능성은 72.9%입니다. chest_pain=1인 경우(72.9% 대 30.4%)보다 2배 이상 높습니다.
몇 가지 생각…
데이터는 동일하지만 데이터를 탐색하는 접근 방식은 다릅니다. 예측 모델을 만들 때도 마찬가지입니다. N차원 공간의 입력 데이터는 서포트 벡터 머신, 랜덤 포레스트 등 다양한 모델을 통해 접근할 수 있습니다.
마치 사진가가 다른 각도나 다른 카메라로 촬영하는 것과 같습니다. 대상은 항상 동일하지만, 관점에 따라 다른 정보를 제공합니다.
원시 테이블과 다양한 플롯을 결합하면 더욱 현실적이고 보완적인 객관적인 시각을 얻을 수 있습니다.
1.2.10 정보 이론에 기반한 상관 관계 분석 {#selecting_best_vars_mic}
MIC 측정값을 기반으로 mine 함수는 예측할 열의 인덱스(또는 단 하나의 변수에 대한 모든 상관 관계를 얻기 위해)를 받을 수 있습니다.
# 예측할 변수의 인덱스 가져오기: has_heart_disease
target="has_heart_disease"
index_target=grep(target, colnames(heart_disease_4))
# master는 모든 상관 관계를 계산하기 위해
# 인덱스 열 번호를 가져옵니다.
mic_predictive=mine(heart_disease_4,
master = index_target)$MIC
# 결과를 포함하는 데이터 프레임 생성,
# 상관 관계에 따라 내림차순으로 정렬하고
# 대상 자체와의 상관 관계 제외
df_predictive =
data.frame(variable=rownames(mic_predictive),
mic=mic_predictive[,1],
stringsAsFactors = F) %>%
arrange(-mic) %>%
filter(variable!=target)
# MIC 측정값을 기반으로 변수 중요도를 보여주는
# 다채로운 플롯 생성
ggplot(df_predictive,
aes(x=reorder(variable, mic),y=mic, fill=variable)
) +
geom_bar(stat='identity') +
coord_flip() +
theme_bw() +
xlab("") +
ylab("Variable Importance (based on MIC)") +
guides(fill=FALSE)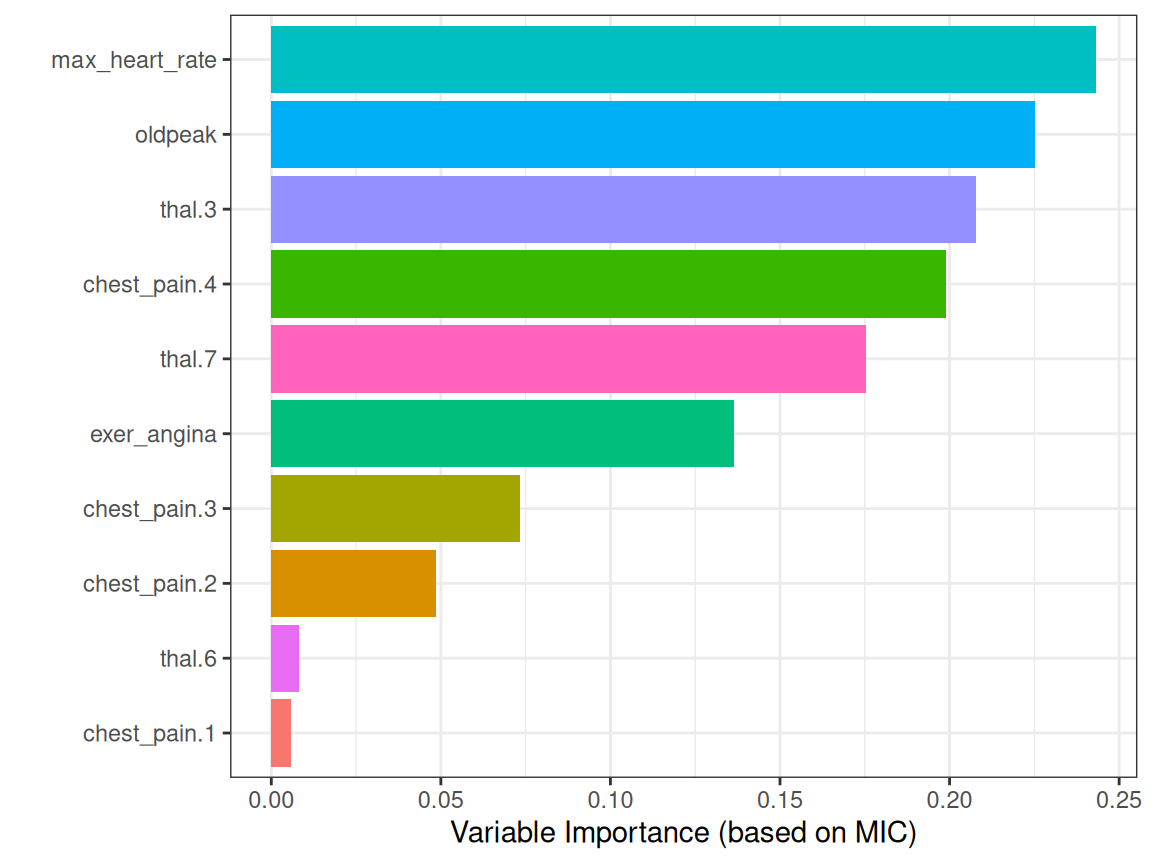
Figure 1.20: 정보 이론을 사용한 상관 관계
상관 관계가 있는 입력 특성을 제외하기 위해 모든 변수 간의 상관 관계를 실행하는 것이 권장되긴 합니다.
1.2.11 MINE만 이런 기능을 제공하나요?
아닙니다. 우리는 MINE 스위트만 사용했지만, 상호 정보와 관련된 다른 알고리즘도 있습니다. R에서는 entropy 및 infotheo 패키지 등이 있습니다.
funModeling 패키지(버전 1.6.6부터)는 섹션 정보 이론을 사용하여 최고의 특성 순위 지정에서 본 것처럼 여러 정보 이론 메트릭을 계산하는 var_rank_info 함수를 도입합니다.
Python에서는 scikit-learn을 통해 상호 정보를 계산할 수 있습니다. 여기 예제가 있습니다.
개념은 도구를 초월합니다.
1.2.11.1 또 다른 상관 관계 예제 (상호 정보)
이번에는 infotheo 패키지를 사용할 것입니다. 먼저 패키지에 있는 discretize 함수(또는 bining)를 적용하는 데이터 준비 단계를 수행해야 합니다. 이 함수는 모든 수치형 변수를 동일 빈도 기준에 따라 범주형으로 변환합니다.
다음 코드는 이전에 본 것처럼 상관 관계 행렬을 생성하지만, 상호 정보 지수를 기반으로 합니다.
library(infotheo)
# 모든 변수 이산화
heart_disease_4_disc=discretize(heart_disease_4)
# 상호 정보를 기반으로 "상관 관계" 계산
heart_info=mutinformation(heart_disease_4_disc, method= "emp")
# 대각선(변수 자체)을 제외한 스케일의 최대값을 시각화하는 해킹
diag(heart_info)=0
# Infotheo 패키지의 색상 및 상관 관계 상호 정보가 있는 상관 관계 플롯. 이 줄은 오른쪽의 플롯만 검색합니다.
corrplot(heart_info, method="color",type="lower", number.cex=0.6,addCoef.col = "black", tl.col="red", tl.srt=90, tl.cex = 0.9, diag=FALSE, is.corr = F)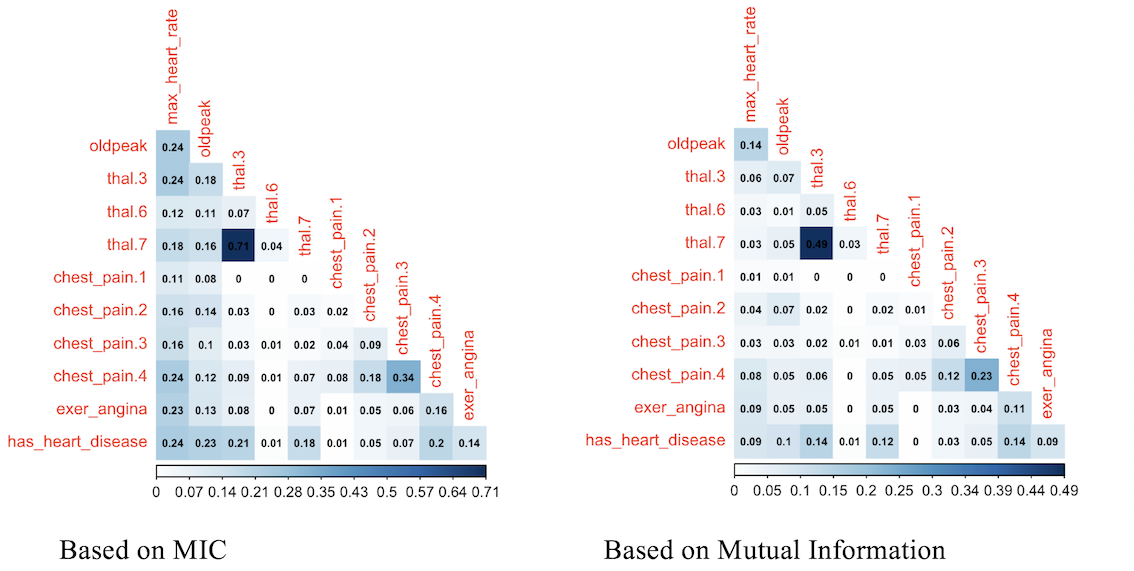
Figure 1.21: 변수 중요도 비교
상호 정보에 기반한 상관 관계 점수는 MIC와 매우 유사하게 관계 순위를 매기지 않습니까?
1.2.12 정보 측정: 일반적인 관점
상관 관계 외에도, MIC 또는 기타 정보 측정 지표는 _함수적 관계_가 있는지 여부를 측정합니다.
높은 MIC 값은 두 변수 간의 관계가 함수로 설명될 수 있음을 나타냅니다. 그 함수 또는 예측 모델을 찾는 것이 우리의 임무입니다.
이 분석은 N-변수로 확장되며, 이 책은 최상의 변수 선택 장에서 다른 알고리즘을 소개합니다.
일부 예측 모델은 다른 모델보다 성능이 좋지만, 관계가 완전히 노이즈가 많다면 아무리 발전된 알고리즘이라도 결국 좋지 않은 결과로 이어질 것입니다.
정보 이론에 대한 더 많은 내용이 나올 것입니다. 지금은 다음 교육용 강의를 확인하십시오:
- 7분 입문 영상 https://www.youtube.com/watch?v=2s3aJfRr9gE
- http://alex.smola.org/teaching/cmu2013-10-701x/slides/R8-information_theory.pdf
- http://www.scholarpedia.org/article/Mutual_information
1.2.13 결론
앤스콤 쿼텟은 플롯과 함께 _원시 통계량_을 얻는 좋은 방법을 가르쳐주었습니다.
우리는 노이즈가 두 변수 간의 관계에 어떻게 영향을 미칠 수 있는지 알 수 있었고, 이러한 현상은 항상 데이터에 나타납니다. 데이터의 노이즈는 예측 모델을 혼란스럽게 만듭니다.
노이즈는 오류와 관련이 있으며, 정보 이론에 기반한 측정값(예: 상호 정보 및 최대 정보 계수)을 통해 연구할 수 있으며, 이는 일반적인 R 제곱보다 한 단계 더 나아갑니다. (Caban et al. 2012)에는 MINE를 특성 선택기로 사용하는 임상 연구가 있습니다.
이러한 방법은 가장 중요한 변수의 순위를 매기기 위해 예측 모델에 의존하지 않는 방법으로 특성 공학에 적용할 수 있습니다. 또한 시계열을 클러스터링하는 데에도 적용할 수 있습니다.
더 읽어보기: 최상의 변수 선택
![]()