import matplotlib.pyplot as plt그래프 그리기 (Plotting)
Tip학습 목표
- 단일 데이터 세트를 나타내는 시계열 그래프(time series plot)를 생성할 수 있습니다.
- 두 데이터 세트 간의 상관관계를 보여주는 산점도(scatter plot)를 생성할 수 있습니다.
Note질문
- 데이터를 어떻게 그래프로 시각화할 수 있나요?
- 생성한 그래프를 어떻게 파일로 저장할 수 있나요?
파이썬에서 가장 널리 사용되는 시각화 라이브러리는 matplotlib 입니다.
- 주로 하위 라이브러리인
matplotlib.pyplot모듈을 사용합니다. - Jupyter Notebook 환경은 코드 셀 아래에 그래프를 직접 렌더링하여 보여줍니다.
- 기초적인 그래프는 다음과 같이 간단하게 생성할 수 있습니다.
time = [0, 1, 2, 3]
position = [0, 100, 200, 300]
plt.plot(time, position)
plt.xlabel('Time (hr)')
plt.ylabel('Position (km)')Text(0, 0.5, 'Position (km)')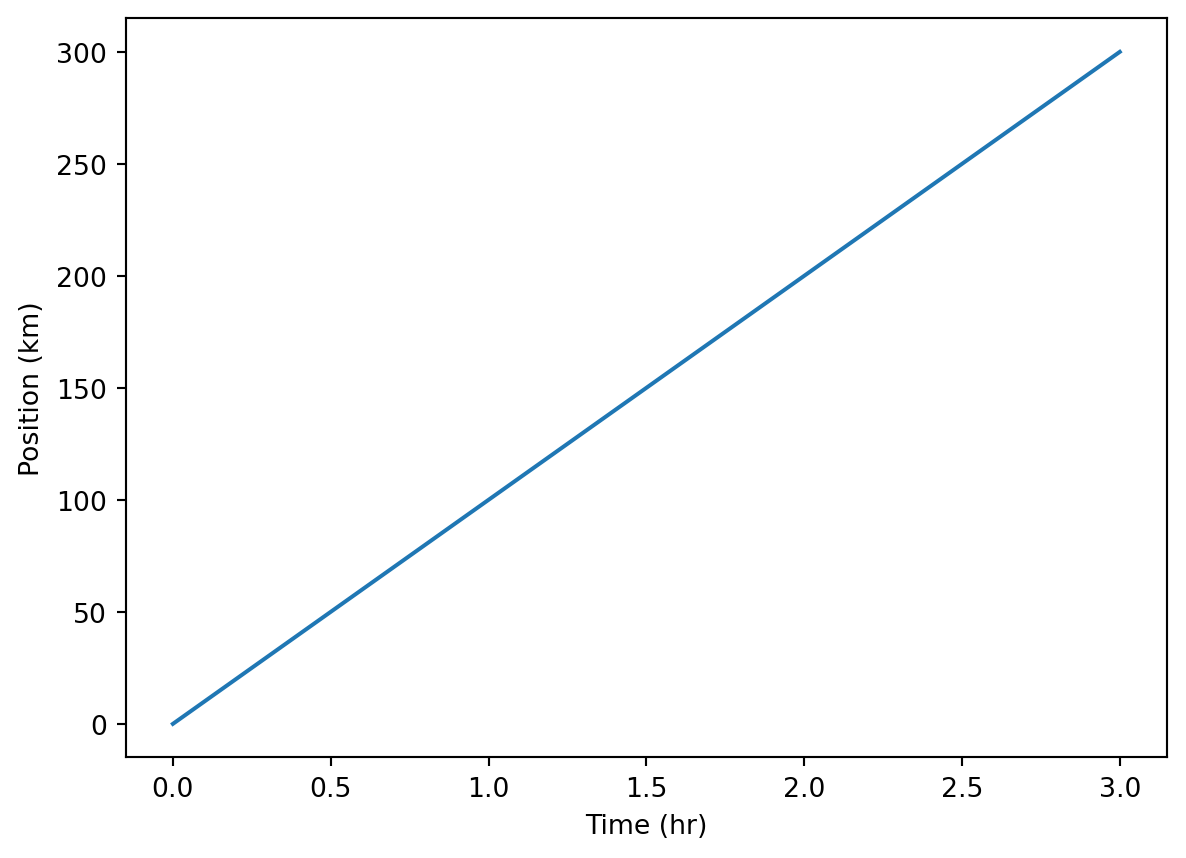

Note그래프 화면에 표시하기
Jupyter Notebook 환경에서는 그래프 생성 코드를 실행하면 결과가 자동으로 출력되고 노트북 파일에 저장됩니다. 하지만 대화형 파이썬 세션이나 스크립트 실행 환경에서는 그래프를 화면에 띄우기 위해 별도의 명령어가 필요합니다.
생성한 그래프를 화면에 나타내려면 다음 명령어를 사용합니다:
plt.show()이 명령어는 Jupyter Notebook에서도 한 셀에서 여러 그래프를 별도로 확인하고 싶을 때 유용합니다.
Pandas dataframe에서 직접 그래프를 그릴 수 있습니다.
- Pandas 데이터프레임 객체를 사용하여 편리하게 그래프를 그릴 수 있습니다.
- 먼저, 문자열로 되어 있는 열 이름을 숫자로 변환하는 작업이 필요할 수 있습니다. 예를 들어,
gdpPercap_접두어를 제거하고 남은 연도 문자열을 정수형으로 변환해 보겠습니다.
import pandas as pd
data = pd.read_csv('data/gapminder_gdp_oceania.csv', index_col='country')
# 열 이름에서 연도 정보만 추출합니다 (예: 'gdpPercap_1952' -> '1952')
years = data.columns.str.replace('gdpPercap_', '')
# 연도를 정수형으로 변환하여 열 이름으로 재설정합니다.
data.columns = years.astype(int)
# 호주(Australia) 데이터를 그래프로 그립니다.
data.loc['Australia'].plot()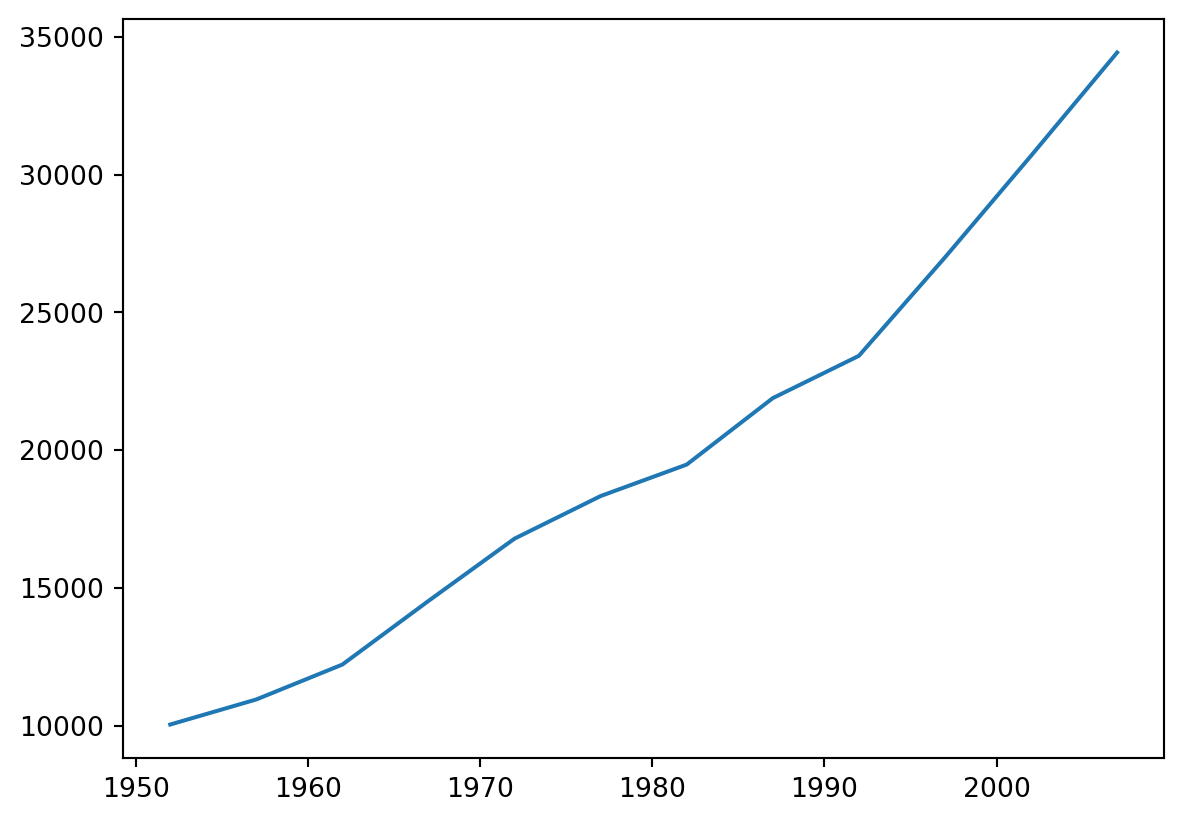

데이터 선택 및 변형 후 그래프 그리기
- 기본적으로
DataFrame.plot()함수는 각 행(row)을 x축의 단위로 사용합니다. - 여러 국가의 데이터를 연도별로 비교하려면 데이터를 전치(transpose)하여 행과 열을 바꾼 뒤 그리는 것이 좋습니다.
data.T.plot()
plt.ylabel('GDP per capita')Text(0, 0.5, 'GDP per capita')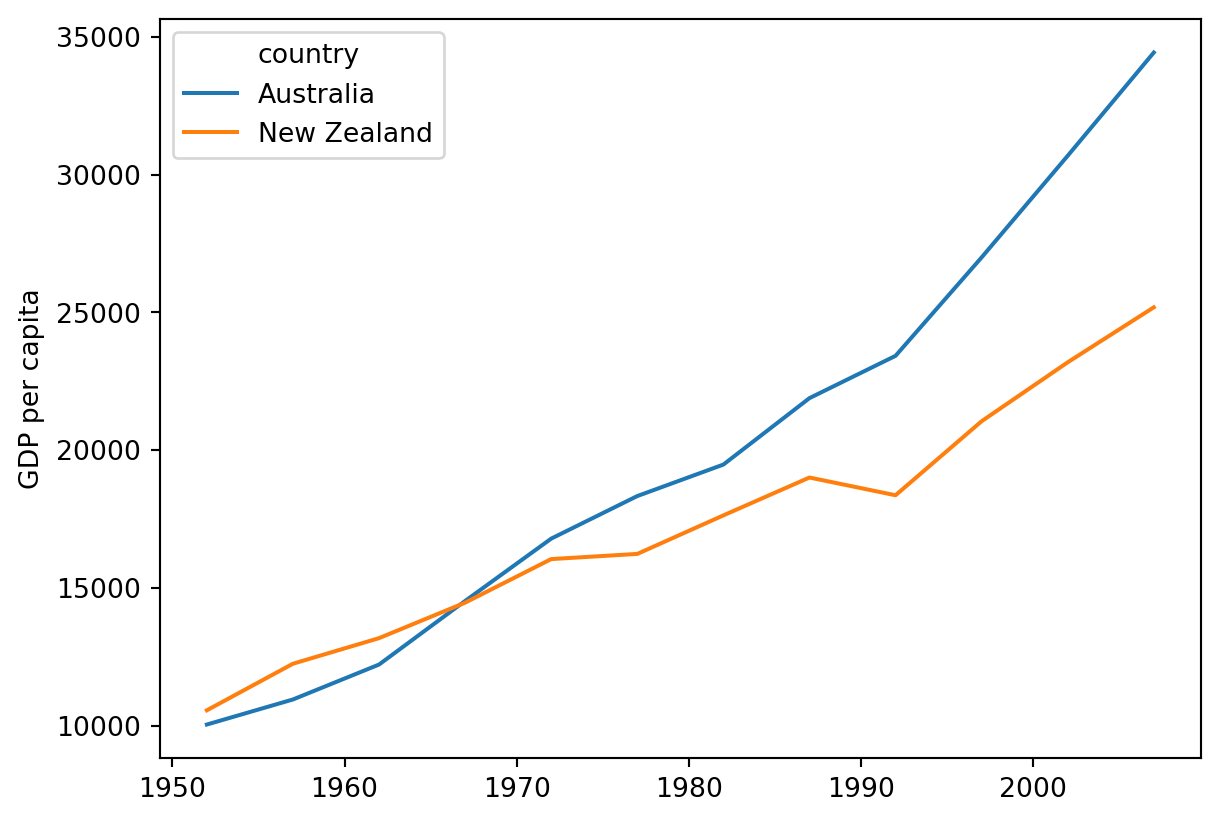

다양한 그래프 스타일 옵션
plt.style.use()를 사용하여 그래프의 테마를 변경하거나,kind='bar'옵션으로 막대 그래프를 그릴 수 있습니다.
plt.style.use('ggplot')
data.T.plot(kind='bar')
plt.ylabel('GDP per capita')Text(0, 0.5, 'GDP per capita')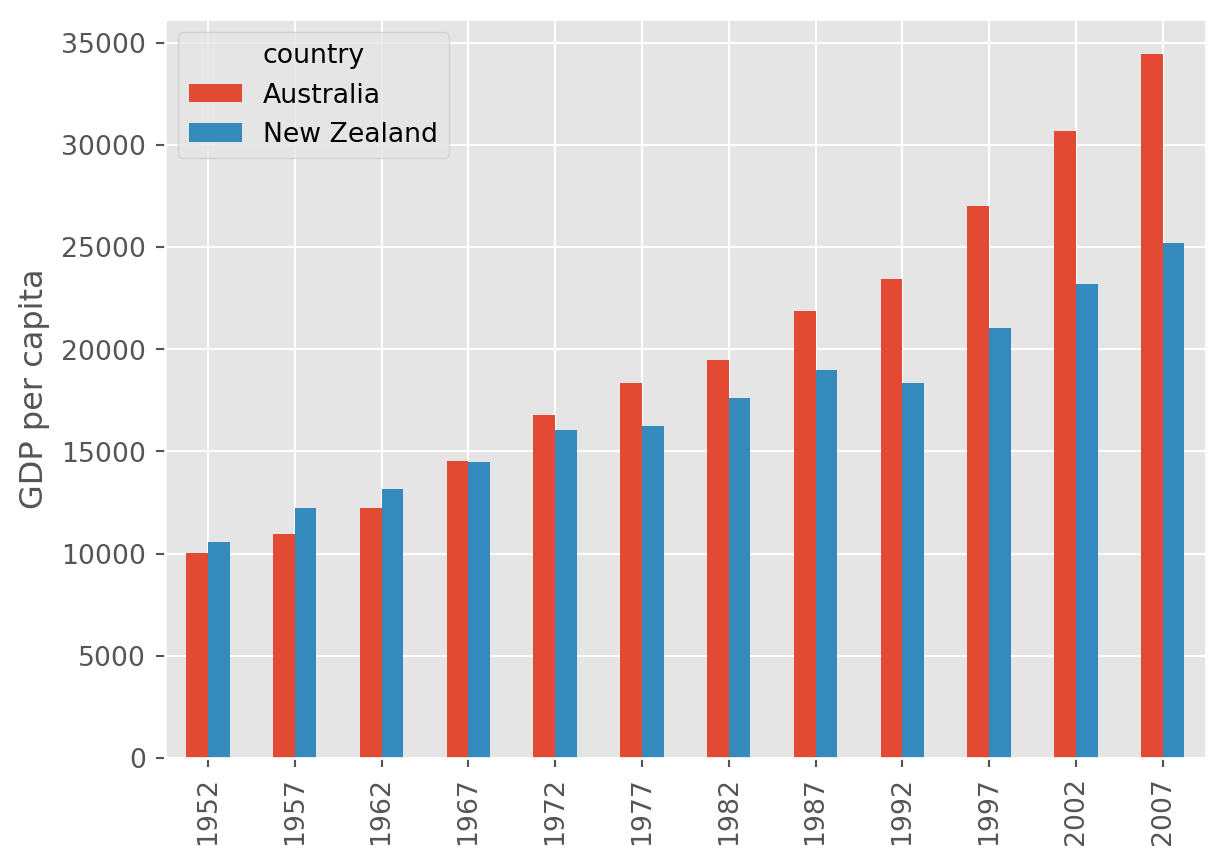

matplotlib 함수 직접 호출하기
- 가장 기본적인 명령어는
plt.plot(x, y)입니다. - 마커 색상이나 선 스타일 등을 지정할 수 있습니다. 예를 들어
'b-'는 파란색 실선,'g--'는 녹색 점선을 의미합니다.
years = data.columns
gdp_australia = data.loc['Australia']
plt.plot(years, gdp_australia, 'g--')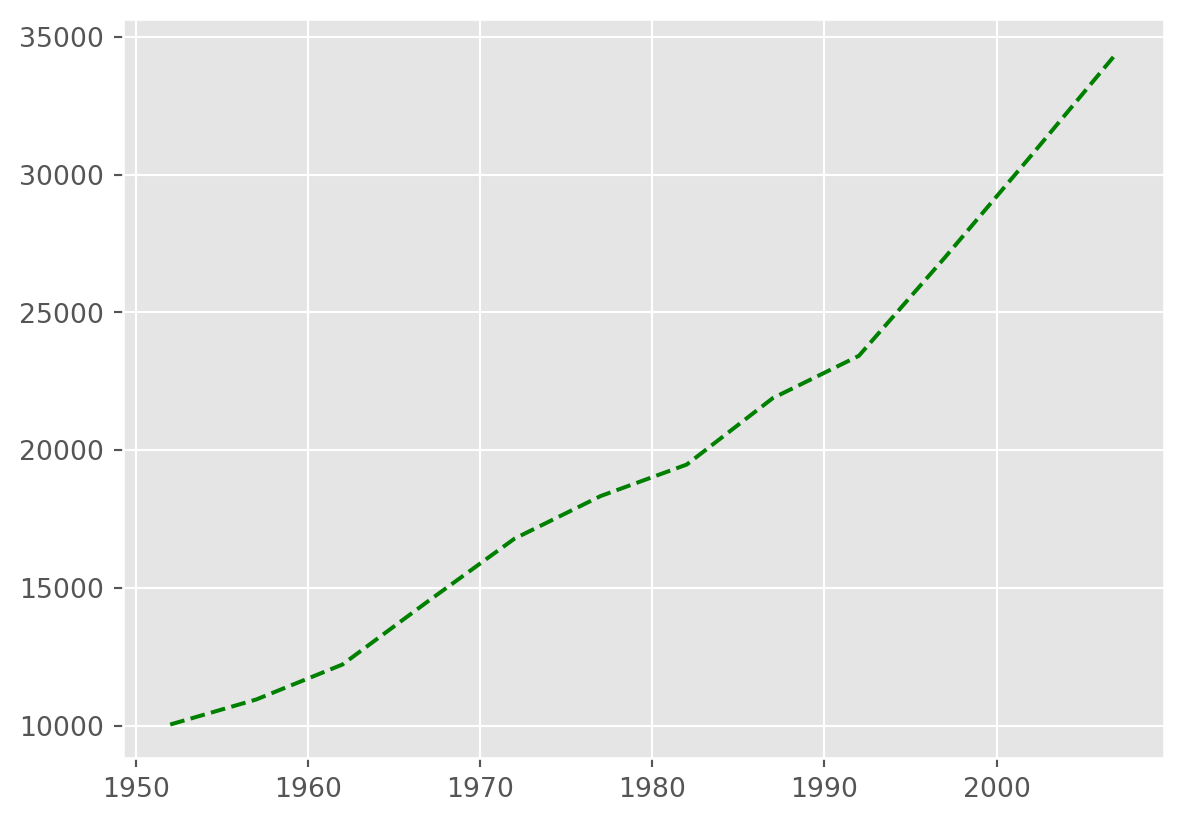
여러 데이터 세트 함께 그리기 및 범례 추가
gdp_australia = data.loc['Australia']
gdp_nz = data.loc['New Zealand']
plt.plot(years, gdp_australia, 'b-', label='Australia')
plt.plot(years, gdp_nz, 'g-', label='New Zealand')
# 범례 추가
plt.legend(loc='upper left')
plt.xlabel('Year')
plt.ylabel('GDP per capita ($)')Text(0, 0.5, 'GDP per capita ($)')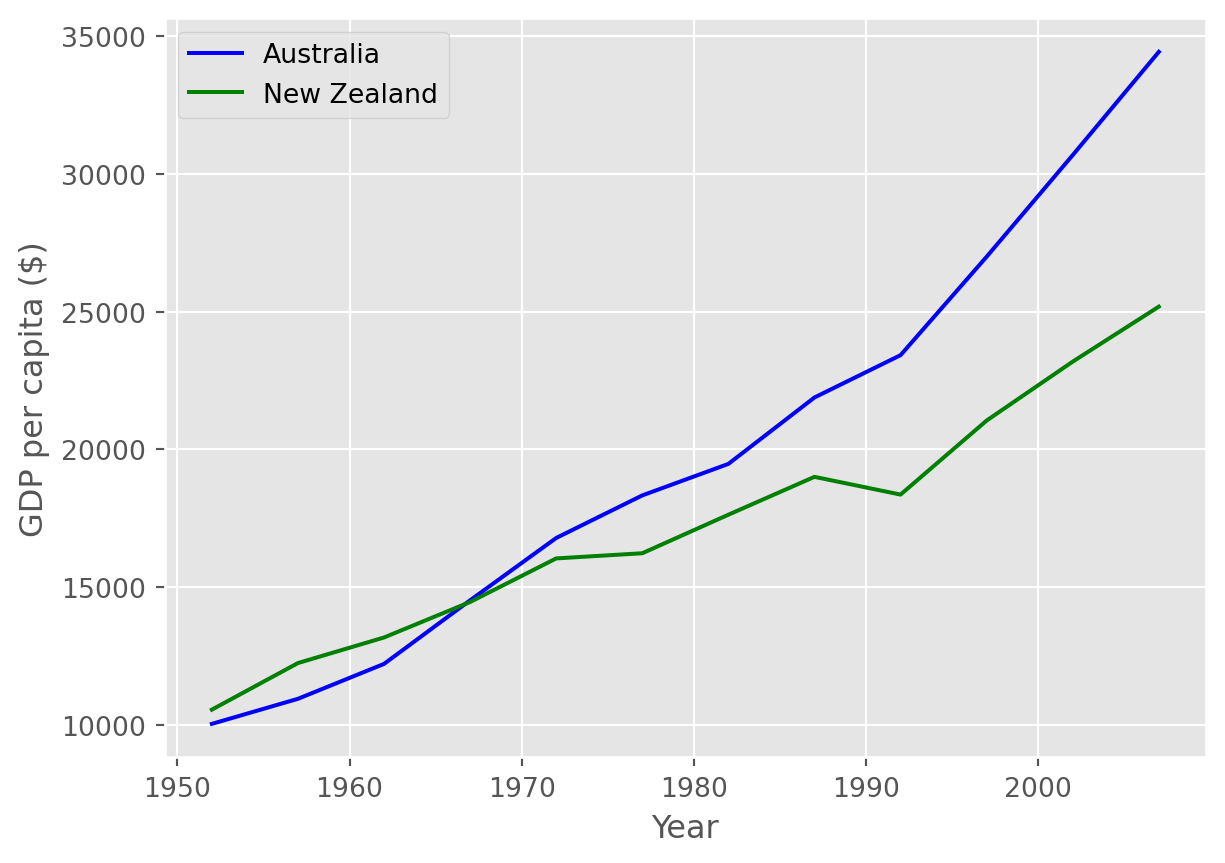
Note범례(Legend) 활용하기
여러 데이터를 겹쳐 그릴 때는 각 선이 무엇을 의미하는지 범례를 통해 설명하는 것이 좋습니다.
- 그래프를 그릴 때
label인자로 이름을 지정합니다. plt.legend()를 호출하여 범례를 표시합니다.
loc 매개변수를 사용하여 범례의 위치를 조정할 수 있습니다 (예: loc='upper left'). 지정하지 않으면 matplotlib이 가장 적절한 빈 공간에 배치합니다.
산점도(Scatter Plot) 그리기
데이터 간의 상관관계를 확인하기 위해 산점도를 사용할 수 있습니다. plt.scatter() 또는 DataFrame.plot.scatter()를 사용합니다.
plt.scatter(gdp_australia, gdp_nz)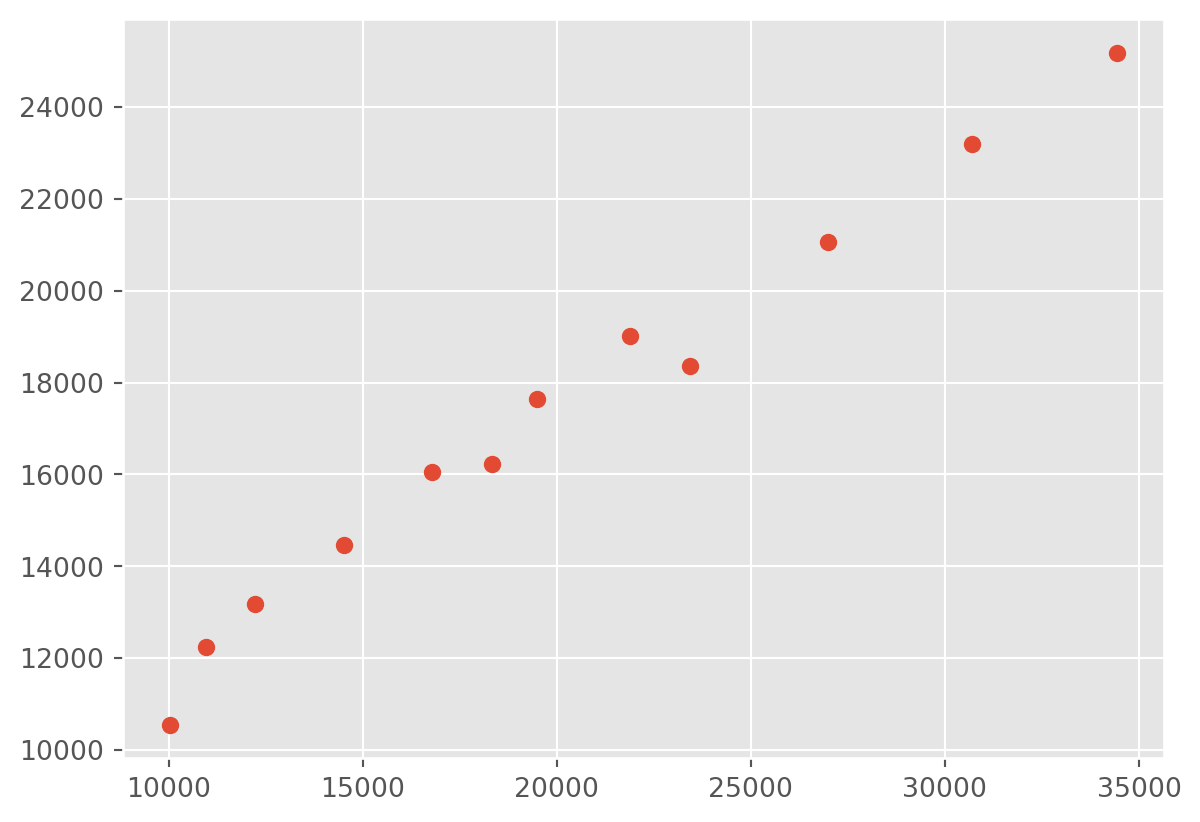
Important연습 문제
최솟값과 최댓값 그래프 그리기
유럽 국가들의 연도별 GDP 최솟값과 최댓값을 하나의 그래프에 겹쳐서 그려보세요.
Caution해답
data_europe = pd.read_csv('data/gapminder_gdp_europe.csv', index_col='country')
data_europe.min().plot(label='min')
data_europe.max().plot(label='max')
plt.legend(loc='best')
plt.xticks(rotation=90)
Important연습 문제
상관관계 살펴보기
아시아 지역 국가들을 대상으로 각 연도별 GDP의 최댓값과 최솟값 간의 상관관계를 산점도로 시각화해 보세요.
Caution해답
data_asia = pd.read_csv('data/gapminder_gdp_asia.csv', index_col='country')
data_asia.describe().T.plot(kind='scatter', x='min', y='max')상관관계를 분석해 보면 최댓값의 변동 폭이 최솟값보다 훨씬 크다는 점을 알 수 있습니다.
Note그래프를 파일로 저장하기
완성된 그래프를 논문이나 보고서에 사용하기 위해 이미지 파일로 저장하고 싶다면 savefig 함수를 사용합니다.
plt.savefig('my_figure.png')<Figure size 672x480 with 0 Axes>png, pdf, svg 등 다양한 형식을 지원합니다. 주의할 점은 plt.show()를 호출하기 전에 plt.savefig()를 먼저 실행해야 한다는 것입니다. plt.show()가 호출되면 내부적으로 그래프 객체가 초기화되어 빈 이미지가 저장될 수 있습니다.
현재 활성화된 그래프 객체를 변수에 저장해 두었다가 나중에 저장할 수도 있습니다.
data.plot(kind='bar')
fig = plt.gcf() # 현재 그래프 객체를 가져옴
fig.savefig('my_figure.png')
Note그래프의 접근성 고려하기
그래프를 만들 때는 누구나 정보를 명확히 파악할 수 있도록 접근성을 고려해야 합니다.
- 텍스트 크기: 제목, 축 레이블, 범례의 글자 크기를 충분히 크게 설정하세요 (
fontsize매개변수 활용). - 시각 요소 강조: 선의 두께(
linewidth)나 마커의 크기(s)를 조절하여 그래프 요소를 뚜렷하게 만드세요. - 색상 이외의 구분: 색상만으로 데이터를 구별하지 마세요. 색맹인 사용자나 흑백 출력을 고려하여 선 스타일(
linestyle)이나 마커 모양(marker)을 다르게 설정하는 것이 좋습니다.
Note핵심 요약
- 파이썬의 대표적인 시각화 라이브러리는
matplotlib입니다. - Pandas 데이터프레임에서 직접 그래프를 그릴 수 있는 메서드를 제공합니다.
- 데이터 정제 후 시각화하는 과정이 일반적입니다.
savefig를 통해 그래프를 다양한 형식의 파일로 저장할 수 있습니다.- 여러 데이터를 하나의 그래프에 겹쳐 그리거나 범례를 추가하여 정보를 명확히 전달할 수 있습니다.