from toolz.curried import *
import pandas as pd
import numpy as np
import statsmodels.formula.api as smf
import seaborn as sns
from matplotlib import pyplot as plt
from cycler import cycler
color = ["0.0", "0.4", "0.8"]
default_cycler = cycler(color=color)
linestyle = ["-", "--", ":", "-."]
marker = ["o", "v", "d", "p"]
plt.rc("axes", prop_cycle=default_cycler)
11.1 불응
불응(Non-compliance)은 실험 대상자가 배정된 처치를 따르지 않는 경우를 말합니다. 예를 들어, 보조금을 받기로 배정되었지만 실제로 받지 않거나, 반대로 배정되지 않았음에도 받는 경우가 있습니다.
from graphviz import Digraph
gr = Digraph(format="png", graph_attr={"rankdir": "LR"})
gr.edge("U", "T")
gr.edge("U", "Y")
gr.edge("Z", "T")
gr.edge("T", "Y")
gr
df = pd.read_csv("../data/prime_card.csv")
df.head()
| 0 |
37.7 |
9687.0 |
822.0 |
0 |
0 |
4913.79 |
700.0 |
complier |
| 1 |
46.0 |
13731.0 |
190.0 |
0 |
0 |
5637.66 |
200.0 |
never-taker |
| 2 |
43.1 |
2839.0 |
214.0 |
1 |
1 |
2410.45 |
700.0 |
complier |
| 3 |
36.0 |
1206.0 |
318.0 |
1 |
1 |
1363.06 |
700.0 |
complier |
| 4 |
39.7 |
4095.0 |
430.0 |
0 |
0 |
2189.80 |
700.0 |
complier |
11.2 잠재적 결과 확장
불응이 존재하는 경우, 처치 배정(Z)과 실제 처치(T)를 구분하여 잠재적 결과를 확장해서 생각해야 합니다.
m = smf.ols("pv~prime_elegible", data=df).fit()
m.summary().tables[1]
|
coef |
std err |
t |
P>|t| |
[0.025 |
0.975] |
| Intercept |
2498.3618 |
24.327 |
102.701 |
0.000 |
2450.677 |
2546.047 |
| prime_elegible |
321.3880 |
34.321 |
9.364 |
0.000 |
254.113 |
388.663 |
m = smf.ols("pv~prime_card", data=df).fit()
m.summary().tables[1]
|
coef |
std err |
t |
P>|t| |
[0.025 |
0.975] |
| Intercept |
2534.4947 |
19.239 |
131.740 |
0.000 |
2496.783 |
2572.206 |
| prime_card |
588.1388 |
41.676 |
14.112 |
0.000 |
506.446 |
669.831 |
11.3 도구변수 식별 가정
도구변수(Instrumental Variable)가 유효하기 위해서는 관련성(Relevance), 배제 제약(Exclusion Restriction), 외생성(Exogeneity) 가정을 만족해야 합니다.
11.4 1단계
first_stage = smf.ols("prime_card ~ prime_elegible", data=df).fit()
first_stage.summary().tables[1]
|
coef |
std err |
t |
P>|t| |
[0.025 |
0.975] |
| Intercept |
6.729e-15 |
0.005 |
1.35e-12 |
1.000 |
-0.010 |
0.010 |
| prime_elegible |
0.4242 |
0.007 |
60.536 |
0.000 |
0.410 |
0.438 |
df.groupby("categ").size() / len(df)
categ
complier 0.4269
never-taker 0.5731
dtype: float64
11.5 2단계
red_form = smf.ols("pv ~ prime_elegible", data=df).fit()
red_form.summary().tables[1]
|
coef |
std err |
t |
P>|t| |
[0.025 |
0.975] |
| Intercept |
2498.3618 |
24.327 |
102.701 |
0.000 |
2450.677 |
2546.047 |
| prime_elegible |
321.3880 |
34.321 |
9.364 |
0.000 |
254.113 |
388.663 |
late = red_form.params["prime_elegible"] / first_stage.params["prime_elegible"]
late
df.groupby("categ")["tau"].mean()
categ
complier 700.0
never-taker 200.0
Name: tau, dtype: float64
11.6 2단계 최소제곱법
2단계 최소제곱법(2SLS)은 도구변수를 활용하여 내생성 문제를 해결하고 인과 효과를 추정하는 표준적인 방법입니다.
gr = Digraph(format="png", graph_attr={"rankdir": "LR"})
gr.edge("U", "T")
gr.edge("U", "Y")
gr.edge("Z", "T")
gr
iv_regr = smf.ols(
"pv ~ prime_card", data=df.assign(prime_card=first_stage.fittedvalues)
).fit()
iv_regr.summary().tables[1]
|
coef |
std err |
t |
P>|t| |
[0.025 |
0.975] |
| Intercept |
2498.3618 |
24.327 |
102.701 |
0.000 |
2450.677 |
2546.047 |
| prime_card |
757.6974 |
80.914 |
9.364 |
0.000 |
599.091 |
916.304 |
11.7 표준오차
Z = df["prime_elegible"]
T = df["prime_card"]
n = len(df)
# not the same as iv_regr.resid!
e_iv = df["pv"] - iv_regr.predict(df)
compliance = np.cov(T, Z)[0, 1] / Z.var()
se = np.std(e_iv) / (compliance * np.std(Z) * np.sqrt(n))
print("SE IV:", se)
print("95% CI:", [late - 2 * se, late + 2 * se])
SE IV: 80.52861026141942
95% CI: [596.6401590115549, 918.7546000572327]
from linearmodels import IV2SLS
formula = "pv ~ 1 + [prime_card ~ prime_elegible]"
iv_model = IV2SLS.from_formula(formula, df).fit(cov_type="unadjusted")
iv_model.summary.tables[1]
Parameter Estimates
|
Parameter |
Std. Err. |
T-stat |
P-value |
Lower CI |
Upper CI |
| Intercept |
2498.4 |
24.211 |
103.19 |
0.0000 |
2450.9 |
2545.8 |
| prime_card |
757.70 |
80.529 |
9.4090 |
0.0000 |
599.86 |
915.53 |
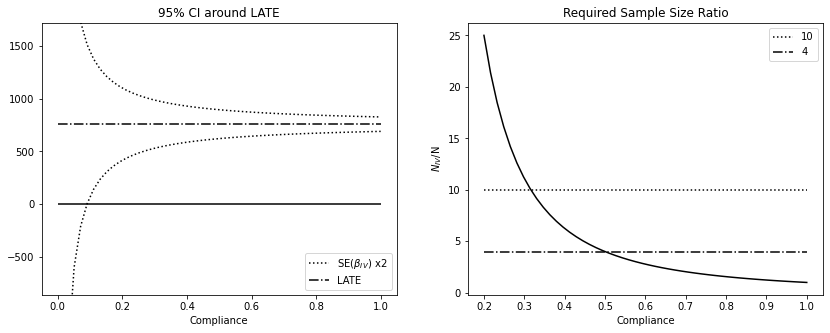
se_formula_iv = lambda compliance: np.std(e_iv) / (compliance * np.std(Z) * np.sqrt(n))
x = np.linspace(0.01, 1, 50)
effect = iv_regr.params["prime_card"]
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5))
ax1.plot(
x, effect - se_formula_iv(x) * 2, label="SE($\\beta_{IV}$) x2", ls=":", color="0"
)
ax1.plot(x, effect + se_formula_iv(x) * 2, ls=":", color="0")
ax1.hlines(effect, 0, 1, ls="-.", label="LATE")
ax1.hlines(0, 0, 1)
ax1.set_xlabel("Compliance")
ax1.set_ylim(-(effect + 100), (effect + 100) * 2)
ax1.legend(loc="lower right")
ax1.set_title("95% CI around LATE")
x = np.linspace(0.2, 1, 50)
ax2.plot(x, 1 / (x**2))
ax2.hlines(10, 0.2, 1, ls=":", label="10")
ax2.hlines(4, 0.2, 1, ls="-.", label="4")
ax2.set_xlabel("Compliance")
ax2.set_ylabel("$N_{IV}$/N")
ax2.set_title("Required Sample Size Ratio")
ax2.legend()
11.8 통제변수와 도구변수 추가
gr = Digraph(format="png", graph_attr={"rankdir": "LR"})
gr.edge("U", "T")
gr.edge("U", "Y")
gr.edge("Z", "T")
gr.edge("T", "Y")
gr.edge("Income", "Y")
gr.edge("Age", "T")
gr.edge("Age", "Y")
gr.edge("Score", "T")
gr
formula = "pv ~ 1 + [prime_card ~ prime_elegible + credit_score]"
iv_model = IV2SLS.from_formula(formula, df).fit()
iv_model.summary.tables[1]
Parameter Estimates
|
Parameter |
Std. Err. |
T-stat |
P-value |
Lower CI |
Upper CI |
| Intercept |
2519.4 |
21.168 |
119.02 |
0.0000 |
2477.9 |
2560.9 |
| prime_card |
659.04 |
58.089 |
11.345 |
0.0000 |
545.19 |
772.90 |
formula = """pv ~ 1
+ [prime_card ~ prime_elegible + credit_score]
+ income + age"""
iv_model = IV2SLS.from_formula(formula, df).fit(cov_type="unadjusted")
iv_model.summary.tables[1]
Parameter Estimates
|
Parameter |
Std. Err. |
T-stat |
P-value |
Lower CI |
Upper CI |
| Intercept |
210.62 |
37.605 |
5.6008 |
0.0000 |
136.91 |
284.32 |
| age |
9.7444 |
0.8873 |
10.982 |
0.0000 |
8.0053 |
11.483 |
| income |
0.3998 |
0.0008 |
471.04 |
0.0000 |
0.3981 |
0.4014 |
| prime_card |
693.12 |
12.165 |
56.978 |
0.0000 |
669.28 |
716.96 |
11.8.1 2SLS 직접 구현
formula_1st = "prime_card ~ prime_elegible + credit_score + income+age"
first_stage = smf.ols(formula_1st, data=df).fit()
iv_model = smf.ols(
"pv ~ prime_card + income + age",
data=df.assign(prime_card=first_stage.fittedvalues),
).fit()
iv_model.summary().tables[1]
|
coef |
std err |
t |
P>|t| |
[0.025 |
0.975] |
| Intercept |
210.6177 |
40.832 |
5.158 |
0.000 |
130.578 |
290.657 |
| prime_card |
693.1207 |
13.209 |
52.474 |
0.000 |
667.229 |
719.013 |
| income |
0.3998 |
0.001 |
433.806 |
0.000 |
0.398 |
0.402 |
| age |
9.7444 |
0.963 |
10.114 |
0.000 |
7.856 |
11.633 |
11.8.2 행렬 구현
Z = df[["prime_elegible", "credit_score", "income", "age"]].values
X = df[["prime_card", "income", "age"]].values
Y = df[["pv"]].values
def add_intercept(x):
return np.concatenate([np.ones((x.shape[0], 1)), x], axis=1)
Z_ = add_intercept(Z)
X_ = add_intercept(X)
# pre-multiplying Z_.dot(...) last is important to avoid
# creating a huge NxN matrix
X_hat = Z_.dot(np.linalg.inv(Z_.T.dot(Z_)).dot(Z_.T).dot(X_))
b_iv = np.linalg.inv(X_hat.T.dot(X_hat)).dot(X_hat.T).dot(Y)
b_iv[1]
e_hat_iv = Y - X_.dot(b_iv)
var = e_hat_iv.var() * np.diag(np.linalg.inv(X_hat.T.dot(X_hat)))
np.sqrt(var[1])
t_tilde = smf.ols("prime_card ~ income + age", data=df).fit().resid
e_hat_iv.std() / (t_tilde.std() * np.sqrt(n * first_stage.rsquared))
11.9 불연속 설계
11.9.2 처치 의도 효과
df_dd = pd.read_csv("../data/prime_card_discontinuity.csv")
df_dd.head()
| 0 |
12100.0 |
1 |
356.472 |
300.0 |
always-takers |
| 1 |
4400.0 |
1 |
268.172 |
300.0 |
always-takers |
| 2 |
4600.0 |
1 |
668.896 |
300.0 |
always-takers |
| 3 |
3500.0 |
1 |
428.094 |
300.0 |
always-takers |
| 4 |
12700.0 |
1 |
1619.793 |
700.0 |
complier |
m = smf.ols(
"pv~balance*I(balance>0)", df_dd.assign(balance=lambda d: d["balance"] - 5000)
).fit()
m.summary().tables[1]
|
coef |
std err |
t |
P>|t| |
[0.025 |
0.975] |
| Intercept |
559.2980 |
8.395 |
66.621 |
0.000 |
542.843 |
575.753 |
| I(balance > 0)[T.True] |
261.0699 |
10.128 |
25.777 |
0.000 |
241.218 |
280.922 |
| balance |
0.0616 |
0.005 |
11.892 |
0.000 |
0.051 |
0.072 |
| balance:I(balance > 0)[T.True] |
-0.0187 |
0.005 |
-3.488 |
0.000 |
-0.029 |
-0.008 |
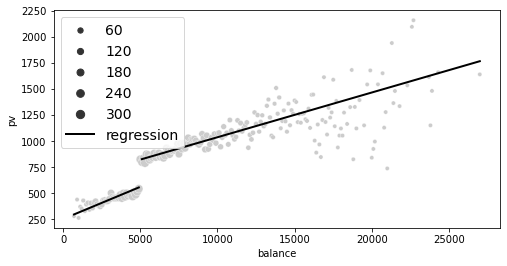
plt_df = (
df_dd.round({"balance": -2})
.assign(size=1)
.groupby("balance")
.agg({"pv": "mean", "size": "sum"})
.reset_index()
)
plt.figure(figsize=(8, 4))
sns.scatterplot(data=plt_df, y="pv", x="balance", size="size", color="C5")
plt.plot(
plt_df.query("balance<5000")["balance"],
m.predict(
plt_df.query("balance<5000").assign(balance=lambda d: d["balance"] - 5000)
),
color="C0",
lw=2,
label="regression",
)
plt.plot(
plt_df.query("balance>5000")["balance"],
m.predict(
plt_df.query("balance>5000").assign(balance=lambda d: d["balance"] - 5000)
),
color="C0",
lw=2,
)
plt.legend(fontsize=14)
11.9.3 도구변수 추정값
def rdd_iv(data, y, t, r, cutoff):
centered_df = data.assign(**{r: data[r] - cutoff})
compliance = smf.ols(f"{t}~{r}*I({r}>0)", centered_df).fit()
itte = smf.ols(f"{y}~{r}*I({r}>0)", centered_df).fit()
param = f"I({r} > 0)[T.True]"
return itte.params[param] / compliance.params[param]
rdd_iv(df_dd, y="pv", t="prime_card", r="balance", cutoff=5000)
(
df_dd.round({"balance": -2}) # round to nearest hundred
.query("balance==5000 & categ=='complier'")["tau"]
.mean()
)
from joblib import Parallel, delayed
from toolz import partial
def bootstrap(data, est_fn, rounds=200, seed=123, pcts=[2.5, 97.5]):
np.random.seed(seed)
stats = Parallel(n_jobs=4)(
delayed(est_fn)(data.sample(frac=1, replace=True)) for _ in range(rounds)
)
return np.percentile(stats, pcts)
bootstrap(df_dd, partial(rdd_iv, y="pv", t="prime_card", r="balance", cutoff=5000))
array([655.08214249, 807.83207567])
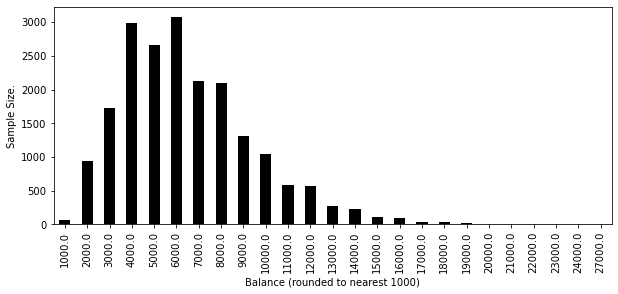
11.9.4 밀도 불연속 테스트
plt.figure(figsize=(10, 4))
df_dd.round({"balance": -3}).groupby("balance").size().plot.bar()
plt.ylabel("Sample Size.")
plt.xlabel("Balance (rounded to nearest 1000)")
Text(0.5, 0, 'Balance (rounded to nearest 1000)')
11.10 요약
gr = Digraph(format="png", graph_attr={"rankdir": "LR"})
gr.edge("U", "School")
gr.edge("U", "Income")
gr.edge("Quarter", "School")
gr.edge("School", "Income")
gr