데이터 과학 교육을 위한 10가지 간단한 규칙
서문
Timbers, T. A., & Çetinkaya-Rundel, M. (2026). Ten simple rules for teaching data science (arXiv:2602.02874). arXiv. https://doi.org/10.48550/arXiv.2602.02874
데이터 과학은 재현 가능하고 투명한 프로세스를 사용하여 데이터로부터 인사이트를 생성하는 연구, 개발 및 실천을 의미합니다1234. 통계학 및 컴퓨터 과학에 뿌리를 둔 데이터 과학 교육자들은 해당 분야에서 사용되는 다양한 교수법을 활용해 왔습니다567. 하지만 데이터 과학은 교육과 학습에 있어 독특한 도전 과제와 기회를 가진 별개의 학문입니다. 여기에서는 최고의 데이터 과학 교육자들이 시범 운영하고 실제 강의실에서 성공적으로 적용된 ’데이터 과학 교육을 위한 10가지 간단한 규칙’을 정리하여 소개하고자 합니다.
규칙 1: 데이터 분석을 통해 데이터 과학 가르치기
첫 번째 규칙은 실제 데이터 분석을 수행하면서 데이터 과학을 배우게 하는 것입니다. 이는 세 번째 강의나 열 번째 강의, 혹은 학기말이 아니라 바로 첫 번째 수업에서 학생들이 데이터를 불러오고, 간단한 데이터 가공(Data Wrangling)을 수행하며, 시각화 결과물을 만들어 보게 하는 것을 의미합니다. 우리는 이를 데이터 과학 교육의 “케이크 먼저 먹기(Let them eat cake)” 방식이라고 부릅니다8.
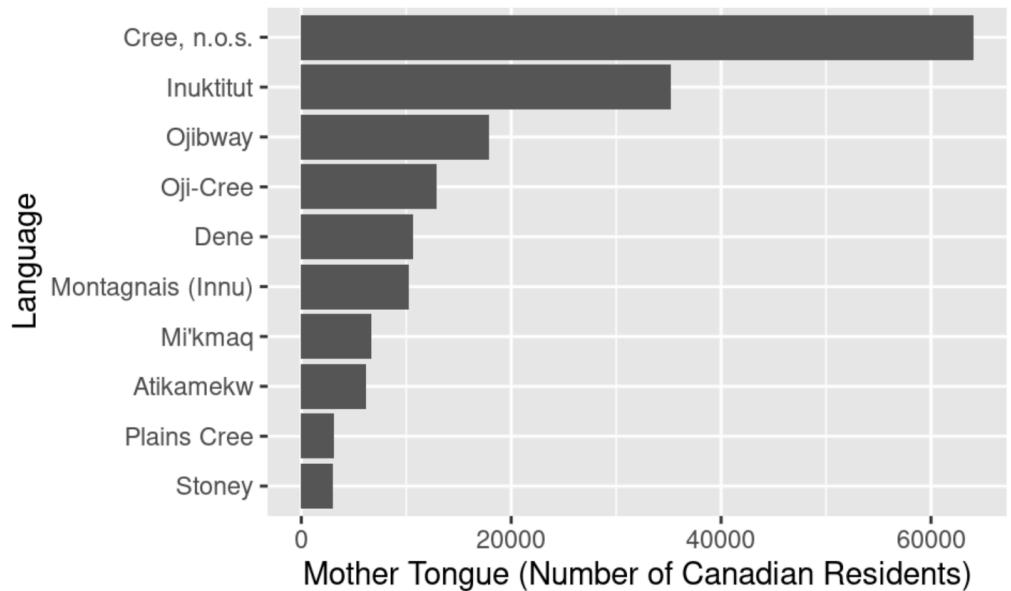
왜 이 방식을 제안할까요? 케이크를 먹는 것처럼 학생들에게 엄청난 동기부여가 되기 때문입니다. 처음 데이터 과학 수업이나 워크숍을 신청하는 학생들은 데이터를 통해 세상에 대한 질문을 던지고 답을 얻는 데 관심이 있습니다. 학생들은 아직 객체 데이터 타입(Data type), R과 Python 중 무엇이 더 좋은지, R을 쓴다면 Tidyverse와 Base R 중 무엇을 써야 하는지 같은 세부적이고 기술적인 문제에 깊이 관심을 가질 만큼 지식이 충분하지 않습니다. 따라서 초기에 흥미로운 결과물을 보여주어 학생들을 사로잡아야 합니다. 일단 흥미를 느끼면, 학생들은 우리가 의도적으로 생략했던 세부적이고 기술적인 부분들을 알려달라고 먼저 요구하게 될 것입니다. 그 예시가 그림 1에 나와 있습니다. 이는 Data Science: A First Introduction9의 첫 장에 나오는 코드로, 학습자들은 CSV 파일에서 데이터를 불러오고 필터링, 정렬, 슬라이싱을 통해 기초적인 데이터 가공을 수행합니다. 마지막으로 캐나다의 원주민 언어와 관련된 질문(캐나다 거주자 중 원주민 언어를 모국어로 사용하는 사람은 몇 명인가?)에 답하기 위해 그래프를 생성합니다. 이 규칙을 지지하고 실천하는 다른 교육자로는 Wang과 동료들10, 데이터 과학 입문 온라인 강의를 진행하는 David Robinson1112, 그리고 “지루하고 기초적인 내용을 앞부분에 배치하지 마라. 현실적이고 흥미로운 과제를 먼저 수행하고 아래로 내려가라”고 말한 Jenny Bryan13 등이 있습니다.
규칙 2: 참여형 라이브 코딩 활용하기
두 번째 규칙은 참여형 라이브 코딩(Participatory Live Coding)을 사용하는 것입니다. 이는 수업 중에 코드를 다룰 때 정적인 슬라이드를 보여주거나 완성된 코드를 실행만 하는 것이 아니라, 직접 코드를 타이핑하고 설명하면서 가르치는 것을 의미합니다. 학생들도 함께 따라 하도록 합니다. 이 방식이 중요한 이유는 실무에서는 중요하지만 프로그래밍 교육에서는 뒷전으로 밀리기 쉬운 ’프로세스와 워크플로우’에 대한 모범 사례를 직접 보여줄 수 있기 때문입니다. 코드를 치면서 왜 이런 방식으로 접근하는지 실시간으로 설명할 수 있습니다. 또한 라이브 코딩 도중 실수를 할 수도 있는데, 이는 오히려 좋은 기회입니다. 학생들에게 강사도 인간이며 실수를 할 수 있다는 점을 보여줄 뿐만 아니라, 코드 문제를 해결하기 위해 어떻게 디버깅하는지 시연할 수 있기 때문입니다. 학생들은 이를 숙제나 실제 업무에 활용할 수 있습니다. 또한 참여형 라이브 코딩은 수업 속도를 늦추어 학생들이 낙오되지 않게 도와줍니다. 이 교수법은 “I do, we do, you do(나의 시범, 우리의 동참, 너의 독자적 수행)”라는 지식 전달 모델14에서 유래했으며, 프로그래밍 교육에서의 적용은 글로벌 비영리 단체인 The Carpentries가 선도했습니다. 이에 대한 모범 사례들은 Nederbragt와 동료들15에 의해 10가지 팁으로 정리되었습니다.
규칙 3: 충분한 실습과 즉각적인 피드백 제공하기
세 번째 간단한 규칙은 엄청나게 많은 실습 기회를 주는 것입니다. 학습자가 충분하다고 느낄 정도보다 훨씬 더 많은 문제를 풀게 하십시오. 반복이 곧 학습으로 이어지기 때문입니다17. 이는 인간에게만 국한된 것이 아니라 동물의 행동 분야 전반에서 발견되는 근본적인 원리입니다1819. 마찬가지로 학생들도 어떤 작업을 이해하고 효과적으로 수행하기 위해서는 여러 번 반복해서 연습해야 합니다. 예를 들어, 파일에서 데이터를 읽는 법을 가르칠 때 단순히 파일 하나만 주지 말고, 구조가 약간씩 다른 6가지 버전의 파일을 주십시오. 이 방식을 통해 학생들은 각 파일의 유형, 열(Column) 간격, 건너뛸 메타데이터 유무, 열 이름 유무 등을 상세히 조사해야 합니다. 저희 수업에서는 학생들이 이러한 6가지 버전을 수업용 워크시트, 랩 과제, 퀴즈를 통해 완수하게 됩니다. 즉, 코스가 끝날 때까지 해당 기술을 15번 이상 연습하게 됩니다. Swirl R 패키지20, Kaggle Learn21, R for Data Science22와 같은 훌륭한 리소스들이 이러한 교수법을 사용합니다. 데이터 과학 실습 문제를 처음 설계하시는 분들께는 Greg Wilson의 Teaching Tech Together23에 있는 “연습 문제 유형(Exercise Types)” 장을 추천합니다.
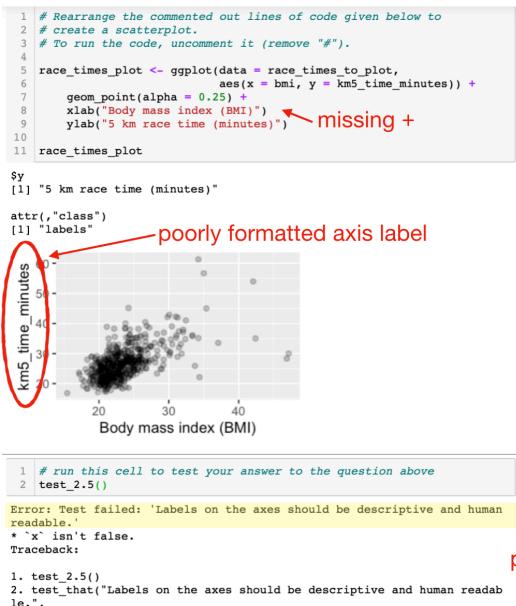
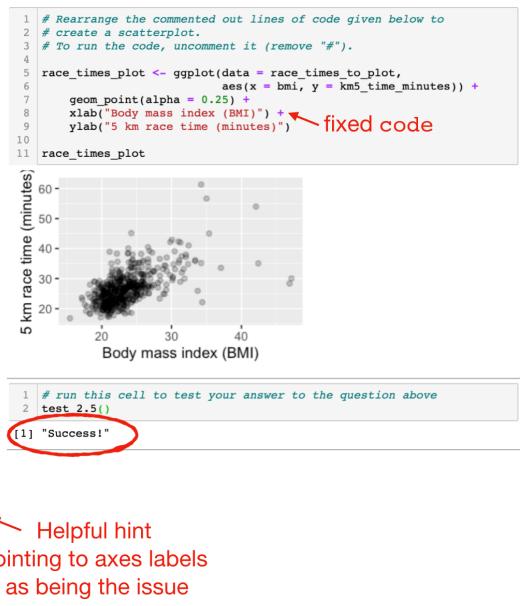
많은 양의 실습을 제공할 때는 즉각적인 피드백이 반드시 병행되어야 합니다. 피드백 없는 연습은 가치가 한정적입니다. 하지만 제한된 교육 자원으로 어떻게 많은 양의 피드백을 실시간으로 줄 수 있을까요? 한 가지 방법은 소프트웨어를 활용한 자동화된 테스트를 이용하는 것입니다. 데이터 과학 과제의 상당 부분은 코드를 작성하는 것이므로, 학생들의 답이 특정 부분에서 틀렸을 때 이를 알려주거나 올바른 방향으로 유도하는 힌트를 제공하는 테스트 코드를 작성할 수 있습니다. 그림 2는 그 실제 사례를 보여줍니다. 여기에서 학생들은 파슨스 프로블럼(Parsons problem, 섞여 있는 코드 한 줄씩을 올바른 순서로 재배열하는 문제) 형식의 ggplot 코드를 받았습니다. 이 예시에서 학생은 코드를 나열했지만 구문 오류(Syntax error)를 범했고, 예상과 다른 결과가 나왔습니다. 즉각적인 피드백이 없다면 학생은 과제가 채점되고 결과가 돌아올 때(보통 며칠 또는 몇 주 뒤)까지 문제가 있다는 사실조차 깨닫지 못할 수도 있습니다. 자동화된 소프트웨어 테스트는 학생들의 집중력이 해당 주제에 머물러 있을 때 즉각적인 피드백을 제공합니다. 이 교수법은 컴퓨터 과학 분야에서 처음 개발되었으며24, 현재 데이터 과학 교육에도 도입되고 있습니다. R을 위한 learnr 패키지25, 그리고 R과 Python 모두에서 작동하는 NBgrader26나 Otter Grader27와 같은 훌륭한 소프트웨어들이 있습니다.
규칙 4: 다루기 쉬운 가공된 데이터(Toy Data) 예시 사용하기
네 번째 규칙은 새로운 도구, 방법론 또는 알고리즘을 소개할 때 다루기 쉽거나 가공된 데이터(Toy Data)를 사용하는 것입니다. 이러한 데이터셋은 요소의 개수가 적어 작업 기억(Working memory)에 한 번에 들어올 수 있습니다. 덕분에 학생들은 알고리즘의 각 단계에서 데이터가 어떻게 변하는지 추적하고, 개념을 더 깊이 이해할 수 있습니다. 예를 들어, 저희 수업 중 하나에서는 Palmer penguins 데이터셋28을 사용하여 K-평균 군집화(K-means clustering)를 가르칩니다. 수백 개의 관측치가 담긴 전체 데이터를 바로 주는 대신, 먼저 몇 개의 데이터만 추려낸 부분 집합을 사용합니다. 그러면 학생들과 함께 각 단계에서 관측치들이 어떻게 이동하는지 살펴보며 알고리즘에 대한 직관을 쌓을 수 있습니다. 이는 Jenny Bryan의 훌륭한 dplyr 조인(Join) 컨닝 페이퍼(Cheat sheet)29에서 영감을 얻은 것입니다. 이 컨닝 페이퍼는 dplyr 패키지30의 다양한 조인 방식을 설명하는데, 조인은 학생들이 이해하고 암기하기 어려운 주제 중 하나입니다. 만약 큰 데이터셋으로 가르친다면 학생들은 내부에서 무슨 일이 일어나는지 전혀 감을 잡을 수 없을 것입니다. 설상가상으로 조인 방식의 이름들도 서로 비슷비슷합니다(Left join, Right join, Inner join, Outer join 등). 이 문제를 해결하기 위해 Jenny Bryan은 7행 4열의 히어로 캐릭터 데이터와 3행 2열의 출판사 데이터를 사용하여 모든 조인 방식을 보여줍니다. 이 데이터들은 한눈에 들어올 만큼 작기 때문에 학생들이 조인 개념을 훨씬 명확하게 이해할 수 있습니다.
물론 가공된 데이터만 사용한다면 학생들의 흥미와 동기를 지속시키기 어렵습니다. 따라서 개념적인 이해가 선행된 후에는 실제적이고 풍부한 데이터를 사용하는 다음 규칙으로 넘어가야 합니다.
규칙 5: 실제적이고 풍부하지만 접근하기 쉬운 데이터셋 사용하기
새로운 개념에 대한 이해가 어느 정도 이루어졌다면, 그다음 단계는 실제 데이터와 현실적인 질문에 이를 적용해 보는 것입니다. 하지만 이때 데이터셋이 모든 학습자에게 ‘접근 가능(Accessible)’한 것인지 확인하는 것이 대단히 중요합니다. 질문의 내용뿐만 아니라 데이터셋의 행(관측치)과 열(변수)이 학습자들 입장에서 즉시 이해될 수 있는 것이어야 합니다. 이는 특히 특정 도메인에서 훈련을 받은 교육자가 빠지기 쉬운 ’전문가의 맹점(Expert blind spot)’이 될 수 있습니다. 예를 들어, 생물학을 전공한 저자 중 한 명은 딥 시퀀싱(Deep sequencing) 데이터셋이 아주 훌륭한 동기부여 예시가 될 것이라고 생각할 수도 있습니다. 하지만 이는 저자가 생물학적 프로세스에 대해 깊이 알고 있기 때문에 생기는 맹점입니다. 만약 학습자들이 유사한 배경 지식이 없다면 그 데이터셋은 인지 과부하(Cognitive load)를 일으켜, 정작 배워야 할 도구나 알고리즘에 집중하지 못하게 만들 수 있습니다. 데이터셋 자체를 이해하는 데 귀중한 인지 자원을 낭비하게 해서는 안 됩니다. 대신 모든 학습자가 관측치와 열의 의미를 쉽게 파악할 수 있는 데이터를 사용해야 합니다. 예를 들어 캐나다의 지역별 언어 사용 인구 데이터31, Gapminder32, UN Votes33 데이터셋 등이 좋은 예입니다. 이 데이터들은 관측치가 수백 개에 달하지만 ’국가, 연도, 인구, 투표 결과’ 등 누구나 쉽게 이해할 수 있는 내용을 담고 있습니다. 이런 데이터로 질문을 던지면 학습자들은 큰 흥미를 느낍니다. 누구나 특정 국가에서 나고 자란 경험이 있기 때문입니다. 이러한 삶의 경험은 데이터셋에 대한 관심과 질문을 이끌어냅니다. 중요한 점은 데이터셋 자체를 이해하는 데 시간을 많이 쏟아서는 안 된다는 것입니다. 또한 학습자들의 지역적 맥락(국가, 지역, 문화)이나 시사 이슈를 반영한 데이터를 가져오면 흥미와 관련성을 높이는 데 큰 도움이 됩니다. 그런 데이터를 제때 찾는 것이 쉽지는 않지만, 데이터 과학 수업에서 배운 내용이 실제 삶과 공동체에서 일어나는 일과 연결된다는 것을 깨닫는 순간, 학습 효과는 배가 됩니다.
규칙 6: 문화적, 역사적 맥락 제공하기
여섯 번째 규칙은 가르치는 내용에 대한 문화적, 역사적 맥락을 제공하는 것입니다. 예를 들어, 새로운 소프트웨어 도구나 기능을 배울 때 학습자 시각에서 설계가 최적이 아니라고 느껴지는 경우가 있는데, 이때 ’왜 그렇게 되었는지’를 설명해 주면 큰 도움이 됩니다. 도구를 만든 사람들이 당시 어떤 고민을 했으며, 왜 X, Y, Z와 같은 이유로 이러한 방식을 선택했는지 설명해 주면 학생들은 소프트웨어가 결국 인간에 의해 만들어진 것이며, 인간의 관점, 역사, 문화에 영향을 받을 수밖에 없다는 점을 이해하게 됩니다. 이는 학습자가 소프트웨어에 대해 느끼는 좌절감이나 짜증을 예방하는 데 결정적인 역할을 합니다. 저희는 이러한 감정적 장벽이 일부 학습자들에게는 해당 소프트웨어를 기피하게 만드는 큰 걸림돌이 된다는 사실을 목격해 왔습니다.
일례로 R34과 tidyverse 패키지35를 배울 때, 함수 호출 시 데이터 프레임의 열 이름을 따옴표 없이(unquoted) 사용하는 것을 보게 됩니다. 다른 프로그래밍 언어에서 온 학습자들에게는 객체의 속성(Object attributes)을 참조할 때 따옴표를 쓰는 것이 당연하기 때문에 이것이 매우 낯설게 느껴질 수 있습니다. 간접 참조(Indirection) 문제로 인해 함수를 작성하는 것도 조금 더 까다로워집니다. Python, Java, C 등에 익숙한 사람들에게는 이것이 처음에는 나쁜 설계처럼 보일 수 있습니다. 하지만 R과 tidyverse가 데이터 분석과 시각화를 수행하는 통계학자들에 의해 만들어졌다는 점, 그리고 사용자가 콘솔에 명령어를 직접 입력하거나 코드를 대화형으로 실행하는 시간이 많을 것으로 예상하고 설계되었다는 점을 알게 되면 이야기가 달라집니다. 따옴표를 여닫는 타이핑 횟수를 최소화함으로써 오타나 문법 오류를 줄이려 한 설계 의도를 이해하게 되는 것입니다.
또 다른 예는 R의 할당 연산자인 화살표(<-)입니다. 두 글자를 써야 한다는 점이 이상하게 보일 수 있지만, R의 전신인 S 언어가 영감을 받은 APL 언어 당시의 키보드에는 할당 연산자가 전용 키 하나로 할당되어 있었다는 역사적 배경36을 알고 나면 훨씬 더 수긍이 갑니다. 이러한 맥락은 학습자들이 처음에는 동의하지 않았던 디자인 선택지도 그 당시 상황에서는 훌륭한 선택이었음을 인지하게 해줍니다. R의 역사에 대해 더 알고 싶으신 분은 Roger Peng의 책 R programming for data science37 중 “R의 역사와 개요” 장을 참고하시기 바랍니다.
규칙 7: 안전하고 포용적이며 환영받는 커뮤니티 구축하기
일곱 번째 규칙은 안전하고 포용적이며 환영받는 커뮤니티를 구축하는 것입니다. 만약 이 논문을 다시 쓴다면 아마 이 규칙을 첫 번째로 옮길 것입니다. 어떤 과목을 가르치든 이것이 가장 먼저 이루어져야 하기 때문입니다. 학습자들은 심리적으로 안전하다고 느끼지 않을 때 효율적으로 배우지 못합니다. 심리적 안전(Psychological safety)이란 부정적인 결과나 피드백에 대한 두려움 없이 자신의 의견이나 행동을 표현할 수 있다는 믿음을 의미합니다38. 질문을 했을 때 바보 취급을 당할까 봐 걱정된다면 학생들은 질문을 하지 않을 것이고, 결국 수업에 소외될 것입니다39. 또한 지능에 대한 부정적인 인식, 차별, 괴롭힘 등으로부터 보호받지 못한다고 느끼면 강의실이나 오피스 아워, 게시판 등에 나타나는 것조차 그만둘 수 있습니다. 따라서 안전하고 포용적인 학습 환경을 만드는 것은 효과적인 학습을 위해 필수적이며, 교수자는 이를 지원하는 가이드라인을 수립할 책임이 있습니다. 저희는 수업에서 행동 강령(Code of conduct)을 제정하고 이를 강의실과 관련 학습 공간에서 매우 중요하게 다룹니다. 수업 첫날에는 정해진 시간을 할애하여 구체적인 행동 강령을 발표합니다. 여기에는 권장되는 행동, 금지되는 행위, 위반 시 보고 절차 및 처벌 규정 등이 명확하게 담겨 있습니다. 또한 만약 강사가 행동 강령을 위반할 경우를 대비하여 여러 개의 보고 채널을 마련해 둡니다. 보고된 위반 사항은 반드시 진지하게 받아들여지고 즉각 조치되어야 합니다. 학생의 우려 사항이 무시되거나 방치되어서는 절대 안 됩니다. 행동 강령을 만들고자 하는 교육자분들께는 다른 조직의 사례(예: The Carpentries의 코드 오브 컨덕트)를 참고하여 자신의 상황에 맞게 수정하는 것을 권장합니다.
규칙 8: 체크리스트를 활용해 집중력 향상 및 동료 학습 촉진하기
여덟 번째 규칙은 체크리스트를 사용해 학습 목표를 명확히 하고 동료 학습(Peer learning)을 촉진하는 것입니다. 동료들끼리 서로 배우는 것이 교육학적으로 매우 효과적이라는 점은 이미 잘 알려져 있습니다40. 이를 구현하는 한 방법이 동료 평가(Peer review)입니다. 하지만 평가를 해본 적이 없거나 본인도 배우고 있는 단계라면 동료 평가가 매우 어렵게 느껴질 수 있습니다. 교육자는 이를 어떻게 도울 수 있을까요? 평소 채점에 사용하는 루브릭(Rubric)을 바탕으로 동료 평가 체크리스트를 만들어 줄 수 있습니다. 왜 체크리스트일까요? 체크리스트는 복잡하거나 반복적이고 지루한 작업을 실수 없이 수행하도록 돕는 강력한 도구이며 항공, 수술, 원자력 발전소와 같은 안전이 중요한 시스템에서 이미 사용되고 있습니다41. 최근에는 학술지(PLoS, Nature Ecology & Evolution 등)나 소프트웨어 퍼블리싱(ROpenSci, PyOpenSci) 등에서도 투명성을 높이고 편향을 줄이기 위해 체크리스트를 도입하고 있습니다42. 저희도 이러한 조직의 리뷰어로 활동하면서 체크리스트가 리뷰의 핵심 요소에 집중하게 하고 중요한 부분을 놓치지 않게 하는 데 얼마나 효과적인지 체감해 왔습니다. 이러한 방식은 데이터 과학 교육에도 큰 가치가 있습니다. 보충 자료 S1 File은 저희 수업에서 사용한 데이터 분석 리뷰 체크리스트의 예시입니다. 이는 저희가 중요하다고 생각하는 평가 요소들을 학생들에게 명확히 전달해 줍니다. 학생들은 체크리스트 항목을 확인하는 것 외에도 서술형 피드백을 작성하게 됩니다. 이 체크리스트는 학생들이 ’체크하지 못한 항목’에 집중하여 구체적인 피드백을 제공하도록 유도합니다. 예를 들어, 소프트웨어 테스트가 누락되었거나 분석의 한계점에 대한 언급이 없다면 해당 항목에 체크를 하지 않게 되고, 자연스럽게 그 부분에 대한 비판적 피드백을 작성하게 되는 것입니다.
규칙 9: 협력하며 일하는 법 가르치기
데이터 과학은 매우 협력적인 학문입니다. 데이터 과학자는 팀으로 일하거나, 최소한 도메인 전문가, 프로젝트 매니저, 고객 등 다른 이해관계자들과 소통해야 합니다. 따라서 학생들에게 협력하는 법을 가르치는 것이 필수적입니다. 이를 효과적으로 수행하려면 협업에 필요한 기술적 도구(Git, GitHub, 프로젝트 보드 등)와 더불어 경청하기, 비판적 피드백 주고받기, 코드 리뷰와 같은 사회적 실천(Social practices)을 가르쳐야 합니다. 또한 실습 기회도 충분히 주어야 합니다. 씽크-페어-쉐어(Think-pair-share)나 페어 프로그래밍과 같은 소규모 활동부터 시작하여 그룹 과제, 그리고 최종 프로젝트까지 복잡도를 단계적으로 높여가며 연습하게 해야 합니다.
장기 과제나 프로젝트를 진행할 때는 좋은 협업 방식을 과제 평가 기준에 포함시키는 것이 좋습니다. 저희 수업에서는 첫 작업 세션의 대부분을 팀 구성 활동에 할애합니다. 아이스 브레이킹을 통해 서로를 알아가고 신뢰를 쌓게 합니다. 그 후 팀 계약서(Teamwork contract)를 작성하여 프로젝트에 대한 기대치와 협업 방식을 명문화합니다. 프로젝트 기간 중에는 정기적인 회의(Stand-ups)를 열고 프로젝트 보드를 사용해 진행 상황을 추적하도록 합니다. 프로젝트가 끝나면 무엇이 잘되었고 무엇을 개선할 수 있었는지 돌아보는 팀워크 성찰 활동을 수행합니다. 노련한 실무자들에게는 당연한 관행들이지만, 협업에 서툰 학생들에게는 이러한 과정이 없으면 협업이 쉽게 무너집니다. 이러한 장치를 마련해도 갈등이 생길 수 있습니다. 이때는 갈등을 피하려 하기보다 당연한 것으로 받아들이고, 갈등이 생겼을 때 어떻게 관리할지에 대한 계획을 미리 세워두는 것이 중요하다는 점을 학생들과 공유해야 합니다.
규칙 10: 학생들이 프로젝트를 수행하게 하기
마지막 간단한 규칙은 학생들이 프로젝트를 완수하게 하는 것입니다. 즉, 데이터 제품 전체를 처음부터 끝까지(Jenny Bryan의 표현을 빌리자면 “나초에서 치즈케이크까지”) 만들어 보게 하는 것입니다. 프로젝트는 개인별로 할 수도 있고 그룹으로 할 수도 있습니다. 핵심은 학생들이 데이터 과학 실무의 전체 워크플로우를 경험해 보는 것입니다. 프로젝트는 학생들에게 큰 동기를 부여할 뿐만 아니라, 실제 데이터의 복잡하고 지저분한 면(현실의 데이터는 항상 지저분하다는 것을 우리 모두 알고 있습니다)을 다루는 소중한 경험을 제공합니다. 대부분의 수업은 데이터 시각화나 전처리 또는 모델링 같은 특정 단계에만 집중하는 경향이 있는데, 프로젝트를 통해서만 이 조각들이 현실적인 시나리오에서 어떻게 맞물려 돌아가는지 이해할 수 있습니다. 이는 예비 데이터 과학자에게 매우 중요한 훈련입니다43.
하지만 강사 입장에서 프로젝트는 학생 수가 많고 교육 자원이 부족할 때 큰 부담이 될 수 있습니다. 이를 관리 가능하게 만드는 방법 중 하나는 프로젝트의 범위를 제한(Scope)하는 것입니다. 특정 주제로 제한하거나, 제공된 데이터셋 리스트 중에서만 선택하게 하거나, 특정 방법론이나 프로그래밍 언어를 쓰게 할 수 있습니다. 이렇게 하면 채점의 일관성을 유지할 수 있고 공통된 루브릭을 사용할 수 있습니다. 예컨대 저희의 협업 소프트웨어 개발 수업에서는 프로젝트 팀원 수만큼의 함수(n개)를 가진 Python 패키지를 만들도록 합니다. 각 함수는 공통된 테마와 관련이 있어야 하며, 데이터 과학이라는 범주 안에 있어야 합니다. 학생들은 수업에서 배운 패키징 도구와 협업 방식을 반드시 활용해야 합니다. 이러한 프로젝트는 범위가 명확하기 때문에 채점이 매우 효율적이면서도, 학생들이 관심 있는 주제를 선택할 수 있게 하여 창의성을 발휘할 기회를 줍니다. 또 다른 방법은 학생들이 본인의 연구나 학위 논문 데이터에 수업에서 배운 개념들을 적용해 보게 하는 것입니다. 이는 대학원 수업에서 특히 효과적입니다. 예를 들어 UBC의 STAT 545 수업에서 학생들은 수업 중에 다루기 쉬운 데이터(Gapminder 등)로 개념을 배우고, 프로젝트에서는 그 개념을 자신의 연구 데이터에 직접 적용합니다. 프로젝트의 난이도는 수업 진도와 맞춰 매주 차츰 올라갑니다. 이 방식 역시 학생들이 사용하는 기술적 방법론들을 통일하여 채점을 수월하게 하면서도, 학생들이 깊은 관심을 가진 주제에 몰입하게 만듭니다.
결론
여기에 나열된 데이터 과학 교육을 위한 10가지 간단한 규칙이 모든 것을 아우르는 것은 아니지만, 새로 시작하는 데이터 과학 교육자들에게 유용한 출발점이 되기를 바랍니다. 이 리스트는 저자들의 교육 경험과 다른 선도적인 데이터 과학 교육자들이 실천해 온 사례들을 바탕으로 정리되었습니다.
지원 정보
S1 File. S1_File.pdf. 저자들이 실제 수업에서 사용한 데이터 분석 동료 평가 체크리스트 예시.
감사의 글
저자들이 제시한 10가지 규칙의 기틀을 마련해 준 커뮤니티의 선도적인 데이터 과학 교육자들과 함께 실험에 참여해 준 학생 여러분께 깊은 감사를 표합니다.
참고 문헌
Berman F, Rutenbar R, Hailpern B, Christensen H, Davidson S, Estrin D, et al. Realizing the potential of data science. Communications of the ACM. 2018;61: 67–72.↩︎
Wing JM. The Data Life Cycle. Harvard Data Science Review. 2019;1. doi:10.1162/99608f92.e26845b4↩︎
Irizarry RA. The Role of Academia in Data Science Education. Harvard Data Science Review. 2020;2. doi:10.1162/99608f92.dd363929↩︎
Timbers T, Campbell T, Lee M. Data science: A first introduction. Chapman; Hall/CRC; 2022.↩︎
Carver R, Everson M, Gabrosek J, Horton N, Lock R, Mocko M, et al. Guidelines for assessment and instruction in statistics education (GAISE) college report 2016. AMSTAT; 2016.↩︎
Zendler A, Klaudt D. Instructional methods to computer science education as investigated by computer science teachers. Journal of Computer Science. 2015;11: 915–927. doi:10.3844/jcssp.2015.915.927↩︎
Fincher SA, Robins AV. The cambridge handbook of computing education research. Cambridge University Press; 2019.↩︎
Çetinkaya-Rundel M, Ellison V. A fresh look at introductory data science. Journal of Statistics and Data Science Education. 2021;29: S16–S26.↩︎
Timbers T, Campbell T, Lee M. Data science: A first introduction. Chapman; Hall/CRC; 2022.↩︎
Wang X, Rush C, Horton NJ. Data visualization on day one: Bringing big ideas into intro stats early and often. arXiv preprint arXiv:170508544. 2017.↩︎
Robinson D. Introduction to the tidyverse. DataCamp Online Course; 2017. Available: https://www.datacamp.com/courses/introduction-to-the-tidyverse↩︎
Robinson D. Announcing ”introduction to the tidyverse”, my new DataCamp course. Variance Explained (blog); 2017. Available: http://varianceexplained.org/r/intro-tidyverse/↩︎
Bryan J. Tweet about not front-loading boring foundational material. Twitter; 2017.↩︎
Fisher D, Frey N. Better learning through structured teaching: A framework for the gradual release of responsibility. ASCD; 2021.↩︎
Nederbragt A, Harris RM, Hill AP, Wilson G. Ten quick tips for teaching with participatory live coding. PLOS Computational Biology. 2020;16: e1008090.↩︎
Timbers T, Campbell T, Lee M. Data science: A first introduction. Chapman; Hall/CRC; 2022.↩︎
Ebbinghaus H. Grundzüge der psychologie v. 2, 1913. Veit; 1913.↩︎
Harris JD. Habituatory response decrement in the intact organism. Psychological bulletin. 1943;40: 385.↩︎
Shaw G. Donald hebb: The organization of behavior. Brain theory: Proceedings of the first trieste meeting on brain theory, october 1–4, 1984. Springer; 1986. pp. 231–233.↩︎
Carchedi N, Kross S, Bauer B, et al. Swirl: Learn r, in r. 2023. Available: https://swirlstats.com↩︎
Kaggle. Kaggle learn. Online learning platform; 2018. Available: https://www.kaggle.com/learn↩︎
Wickham H, Grolemund G, Çetinkaya-Rundel M. R for data science. 2nd ed. O’Reilly Media; 2023.↩︎
Wilson G. Teaching tech together: How to make your lessons work and build a teaching community around them. Chapman; Hall/CRC; 2019.↩︎
Wilson G. Teaching tech together: How to make your lessons work and build a teaching community around them. Chapman; Hall/CRC; 2019.↩︎
Kross S, Çetinkaya-Rundel M, et al. Learnr: Interactive tutorials for r. 2024. Available: https://rstudio.github.io/learnr/↩︎
Hamrick JB et al. Nbgrader: A tool for creating and grading assignments in the jupyter notebook. Proceedings of the 19th python in science conference. 2016. pp. 68–74. doi:10.25080/Majora-629e541a-00e↩︎
Kim EJ, Lau S, Hug J, DeNero J. Otter: A tool for automated grading of jupyter notebooks and more. Proceedings of the 23rd python in science conference. 2022. pp. 120–127. doi:10.25080/majora-2127ed6e-00c↩︎
Horst A, Hill A, Gorman K. Palmerpenguins: Data for palmer archipelago (antarctica) penguin species. R Journal. 2020;12: 277–283. doi:10.32614/RJ-2020-043↩︎
Bryan J. STAT 545: Data wrangling, exploration, and analysis with R. 2015. Available: https://stat545.com/↩︎
Wickham H, François R, Henry L, Müller K. Dplyr: A grammar of data manipulation. 2024. Available: https://CRAN.R-project.org/package=dplyr↩︎
Timbers T. Canlang: Canadian census language data. 2020. Available: https://ttimbers.github.io/canlang/↩︎
Bryan J. Gapminder: Data from gapminder. 2017. Available: https://CRAN.R-project.org/package=gapminder↩︎
Robinson D. Unvotes: United nations general assembly voting data. 2021. doi:10.32614/CRAN.package.unvotes↩︎
Ihaka R, Gentleman R. R: A language for data analysis and graphics. Journal of computational and graphical statistics. 1996;5: 299–314.↩︎
Wickham H, Hester J, Henry L, et al. Tidyverse: Easily install and load the ’tidyverse’. 2024. Available: https://CRAN.R-project.org/package=tidyverse↩︎
Fay C. Why do we use arrow as an assignment operator? Blog post; 2018. Available: https://colinfay.me/r-assignment/↩︎
Peng RD. R programming for data science. Leanpub Victoria, BC, Canada; 2016.↩︎
Edmondson A. Psychological safety and learning behavior in work teams. Administrative science quarterly. 1999;44: 350–383.↩︎
Lyman B, Mendon CR. Pre-licensure nursing students’ experiences of psychological safety: A qualitative descriptive study. Nurse education today. 2021;105: 105026.↩︎
Topping K. Peer assessment between students in colleges and universities. Review of Educational Research. 1998;68: 249–276. Available: http://www.jstor.org/stable/1170598↩︎
Gawande A. Checklist manifesto, the (HB). Penguin Books India; 2010.↩︎
Parker TH, Griffith SC, Bronstein JL, Fidler F, Foster S, Fraser H, et al. Empowering peer reviewers with a checklist to improve transparency. Nature ecology & evolution. 2018;2: 929–935.↩︎
Çetinkaya-Rundel M, Dogucu M, Rummerfield W. The 5Ws and 1H of term projects in the introductory data science classroom. Statistics Education Research Journal. 2022;21: 4–4.↩︎